 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Comparison of State-of-the-Art Deep Learning Methods for Image Multi-Label Classification
Apr 05, 2019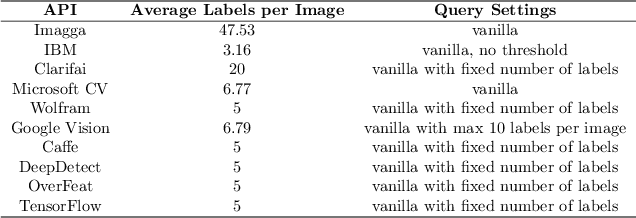
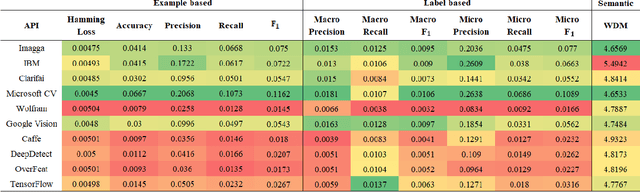
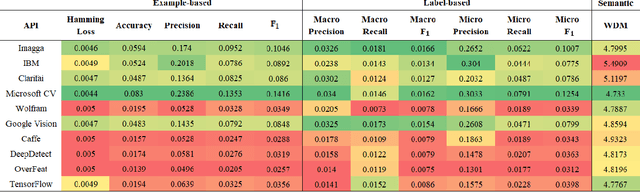
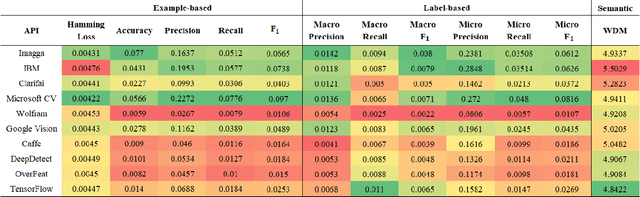
Image understanding relies heavily on accurate multi-label classification. In recent years deep learning (DL) algorithms have become very successful tools for multi-label classification of image objects. With these set of tools, various implementations of DL algorithms have been released for the public use in the form of application programming interfaces (API). In this study, we evaluate and compare 10 of the most prominent publicly available APIs in a best-of-breed challenge. The evaluation is performed on the Visual Genome labeling benchmark dataset using 12 well-recognized similarity metrics. In addition, for the first time in this kind of comparison, we use a semantic similarity metric to evaluate the semantic similarity performance of these APIs. In this evaluation, Microsoft's Computer Vision, TensorFlow, Imagga, and IBM's Visual Recognition showed better performance than the other APIs. Furthermore, the new semantic similarity metric allowed deeper insights for comparison.
Transfer Learning for Content-Based Recommender Systems using Tree Matching
May 15, 2013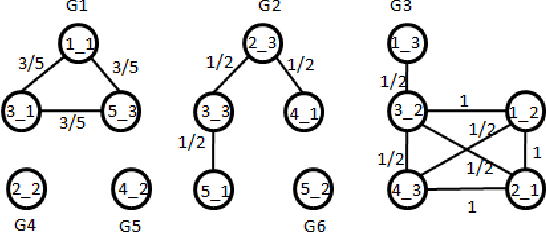
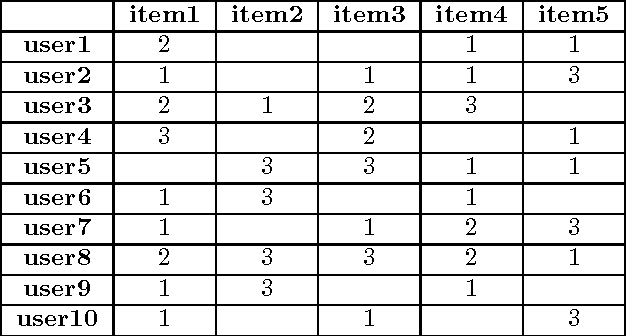
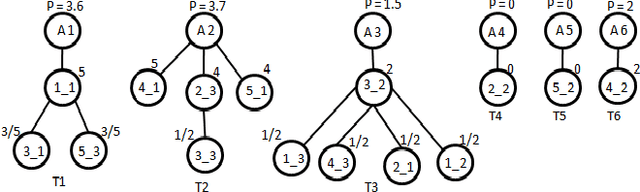
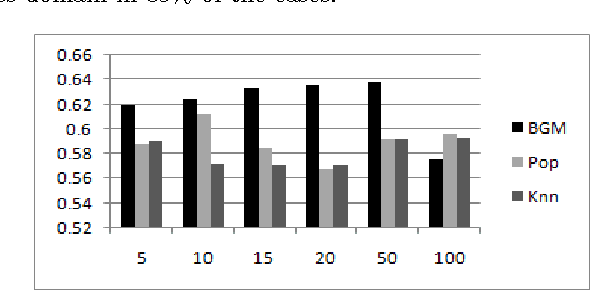
In this paper we present a new approach to content-based transfer learning for solving the data sparsity problem in cases when the users' preferences in the target domain are either scarce or unavailable, but the necessary information on the preferences exists in another domain. We show that training a system to use such information across domains can produce better performance. Specifically, we represent users' behavior patterns based on topological graph structures. Each behavior pattern represents the behavior of a set of users, when the users' behavior is defined as the items they rated and the items' rating values. In the next step we find a correlation between behavior patterns in the source domain and behavior patterns in the target domain. This mapping is considered a bridge between the two domains. Based on the correlation and content-attributes of the items, we train a machine learning model to predict users' ratings in the target domain. When we compare our approach to the popularity approach and KNN-cross-domain on a real world dataset, the results show that on an average of 83$%$ of the cases our approach outperforms both methods.