 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensing Ambiguity in Henry James' "The Turn of the Screw"
Nov 21, 2020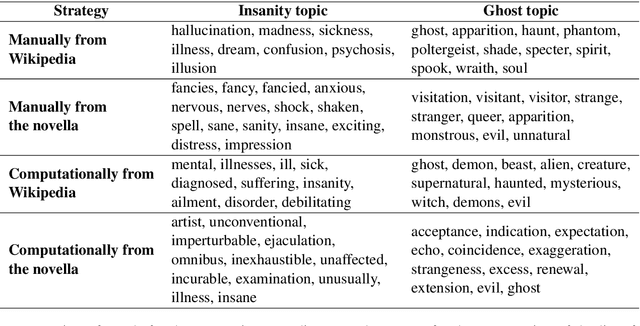
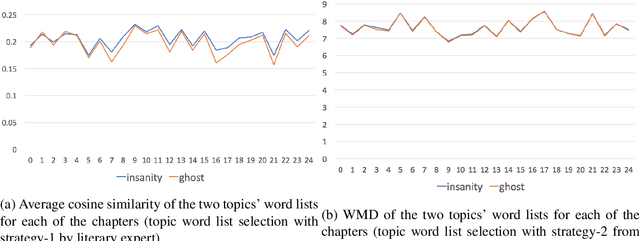
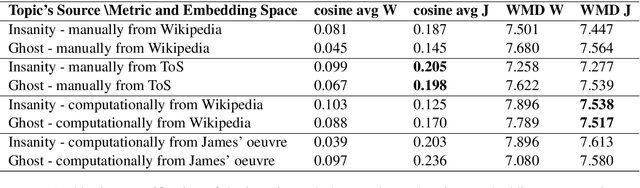
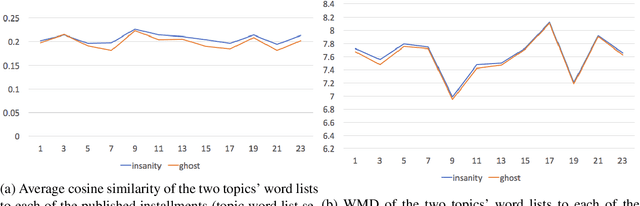
Fields such as the philosophy of language, continental philosophy, and literary studies have long established that human language is, at its essence, ambiguous and that this quality, although challenging to communication, enriches language and points to the complexity of human thought. On the other hand, in the NLP field there have been ongoing efforts aimed at disambiguation for various downstream tasks. This work brings together computational text analysis and literary analysis to demonstrate the extent to which ambiguity in certain texts plays a key role in shaping meaning and thus requires analysis rather than elimination. We revisit the discussion, well known in the humanities, about the role ambiguity plays in Henry James' 19th century novella, The Turn of the Screw. We model each of the novella's two competing interpretations as a topic and computationally demonstrate that the duality between them exists consistently throughout the work and shapes, rather than obscures, its meaning. We also demonstrate that cosine similarity and word mover's distance are sensitive enough to detect ambiguity in its most subtle literary form, despite doubts to the contrary raised by literary scholars. Our analysis is built on topic word lists and word embeddings from various sources. We first claim, and then empirically show, the interdependence between computational analysis and close reading performed by a human expert.
Lessons Learned from Applying off-the-shelf BERT: There is no Silver Bullet
Sep 18, 2020
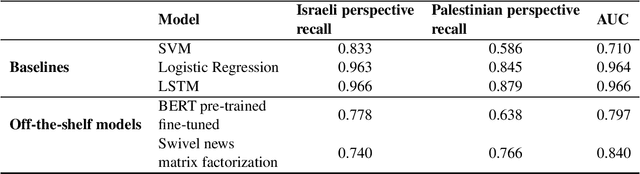
One of the challenges in the NLP field is training large classification models, a task that is both difficult and tedious. It is even harder when GPU hardware is unavailable. The increased availability of pre-trained and off-the-shelf word embeddings, models, and modules aim at easing the process of training large models and achieving a competitive performance. We explore the use of off-the-shelf BERT models and share the results of our experiments and compare their results to those of LSTM networks and more simple baselines. We show that the complexity and computational cost of BERT is not a guarantee for enhanced predictive performance in the classification tasks at hand.
Implicit Dimension Identification in User-Generated Text with LSTM Networks
Feb 01, 2019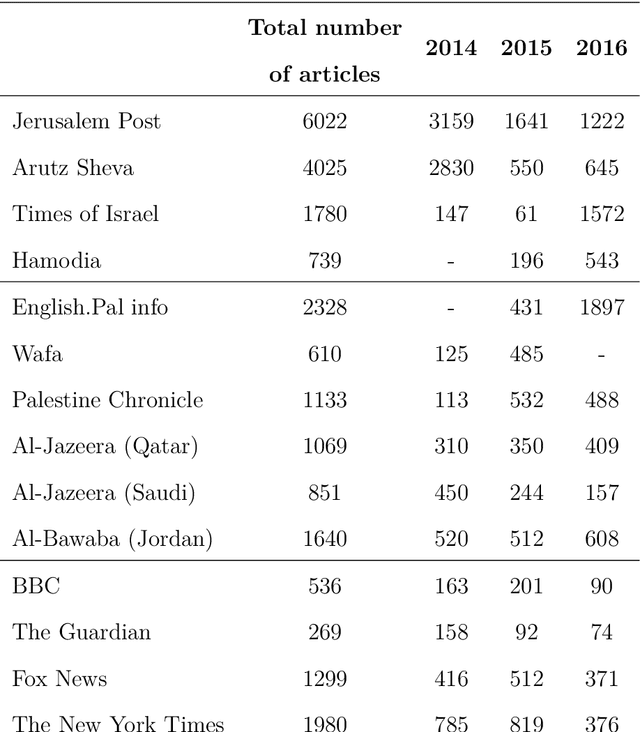


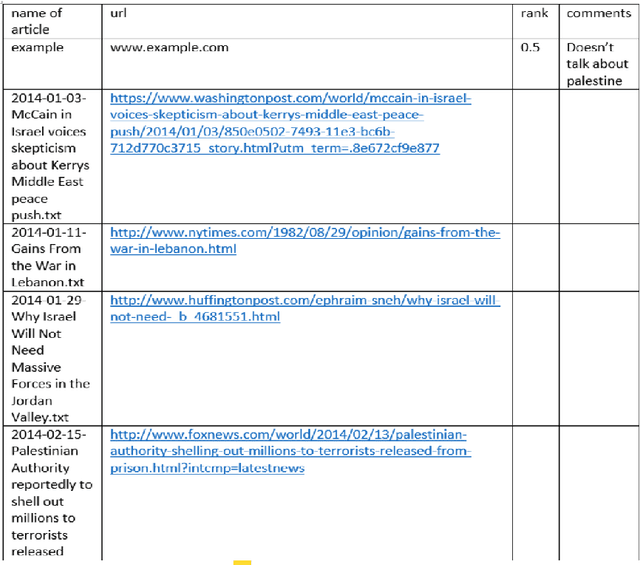
In the process of online storytelling, individual users create and consume highly diverse content that contains a great deal of implicit beliefs and not plainly expressed narrative. It is hard to manually detect these implicit beliefs, intentions and moral foundations of the writers. We study and investigate two different tasks, each of which reflect the difficulty of detecting an implicit user's knowledge, intent or belief that may be based on writer's moral foundation: 1) political perspective detection in news articles 2) identification of informational vs. conversational questions in community question answering (CQA) archives and. In both tasks we first describe new interesting annotated datasets and make the datasets publicly available. Second, we compare various classification algorithms, and show the differences in their performance on both tasks. Third, in political perspective detection task we utilize a narrative representation language of local press to identify perspective differences between presumably neutral American and British press.
Choosing the Right Word: Using Bidirectional LSTM Tagger for Writing Support Systems
Jan 08, 2019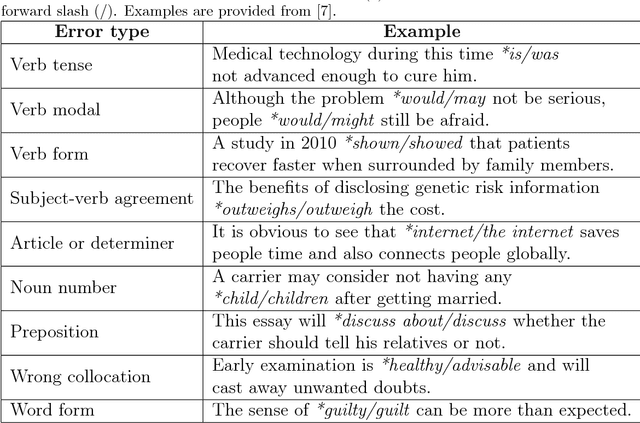
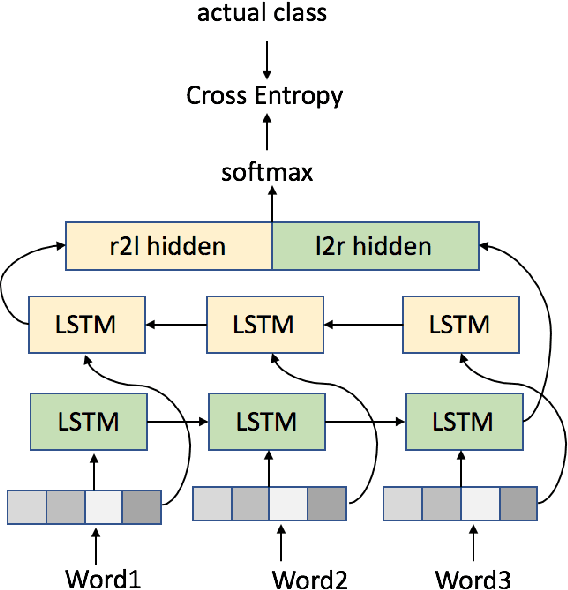
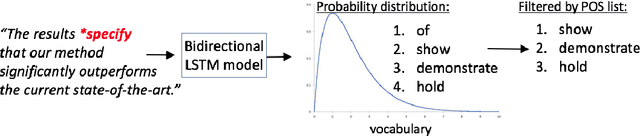
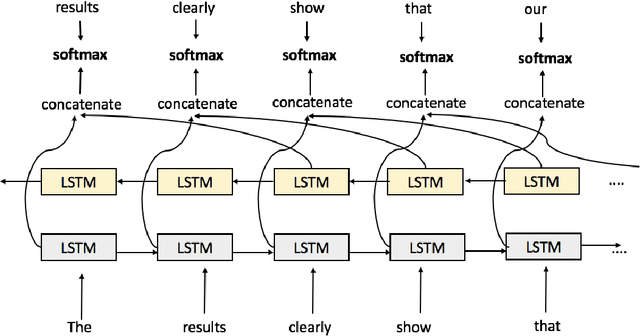
Scientific writing is difficult. It is even harder for those for whom English is a second language (ESL learners). Scholars around the world spend a significant amount of time and resources proofreading their work before submitting it for review or publication. In this paper we present a novel machine learning based application for proper word choice task. Proper word choice is a generalization the lexical substitution (LS) and grammatical error correction (GEC) tasks. We demonstrate and evaluate the usefulness of applying bidirectional Long Short Term Memory (LSTM) tagger, for this task. While state-of-the-art grammatical error correction uses error-specific classifiers and machine translation methods, we demonstrate an unsupervised method that is based solely on a high quality text corpus and does not require manually annotated data. We use a bidirectional Recurrent Neural Network (RNN) with LSTM for learning the proper word choice based on a word's sentential context. We demonstrate and evaluate our application on both a domain-specific (scientific), writing task and a general-purpose writing task. We show that our domain-specific and general-purpose models outperform state-of-the-art general context learning. As an additional contribution of this research, we also share our code, pre-trained models, and a new ESL learner test set with the research community.
Language Models with Pre-Trained (GloVe) Word Embeddings
Feb 05, 2017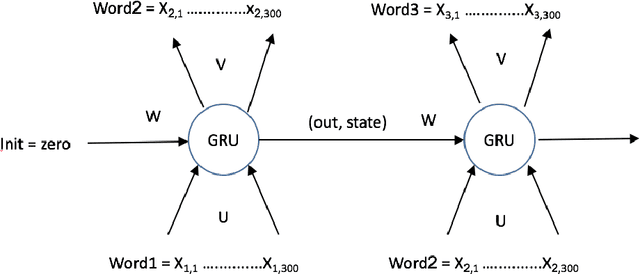
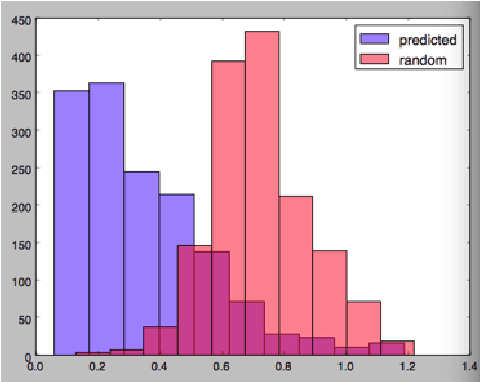
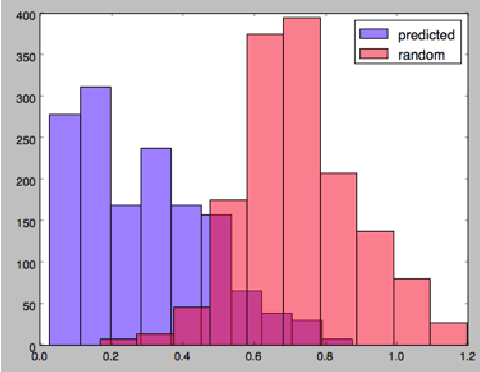
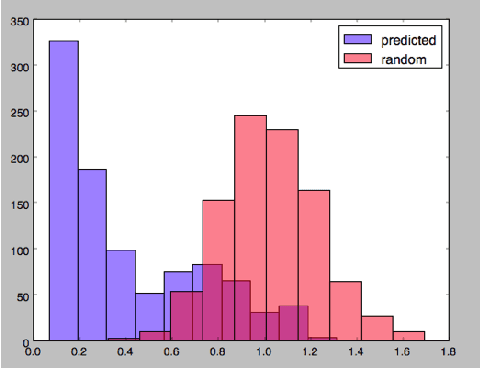
In this work we implement a training of a Language Model (LM), using Recurrent Neural Network (RNN) and GloVe word embeddings, introduced by Pennigton et al. in [1]. The implementation is following the general idea of training RNNs for LM tasks presented in [2], but is rather using Gated Recurrent Unit (GRU) [3] for a memory cell, and not the more commonly used LSTM [4].