 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Music: A Survey
Aug 27, 2024



In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Instruct-MusicGen: Unlocking Text-to-Music Editing for Music Language Models via Instruction Tuning
May 29, 2024



Recent advances in text-to-music editing, which employ text queries to modify music (e.g.\ by changing its style or adjusting instrumental components), present unique challenges and opportunities for AI-assisted music creation. Previous approaches in this domain have been constrained by the necessity to train specific editing models from scratch, which is both resource-intensive and inefficient; other research uses large language models to predict edited music, resulting in imprecise audio reconstruction. To Combine the strengths and address these limitations, we introduce Instruct-MusicGen, a novel approach that finetunes a pretrained MusicGen model to efficiently follow editing instructions such as adding, removing, or separating stems. Our approach involves a modification of the original MusicGen architecture by incorporating a text fusion module and an audio fusion module, which allow the model to process instruction texts and audio inputs concurrently and yield the desired edited music. Remarkably, Instruct-MusicGen only introduces 8% new parameters to the original MusicGen model and only trains for 5K steps, yet it achieves superior performance across all tasks compared to existing baselines, and demonstrates performance comparable to the models trained for specific tasks. This advancement not only enhances the efficiency of text-to-music editing but also broadens the applicability of music language models in dynamic music production environments.
Arrange, Inpaint, and Refine: Steerable Long-term Music Audio Generation and Editing via Content-based Controls
Feb 14, 2024



Controllable music generation plays a vital role in human-AI music co-creation. While Large Language Models (LLMs) have shown promise in generating high-quality music, their focus on autoregressive generation limits their utility in music editing tasks. To bridge this gap, we introduce a novel Parameter-Efficient Fine-Tuning (PEFT) method. This approach enables autoregressive language models to seamlessly address music inpainting tasks. Additionally, our PEFT method integrates frame-level content-based controls, facilitating track-conditioned music refinement and score-conditioned music arrangement. We apply this method to fine-tune MusicGen, a leading autoregressive music generation model. Our experiments demonstrate promising results across multiple music editing tasks, offering more flexible controls for future AI-driven music editing tools. A demo page\footnote{\url{https://kikyo-16.github.io/AIR/}.} showcasing our work and source codes\footnote{\url{https://github.com/Kikyo-16/airgen}.} are available online.
Content-based Controls For Music Large Language Modeling
Oct 26, 2023



Recent years have witnessed a rapid growth of large-scale language models in the domain of music audio. Such models enable end-to-end generation of higher-quality music, and some allow conditioned generation using text descriptions. However, the control power of text controls on music is intrinsically limited, as they can only describe music indirectly through meta-data (such as singers and instruments) or high-level representations (such as genre and emotion). We aim to further equip the models with direct and content-based controls on innate music languages such as pitch, chords and drum track. To this end, we contribute Coco-Mulla, a content-based control method for music large language modeling. It uses a parameter-efficient fine-tuning (PEFT) method tailored for Transformer-based audio models. Experiments show that our approach achieved high-quality music generation with low-resource semi-supervised learning, tuning with less than 4% parameters compared to the original model and training on a small dataset with fewer than 300 songs. Moreover, our approach enables effective content-based controls, and we illustrate the control power via chords and rhythms, two of the most salient features of music audio. Furthermore, we show that by combining content-based controls and text descriptions, our system achieves flexible music variation generation and style transfer. Our source codes and demos are available online.
A Unified Model for Zero-shot Music Source Separation, Transcription and Synthesis
Aug 07, 2021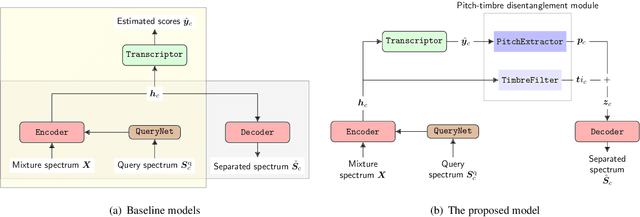

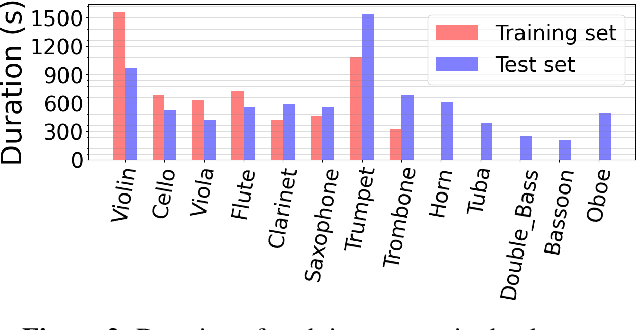
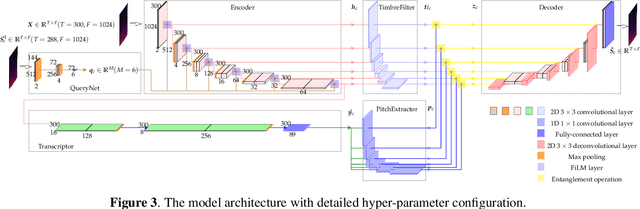
We propose a unified model for three inter-related tasks: 1) to \textit{separate} individual sound sources from a mixed music audio, 2) to \textit{transcribe} each sound source to MIDI notes, and 3) to\textit{ synthesize} new pieces based on the timbre of separated sources. The model is inspired by the fact that when humans listen to music, our minds can not only separate the sounds of different instruments, but also at the same time perceive high-level representations such as score and timbre. To mirror such capability computationally, we designed a pitch-timbre disentanglement module based on a popular encoder-decoder neural architecture for source separation. The key inductive biases are vector-quantization for pitch representation and pitch-transformation invariant for timbre representation. In addition, we adopted a query-by-example method to achieve \textit{zero-shot} learning, i.e., the model is capable of doing source separation, transcription, and synthesis for \textit{unseen} instruments. The current design focuses on audio mixtures of two monophonic instruments. Experimental results show that our model outperforms existing multi-task baselines, and the transcribed score serves as a powerful auxiliary for separation tasks.
Guided Learning Convolution System for DCASE 2019 Task 4
Sep 11, 2019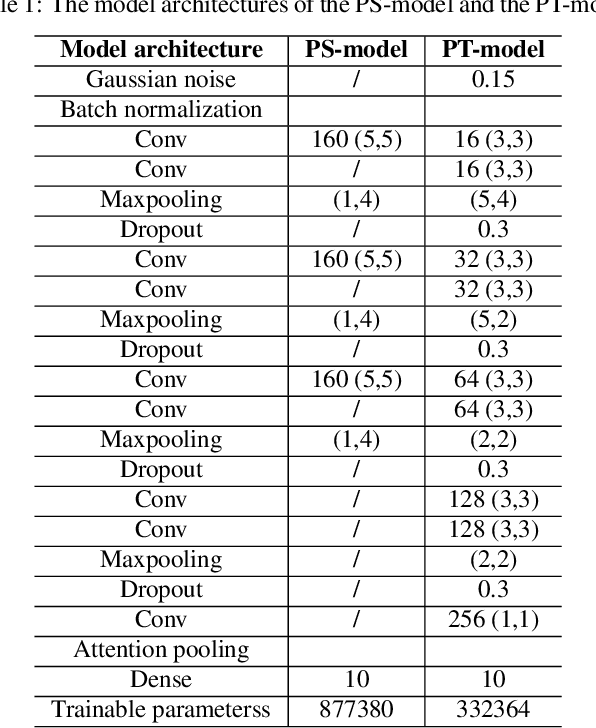
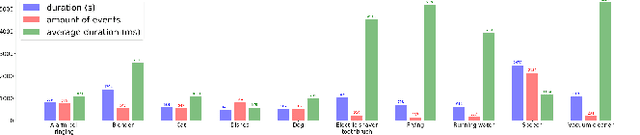
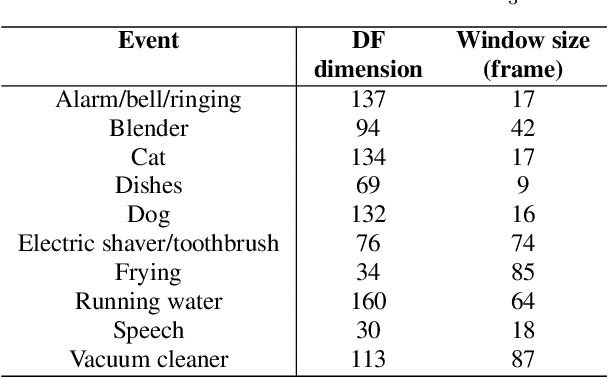
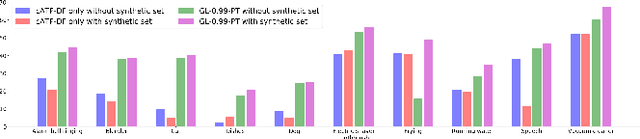
In this paper, we describe in detail the system we submitted to DCASE2019 task 4: sound event detection (SED) in domestic environments. We employ a convolutional neural network (CNN) with an embedding-level attention pooling module to solve it. By considering the interference caused by the co-occurrence of multiple events in the unbalanced dataset, we utilize the disentangled feature to raise the performance of the model. To take advantage of the unlabeled data, we adopt Guided Learning for semi-supervised learning. A group of median filters with adaptive window sizes is utilized in the post-processing of output probabilities of the model. We also analyze the effect of the synthetic data on the performance of the model and finally achieve an event-based F-measure of 45.43% on the validation set and an event-based F-measure of 42.7% on the test set. The system we submitted to the challenge achieves the best performance compared to those of other participates.
Guided Learning for the combination of weakly-supervised and semi-supervised learning
Jul 16, 2019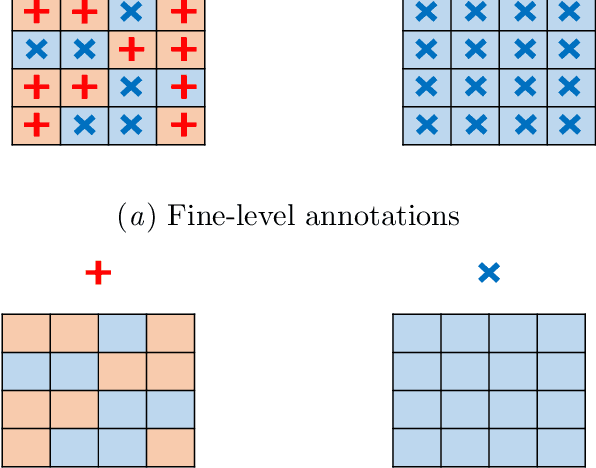
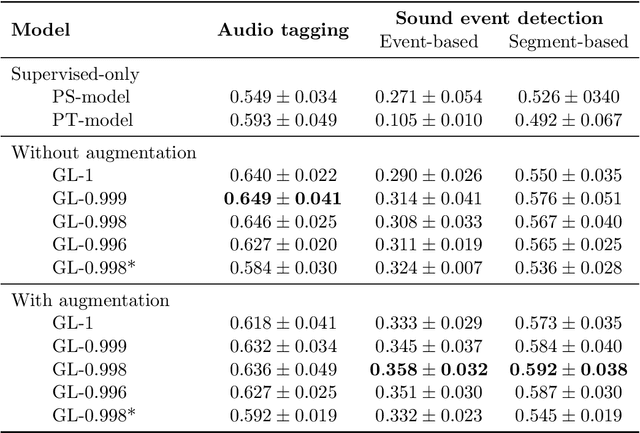
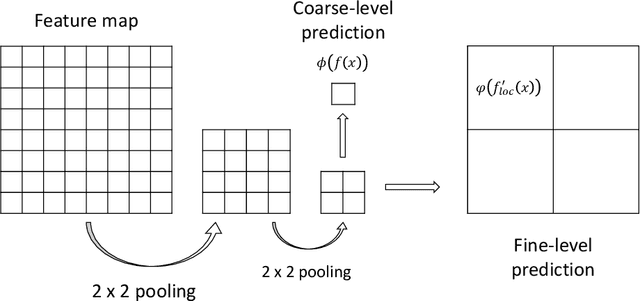
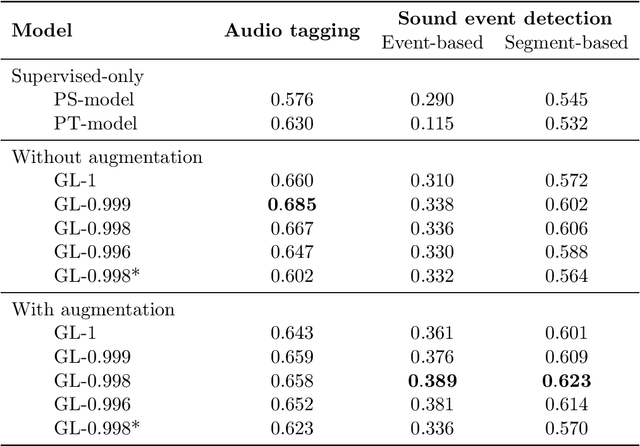
We propose a simple but efficient method to combine semi-supervised learning with weakly-supervised learning for deep neural networks. Weakly-supervised learning is to solve the task which requires fine-level prediction with only coarse-level annotations available. Designing deep neural networks for weakly-supervised learning is always accompanied by a trade-off between fine-level information detection performance and coarse-level classification accuracy. While combining weakly-supervised learning with semi-supervised learning using unlabeled data, in contrast to seeking for this trade-off, we design two different models for different targets. One merely pursues finer information detection performance as the final target, while another one is more professional in achieving higher coarse-level classification accuracy so that it is regarded as a more professional teacher to teach the former model using unlabeled data. We present an end-to-end semi-supervised learning process termed Guided Learning for these two different models to improve the training efficiency. Our approach outperforms the first place result on DCASE2018 Task 4 which employs Mean Teacher with a well-design CRNN network from 32.4% to 38.9%, achieving state-of-the-art performance.
Disentangled Feature for Weakly Supervised Multi-class Sound Event Detection
Jun 03, 2019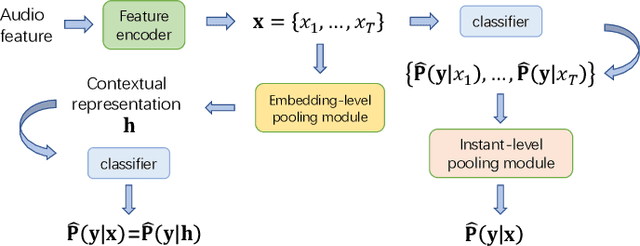
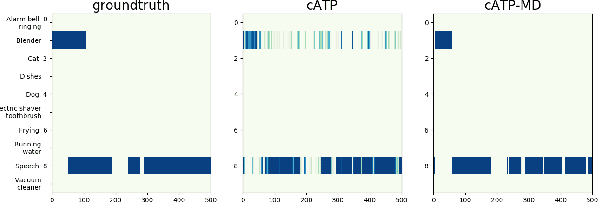
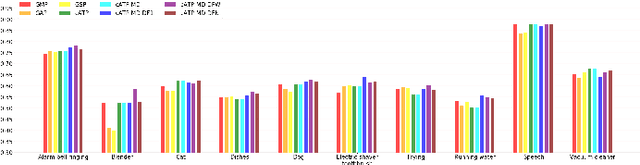
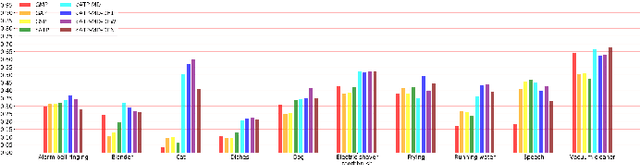
We propose a disentangled feature for weakly supervised multiclass sound event detection (SED), which helps ameliorate the performance and the training efficiency of class-wise attention based detection system by the introduction of more class-wise prior information as well as the network redundancy weight reduction. In this paper, we approach SED as a multiple instance learning (MIL) problem and utilize a neural network framework with class-wise attention pooling (cATP) module to solve it. Aiming at making finer detection even if there is only a small number of clips with less co-occurrence of the categories available in the training set, we optimize the high-level feature space of cATP-MIL by disentangling it based on class-wise identifiable information in the training set and obtain multiple different subspaces. Experiments show that our approach achieves competitive performance on Task4 of the DCASE2018 challenge.