 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
ProTAL: A Drag-and-Link Video Programming Framework for Temporal Action Localization
May 23, 2025



Temporal Action Localization (TAL) aims to detect the start and end timestamps of actions in a video. However, the training of TAL models requires a substantial amount of manually annotated data. Data programming is an efficient method to create training labels with a series of human-defined labeling functions. However, its application in TAL faces difficulties of defining complex actions in the context of temporal video frames. In this paper, we propose ProTAL, a drag-and-link video programming framework for TAL. ProTAL enables users to define \textbf{key events} by dragging nodes representing body parts and objects and linking them to constrain the relations (direction, distance, etc.). These definitions are used to generate action labels for large-scale unlabelled videos. A semi-supervised method is then employed to train TAL models with such labels. We demonstrate the effectiveness of ProTAL through a usage scenario and a user study, providing insights into designing video programming framework.
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
Jan 24, 2025



This paper introduces the open-source dataset WanJuanSiLu, designed to provide high-quality training corpora for low-resource languages, thereby advancing the research and development of multilingual models. To achieve this, we have developed a systematic data processing framework tailored for low-resource languages. This framework encompasses key stages such as data extraction, corpus cleaning, content deduplication, security filtering, quality evaluation, and theme classification. Through the implementation of this framework, we have significantly improved both the quality and security of the dataset, while maintaining its linguistic diversity. As of now, data for all five languages have been fully open-sourced. The dataset can be accessed at https://opendatalab.com/applyMultilingualCorpus, and GitHub repository is available at https://github.com/opendatalab/WanJuan3.0
Mining Public Opinion on Twitter about Natural Disaster Response Using Machine Learning Techniques
Jun 01, 2020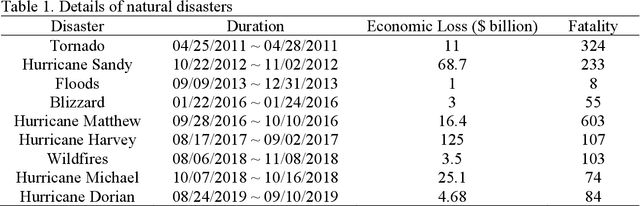
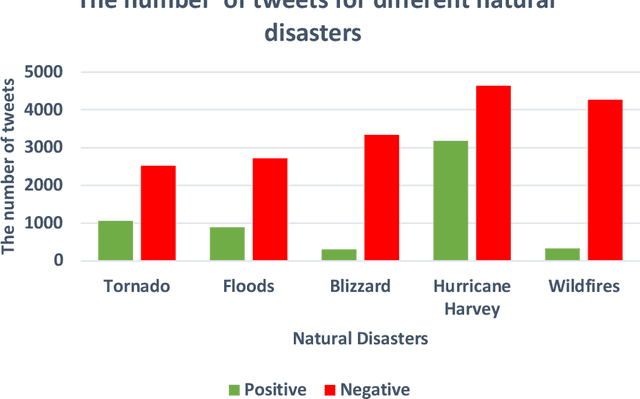

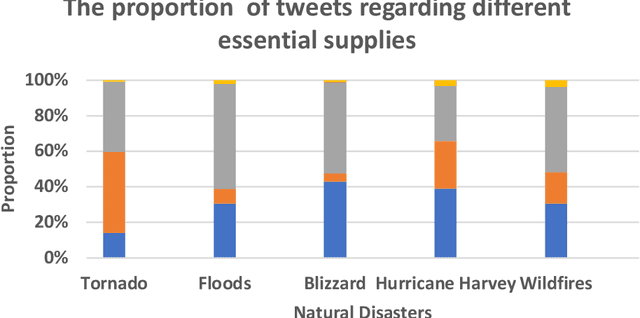
With the development of the Internet, social media has become an essential channel for posting disaster-related information. Analyzing attitudes hidden in these texts, known as sentiment analysis, is crucial for the government or relief agencies to improve disaster response efficiency, but it has not received sufficient attention. This paper aims to fill this gap by focusing on investigating public attitudes towards disaster response and analyzing targeted relief supplies during disaster relief. The research comprises four steps. First, this paper implements Python in grasping Twitter data, and then, we assess public perceptron quantitatively by these opinioned texts, which contain information like the demand for targeted relief supplies, satisfactions of disaster response and fear of the public. A natural disaster dataset with sentiment labels is created, which contains 49,816 Twitter data about natural disasters in the United States. Second, this paper proposes eight machine learning models for sentiment prediction, which are the most popular models used in classification problems. Third, the comparison of these models is conducted via various metrics, and this paper also discusses the optimization method of these models from the perspective of model parameters and input data structures. Finally, a set of real-world instances are studied from the perspective of analyzing changes of public opinion during different natural disasters and understanding the relationship between the same hazard and time series. Results in this paper demonstrate the feasibility and validation of the proposed research approach and provide relief agencies with insights into better disaster response.