 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS3: Efficient Online Capability Synergy for Two-Tower Recommendation
Apr 21, 2026To balance effectiveness and efficiency in recommender systems, multi-stage pipelines commonly use lightweight two-tower models for large-scale candidate retrieval. However, the isolated two-tower architecture restricts representation capacity, embedding-space alignment, and cross-feature interactions. Existing solutions such as late interaction and knowledge distillation can mitigate these issues, but often increase latency or are difficult to deploy in online learning settings. We propose Capability Synergy (CS3), an efficient online framework that strengthens two-tower retrievers while preserving real-time constraints. CS3 introduces three mechanisms: (1) Cycle-Adaptive Structure for self-revision via adaptive feature denoising within each tower; (2) Cross-Tower Synchronization to improve alignment through lightweight mutual awareness between towers; and (3) Cascade-Model Sharing to enhance cross-stage consistency by reusing knowledge from downstream models. CS3 is plug-and-play with diverse two-tower backbones and compatible with online learning. Experiments on three public datasets show consistent gains over strong baselines, and deployment in a largescale advertising system yields up to 8.36% revenue improvement across three scenarios while maintaining ms-level latency.
FlexServe: A Fast and Secure LLM Serving System for Mobile Devices with Flexible Resource Isolation
Mar 10, 2026Device-side Large Language Models (LLMs) have witnessed explosive growth, offering higher privacy and availability compared to cloud-side LLMs. During LLM inference, both model weights and user data are valuable, and attackers may even compromise the OS kernel to steal them. ARM TrustZone is the de facto hardware-based isolation technology on mobile devices, used to protect sensitive applications from a compromised OS. However, protecting LLM inference with TrustZone incurs significant overhead due to its inflexible isolation of memory and the NPU. To address these challenges, this paper introduces FlexServe, a fast and secure LLM serving system for mobile devices. It first introduces a Flexible Resource Isolation mechanism to construct Flexible Secure Memory (Flex-Mem) and Flexible Secure NPU (Flex-NPU). Both memory pages and the NPU can be efficiently switched between unprotected and protected modes. Based on these mechanisms, FlexServe designs a fast and secure LLM inference framework within TrustZone's secure world. The LLM-Aware Memory Management and Secure Inference Pipeline are introduced to accelerate inference. A Multi-Model Scheduler is proposed to optimize multi-model workflows. We implement a prototype of FlexServe and compare it with two TrustZone-based strawman designs. The results show that FlexServe achieves an average $10.05\times$ speedup in Time to First Token (TTFT) compared to the strawman, and an average $2.44\times$ TTFT speedup compared to an optimized strawman with pipeline and secure NPU enabled. For multi-model agent workflows, the end-to-end speedup is up to $24.30\times$ and $4.05\times$ compared to the strawman and optimized strawman, respectively.
Generative Recommendation for Large-Scale Advertising
Feb 26, 2026Generative recommendation has recently attracted widespread attention in industry due to its potential for scaling and stronger model capacity. However, deploying real-time generative recommendation in large-scale advertising requires designs beyond large-language-model (LLM)-style training and serving recipes. We present a production-oriented generative recommender co-designed across architecture, learning, and serving, named GR4AD (Generative Recommendation for ADdvertising). As for tokenization, GR4AD proposes UA-SID (Unified Advertisement Semantic ID) to capture complicated business information. Furthermore, GR4AD introduces LazyAR, a lazy autoregressive decoder that relaxes layer-wise dependencies for short, multi-candidate generation, preserving effectiveness while reducing inference cost, which facilitates scaling under fixed serving budgets. To align optimization with business value, GR4AD employs VSL (Value-Aware Supervised Learning) and proposes RSPO (Ranking-Guided Softmax Preference Optimization), a ranking-aware, list-wise reinforcement learning algorithm that optimizes value-based rewards under list-level metrics for continual online updates. For online inference, we further propose dynamic beam serving, which adapts beam width across generation levels and online load to control compute. Large-scale online A/B tests show up to 4.2% ad revenue improvement over an existing DLRM-based stack, with consistent gains from both model scaling and inference-time scaling. GR4AD has been fully deployed in Kuaishou advertising system with over 400 million users and achieves high-throughput real-time serving.
An Effective Way for Cross-Market Recommendation with Hybrid Pre-Ranking and Ranking Models
Mar 02, 2022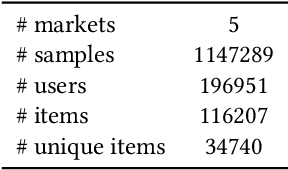
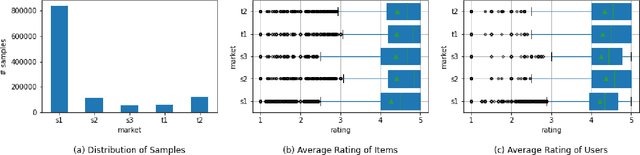
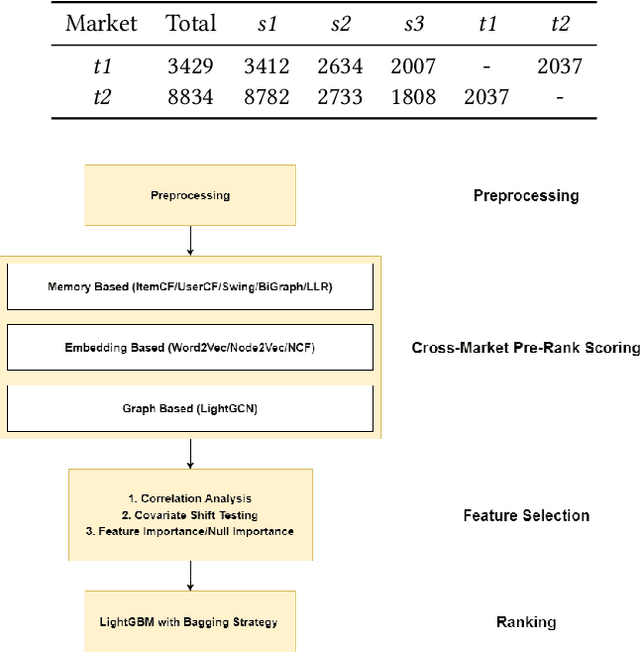
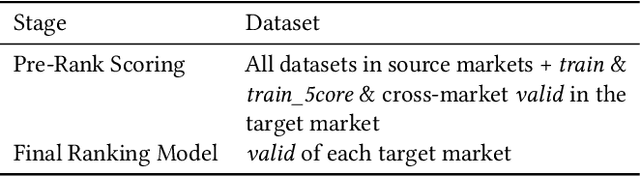
The Cross-Market Recommendation task of WSDM CUP 2022 is about finding solutions to improve individual recommendation systems in resource-scarce target markets by leveraging data from similar high-resource source markets. Finally, our team OPDAI won the first place with NDCG@10 score of 0.6773 on the leaderboard. Our solution to this task will be detailed in this paper. To better transform information from source markets to target markets, we adopt two stages of ranking. In pre-ranking stage, we adopt diverse pre-ranking methods or models to do feature generation. After elaborate feature analysis and feature selection, we train LightGBM with 10-fold bagging to do the final ranking.