 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Collective Decision-Making
Nov 03, 2023



In various work contexts, such as meeting scheduling, collaborating, and project planning, collective decision-making is essential but often challenging due to diverse individual preferences, varying work focuses, and power dynamics among members. To address this, we propose a system leveraging Large Language Models (LLMs) to facilitate group decision-making by managing conversations and balancing preferences among individuals. Our system extracts individual preferences and suggests options that satisfy a significant portion of the members. We apply this system to corporate meeting scheduling. We create synthetic employee profiles and simulate conversations at scale, leveraging LLMs to evaluate the system. Our results indicate efficient coordination with reduced interactions between members and the LLM-based system. The system also effectively refines proposed options over time, ensuring their quality and equity. Finally, we conduct a survey study involving human participants to assess our system's ability to aggregate preferences and reasoning. Our findings show that the system exhibits strong performance in both dimensions.
S3-DST: Structured Open-Domain Dialogue Segmentation and State Tracking in the Era of LLMs
Sep 16, 2023



The traditional Dialogue State Tracking (DST) problem aims to track user preferences and intents in user-agent conversations. While sufficient for task-oriented dialogue systems supporting narrow domain applications, the advent of Large Language Model (LLM)-based chat systems has introduced many real-world intricacies in open-domain dialogues. These intricacies manifest in the form of increased complexity in contextual interactions, extended dialogue sessions encompassing a diverse array of topics, and more frequent contextual shifts. To handle these intricacies arising from evolving LLM-based chat systems, we propose joint dialogue segmentation and state tracking per segment in open-domain dialogue systems. Assuming a zero-shot setting appropriate to a true open-domain dialogue system, we propose S3-DST, a structured prompting technique that harnesses Pre-Analytical Recollection, a novel grounding mechanism we designed for improving long context tracking. To demonstrate the efficacy of our proposed approach in joint segmentation and state tracking, we evaluate S3-DST on a proprietary anonymized open-domain dialogue dataset, as well as publicly available DST and segmentation datasets. Across all datasets and settings, S3-DST consistently outperforms the state-of-the-art, demonstrating its potency and robustness the next generation of LLM-based chat systems.
Using Large Language Models to Generate, Validate, and Apply User Intent Taxonomies
Sep 14, 2023



Log data can reveal valuable information about how users interact with web search services, what they want, and how satisfied they are. However, analyzing user intents in log data is not easy, especially for new forms of web search such as AI-driven chat. To understand user intents from log data, we need a way to label them with meaningful categories that capture their diversity and dynamics. Existing methods rely on manual or ML-based labeling, which are either expensive or inflexible for large and changing datasets. We propose a novel solution using large language models (LLMs), which can generate rich and relevant concepts, descriptions, and examples for user intents. However, using LLMs to generate a user intent taxonomy and apply it to do log analysis can be problematic for two main reasons: such a taxonomy is not externally validated, and there may be an undesirable feedback loop. To overcome these issues, we propose a new methodology with human experts and assessors to verify the quality of the LLM-generated taxonomy. We also present an end-to-end pipeline that uses an LLM with human-in-the-loop to produce, refine, and use labels for user intent analysis in log data. Our method offers a scalable and adaptable way to analyze user intents in web-scale log data with minimal human effort. We demonstrate its effectiveness by uncovering new insights into user intents from search and chat logs from Bing.
Situating Recommender Systems in Practice: Towards Inductive Learning and Incremental Updates
Nov 11, 2022With information systems becoming larger scale, recommendation systems are a topic of growing interest in machine learning research and industry. Even though progress on improving model design has been rapid in research, we argue that many advances fail to translate into practice because of two limiting assumptions. First, most approaches focus on a transductive learning setting which cannot handle unseen users or items and second, many existing methods are developed for static settings that cannot incorporate new data as it becomes available. We argue that these are largely impractical assumptions on real-world platforms where new user interactions happen in real time. In this survey paper, we formalize both concepts and contextualize recommender systems work from the last six years. We then discuss why and how future work should move towards inductive learning and incremental updates for recommendation model design and evaluation. In addition, we present best practices and fundamental open challenges for future research.
Learning Causal Effects on Hypergraphs
Jul 07, 2022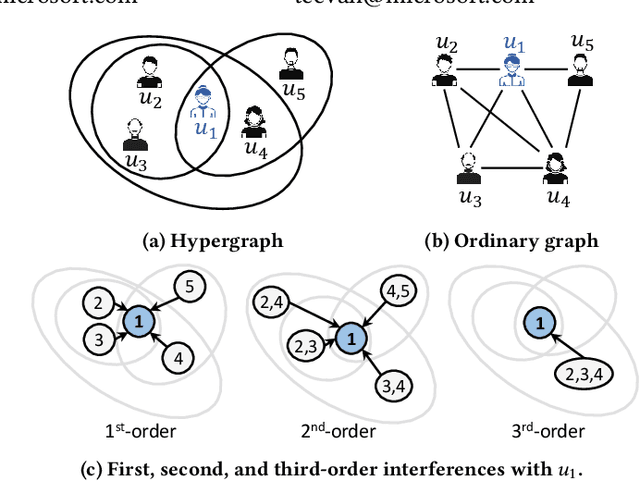
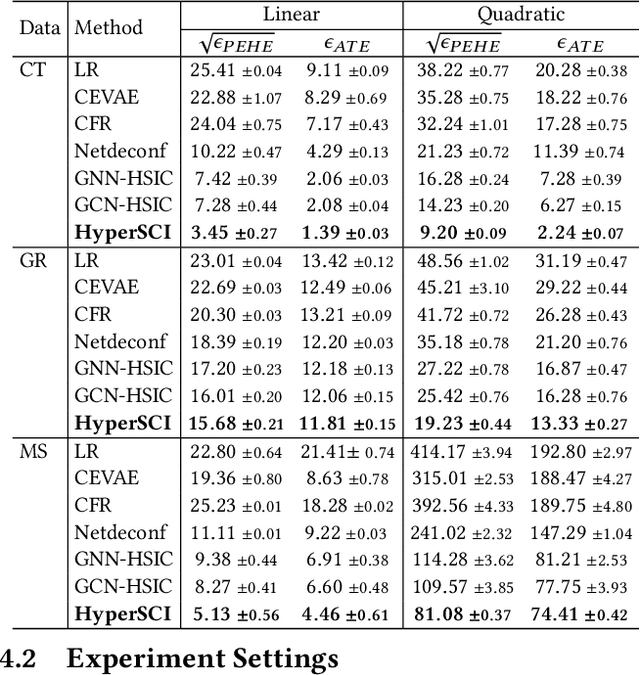


Hypergraphs provide an effective abstraction for modeling multi-way group interactions among nodes, where each hyperedge can connect any number of nodes. Different from most existing studies which leverage statistical dependencies, we study hypergraphs from the perspective of causality. Specifically, in this paper, we focus on the problem of individual treatment effect (ITE) estimation on hypergraphs, aiming to estimate how much an intervention (e.g., wearing face covering) would causally affect an outcome (e.g., COVID-19 infection) of each individual node. Existing works on ITE estimation either assume that the outcome on one individual should not be influenced by the treatment assignments on other individuals (i.e., no interference), or assume the interference only exists between pairs of connected individuals in an ordinary graph. We argue that these assumptions can be unrealistic on real-world hypergraphs, where higher-order interference can affect the ultimate ITE estimations due to the presence of group interactions. In this work, we investigate high-order interference modeling, and propose a new causality learning framework powered by hypergraph neural networks. Extensive experiments on real-world hypergraphs verify the superiority of our framework over existing baselines.
Lightweight Compositional Embeddings for Incremental Streaming Recommendation
Feb 04, 2022



Most work in graph-based recommender systems considers a {\em static} setting where all information about test nodes (i.e., users and items) is available upfront at training time. However, this static setting makes little sense for many real-world applications where data comes in continuously as a stream of new edges and nodes, and one has to update model predictions incrementally to reflect the latest state. To fully capitalize on the newly available data in the stream, recent graph-based recommendation models would need to be repeatedly retrained, which is infeasible in practice. In this paper, we study the graph-based streaming recommendation setting and propose a compositional recommendation model -- Lightweight Compositional Embedding (LCE) -- that supports incremental updates under low computational cost. Instead of learning explicit embeddings for the full set of nodes, LCE learns explicit embeddings for only a subset of nodes and represents the other nodes {\em implicitly}, through a composition function based on their interactions in the graph. This provides an effective, yet efficient, means to leverage streaming graph data when one node type (e.g., items) is more amenable to static representation. We conduct an extensive empirical study to compare LCE to a set of competitive baselines on three large-scale user-item recommendation datasets with interactions under a streaming setting. The results demonstrate the superior performance of LCE, showing that it achieves nearly skyline performance with significantly fewer parameters than alternative graph-based models.
Learning Fair Node Representations with Graph Counterfactual Fairness
Jan 10, 2022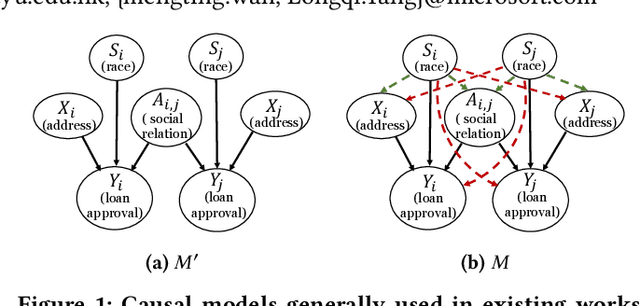
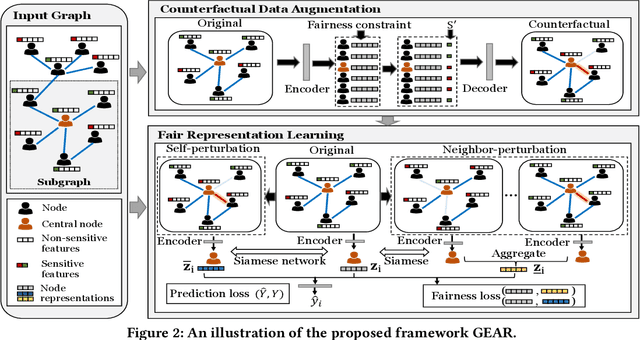
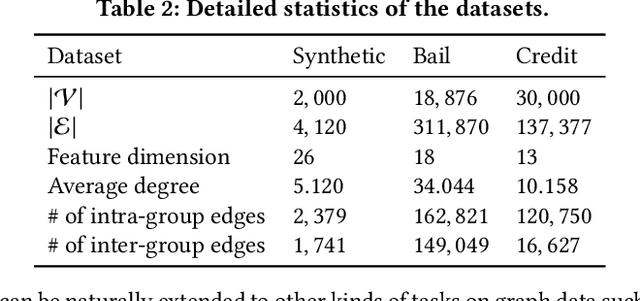
Fair machine learning aims to mitigate the biases of model predictions against certain subpopulations regarding sensitive attributes such as race and gender. Among the many existing fairness notions, counterfactual fairness measures the model fairness from a causal perspective by comparing the predictions of each individual from the original data and the counterfactuals. In counterfactuals, the sensitive attribute values of this individual had been modified. Recently, a few works extend counterfactual fairness to graph data, but most of them neglect the following facts that can lead to biases: 1) the sensitive attributes of each node's neighbors may causally affect the prediction w.r.t. this node; 2) the sensitive attributes may causally affect other features and the graph structure. To tackle these issues, in this paper, we propose a novel fairness notion - graph counterfactual fairness, which considers the biases led by the above facts. To learn node representations towards graph counterfactual fairness, we propose a novel framework based on counterfactual data augmentation. In this framework, we generate counterfactuals corresponding to perturbations on each node's and their neighbors' sensitive attributes. Then we enforce fairness by minimizing the discrepancy between the representations learned from the original graph and the counterfactuals for each node. Experiments on both synthetic and real-world graphs show that our framework outperforms the state-of-the-art baselines in graph counterfactual fairness, and also achieves comparable prediction performance.
Learning to Represent Human Motives for Goal-directed Web Browsing
Aug 07, 2021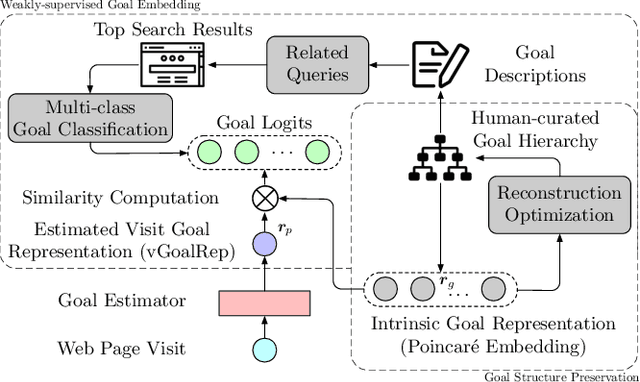
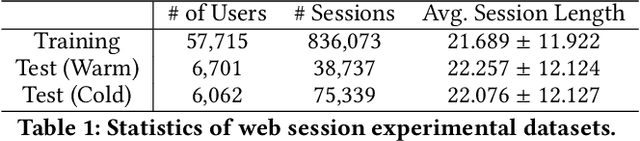
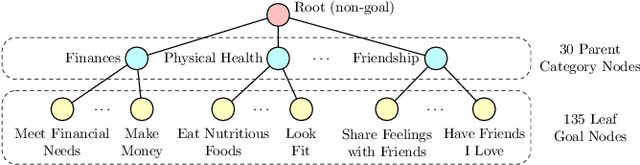
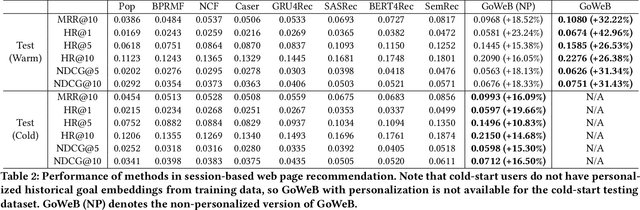
Motives or goals are recognized in psychology literature as the most fundamental drive that explains and predicts why people do what they do, including when they browse the web. Although providing enormous value, these higher-ordered goals are often unobserved, and little is known about how to leverage such goals to assist people's browsing activities. This paper proposes to take a new approach to address this problem, which is fulfilled through a novel neural framework, Goal-directed Web Browsing (GoWeB). We adopt a psychologically-sound taxonomy of higher-ordered goals and learn to build their representations in a structure-preserving manner. Then we incorporate the resulting representations for enhancing the experiences of common activities people perform on the web. Experiments on large-scale data from Microsoft Edge web browser show that GoWeB significantly outperforms competitive baselines for in-session web page recommendation, re-visitation classification, and goal-based web page grouping. A follow-up analysis further characterizes how the variety of human motives can affect the difference observed in human behavioral patterns.
Current Challenges and Future Directions in Podcast Information Access
Jun 17, 2021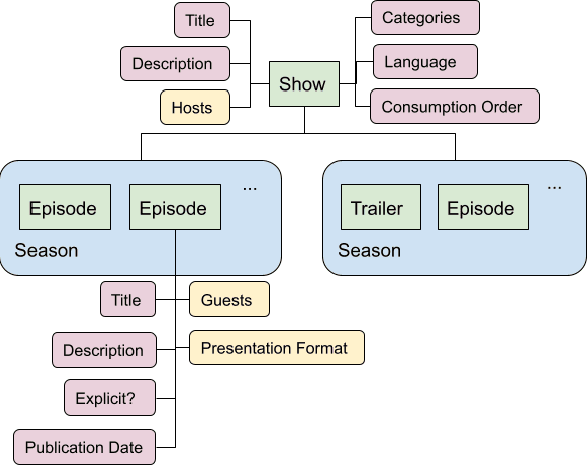
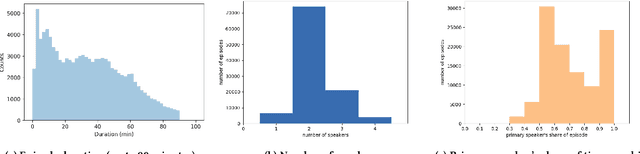
Podcasts are spoken documents across a wide-range of genres and styles, with growing listenership across the world, and a rapidly lowering barrier to entry for both listeners and creators. The great strides in search and recommendation in research and industry have yet to see impact in the podcast space, where recommendations are still largely driven by word of mouth. In this perspective paper, we highlight the many differences between podcasts and other media, and discuss our perspective on challenges and future research directions in the domain of podcast information access.
Personal Productivity and Well-being -- Chapter 2 of the 2021 New Future of Work Report
Mar 03, 2021We now turn to understanding the impact that COVID-19 had on the personal productivity and well-being of information workers as their work practices were impacted by remote work. This chapter overviews people's productivity, satisfaction, and work patterns, and shows that the challenges and benefits of remote work are closely linked. Looking forward, the infrastructure surrounding work will need to evolve to help people adapt to the challenges of remote and hybrid work.