 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Position Encoding in Diffusion U-Net for Training-free High-resolution Image Generation
Mar 12, 2025



Denoising higher-resolution latents via a pre-trained U-Net leads to repetitive and disordered image patterns. Although recent studies make efforts to improve generative quality by aligning denoising process across original and higher resolutions, the root cause of suboptimal generation is still lacking exploration. Through comprehensive analysis of position encoding in U-Net, we attribute it to inconsistent position encoding, sourced by the inadequate propagation of position information from zero-padding to latent features in convolution layers as resolution increases. To address this issue, we propose a novel training-free approach, introducing a Progressive Boundary Complement (PBC) method. This method creates dynamic virtual image boundaries inside the feature map to enhance position information propagation, enabling high-quality and rich-content high-resolution image synthesis. Extensive experiments demonstrate the superiority of our method.
Label Drop for Multi-Aspect Relation Modeling in Universal Information Extraction
Feb 18, 2025



Universal Information Extraction (UIE) has garnered significant attention due to its ability to address model explosion problems effectively. Extractive UIE can achieve strong performance using a relatively small model, making it widely adopted. Extractive UIEs generally rely on task instructions for different tasks, including single-target instructions and multiple-target instructions. Single-target instruction UIE enables the extraction of only one type of relation at a time, limiting its ability to model correlations between relations and thus restricting its capability to extract complex relations. While multiple-target instruction UIE allows for the extraction of multiple relations simultaneously, the inclusion of irrelevant relations introduces decision complexity and impacts extraction accuracy. Therefore, for multi-relation extraction, we propose LDNet, which incorporates multi-aspect relation modeling and a label drop mechanism. By assigning different relations to different levels for understanding and decision-making, we reduce decision confusion. Additionally, the label drop mechanism effectively mitigates the impact of irrelevant relations. Experiments show that LDNet outperforms or achieves competitive performance with state-of-the-art systems on 9 tasks, 33 datasets, in both single-modal and multi-modal, few-shot and zero-shot settings.\footnote{https://github.com/Lu-Yang666/LDNet}
A Peaceman-Rachford Splitting Approach with Deep Equilibrium Network for Channel Estimation
Oct 31, 2024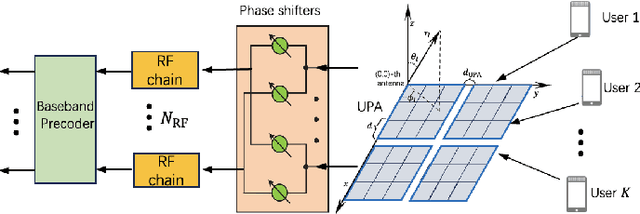

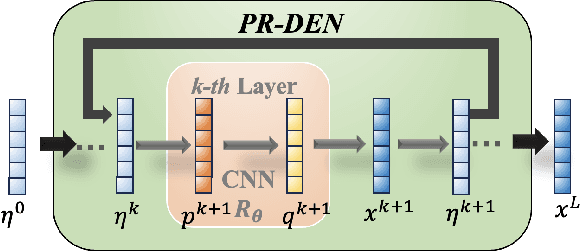
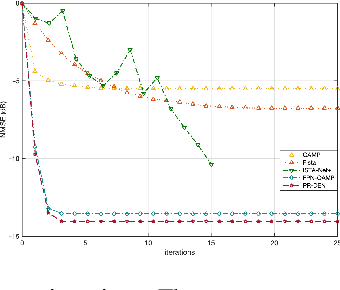
Multiple-input multiple-output (MIMO) is pivotal for wireless systems, yet its high-dimensional, stochastic channel poses significant challenges for accurate estimation, highlighting the critical need for robust estimation techniques. In this paper, we introduce a novel channel estimation method for the MIMO system. The main idea is to construct a fixed-point equation for channel estimation, which can be implemented into the deep equilibrium (DEQ) model with a fixed network. Specifically, the Peaceman-Rachford (PR) splitting method is applied to the dual form of the regularized minimization problem to construct fixed-point equation with non-expansive property. Then, the fixed-point equation is implemented into the DEQ model with a fixed layer, leveraging its advantage of the low training complexity. Moreover, we provide a rigorous theoretical analysis, demonstrating the convergence and optimality of our approach. Additionally, simulations of hybrid far- and near-field channels demonstrate that our approach yields favorable results, indicating its ability to advance channel estimation in MIMO system.
Robustness and Security Enhancement of Radio Frequency Fingerprint Identification in Time-Varying Channels
Oct 10, 2024



Radio frequency fingerprint identification (RFFI) is becoming increasingly popular, especially in applications with constrained power, such as the Internet of Things (IoT). Due to subtle manufacturing variations, wireless devices have unique radio frequency fingerprints (RFFs). These RFFs can be used with pattern recognition algorithms to classify wireless devices. However, Implementing reliable RFFI in time-varying channels is challenging because RFFs are often distorted by channel effects, reducing the classification accuracy. This paper introduces a new channel-robust RFF, and leverages transfer learning to enhance RFFI in the time-varying channels. Experimental results show that the proposed RFFI system achieved an average classification accuracy improvement of 33.3 % in indoor environments and 34.5 % in outdoor environments. This paper also analyzes the security of the proposed RFFI system to address the security flaw in formalized impersonation attacks. Since RFF collection is being carried out in uncontrolled deployment environments, RFFI systems can be targeted with false RFFs sent by rogue devices. The resulting classifiers may classify the rogue devices as legitimate, effectively replacing their true identities. To defend against impersonation attacks, a novel keyless countermeasure is proposed, which exploits the intrinsic output of the softmax function after classifier training without sacrificing the lightweight nature of RFFI. Experimental results demonstrate an average increase of 0.3 in the area under the receiver operating characteristic curve (AUC), with a 40.0 % improvement in attack detection rate in indoor and outdoor environments.
The Music Maestro or The Musically Challenged, A Massive Music Evaluation Benchmark for Large Language Models
Jun 22, 2024



Benchmark plays a pivotal role in assessing the advancements of large language models (LLMs). While numerous benchmarks have been proposed to evaluate LLMs' capabilities, there is a notable absence of a dedicated benchmark for assessing their musical abilities. To address this gap, we present ZIQI-Eval, a comprehensive and large-scale music benchmark specifically designed to evaluate the music-related capabilities of LLMs. ZIQI-Eval encompasses a wide range of questions, covering 10 major categories and 56 subcategories, resulting in over 14,000 meticulously curated data entries. By leveraging ZIQI-Eval, we conduct a comprehensive evaluation over 16 LLMs to evaluate and analyze LLMs' performance in the domain of music. Results indicate that all LLMs perform poorly on the ZIQI-Eval benchmark, suggesting significant room for improvement in their musical capabilities. With ZIQI-Eval, we aim to provide a standardized and robust evaluation framework that facilitates a comprehensive assessment of LLMs' music-related abilities. The dataset is available at GitHub\footnote{https://github.com/zcli-charlie/ZIQI-Eval} and HuggingFace\footnote{https://huggingface.co/datasets/MYTH-Lab/ZIQI-Eval}.
Frequency-based Matcher for Long-tailed Semantic Segmentation
Jun 06, 2024



The successful application of semantic segmentation technology in the real world has been among the most exciting achievements in the computer vision community over the past decade. Although the long-tailed phenomenon has been investigated in many fields, e.g., classification and object detection, it has not received enough attention in semantic segmentation and has become a non-negligible obstacle to applying semantic segmentation technology in autonomous driving and virtual reality. Therefore, in this work, we focus on a relatively under-explored task setting, long-tailed semantic segmentation (LTSS). We first establish three representative datasets from different aspects, i.e., scene, object, and human. We further propose a dual-metric evaluation system and construct the LTSS benchmark to demonstrate the performance of semantic segmentation methods and long-tailed solutions. We also propose a transformer-based algorithm to improve LTSS, frequency-based matcher, which solves the oversuppression problem by one-to-many matching and automatically determines the number of matching queries for each class. Given the comprehensiveness of this work and the importance of the issues revealed, this work aims to promote the empirical study of semantic segmentation tasks. Our datasets, codes, and models will be publicly available.
E4C: Enhance Editability for Text-Based Image Editing by Harnessing Efficient CLIP Guidance
Mar 15, 2024



Diffusion-based image editing is a composite process of preserving the source image content and generating new content or applying modifications. While current editing approaches have made improvements under text guidance, most of them have only focused on preserving the information of the input image, disregarding the importance of editability and alignment to the target prompt. In this paper, we prioritize the editability by proposing a zero-shot image editing method, named \textbf{E}nhance \textbf{E}ditability for text-based image \textbf{E}diting via \textbf{E}fficient \textbf{C}LIP guidance (\textbf{E4C}), which only requires inference-stage optimization to explicitly enhance the edibility and text alignment. Specifically, we develop a unified dual-branch feature-sharing pipeline that enables the preservation of the structure or texture of the source image while allowing the other to be adapted based on the editing task. We further integrate CLIP guidance into our pipeline by utilizing our novel random-gateway optimization mechanism to efficiently enhance the semantic alignment with the target prompt. Comprehensive quantitative and qualitative experiments demonstrate that our method effectively resolves the text alignment issues prevalent in existing methods while maintaining the fidelity to the source image, and performs well across a wide range of editing tasks.
Controllable Generation with Text-to-Image Diffusion Models: A Survey
Mar 07, 2024



In the rapidly advancing realm of visual generation, diffusion models have revolutionized the landscape, marking a significant shift in capabilities with their impressive text-guided generative functions. However, relying solely on text for conditioning these models does not fully cater to the varied and complex requirements of different applications and scenarios. Acknowledging this shortfall, a variety of studies aim to control pre-trained text-to-image (T2I) models to support novel conditions. In this survey, we undertake a thorough review of the literature on controllable generation with T2I diffusion models, covering both the theoretical foundations and practical advancements in this domain. Our review begins with a brief introduction to the basics of denoising diffusion probabilistic models (DDPMs) and widely used T2I diffusion models. We then reveal the controlling mechanisms of diffusion models, theoretically analyzing how novel conditions are introduced into the denoising process for conditional generation. Additionally, we offer a detailed overview of research in this area, organizing it into distinct categories from the condition perspective: generation with specific conditions, generation with multiple conditions, and universal controllable generation. For an exhaustive list of the controllable generation literature surveyed, please refer to our curated repository at \url{https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models}.
Concept-centric Personalization with Large-scale Diffusion Priors
Dec 13, 2023Despite large-scale diffusion models being highly capable of generating diverse open-world content, they still struggle to match the photorealism and fidelity of concept-specific generators. In this work, we present the task of customizing large-scale diffusion priors for specific concepts as concept-centric personalization. Our goal is to generate high-quality concept-centric images while maintaining the versatile controllability inherent to open-world models, enabling applications in diverse tasks such as concept-centric stylization and image translation. To tackle these challenges, we identify catastrophic forgetting of guidance prediction from diffusion priors as the fundamental issue. Consequently, we develop a guidance-decoupled personalization framework specifically designed to address this task. We propose Generalized Classifier-free Guidance (GCFG) as the foundational theory for our framework. This approach extends Classifier-free Guidance (CFG) to accommodate an arbitrary number of guidances, sourced from a variety of conditions and models. Employing GCFG enables us to separate conditional guidance into two distinct components: concept guidance for fidelity and control guidance for controllability. This division makes it feasible to train a specialized model for concept guidance, while ensuring both control and unconditional guidance remain intact. We then present a null-text Concept-centric Diffusion Model as a concept-specific generator to learn concept guidance without the need for text annotations. Code will be available at https://github.com/PRIV-Creation/Concept-centric-Personalization.
FFEINR: Flow Feature-Enhanced Implicit Neural Representation for Spatio-temporal Super-Resolution
Aug 27, 2023



Large-scale numerical simulations are capable of generating data up to terabytes or even petabytes. As a promising method of data reduction, super-resolution (SR) has been widely studied in the scientific visualization community. However, most of them are based on deep convolutional neural networks (CNNs) or generative adversarial networks (GANs) and the scale factor needs to be determined before constructing the network. As a result, a single training session only supports a fixed factor and has poor generalization ability. To address these problems, this paper proposes a Feature-Enhanced Implicit Neural Representation (FFEINR) for spatio-temporal super-resolution of flow field data. It can take full advantage of the implicit neural representation in terms of model structure and sampling resolution. The neural representation is based on a fully connected network with periodic activation functions, which enables us to obtain lightweight models. The learned continuous representation can decode the low-resolution flow field input data to arbitrary spatial and temporal resolutions, allowing for flexible upsampling. The training process of FFEINR is facilitated by introducing feature enhancements for the input layer, which complements the contextual information of the flow field. To demonstrate the effectiveness of the proposed method, a series of experiments are conducted on different datasets by setting different hyperparameters. The results show that FFEINR achieves significantly better results than the trilinear interpolation method.