 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitionCapturerPro: Towards High-Fidelity Visual Decoding from EEG/MEG via Multi-modal Information and Asymmetric Alignment
Mar 13, 2026Visual stimuli reconstruction from EEG remains challenging due to fidelity loss and representation shift. We propose CognitionCapturerPro, an enhanced framework that integrates EEG with multi-modal priors (images, text, depth, and edges) via collaborative training. Our core contributions include an uncertainty-weighted similarity scoring mechanism to quantify modality-specific fidelity and a fusion encoder for integrating shared representations. By employing a simplified alignment module and a pre-trained diffusion model, our method significantly outperforms the original CognitionCapturer on the THINGS-EEG dataset, improving Top-1 and Top-5 retrieval accuracy by 25.9% and 10.6%, respectively. Code is available at: https://github.com/XiaoZhangYES/CognitionCapturerPro.
Learning-based 3D Occupancy Prediction for Autonomous Navigation in Occluded Environments
Nov 08, 2020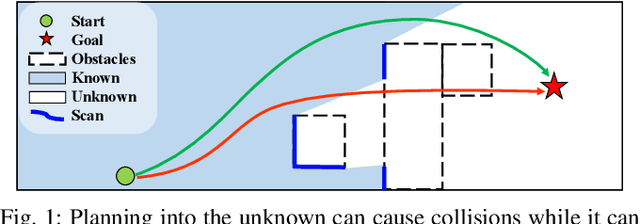
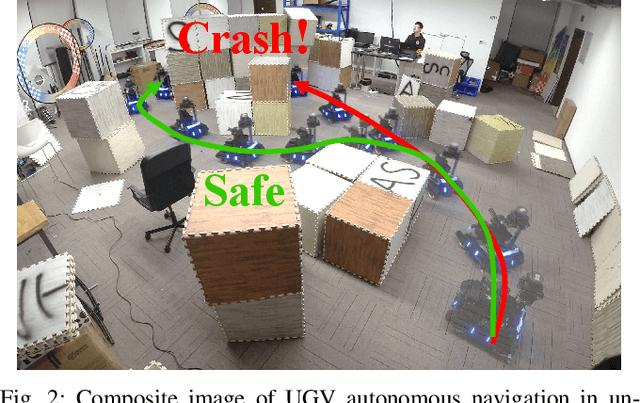

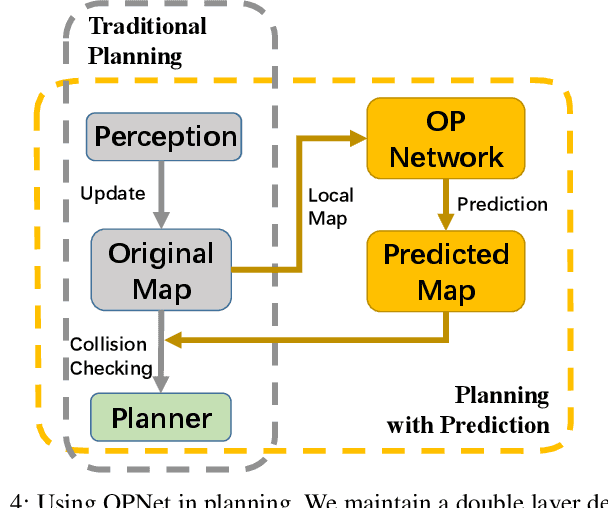
In autonomous navigation of mobile robots, sensors suffer from massive occlusion in cluttered environments, leaving significant amount of space unknown during planning. In practice, treating the unknown space in optimistic or pessimistic ways both set limitations on planning performance, thus aggressiveness and safety cannot be satisfied at the same time. However, humans can infer the exact shape of the obstacles from only partial observation and generate non-conservative trajectories that avoid possible collisions in occluded space. Mimicking human behavior, in this paper, we propose a method based on deep neural network to predict occupancy distribution of unknown space reliably. Specifically, the proposed method utilizes contextual information of environments and learns from prior knowledge to predict obstacle distributions in occluded space. We use unlabeled and no-ground-truth data to train our network and successfully apply it to real-time navigation in unseen environments without any refinement. Results show that our method leverages the performance of a kinodynamic planner by improving security with no reduction of speed in clustered environments.