 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSCo: Making Absence Visible in Intelligent Summarization Interfaces
Jan 12, 2026Intelligent interfaces increasingly use large language models to summarize user-generated content, yet these summaries emphasize what is mentioned while overlooking what is missing. This presence bias can mislead users who rely on summaries to make decisions. We present Domain Informed Summarization through Contrast (DiSCo), an expectation-based computational approach that makes absences visible by comparing each entity's content with domain topical expectations captured in reference distributions of aspects typically discussed in comparable accommodations. This comparison identifies aspects that are either unusually emphasized or missing relative to domain norms and integrates them into the generated text. In a user study across three accommodation domains, namely ski, beach, and city center, DiSCo summaries were rated as more detailed and useful for decision making than baseline large language model summaries, although slightly harder to read. The findings show that modeling expectations reduces presence bias and improves both transparency and decision support in intelligent summarization interfaces.
Controlling Summarization Length Through EOS Token Weighting
Jun 05, 2025Controlling the length of generated text can be crucial in various text-generation tasks, including summarization. Existing methods often require complex model alterations, limiting compatibility with pre-trained models. We address these limitations by developing a simple approach for controlling the length of automatic text summaries by increasing the importance of correctly predicting the EOS token in the cross-entropy loss computation. The proposed methodology is agnostic to architecture and decoding algorithms and orthogonal to other inference-time techniques to control the generation length. We tested it with encoder-decoder and modern GPT-style LLMs, and show that this method can control generation length, often without affecting the quality of the summary.
Enhancing Travel Decision-Making: A Contrastive Learning Approach for Personalized Review Rankings in Accommodations
Jun 30, 2024User-generated reviews significantly influence consumer decisions, particularly in the travel domain when selecting accommodations. This paper contribution comprising two main elements. Firstly, we present a novel dataset of authentic guest reviews sourced from a prominent online travel platform, totaling over two million reviews from 50,000 distinct accommodations. Secondly, we propose an innovative approach for personalized review ranking. Our method employs contrastive learning to intricately capture the relationship between a review and the contextual information of its respective reviewer. Through a comprehensive experimental study, we demonstrate that our approach surpasses several baselines across all reported metrics. Augmented by a comparative analysis, we showcase the efficacy of our method in elevating personalized review ranking. The implications of our research extend beyond the travel domain, with potential applications in other sectors where personalized review ranking is paramount, such as online e-commerce platforms.
Text2Topic: Multi-Label Text Classification System for Efficient Topic Detection in User Generated Content with Zero-Shot Capabilities
Oct 23, 2023Multi-label text classification is a critical task in the industry. It helps to extract structured information from large amount of textual data. We propose Text to Topic (Text2Topic), which achieves high multi-label classification performance by employing a Bi-Encoder Transformer architecture that utilizes concatenation, subtraction, and multiplication of embeddings on both text and topic. Text2Topic also supports zero-shot predictions, produces domain-specific text embeddings, and enables production-scale batch-inference with high throughput. The final model achieves accurate and comprehensive results compared to state-of-the-art baselines, including large language models (LLMs). In this study, a total of 239 topics are defined, and around 1.6 million text-topic pairs annotations (in which 200K are positive) are collected on approximately 120K texts from 3 main data sources on Booking.com. The data is collected with optimized smart sampling and partial labeling. The final Text2Topic model is deployed on a real-world stream processing platform, and it outperforms other models with 92.9% micro mAP, as well as a 75.8% macro mAP score. We summarize the modeling choices which are extensively tested through ablation studies, and share detailed in-production decision-making steps.
Online Budgeted Learning for Classifier Induction
Mar 13, 2019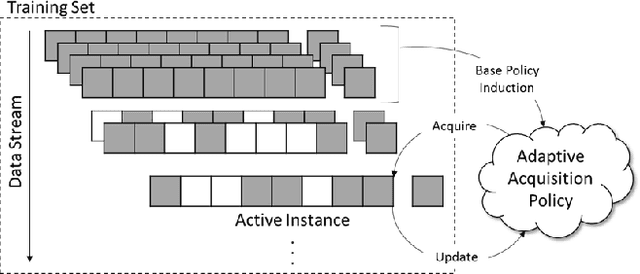
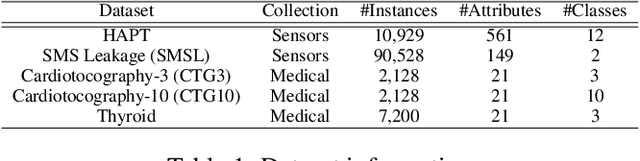
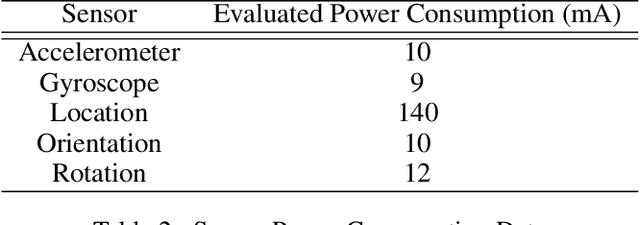
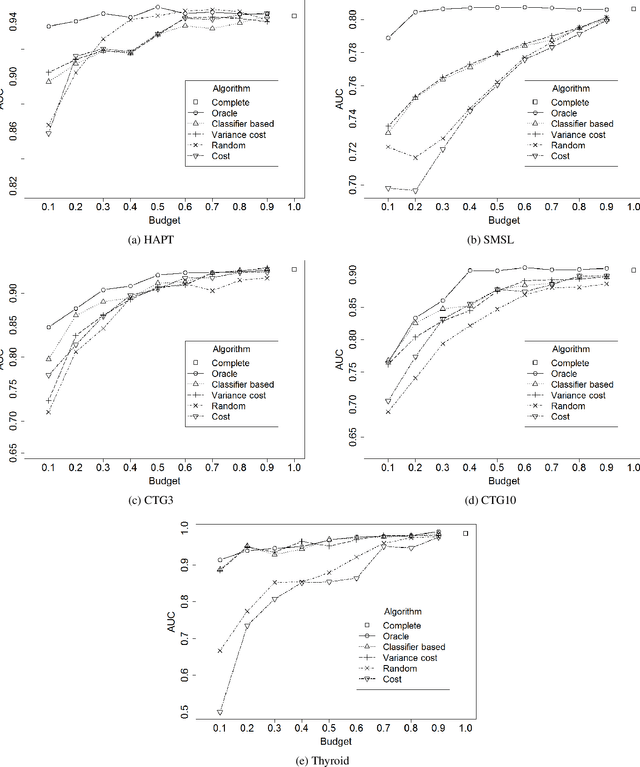
In real-world machine learning applications, there is a cost associated with sampling of different features. Budgeted learning can be used to select which feature-values to acquire from each instance in a dataset, such that the best model is induced under a given constraint. However, this approach is not possible in the domain of online learning since one may not retroactively acquire feature-values from past instances. In online learning, the challenge is to find the optimum set of features to be acquired from each instance upon arrival from a data stream. In this paper we introduce the issue of online budgeted learning and describe a general framework for addressing this challenge. We propose two types of feature value acquisition policies based on the multi-armed bandit problem: random and adaptive. Adaptive policies perform online adjustments according to new information coming from a data stream, while random policies are not sensitive to the information that arrives from the data stream. Our comparative study on five real-world datasets indicates that adaptive policies outperform random policies for most budget limitations and datasets. Furthermore, we found that in some cases adaptive policies achieve near-optimal results.