 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversifying Database Activity Monitoring with Bandits
Oct 23, 2019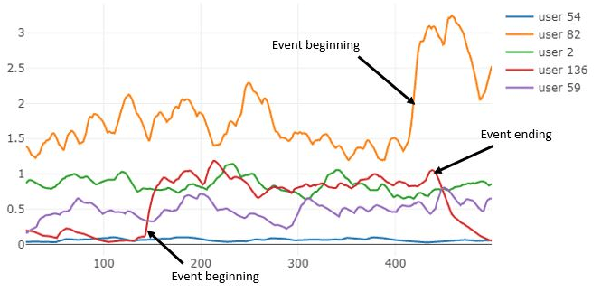
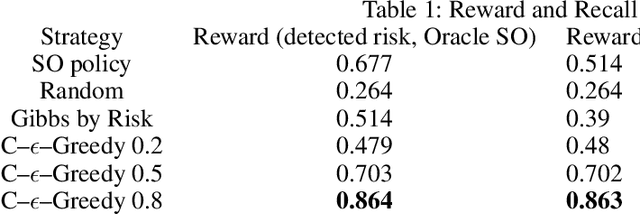
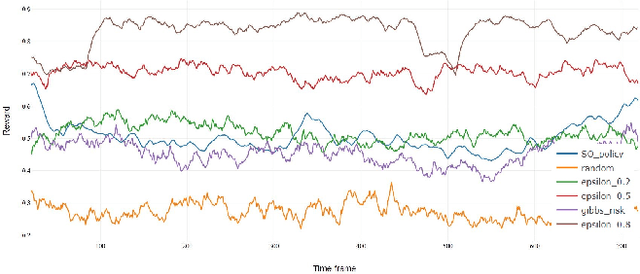
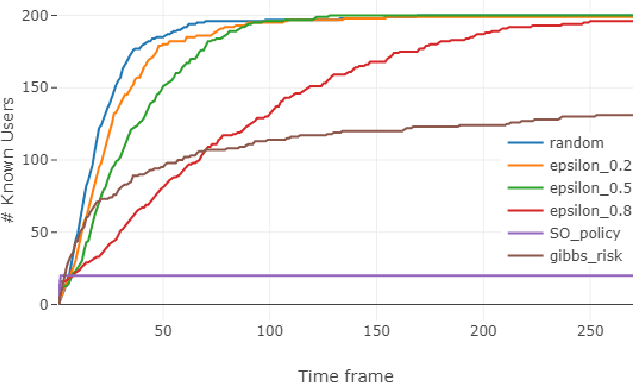
Database activity monitoring (DAM) systems are commonly used by organizations to protect the organizational data, knowledge and intellectual properties. In order to protect organizations database DAM systems have two main roles, monitoring (documenting activity) and alerting to anomalous activity. Due to high-velocity streams and operating costs, such systems are restricted to examining only a sample of the activity. Current solutions use policies, manually crafted by experts, to decide which transactions to monitor and log. This limits the diversity of the data collected. Bandit algorithms, which use reward functions as the basis for optimization while adding diversity to the recommended set, have gained increased attention in recommendation systems for improving diversity. In this work, we redefine the data sampling problem as a special case of the multi-armed bandit (MAB) problem and present a novel algorithm, which combines expert knowledge with random exploration. We analyze the effect of diversity on coverage and downstream event detection tasks using a simulated dataset. In doing so, we find that adding diversity to the sampling using the bandit-based approach works well for this task and maximizing population coverage without decreasing the quality in terms of issuing alerts about events.
Deep Context-Aware Recommender System Utilizing Sequential Latent Context
Sep 09, 2019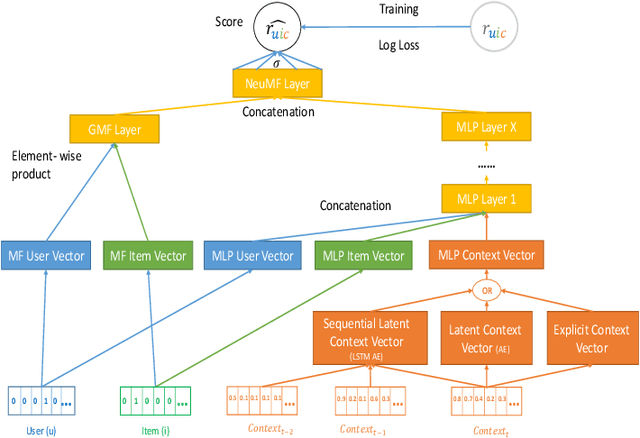

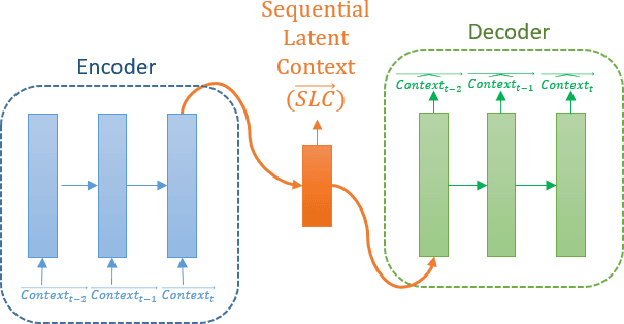
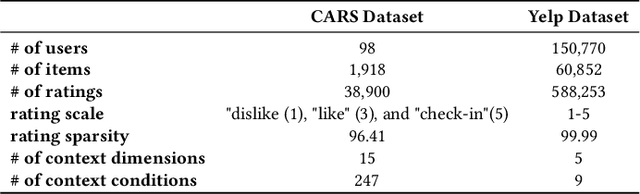
Context-aware recommender systems (CARSs) apply sensing and analysis of user context in order to provide personalized services. Adding context to a recommendation model is challenging, since the addition of context may increases both the dimensionality and sparsity of the model. Recent research has shown that modeling contextual information as a latent vector may address the sparsity and dimensionality challenges. We suggest a new latent modeling of sequential context by generating sequences of contextual information and reducing their contextual space to a compressed latent space.We train a long short-term memory (LSTM) encoder-decoder network on sequences of contextual information and extract sequential latent context from the hidden layer of the network in order to represent a compressed representation of sequential data. We propose new context-aware recommendation models that extend the neural collaborative filtering approach and learn nonlinear interactions between latent features of users, items, and contexts which take into account the sequential latent context representation as part of the recommendation process. We deployed our approach using two context-aware datasets with different context dimensions. Empirical analysis of our results validates that our proposed sequential latent context-aware model (SLCM), surpasses state of the art CARS models.
Assessing the Quality of Scientific Papers
Aug 12, 2019
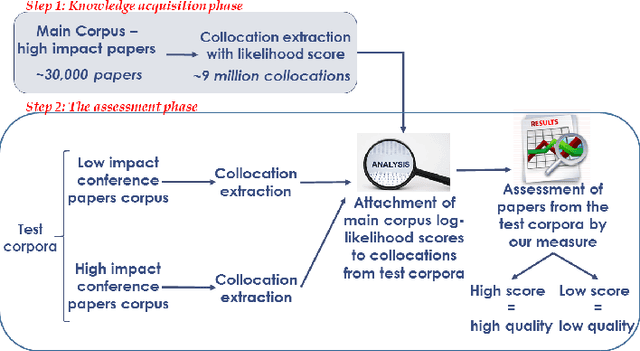

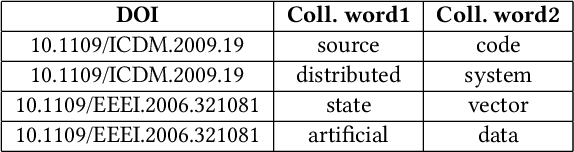
A multitude of factors are responsible for the overall quality of scientific papers, including readability, linguistic quality, fluency,semantic complexity, and of course domain-specific technical factors. These factors vary from one field of study to another. In this paper, we propose a measure and method for assessing the overall quality of the scientific papers in a particular field of study. We evaluate our method in the computer science domain, but it can be applied to other technical and scientific fields.Our method is based on the corpus linguistics technique. This technique enables the extraction of required information and knowledge associated with a specific domain. For this purpose, we have created a large corpus, consisting of papers from very high impact conferences. First, we analyze this corpus in order to extract rich domain-specific terminology and knowledge. Then we use the acquired knowledge to estimate the quality of scientific papers by applying our proposed measure. We examine our measure on high and low scientific impact test corpora. Our results show a significant difference in the measure scores of the high and low impact test corpora. Second, we develop a classifier based on our proposed measure and compare it to the baseline classifier. Our results show that the classifier based on our measure over-performed the baseline classifier. Based on the presented results the proposed measure and the technique can be used for automated assessment of scientific papers.
New Item Consumption Prediction Using Deep Learning
May 12, 2019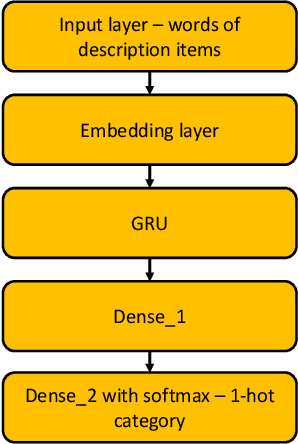
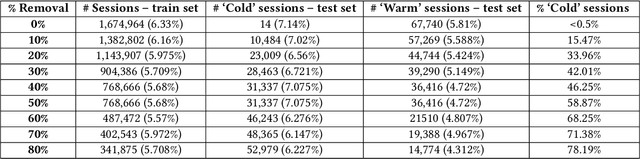
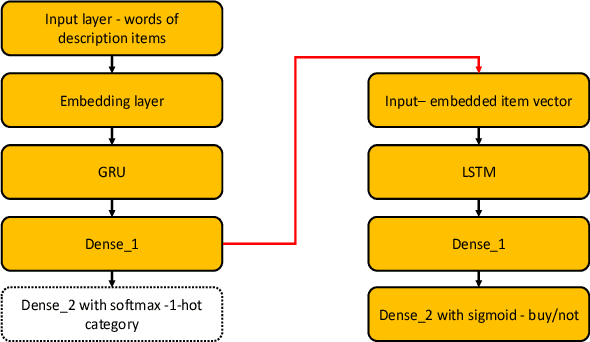
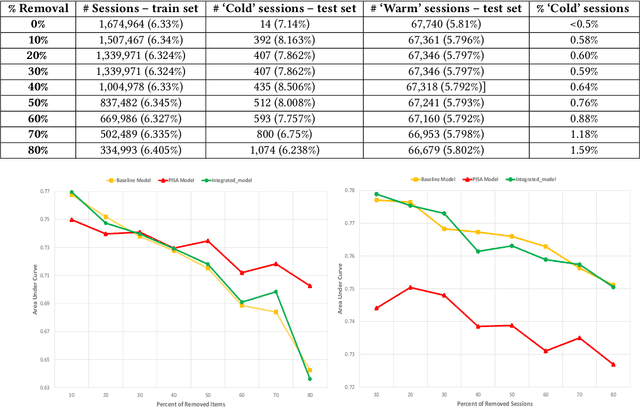
Recommendation systems have become ubiquitous in today's online world and are an integral part of practically every e-commerce platform. While traditional recommender systems use customer history, this approach is not feasible in 'cold start' scenarios. Such scenarios include the need to produce recommendations for new or unregistered users and the introduction of new items. In this study, we present the Purchase Intent Session-bAsed (PISA) algorithm, a content-based algorithm for predicting the purchase intent for cold start session-based scenarios. Our approach employs deep learning techniques both for modeling the content and purchase intent prediction. Our experiments show that PISA outperforms a well-known deep learning baseline when new items are introduced. In addition, while content-based approaches often fail to perform well in highly imbalanced datasets, our approach successfully handles such cases. Finally, our experiments show that combining PISA with the baseline in non-cold start scenarios further improves performance.
Semantic Comparison of State-of-the-Art Deep Learning Methods for Image Multi-Label Classification
Apr 05, 2019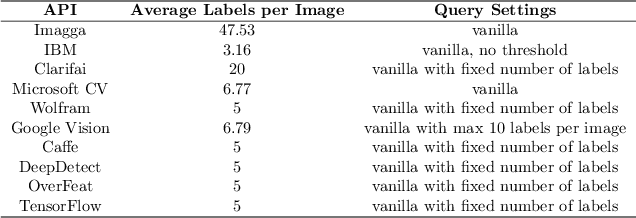
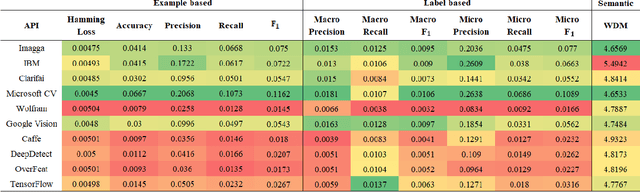
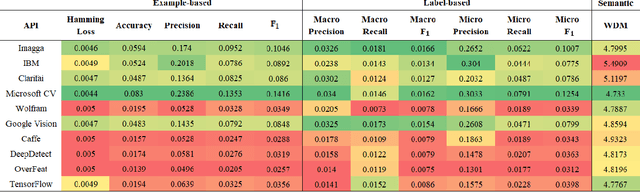
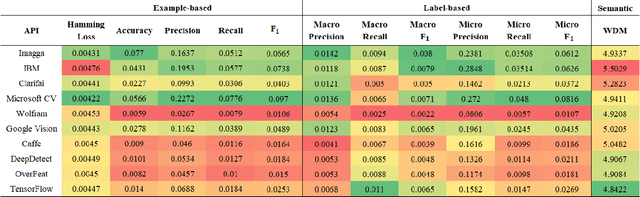
Image understanding relies heavily on accurate multi-label classification. In recent years deep learning (DL) algorithms have become very successful tools for multi-label classification of image objects. With these set of tools, various implementations of DL algorithms have been released for the public use in the form of application programming interfaces (API). In this study, we evaluate and compare 10 of the most prominent publicly available APIs in a best-of-breed challenge. The evaluation is performed on the Visual Genome labeling benchmark dataset using 12 well-recognized similarity metrics. In addition, for the first time in this kind of comparison, we use a semantic similarity metric to evaluate the semantic similarity performance of these APIs. In this evaluation, Microsoft's Computer Vision, TensorFlow, Imagga, and IBM's Visual Recognition showed better performance than the other APIs. Furthermore, the new semantic similarity metric allowed deeper insights for comparison.
Online Budgeted Learning for Classifier Induction
Mar 13, 2019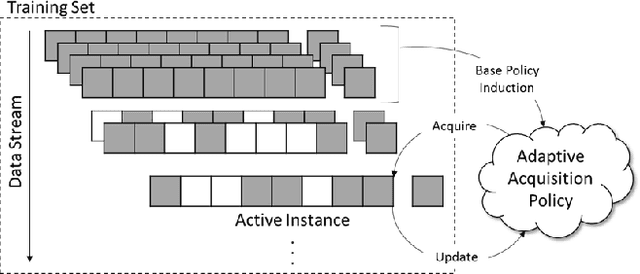
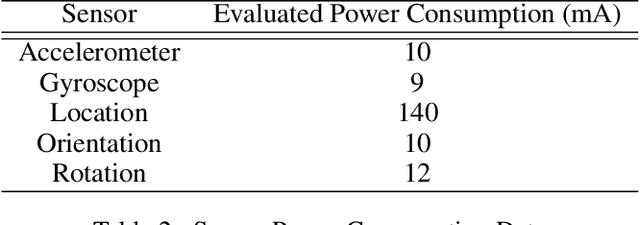
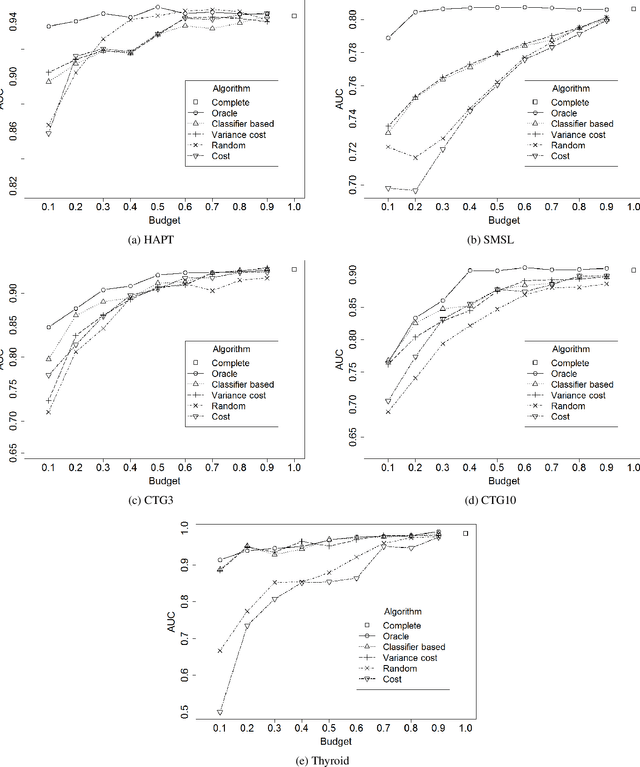
In real-world machine learning applications, there is a cost associated with sampling of different features. Budgeted learning can be used to select which feature-values to acquire from each instance in a dataset, such that the best model is induced under a given constraint. However, this approach is not possible in the domain of online learning since one may not retroactively acquire feature-values from past instances. In online learning, the challenge is to find the optimum set of features to be acquired from each instance upon arrival from a data stream. In this paper we introduce the issue of online budgeted learning and describe a general framework for addressing this challenge. We propose two types of feature value acquisition policies based on the multi-armed bandit problem: random and adaptive. Adaptive policies perform online adjustments according to new information coming from a data stream, while random policies are not sensitive to the information that arrives from the data stream. Our comparative study on five real-world datasets indicates that adaptive policies outperform random policies for most budget limitations and datasets. Furthermore, we found that in some cases adaptive policies achieve near-optimal results.
Personal Dynamic Cost-Aware Sensing for Latent Context Detection
Mar 13, 2019

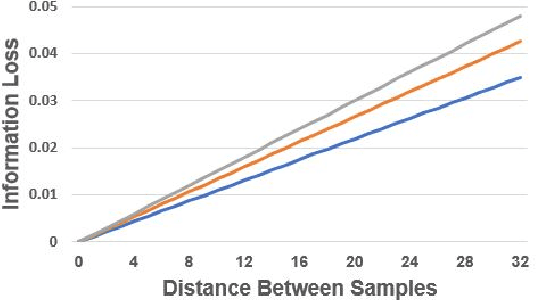
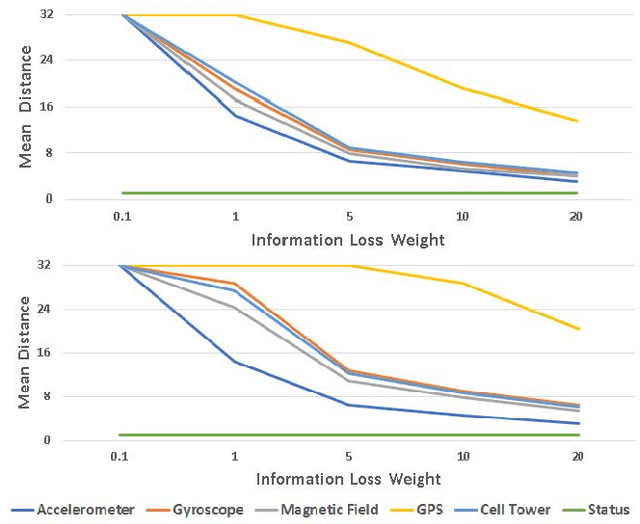
In the past decade, the usage of mobile devices has gone far beyond simple activities like calling and texting. Today, smartphones contain multiple embedded sensors and are able to collect useful sensing data about the user and infer the user's context. The more frequent the sensing, the more accurate the context. However, continuous sensing results in huge energy consumption, decreasing the battery's lifetime. We propose a novel approach for cost-aware sensing when performing continuous latent context detection. The suggested method dynamically determines user's sensors sampling policy based on three factors: (1) User's last known context; (2) Predicted information loss using KL-Divergence; and (3) Sensors' sampling costs. The objective function aims at minimizing both sampling cost and information loss. The method is based on various machine learning techniques including autoencoder neural networks for latent context detection, linear regression for information loss prediction, and convex optimization for determining the optimal sampling policy. To evaluate the suggested method, we performed a series of tests on real-world data recorded at a high-frequency rate; the data was collected from six mobile phone sensors of twenty users over the course of a week. Results show that by applying a dynamic sampling policy, our method naturally balances information loss and energy consumption and outperforms the static approach.% We compared the performance of our method with another state of the art dynamic sampling method and demonstrate its consistent superiority in various measures. %Our methods outperformed, and were able to improve we achieved better results in either sampling cost or information loss, and in some cases we improved both.
Detecting drug-drug interactions using artificial neural networks and classic graph similarity measures
Mar 11, 2019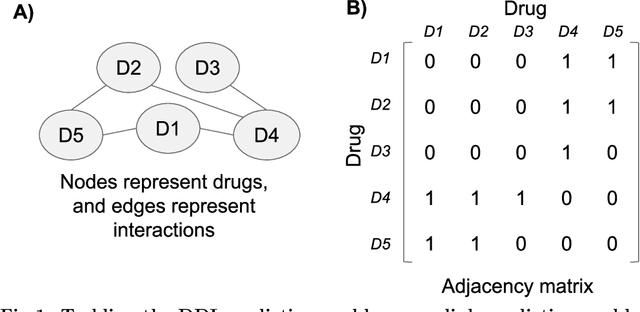
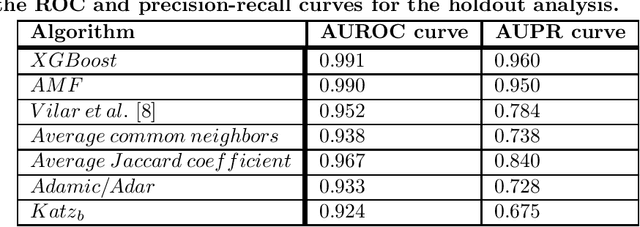

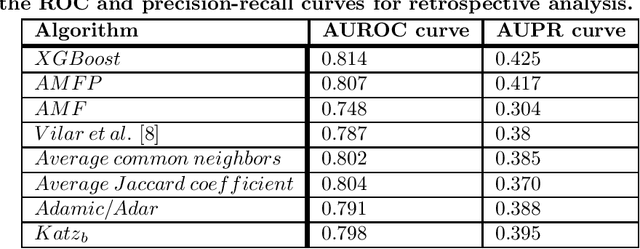
Drug-drug interactions are preventable causes of medical injuries and often result in doctor and emergency room visits. Computational techniques can be used to predict potential drug-drug interactions. We approach the drug-drug interaction prediction problem as a link prediction problem and present two novel methods for drug-drug interaction prediction based on artificial neural networks and factor propagation over graph nodes: adjacency matrix factorization (AMF) and adjacency matrix factorization with propagation (AMFP). We conduct a retrospective analysis by training our models on a previous release of the DrugBank database with 1,141 drugs and 45,296 drug-drug interactions and evaluate the results on a later version of DrugBank with 1,440 drugs and 248,146 drug-drug interactions. Additionally, we perform a holdout analysis using DrugBank. We report an area under the receiver operating characteristic curve score of 0.807 and 0.990 for the retrospective and holdout analyses respectively. Finally, we create an ensemble-based classifier using AMF, AMFP, and existing link prediction methods and obtain an area under the receiver operating characteristic curve of 0.814 and 0.991 for the retrospective and the holdout analyses. We demonstrate that AMF and AMFP provide state of the art results compared to existing methods and that the ensemble-based classifier improves the performance by combining various predictors. These results suggest that AMF, AMFP, and the proposed ensemble-based classifier can provide important information during drug development and regarding drug prescription given only partial or noisy data. These methods can also be used to solve other link prediction problems. Drug embeddings (compressed representations) created when training our models using the interaction network have been made public.
Explaining Anomalies Detected by Autoencoders Using SHAP
Mar 06, 2019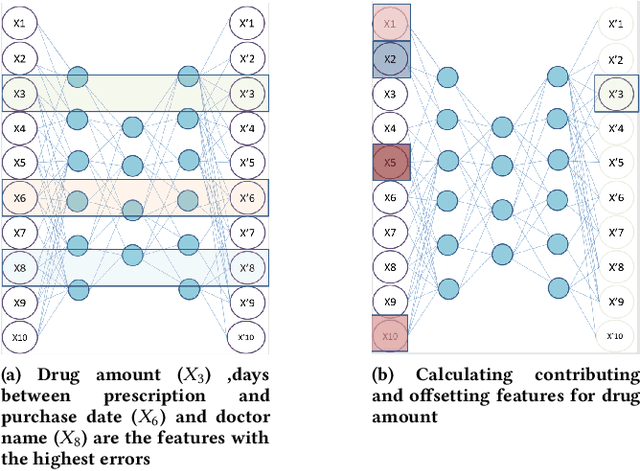



Anomaly detection algorithms are often thought to be limited because they don't facilitate the process of validating results performed by domain experts. In Contrast, deep learning algorithms for anomaly detection, such as autoencoders, point out the outliers, saving experts the time-consuming task of examining normal cases in order to find anomalies. Most outlier detection algorithms output a score for each instance in the database. The top-k most intense outliers are returned to the user for further inspection; however the manual validation of results becomes challenging without additional clues. An explanation of why an instance is anomalous enables the experts to focus their investigation on most important anomalies and may increase their trust in the algorithm. Recently, a game theory-based framework known as SHapley Additive exPlanations (SHAP) has been shown to be effective in explaining various supervised learning models. In this research, we extend SHAP to explain anomalies detected by an autoencoder, an unsupervised model. The proposed method extracts and visually depicts both the features that most contributed to the anomaly and those that offset it. A preliminary experimental study using real world data demonstrates the usefulness of the proposed method in assisting the domain experts to understand the anomaly and filtering out the uninteresting anomalies, aiming at minimizing the false positive rate of detected anomalies.
Implicit Dimension Identification in User-Generated Text with LSTM Networks
Feb 01, 2019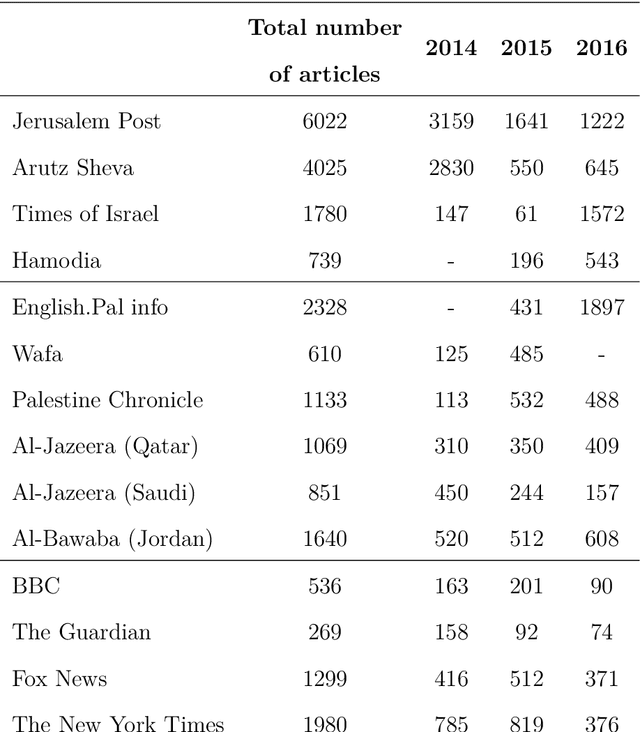


In the process of online storytelling, individual users create and consume highly diverse content that contains a great deal of implicit beliefs and not plainly expressed narrative. It is hard to manually detect these implicit beliefs, intentions and moral foundations of the writers. We study and investigate two different tasks, each of which reflect the difficulty of detecting an implicit user's knowledge, intent or belief that may be based on writer's moral foundation: 1) political perspective detection in news articles 2) identification of informational vs. conversational questions in community question answering (CQA) archives and. In both tasks we first describe new interesting annotated datasets and make the datasets publicly available. Second, we compare various classification algorithms, and show the differences in their performance on both tasks. Third, in political perspective detection task we utilize a narrative representation language of local press to identify perspective differences between presumably neutral American and British press.