 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ground Instructional Articles in Videos through Narrations
Jun 06, 2023



In this paper we present an approach for localizing steps of procedural activities in narrated how-to videos. To deal with the scarcity of labeled data at scale, we source the step descriptions from a language knowledge base (wikiHow) containing instructional articles for a large variety of procedural tasks. Without any form of manual supervision, our model learns to temporally ground the steps of procedural articles in how-to videos by matching three modalities: frames, narrations, and step descriptions. Specifically, our method aligns steps to video by fusing information from two distinct pathways: i) {\em direct} alignment of step descriptions to frames, ii) {\em indirect} alignment obtained by composing steps-to-narrations with narrations-to-video correspondences. Notably, our approach performs global temporal grounding of all steps in an article at once by exploiting order information, and is trained with step pseudo-labels which are iteratively refined and aggressively filtered. In order to validate our model we introduce a new evaluation benchmark -- HT-Step -- obtained by manually annotating a 124-hour subset of HowTo100M\footnote{A test server is accessible at \url{https://eval.ai/web/challenges/challenge-page/2082}.} with steps sourced from wikiHow articles. Experiments on this benchmark as well as zero-shot evaluations on CrossTask demonstrate that our multi-modality alignment yields dramatic gains over several baselines and prior works. Finally, we show that our inner module for matching narration-to-video outperforms by a large margin the state of the art on the HTM-Align narration-video alignment benchmark.
Open-world Instance Segmentation: Top-down Learning with Bottom-up Supervision
Mar 09, 2023



Many top-down architectures for instance segmentation achieve significant success when trained and tested on pre-defined closed-world taxonomy. However, when deployed in the open world, they exhibit notable bias towards seen classes and suffer from significant performance drop. In this work, we propose a novel approach for open world instance segmentation called bottom-Up and top-Down Open-world Segmentation (UDOS) that combines classical bottom-up segmentation algorithms within a top-down learning framework. UDOS first predicts parts of objects using a top-down network trained with weak supervision from bottom-up segmentations. The bottom-up segmentations are class-agnostic and do not overfit to specific taxonomies. The part-masks are then fed into affinity-based grouping and refinement modules to predict robust instance-level segmentations. UDOS enjoys both the speed and efficiency from the top-down architectures and the generalization ability to unseen categories from bottom-up supervision. We validate the strengths of UDOS on multiple cross-category as well as cross-dataset transfer tasks from 5 challenging datasets including MS-COCO, LVIS, ADE20k, UVO and OpenImages, achieving significant improvements over state-of-the-art across the board. Our code and models are available on our project page.
MINOTAUR: Multi-task Video Grounding From Multimodal Queries
Feb 16, 2023



Video understanding tasks take many forms, from action detection to visual query localization and spatio-temporal grounding of sentences. These tasks differ in the type of inputs (only video, or video-query pair where query is an image region or sentence) and outputs (temporal segments or spatio-temporal tubes). However, at their core they require the same fundamental understanding of the video, i.e., the actors and objects in it, their actions and interactions. So far these tasks have been tackled in isolation with individual, highly specialized architectures, which do not exploit the interplay between tasks. In contrast, in this paper, we present a single, unified model for tackling query-based video understanding in long-form videos. In particular, our model can address all three tasks of the Ego4D Episodic Memory benchmark which entail queries of three different forms: given an egocentric video and a visual, textual or activity query, the goal is to determine when and where the answer can be seen within the video. Our model design is inspired by recent query-based approaches to spatio-temporal grounding, and contains modality-specific query encoders and task-specific sliding window inference that allow multi-task training with diverse input modalities and different structured outputs. We exhaustively analyze relationships among the tasks and illustrate that cross-task learning leads to improved performance on each individual task, as well as the ability to generalize to unseen tasks, such as zero-shot spatial localization of language queries.
Egocentric Video Task Translation @ Ego4D Challenge 2022
Feb 03, 2023



This technical report describes the EgoTask Translation approach that explores relations among a set of egocentric video tasks in the Ego4D challenge. To improve the primary task of interest, we propose to leverage existing models developed for other related tasks and design a task translator that learns to ''translate'' auxiliary task features to the primary task. With no modification to the baseline architectures, our proposed approach achieves competitive performance on two Ego4D challenges, ranking the 1st in the talking to me challenge and the 3rd in the PNR keyframe localization challenge.
HierVL: Learning Hierarchical Video-Language Embeddings
Jan 05, 2023



Video-language embeddings are a promising avenue for injecting semantics into visual representations, but existing methods capture only short-term associations between seconds-long video clips and their accompanying text. We propose HierVL, a novel hierarchical video-language embedding that simultaneously accounts for both long-term and short-term associations. As training data, we take videos accompanied by timestamped text descriptions of human actions, together with a high-level text summary of the activity throughout the long video (as are available in Ego4D). We introduce a hierarchical contrastive training objective that encourages text-visual alignment at both the clip level and video level. While the clip-level constraints use the step-by-step descriptions to capture what is happening in that instant, the video-level constraints use the summary text to capture why it is happening, i.e., the broader context for the activity and the intent of the actor. Our hierarchical scheme yields a clip representation that outperforms its single-level counterpart as well as a long-term video representation that achieves SotA results on tasks requiring long-term video modeling. HierVL successfully transfers to multiple challenging downstream tasks (in EPIC-KITCHENS-100, Charades-Ego, HowTo100M) in both zero-shot and fine-tuned settings.
What You Say Is What You Show: Visual Narration Detection in Instructional Videos
Jan 05, 2023Narrated "how-to" videos have emerged as a promising data source for a wide range of learning problems, from learning visual representations to training robot policies. However, this data is extremely noisy, as the narrations do not always describe the actions demonstrated in the video. To address this problem we introduce the novel task of visual narration detection, which entails determining whether a narration is visually depicted by the actions in the video. We propose "What You Say is What You Show" (WYS^2), a method that leverages multi-modal cues and pseudo-labeling to learn to detect visual narrations with only weakly labeled data. We further generalize our approach to operate on only audio input, learning properties of the narrator's voice that hint if they are currently doing what they describe. Our model successfully detects visual narrations in in-the-wild videos, outperforming strong baselines, and we demonstrate its impact for state-of-the-art summarization and alignment of instructional video.
Ego-Only: Egocentric Action Detection without Exocentric Pretraining
Jan 03, 2023We present Ego-Only, the first training pipeline that enables state-of-the-art action detection on egocentric (first-person) videos without any form of exocentric (third-person) pretraining. Previous approaches found that egocentric models cannot be trained effectively from scratch and that exocentric representations transfer well to first-person videos. In this paper we revisit these two observations. Motivated by the large content and appearance gap separating the two domains, we propose a strategy that enables effective training of egocentric models without exocentric pretraining. Our Ego-Only pipeline is simple. It trains the video representation with a masked autoencoder finetuned for temporal segmentation. The learned features are then fed to an off-the-shelf temporal action localization method to detect actions. We evaluate our approach on two established egocentric video datasets: Ego4D and EPIC-Kitchens-100. On Ego4D, our Ego-Only is on-par with exocentric pretraining methods that use an order of magnitude more labels. On EPIC-Kitchens-100, our Ego-Only even outperforms exocentric pretraining (by 2.1% on verbs and by 1.8% on nouns), setting a new state-of-the-art.
Egocentric Video Task Translation
Dec 13, 2022Different video understanding tasks are typically treated in isolation, and even with distinct types of curated data (e.g., classifying sports in one dataset, tracking animals in another). However, in wearable cameras, the immersive egocentric perspective of a person engaging with the world around them presents an interconnected web of video understanding tasks -- hand-object manipulations, navigation in the space, or human-human interactions -- that unfold continuously, driven by the person's goals. We argue that this calls for a much more unified approach. We propose EgoTask Translation (EgoT2), which takes a collection of models optimized on separate tasks and learns to translate their outputs for improved performance on any or all of them at once. Unlike traditional transfer or multi-task learning, EgoT2's flipped design entails separate task-specific backbones and a task translator shared across all tasks, which captures synergies between even heterogeneous tasks and mitigates task competition. Demonstrating our model on a wide array of video tasks from Ego4D, we show its advantages over existing transfer paradigms and achieve top-ranked results on four of the Ego4D 2022 benchmark challenges.
HistoPerm: A Permutation-Based View Generation Approach for Learning Histopathologic Feature Representations
Sep 13, 2022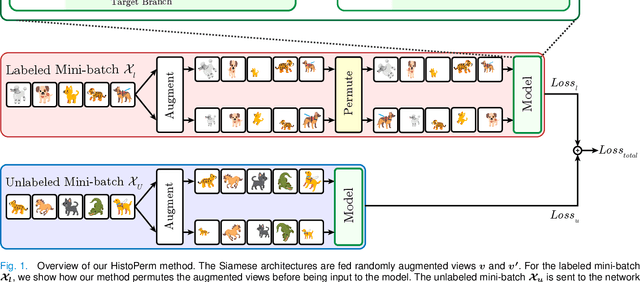
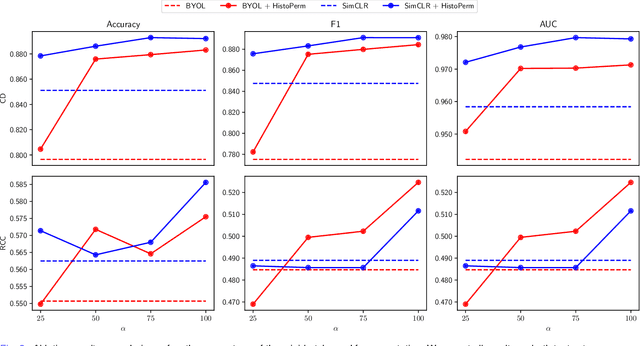
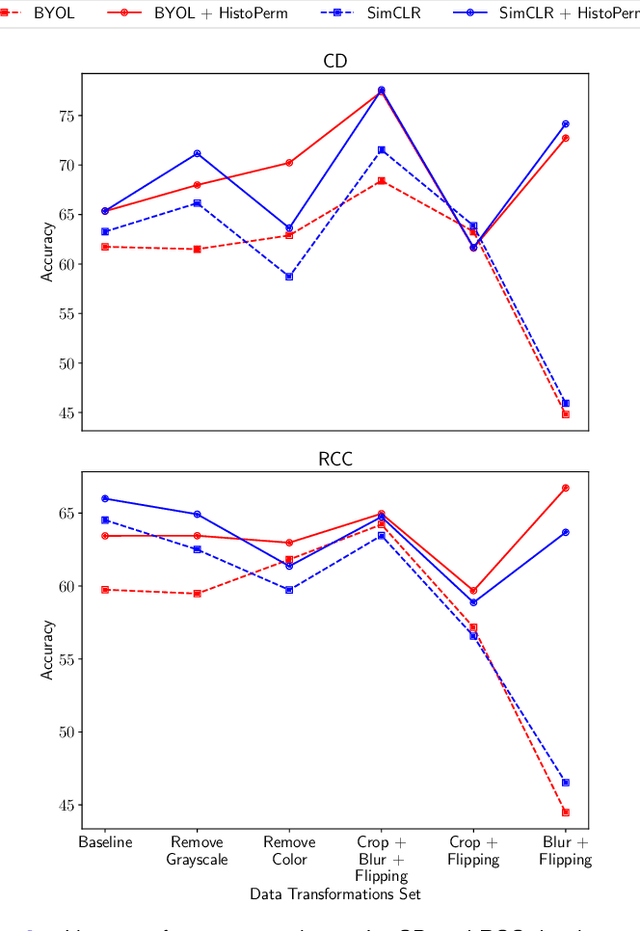
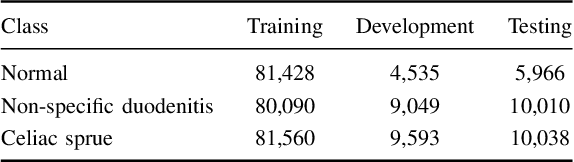
Recently, deep learning methods have been successfully applied to solve numerous challenges in the field of digital pathology. However, many of these approaches are fully supervised and require annotated images. Annotating a histology image is a time-consuming and tedious process for even a highly skilled pathologist, and, as such, most histology datasets lack region-of-interest annotations and are weakly labeled. In this paper, we introduce HistoPerm, a view generation approach designed for improving the performance of representation learning techniques on histology images in weakly supervised settings. In HistoPerm, we permute augmented views of patches generated from whole-slide histology images to improve classification accuracy. These permuted views belong to the same original slide-level class but are produced from distinct patch instances. We tested adding HistoPerm to BYOL and SimCLR, two prominent representation learning methods, on two public histology datasets for Celiac disease and Renal Cell Carcinoma. For both datasets, we found improved performance in terms of accuracy, F1-score, and AUC compared to the standard BYOL and SimCLR approaches. Particularly, in a linear evaluation configuration, HistoPerm increases classification accuracy on the Celiac disease dataset by 8% for BYOL and 3% for SimCLR. Similarly, with HistoPerm, classification accuracy increases by 2% for BYOL and 0.25% for SimCLR on the Renal Cell Carcinoma dataset. The proposed permutation-based view generation approach can be adopted in common representation learning frameworks to capture histopathology features in weakly supervised settings and can lead to whole-slide classification outcomes that are close to, or even better than, fully supervised methods.
Deformable Video Transformer
Mar 31, 2022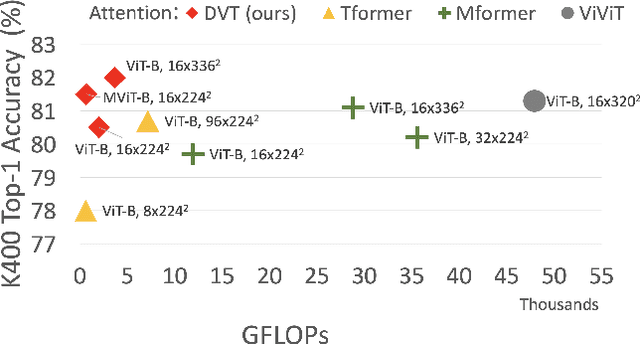

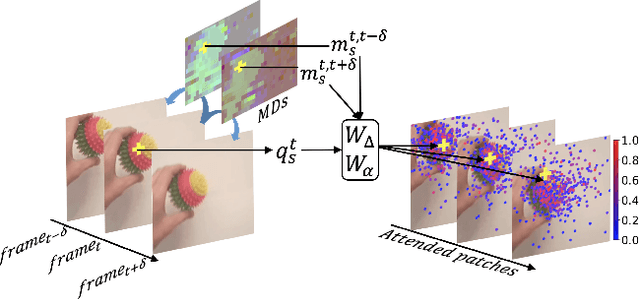
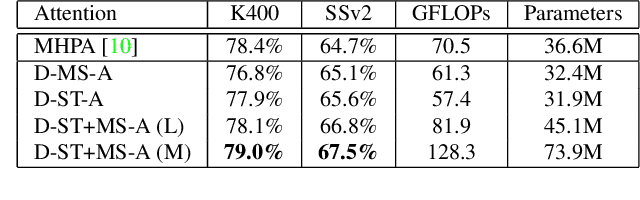
Video transformers have recently emerged as an effective alternative to convolutional networks for action classification. However, most prior video transformers adopt either global space-time attention or hand-defined strategies to compare patches within and across frames. These fixed attention schemes not only have high computational cost but, by comparing patches at predetermined locations, they neglect the motion dynamics in the video. In this paper, we introduce the Deformable Video Transformer (DVT), which dynamically predicts a small subset of video patches to attend for each query location based on motion information, thus allowing the model to decide where to look in the video based on correspondences across frames. Crucially, these motion-based correspondences are obtained at zero-cost from information stored in the compressed format of the video. Our deformable attention mechanism is optimised directly with respect to classification performance, thus eliminating the need for suboptimal hand-design of attention strategies. Experiments on four large-scale video benchmarks (Kinetics-400, Something-Something-V2, EPIC-KITCHENS and Diving-48) demonstrate that, compared to existing video transformers, our model achieves higher accuracy at the same or lower computational cost, and it attains state-of-the-art results on these four datasets.