 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect and Calibrate the Low-confidence: Dual-Channel Consistency based Graph Convolutional Networks
May 08, 2022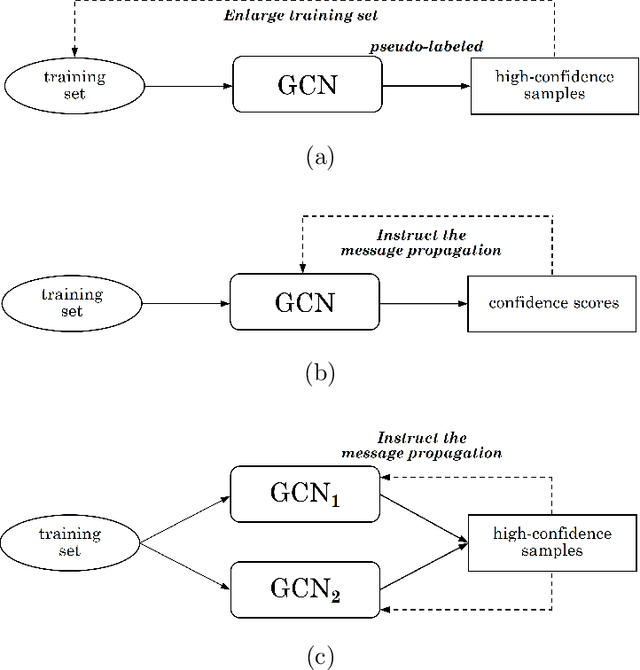
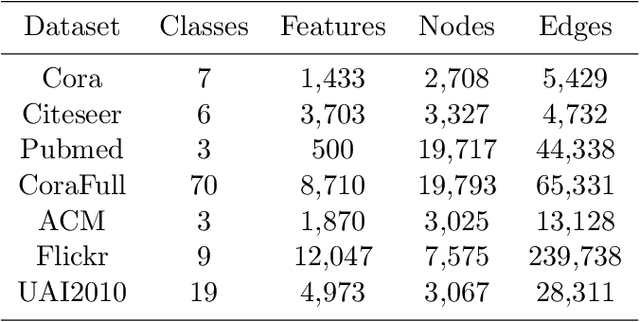
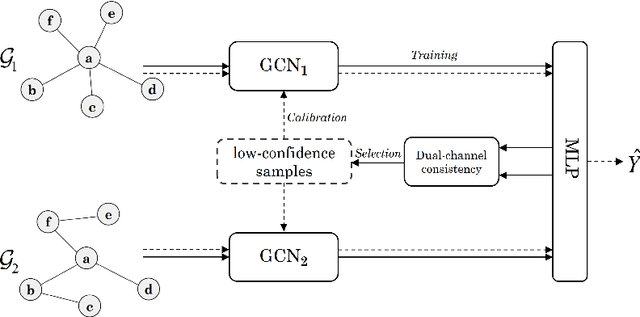
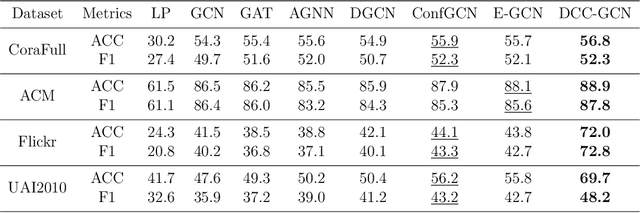
The Graph Convolutional Networks (GCNs) have achieved excellent results in node classification tasks, but the model's performance at low label rates is still unsatisfactory. Previous studies in Semi-Supervised Learning (SSL) for graph have focused on using network predictions to generate soft pseudo-labels or instructing message propagation, which inevitably contains the incorrect prediction due to the over-confident in the predictions. Our proposed Dual-Channel Consistency based Graph Convolutional Networks (DCC-GCN) uses dual-channel to extract embeddings from node features and topological structures, and then achieves reliable low-confidence and high-confidence samples selection based on dual-channel consistency. We further confirmed that the low-confidence samples obtained based on dual-channel consistency were low in accuracy, constraining the model's performance. Unlike previous studies ignoring low-confidence samples, we calibrate the feature embeddings of the low-confidence samples by using the neighborhood's high-confidence samples. Our experiments have shown that the DCC-GCN can more accurately distinguish between low-confidence and high-confidence samples, and can also significantly improve the accuracy of low-confidence samples. We conducted extensive experiments on the benchmark datasets and demonstrated that DCC-GCN is significantly better than state-of-the-art baselines at different label rates.
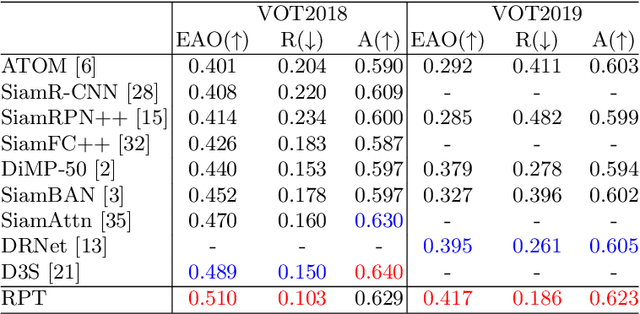
RPT++: Customized Feature Representation for Siamese Visual Tracking
Oct 23, 2021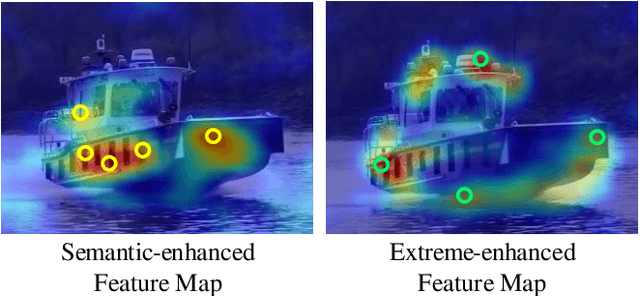

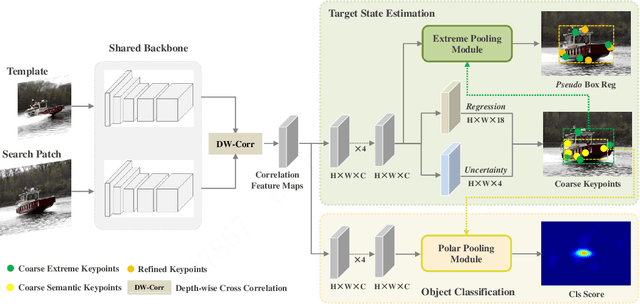

While recent years have witnessed remarkable progress in the feature representation of visual tracking, the problem of feature misalignment between the classification and regression tasks is largely overlooked. The approaches of feature extraction make no difference for these two tasks in most of advanced trackers. We argue that the performance gain of visual tracking is limited since features extracted from the salient area provide more recognizable visual patterns for classification, while these around the boundaries contribute to accurately estimating the target state. We address this problem by proposing two customized feature extractors, named polar pooling and extreme pooling to capture task-specific visual patterns. Polar pooling plays the role of enriching information collected from the semantic keypoints for stronger classification, while extreme pooling facilitates explicit visual patterns of the object boundary for accurate target state estimation. We demonstrate the effectiveness of the task-specific feature representation by integrating it into the recent and advanced tracker RPT. Extensive experiments on several benchmarks show that our Customized Features based RPT (RPT++) achieves new state-of-the-art performances on OTB-100, VOT2018, VOT2019, GOT-10k, TrackingNet and LaSOT.
Adaptive Multi-layer Contrastive Graph Neural Networks
Sep 29, 2021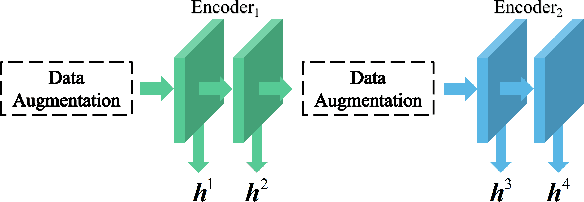
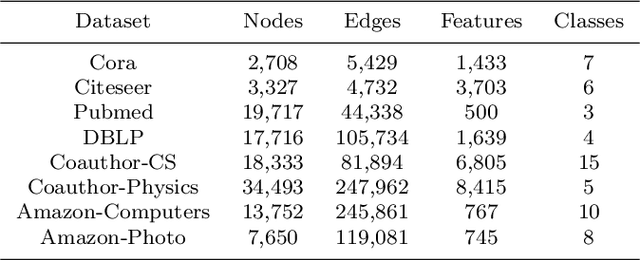
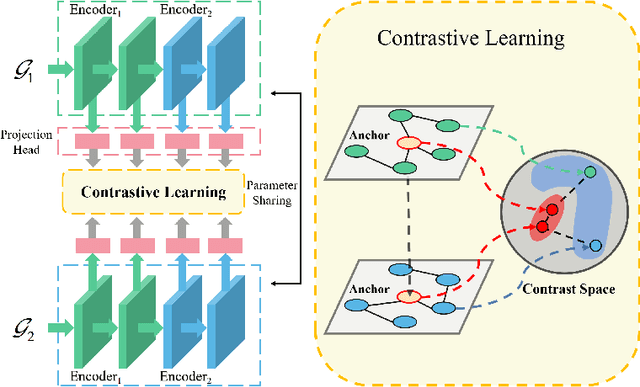
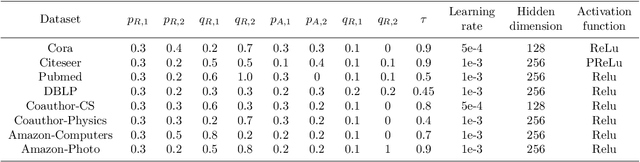
We present Adaptive Multi-layer Contrastive Graph Neural Networks (AMC-GNN), a self-supervised learning framework for Graph Neural Network, which learns feature representations of sample data without data labels. AMC-GNN generates two graph views by data augmentation and compares different layers' output embeddings of Graph Neural Network encoders to obtain feature representations, which could be used for downstream tasks. AMC-GNN could learn the importance weights of embeddings in different layers adaptively through the attention mechanism, and an auxiliary encoder is introduced to train graph contrastive encoders better. The accuracy is improved by maximizing the representation's consistency of positive pairs in the early layers and the final embedding space. Our experiments show that the results can be consistently improved by using the AMC-GNN framework, across four established graph benchmarks: Cora, Citeseer, Pubmed, DBLP citation network datasets, as well as four newly proposed datasets: Co-author-CS, Co-author-Physics, Amazon-Computers, Amazon-Photo.
Improving the Transferability of Adversarial Examples with New Iteration Framework and Input Dropout
Jun 22, 2021

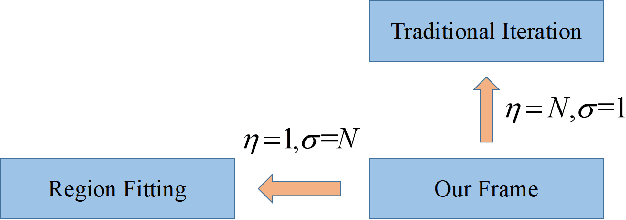
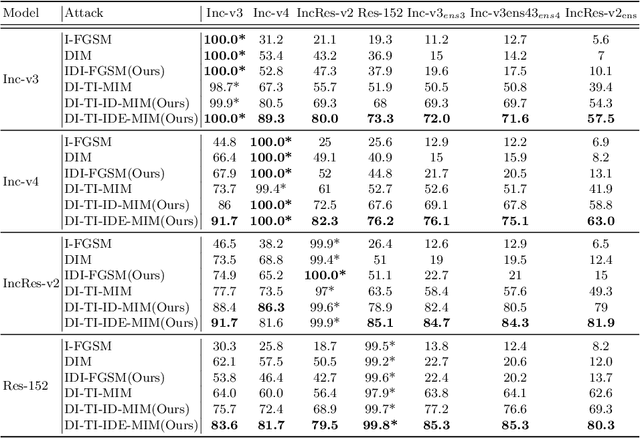
Deep neural networks(DNNs) is vulnerable to be attacked by adversarial examples. Black-box attack is the most threatening attack. At present, black-box attack methods mainly adopt gradient-based iterative attack methods, which usually limit the relationship between the iteration step size, the number of iterations, and the maximum perturbation. In this paper, we propose a new gradient iteration framework, which redefines the relationship between the above three. Under this framework, we easily improve the attack success rate of DI-TI-MIM. In addition, we propose a gradient iterative attack method based on input dropout, which can be well combined with our framework. We further propose a multi dropout rate version of this method. Experimental results show that our best method can achieve attack success rate of 96.2\% for defense model on average, which is higher than the state-of-the-art gradient-based attacks.
Dynamic Defense Approach for Adversarial Robustness in Deep Neural Networks via Stochastic Ensemble Smoothed Model
May 06, 2021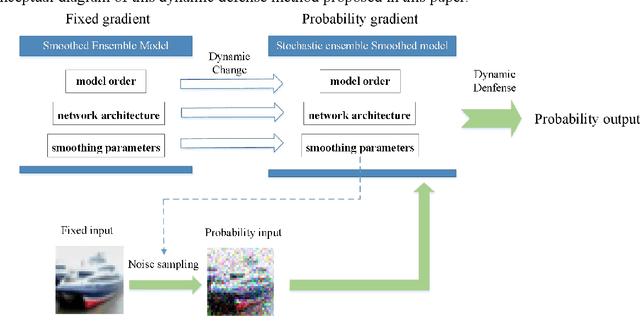
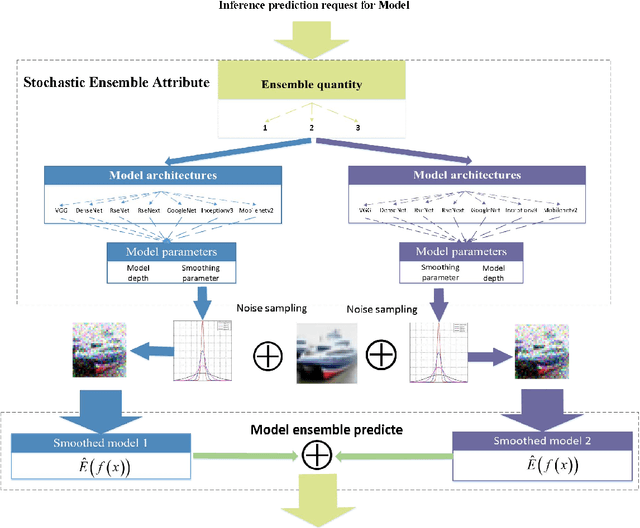
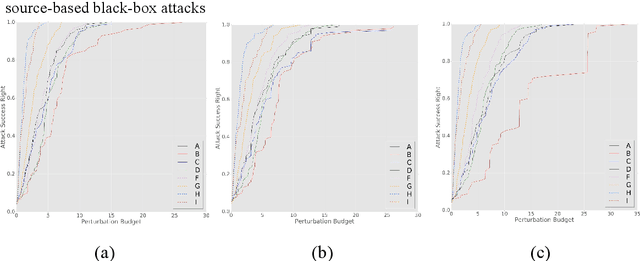
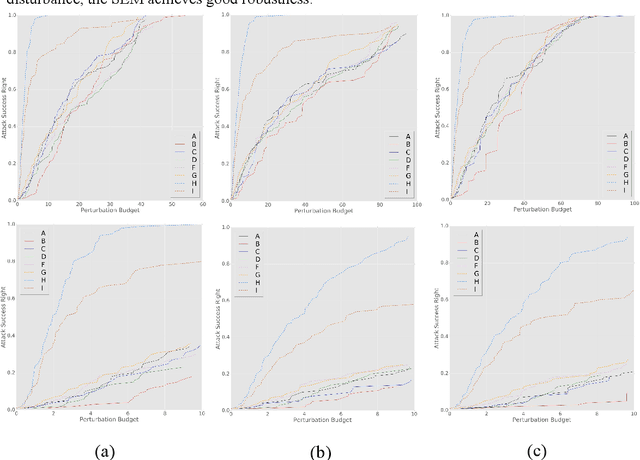
Deep neural networks have been shown to suffer from critical vulnerabilities under adversarial attacks. This phenomenon stimulated the creation of different attack and defense strategies similar to those adopted in cyberspace security. The dependence of such strategies on attack and defense mechanisms makes the associated algorithms on both sides appear as closely reciprocating processes. The defense strategies are particularly passive in these processes, and enhancing initiative of such strategies can be an effective way to get out of this arms race. Inspired by the dynamic defense approach in cyberspace, this paper builds upon stochastic ensemble smoothing based on defense method of random smoothing and model ensemble. Proposed method employs network architecture and smoothing parameters as ensemble attributes, and dynamically change attribute-based ensemble model before every inference prediction request. The proposed method handles the extreme transferability and vulnerability of ensemble models under white-box attacks. Experimental comparison of ASR-vs-distortion curves with different attack scenarios shows that even the attacker with the highest attack capability cannot easily exceed the attack success rate associated with the ensemble smoothed model, especially under untargeted attacks.
RPT: Learning Point Set Representation for Siamese Visual Tracking
Sep 02, 2020

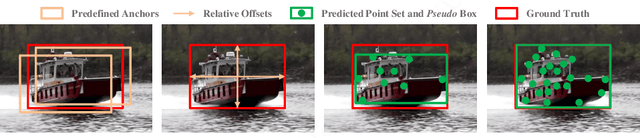
While remarkable progress has been made in robust visual tracking, accurate target state estimation still remains a highly challenging problem. In this paper, we argue that this issue is closely related to the prevalent bounding box representation, which provides only a coarse spatial extent of object. Thus an effcient visual tracking framework is proposed to accurately estimate the target state with a finer representation as a set of representative points. The point set is trained to indicate the semantically and geometrically significant positions of target region, enabling more fine-grained localization and modeling of object appearance. We further propose a multi-level aggregation strategy to obtain detailed structure information by fusing hierarchical convolution layers. Extensive experiments on several challenging benchmarks including OTB2015, VOT2018, VOT2019 and GOT-10k demonstrate that our method achieves new state-of-the-art performance while running at over 20 FPS.
Neural encoding and interpretation for high-level visual cortices based on fMRI using image caption features
Mar 26, 2020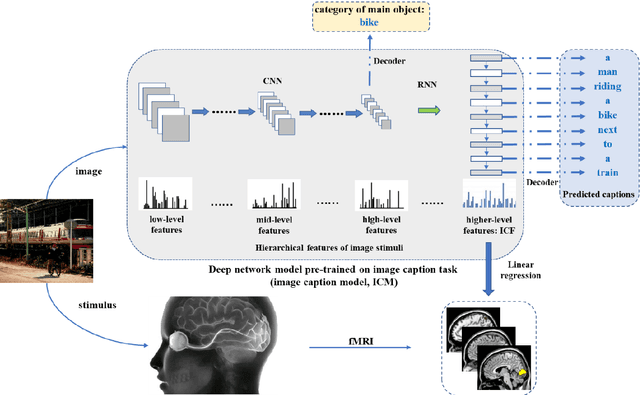
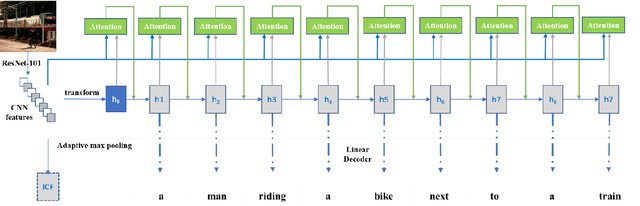
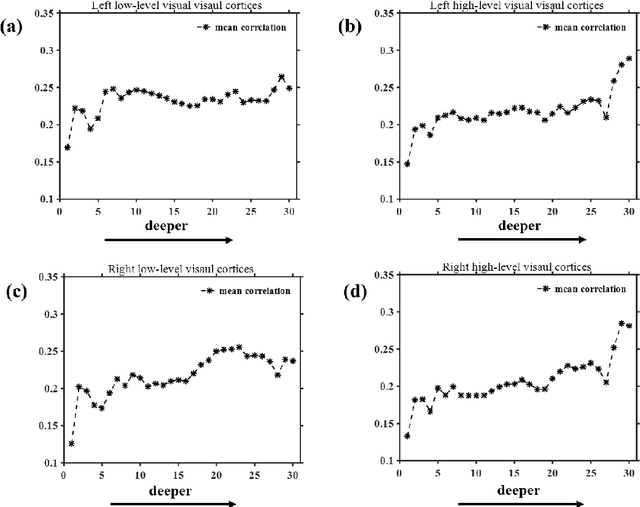
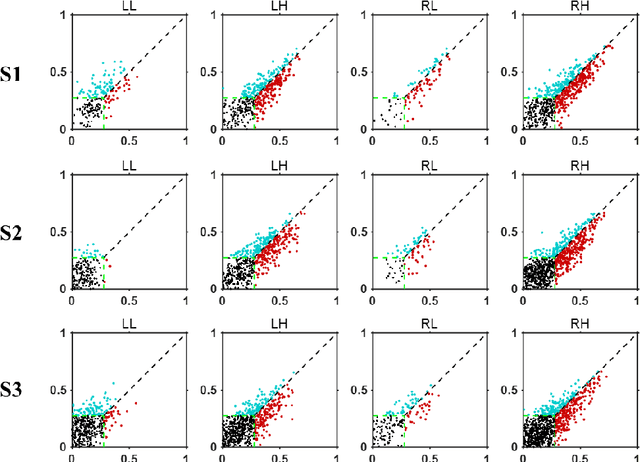
On basis of functional magnetic resonance imaging (fMRI), researchers are devoted to designing visual encoding models to predict the neuron activity of human in response to presented image stimuli and analyze inner mechanism of human visual cortices. Deep network structure composed of hierarchical processing layers forms deep network models by learning features of data on specific task through big dataset. Deep network models have powerful and hierarchical representation of data, and have brought about breakthroughs for visual encoding, while revealing hierarchical structural similarity with the manner of information processing in human visual cortices. However, previous studies almost used image features of those deep network models pre-trained on classification task to construct visual encoding models. Except for deep network structure, the task or corresponding big dataset is also important for deep network models, but neglected by previous studies. Because image classification is a relatively fundamental task, it is difficult to guide deep network models to master high-level semantic representations of data, which causes into that encoding performance for high-level visual cortices is limited. In this study, we introduced one higher-level vision task: image caption (IC) task and proposed the visual encoding model based on IC features (ICFVEM) to encode voxels of high-level visual cortices. Experiment demonstrated that ICFVEM obtained better encoding performance than previous deep network models pre-trained on classification task. In addition, the interpretation of voxels was realized to explore the detailed characteristics of voxels based on the visualization of semantic words, and comparative analysis implied that high-level visual cortices behaved the correlative representation of image content.
BigGAN-based Bayesian reconstruction of natural images from human brain activity
Mar 13, 2020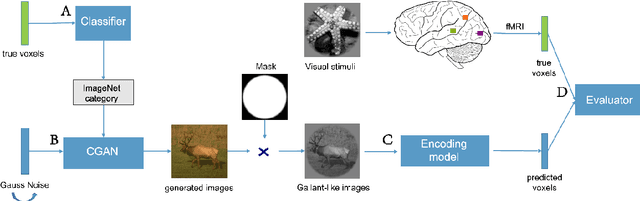
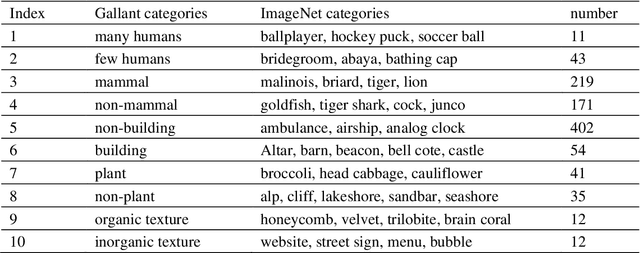


In the visual decoding domain, visually reconstructing presented images given the corresponding human brain activity monitored by functional magnetic resonance imaging (fMRI) is difficult, especially when reconstructing viewed natural images. Visual reconstruction is a conditional image generation on fMRI data and thus generative adversarial network (GAN) for natural image generation is recently introduced for this task. Although GAN-based methods have greatly improved, the fidelity and naturalness of reconstruction are still unsatisfactory due to the small number of fMRI data samples and the instability of GAN training. In this study, we proposed a new GAN-based Bayesian visual reconstruction method (GAN-BVRM) that includes a classifier to decode categories from fMRI data, a pre-trained conditional generator to generate natural images of specified categories, and a set of encoding models and evaluator to evaluate generated images. GAN-BVRM employs the pre-trained generator of the prevailing BigGAN to generate masses of natural images, and selects the images that best matches with the corresponding brain activity through the encoding models as the reconstruction of the image stimuli. In this process, the semantic and detailed contents of reconstruction are controlled by decoded categories and encoding models, respectively. GAN-BVRM used the Bayesian manner to avoid contradiction between naturalness and fidelity from current GAN-based methods and thus can improve the advantages of GAN. Experimental results revealed that GAN-BVRM improves the fidelity and naturalness, that is, the reconstruction is natural and similar to the presented image stimuli.
AdvJND: Generating Adversarial Examples with Just Noticeable Difference
Feb 01, 2020

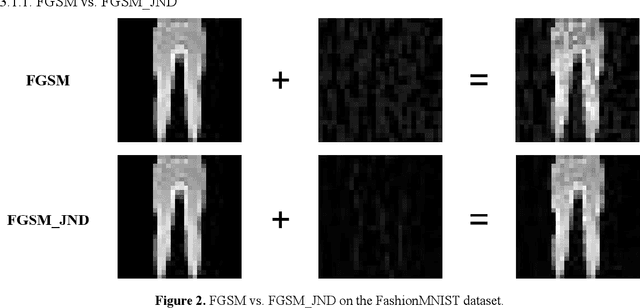
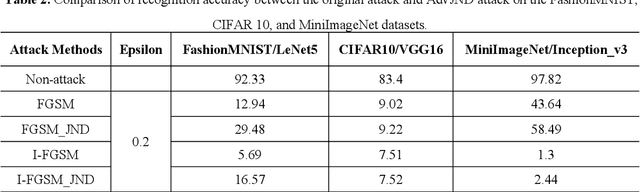
Compared with traditional machine learning models, deep neural networks perform better, especially in image classification tasks. However, they are vulnerable to adversarial examples. Adding small perturbations on examples causes a good-performance model to misclassify the crafted examples, without category differences in the human eyes, and fools deep models successfully. There are two requirements for generating adversarial examples: the attack success rate and image fidelity metrics. Generally, perturbations are increased to ensure the adversarial examples' high attack success rate; however, the adversarial examples obtained have poor concealment. To alleviate the tradeoff between the attack success rate and image fidelity, we propose a method named AdvJND, adding visual model coefficients, just noticeable difference coefficients, in the constraint of a distortion function when generating adversarial examples. In fact, the visual subjective feeling of the human eyes is added as a priori information, which decides the distribution of perturbations, to improve the image quality of adversarial examples. We tested our method on the FashionMNIST, CIFAR10, and MiniImageNet datasets. Adversarial examples generated by our AdvJND algorithm yield gradient distributions that are similar to those of the original inputs. Hence, the crafted noise can be hidden in the original inputs, thus improving the attack concealment significantly.
HAD-GAN: A Human-perception Auxiliary Defense GAN to Defend Adversarial Examples
Sep 25, 2019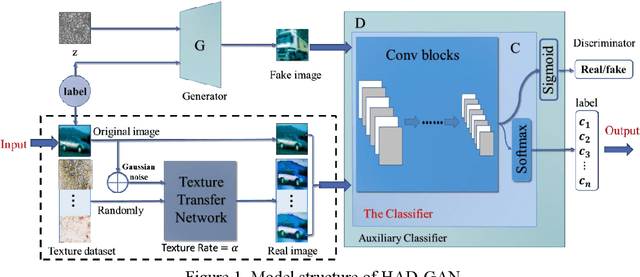
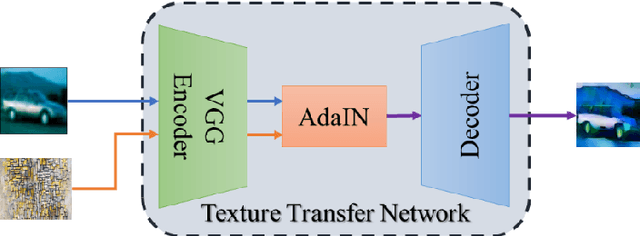
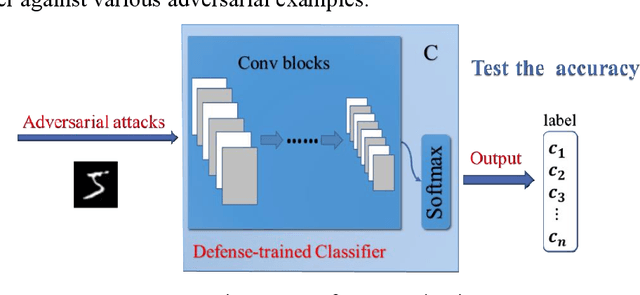
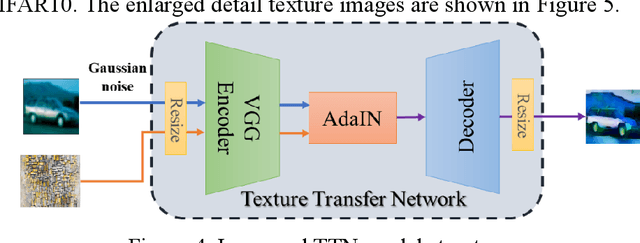
Adversarial examples reveal the vulnerability and unexplained nature of neural networks. Studying the defense of adversarial examples is of considerable practical importance. Most adversarial examples that misclassify networks are often undetectable by humans. In this paper, we propose a defense model to train the classifier into a human-perception classification model with shape preference. The proposed model comprising a texture transfer network (TTN) and an auxiliary defense generative adversarial networks (GAN) is called Human-perception Auxiliary Defense GAN (HAD-GAN). The TTN is used to extend the texture samples of a clean image and helps classifiers focus on its shape. GAN is utilized to form a training framework for the model and generate the necessary images. A series of experiments conducted on MNIST, Fashion-MNIST and CIFAR10 show that the proposed model outperforms the state-of-the-art defense methods for network robustness. The model also demonstrates a significant improvement on defense capability of adversarial examples.