 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Influence: Data Attribution with Baseline
Aug 07, 2025As an effective approach to quantify how training samples influence test sample, data attribution is crucial for understanding data and model and further enhance the transparency of machine learning models. We find that prevailing data attribution methods based on leave-one-out (LOO) strategy suffer from the local-based explanation, as these LOO-based methods only perturb a single training sample, and overlook the collective influence in the training set. On the other hand, the lack of baseline in many data attribution methods reduces the flexibility of the explanation, e.g., failing to provide counterfactual explanations. In this paper, we propose Integrated Influence, a novel data attribution method that incorporates a baseline approach. Our method defines a baseline dataset, follows a data degeneration process to transition the current dataset to the baseline, and accumulates the influence of each sample throughout this process. We provide a solid theoretical framework for our method, and further demonstrate that popular methods, such as influence functions, can be viewed as special cases of our approach. Experimental results show that Integrated Influence generates more reliable data attributions compared to existing methods in both data attribution task and mislablled example identification task.
Task-oriented Time Series Imputation Evaluation via Generalized Representers
Oct 10, 2024



Time series analysis is widely used in many fields such as power energy, economics, and transportation, including different tasks such as forecasting, anomaly detection, classification, etc. Missing values are widely observed in these tasks, and often leading to unpredictable negative effects on existing methods, hindering their further application. In response to this situation, existing time series imputation methods mainly focus on restoring sequences based on their data characteristics, while ignoring the performance of the restored sequences in downstream tasks. Considering different requirements of downstream tasks (e.g., forecasting), this paper proposes an efficient downstream task-oriented time series imputation evaluation approach. By combining time series imputation with neural network models used for downstream tasks, the gain of different imputation strategies on downstream tasks is estimated without retraining, and the most favorable imputation value for downstream tasks is given by combining different imputation strategies according to the estimated gain.
CURLS: Causal Rule Learning for Subgroups with Significant Treatment Effect
Jul 01, 2024In causal inference, estimating heterogeneous treatment effects (HTE) is critical for identifying how different subgroups respond to interventions, with broad applications in fields such as precision medicine and personalized advertising. Although HTE estimation methods aim to improve accuracy, how to provide explicit subgroup descriptions remains unclear, hindering data interpretation and strategic intervention management. In this paper, we propose CURLS, a novel rule learning method leveraging HTE, which can effectively describe subgroups with significant treatment effects. Specifically, we frame causal rule learning as a discrete optimization problem, finely balancing treatment effect with variance and considering the rule interpretability. We design an iterative procedure based on the minorize-maximization algorithm and solve a submodular lower bound as an approximation for the original. Quantitative experiments and qualitative case studies verify that compared with state-of-the-art methods, CURLS can find subgroups where the estimated and true effects are 16.1% and 13.8% higher and the variance is 12.0% smaller, while maintaining similar or better estimation accuracy and rule interpretability. Code is available at https://osf.io/zwp2k/.
SLIM: a Scalable Light-weight Root Cause Analysis for Imbalanced Data in Microservice
May 31, 2024



The newly deployed service -- one kind of change service, could lead to a new type of minority fault. Existing state-of-the-art methods for fault localization rarely consider the imbalanced fault classification in change service. This paper proposes a novel method that utilizes decision rule sets to deal with highly imbalanced data by optimizing the F1 score subject to cardinality constraints. The proposed method greedily generates the rule with maximal marginal gain and uses an efficient minorize-maximization (MM) approach to select rules iteratively, maximizing a non-monotone submodular lower bound. Compared with existing fault localization algorithms, our algorithm can adapt to the imbalanced fault scenario of change service, and provide interpretable fault causes which are easy to understand and verify. Our method can also be deployed in the online training setting, with only about 15% training overhead compared to the current SOTA methods. Empirical studies showcase that our algorithm outperforms existing fault localization algorithms in both accuracy and model interpretability.
Interactive Generalized Additive Model and Its Applications in Electric Load Forecasting
Oct 24, 2023



Electric load forecasting is an indispensable component of electric power system planning and management. Inaccurate load forecasting may lead to the threat of outages or a waste of energy. Accurate electric load forecasting is challenging when there is limited data or even no data, such as load forecasting in holiday, or under extreme weather conditions. As high-stakes decision-making usually follows after load forecasting, model interpretability is crucial for the adoption of forecasting models. In this paper, we propose an interactive GAM which is not only interpretable but also can incorporate specific domain knowledge in electric power industry for improved performance. This boosting-based GAM leverages piecewise linear functions and can be learned through our efficient algorithm. In both public benchmark and electricity datasets, our interactive GAM outperforms current state-of-the-art methods and demonstrates good generalization ability in the cases of extreme weather events. We launched a user-friendly web-based tool based on interactive GAM and already incorporated it into our eForecaster product, a unified AI platform for electricity forecasting.
SaDI: A Self-adaptive Decomposed Interpretable Framework for Electric Load Forecasting under Extreme Events
Jun 14, 2023



Accurate prediction of electric load is crucial in power grid planning and management. In this paper, we solve the electric load forecasting problem under extreme events such as scorching heats. One challenge for accurate forecasting is the lack of training samples under extreme conditions. Also load usually changes dramatically in these extreme conditions, which calls for interpretable model to make better decisions. In this paper, we propose a novel forecasting framework, named Self-adaptive Decomposed Interpretable framework~(SaDI), which ensembles long-term trend, short-term trend, and period modelings to capture temporal characteristics in different components. The external variable triggered loss is proposed for the imbalanced learning under extreme events. Furthermore, Generalized Additive Model (GAM) is employed in the framework for desirable interpretability. The experiments on both Central China electric load and public energy meters from buildings show that the proposed SaDI framework achieves average 22.14% improvement compared with the current state-of-the-art algorithms in forecasting under extreme events in terms of daily mean of normalized RMSE. Code, Public datasets, and Appendix are available at: https://doi.org/10.24433/CO.9696980.v1 .
Robust Dominant Periodicity Detection for Time Series with Missing Data
Mar 06, 2023



Periodicity detection is an important task in time series analysis, but still a challenging problem due to the diverse characteristics of time series data like abrupt trend change, outlier, noise, and especially block missing data. In this paper, we propose a robust and effective periodicity detection algorithm for time series with block missing data. We first design a robust trend filter to remove the interference of complicated trend patterns under missing data. Then, we propose a robust autocorrelation function (ACF) that can handle missing values and outliers effectively. We rigorously prove that the proposed robust ACF can still work well when the length of the missing block is less than $1/3$ of the period length. Last, by combining the time-frequency information, our algorithm can generate the period length accurately. The experimental results demonstrate that our algorithm outperforms existing periodicity detection algorithms on real-world time series datasets.
* Accepted by 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023)
Learning Interpretable Decision Rule Sets: A Submodular Optimization Approach
Jun 08, 2022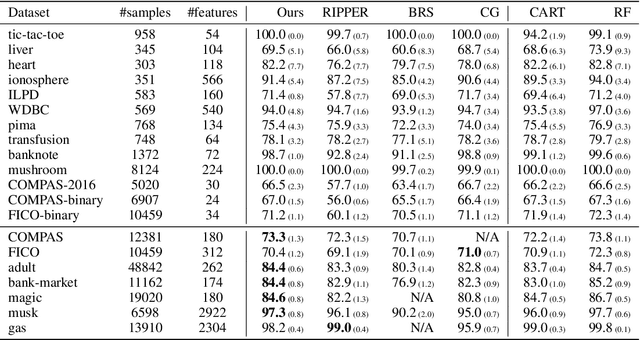
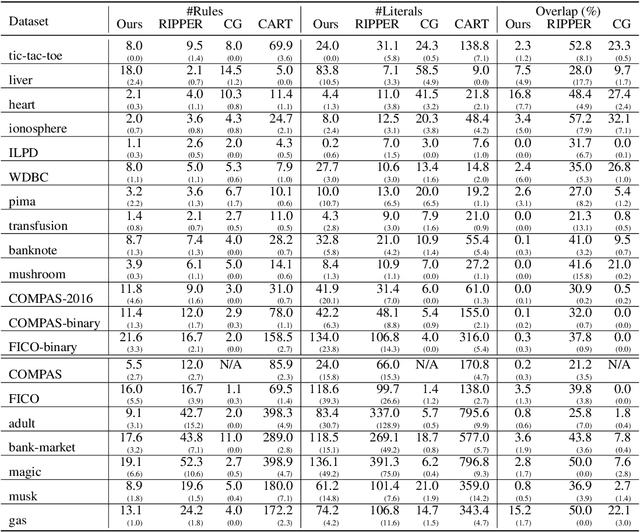
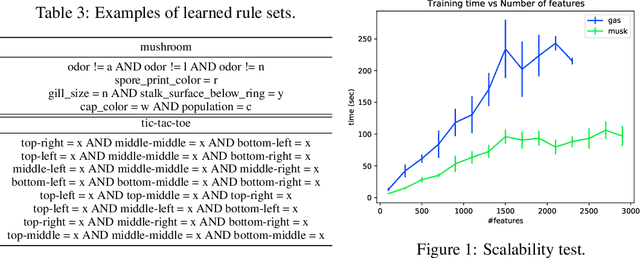
Rule sets are highly interpretable logical models in which the predicates for decision are expressed in disjunctive normal form (DNF, OR-of-ANDs), or, equivalently, the overall model comprises an unordered collection of if-then decision rules. In this paper, we consider a submodular optimization based approach for learning rule sets. The learning problem is framed as a subset selection task in which a subset of all possible rules needs to be selected to form an accurate and interpretable rule set. We employ an objective function that exhibits submodularity and thus is amenable to submodular optimization techniques. To overcome the difficulty arose from dealing with the exponential-sized ground set of rules, the subproblem of searching a rule is casted as another subset selection task that asks for a subset of features. We show it is possible to write the induced objective function for the subproblem as a difference of two submodular (DS) functions to make it approximately solvable by DS optimization algorithms. Overall, the proposed approach is simple, scalable, and likely to be benefited from further research on submodular optimization. Experiments on real datasets demonstrate the effectiveness of our method.
NetRCA: An Effective Network Fault Cause Localization Algorithm
Mar 07, 2022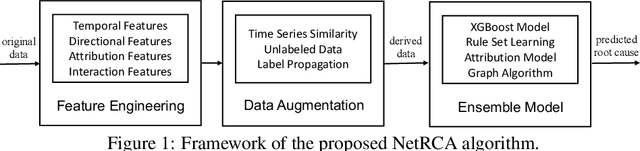
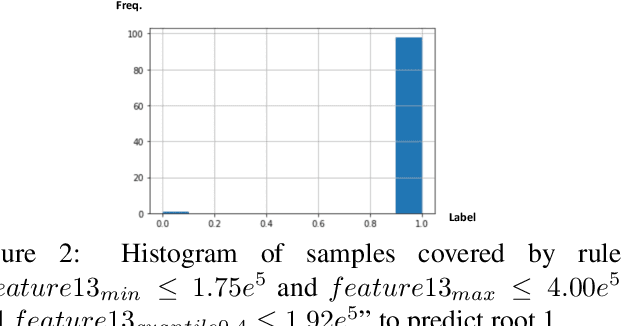
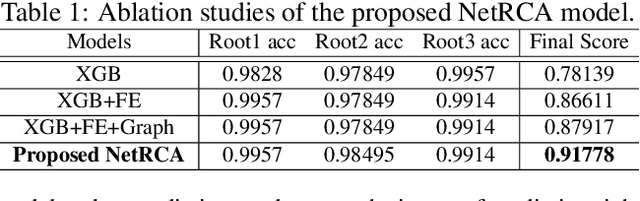
Localizing the root cause of network faults is crucial to network operation and maintenance. However, due to the complicated network architectures and wireless environments, as well as limited labeled data, accurately localizing the true root cause is challenging. In this paper, we propose a novel algorithm named NetRCA to deal with this problem. Firstly, we extract effective derived features from the original raw data by considering temporal, directional, attribution, and interaction characteristics. Secondly, we adopt multivariate time series similarity and label propagation to generate new training data from both labeled and unlabeled data to overcome the lack of labeled samples. Thirdly, we design an ensemble model which combines XGBoost, rule set learning, attribution model, and graph algorithm, to fully utilize all data information and enhance performance. Finally, experiments and analysis are conducted on the real-world dataset from ICASSP 2022 AIOps Challenge to demonstrate the superiority and effectiveness of our approach.
A Robust and Efficient Multi-Scale Seasonal-Trend Decomposition
Sep 18, 2021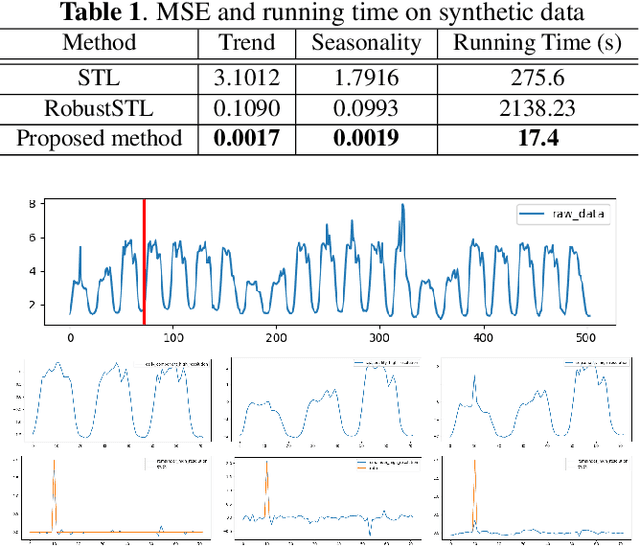
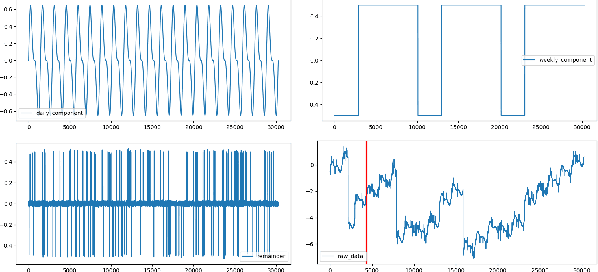
Many real-world time series exhibit multiple seasonality with different lengths. The removal of seasonal components is crucial in numerous applications of time series, including forecasting and anomaly detection. However, many seasonal-trend decomposition algorithms suffer from high computational cost and require a large amount of data when multiple seasonal components exist, especially when the periodic length is long. In this paper, we propose a general and efficient multi-scale seasonal-trend decomposition algorithm for time series with multiple seasonality. We first down-sample the original time series onto a lower resolution, and then convert it to a time series with single seasonality. Thus, existing seasonal-trend decomposition algorithms can be applied directly to obtain the rough estimates of trend and the seasonal component corresponding to the longer periodic length. By considering the relationship between different resolutions, we formulate the recovery of different components on the high resolution as an optimization problem, which is solved efficiently by our alternative direction multiplier method (ADMM) based algorithm. Our experimental results demonstrate the accurate decomposition results with significantly improved efficiency.
* Accepted by 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2021)