 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation Contrastive Decoding: Improving LLMs Reasoning with Contrastive Decoding and Distillation
Feb 21, 2024We propose a straightforward approach called Distillation Contrastive Decoding (DCD) to enhance the reasoning capabilities of Large Language Models (LLMs) during inference. In contrast to previous approaches that relied on smaller amateur models or analysis of hidden state differences, DCD employs Contrastive Chain-of-thought Prompting and advanced distillation techniques, including Dropout and Quantization. This approach effectively addresses the limitations of Contrastive Decoding (CD), which typically requires both an expert and an amateur model, thus increasing computational resource demands. By integrating contrastive prompts with distillation, DCD obviates the need for an amateur model and reduces memory usage. Our evaluations demonstrate that DCD significantly enhances LLM performance across a range of reasoning benchmarks, surpassing both CD and existing methods in the GSM8K and StrategyQA datasets.
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Feb 06, 2024Automated red teaming holds substantial promise for uncovering and mitigating the risks associated with the malicious use of large language models (LLMs), yet the field lacks a standardized evaluation framework to rigorously assess new methods. To address this issue, we introduce HarmBench, a standardized evaluation framework for automated red teaming. We identify several desirable properties previously unaccounted for in red teaming evaluations and systematically design HarmBench to meet these criteria. Using HarmBench, we conduct a large-scale comparison of 18 red teaming methods and 33 target LLMs and defenses, yielding novel insights. We also introduce a highly efficient adversarial training method that greatly enhances LLM robustness across a wide range of attacks, demonstrating how HarmBench enables codevelopment of attacks and defenses. We open source HarmBench at https://github.com/centerforaisafety/HarmBench.
Representation Engineering: A Top-Down Approach to AI Transparency
Oct 10, 2023



In this paper, we identify and characterize the emerging area of representation engineering (RepE), an approach to enhancing the transparency of AI systems that draws on insights from cognitive neuroscience. RepE places population-level representations, rather than neurons or circuits, at the center of analysis, equipping us with novel methods for monitoring and manipulating high-level cognitive phenomena in deep neural networks (DNNs). We provide baselines and an initial analysis of RepE techniques, showing that they offer simple yet effective solutions for improving our understanding and control of large language models. We showcase how these methods can provide traction on a wide range of safety-relevant problems, including honesty, harmlessness, power-seeking, and more, demonstrating the promise of top-down transparency research. We hope that this work catalyzes further exploration of RepE and fosters advancements in the transparency and safety of AI systems.
Prompting Multilingual Large Language Models to Generate Code-Mixed Texts: The Case of South East Asian Languages
Mar 30, 2023



While code-mixing is a common linguistic practice in many parts of the world, collecting high-quality and low-cost code-mixed data remains a challenge for natural language processing (NLP) research. The proliferation of Large Language Models (LLMs) in recent times compels one to ask: can these systems be used for data generation? In this article, we explore prompting multilingual LLMs in a zero-shot manner to create code-mixed data for five languages in South East Asia (SEA) -- Indonesian, Malay, Chinese, Tagalog, Vietnamese, as well as the creole language Singlish. We find that ChatGPT shows the most potential, capable of producing code-mixed text 68% of the time when the term "code-mixing" is explicitly defined. Moreover, both ChatGPT's and InstructGPT's (davinci-003) performances in generating Singlish texts are noteworthy, averaging a 96% success rate across a variety of prompts. Their code-mixing proficiency, however, is dampened by word choice errors that lead to semantic inaccuracies. Other multilingual models such as BLOOMZ and Flan-T5-XXL are unable to produce code-mixed texts altogether. By highlighting the limited promises of LLMs in a specific form of low-resource data generation, we call for a measured approach when applying similar techniques to other data-scarce NLP contexts.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023



As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
MTet: Multi-domain Translation for English and Vietnamese
Oct 19, 2022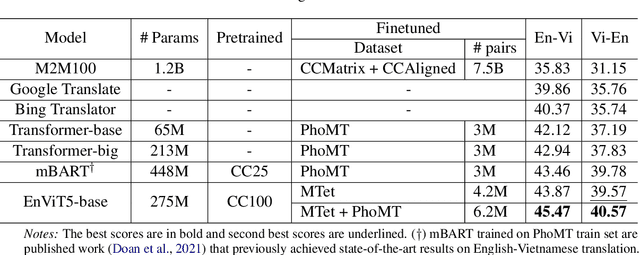
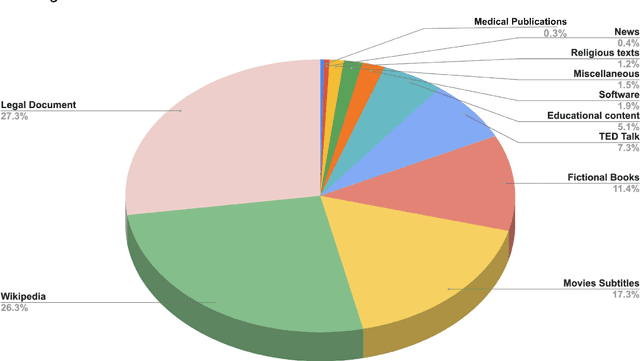

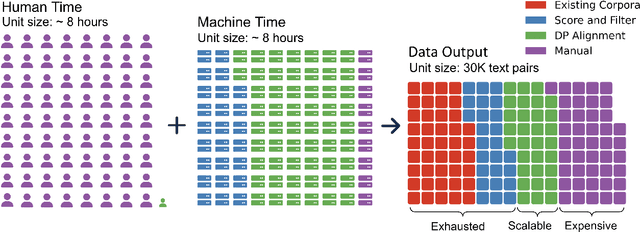
We introduce MTet, the largest publicly available parallel corpus for English-Vietnamese translation. MTet consists of 4.2M high-quality training sentence pairs and a multi-domain test set refined by the Vietnamese research community. Combining with previous works on English-Vietnamese translation, we grow the existing parallel dataset to 6.2M sentence pairs. We also release the first pretrained model EnViT5 for English and Vietnamese languages. Combining both resources, our model significantly outperforms previous state-of-the-art results by up to 2 points in translation BLEU score, while being 1.6 times smaller.
Enriching Biomedical Knowledge for Low-resource Language Through Translation
Oct 11, 2022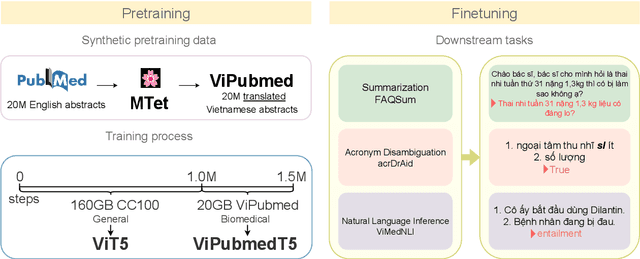
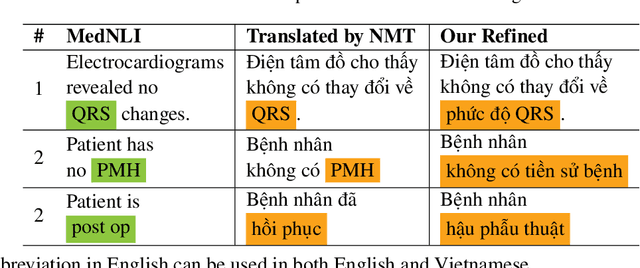

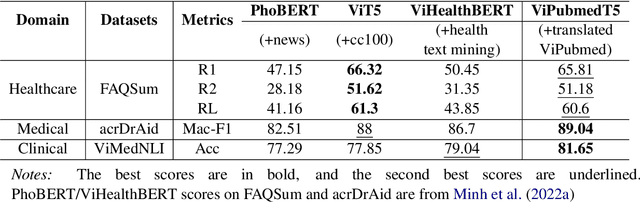
Biomedical data and benchmarks are highly valuable yet very limited in low-resource languages other than English such as Vietnamese. In this paper, we make use of a state-of-the-art translation model in English-Vietnamese to translate and produce both pretrained as well as supervised data in the biomedical domains. Thanks to such large-scale translation, we introduce ViPubmedT5, a pretrained Encoder-Decoder Transformer model trained on 20 million translated abstracts from the high-quality public PubMed corpus. ViPubMedT5 demonstrates state-of-the-art results on two different biomedical benchmarks in summarization and acronym disambiguation. Further, we release ViMedNLI - a new NLP task in Vietnamese translated from MedNLI using the recently public En-vi translation model and carefully refined by human experts, with evaluations of existing methods against ViPubmedT5.
ViT5: Pretrained Text-to-Text Transformer for Vietnamese Language Generation
May 13, 2022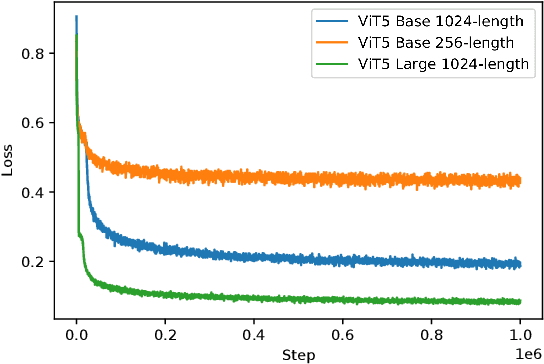

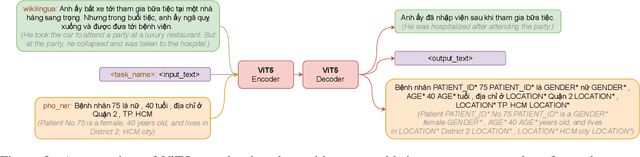
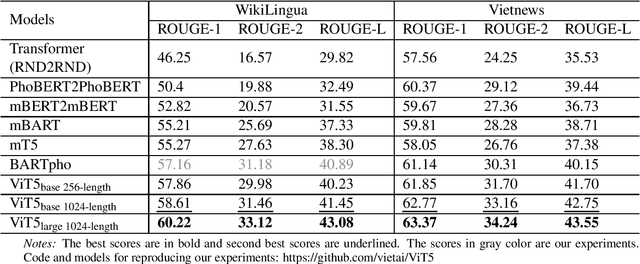
We present ViT5, a pretrained Transformer-based encoder-decoder model for the Vietnamese language. With T5-style self-supervised pretraining, ViT5 is trained on a large corpus of high-quality and diverse Vietnamese texts. We benchmark ViT5 on two downstream text generation tasks, Abstractive Text Summarization and Named Entity Recognition. Although Abstractive Text Summarization has been widely studied for the English language thanks to its rich and large source of data, there has been minimal research into the same task in Vietnamese, a much lower resource language. In this work, we perform exhaustive experiments on both Vietnamese Abstractive Summarization and Named Entity Recognition, validating the performance of ViT5 against many other pretrained Transformer-based encoder-decoder models. Our experiments show that ViT5 significantly outperforms existing models and achieves state-of-the-art results on Vietnamese Text Summarization. On the task of Named Entity Recognition, ViT5 is competitive against previous best results from pretrained encoder-based Transformer models. Further analysis shows the importance of context length during the self-supervised pretraining on downstream performance across different settings.
VieSum: How Robust Are Transformer-based Models on Vietnamese Summarization?
Oct 08, 2021
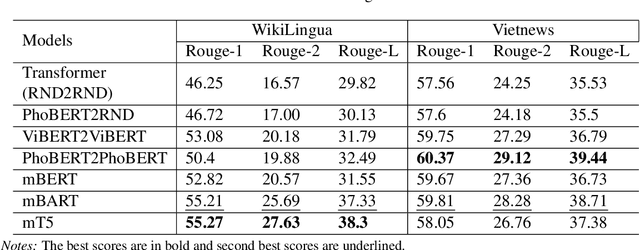
Text summarization is a challenging task within natural language processing that involves text generation from lengthy input sequences. While this task has been widely studied in English, there is very limited research on summarization for Vietnamese text. In this paper, we investigate the robustness of transformer-based encoder-decoder architectures for Vietnamese abstractive summarization. Leveraging transfer learning and self-supervised learning, we validate the performance of the methods on two Vietnamese datasets.