 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated interpretation of congenital heart disease from multi-view echocardiograms
Nov 30, 2023



Congenital heart disease (CHD) is the most common birth defect and the leading cause of neonate death in China. Clinical diagnosis can be based on the selected 2D key-frames from five views. Limited by the availability of multi-view data, most methods have to rely on the insufficient single view analysis. This study proposes to automatically analyze the multi-view echocardiograms with a practical end-to-end framework. We collect the five-view echocardiograms video records of 1308 subjects (including normal controls, ventricular septal defect (VSD) patients and atrial septal defect (ASD) patients) with both disease labels and standard-view key-frame labels. Depthwise separable convolution-based multi-channel networks are adopted to largely reduce the network parameters. We also approach the imbalanced class problem by augmenting the positive training samples. Our 2D key-frame model can diagnose CHD or negative samples with an accuracy of 95.4\%, and in negative, VSD or ASD classification with an accuracy of 92.3\%. To further alleviate the work of key-frame selection in real-world implementation, we propose an adaptive soft attention scheme to directly explore the raw video data. Four kinds of neural aggregation methods are systematically investigated to fuse the information of an arbitrary number of frames in a video. Moreover, with a view detection module, the system can work without the view records. Our video-based model can diagnose with an accuracy of 93.9\% (binary classification), and 92.1\% (3-class classification) in a collected 2D video testing set, which does not need key-frame selection and view annotation in testing. The detailed ablation study and the interpretability analysis are provided.
* Published in Medical Image Analysis
Self-Infilling Code Generation
Nov 29, 2023This work introduces a general code generation framework that incorporates infilling operations into auto-regressive decoding. Our approach capitalizes on the observation that recent code language models with infilling capabilities can perform \emph{self-infilling}: whereas infilling operations aim to fill in the middle based on a predefined prefix and suffix, self-infilling sequentially generates both such surrounding context and the infilled content. We utilize this feature to develop an infilling-augmented decoding process that facilitates non-monotonic generation. This approach allows for postponing the generation of uncertain code snippets until a definitive suffix is established, leading to improved control over the generation sequence. In addition, it facilitates a looping mechanism, which can iteratively update and synchronize each piece of generation in a cyclic manner. Extensive experiments are conducted to demonstrate that our proposed decoding process is effective in enhancing regularity and quality across several code generation benchmarks.
Attentive Multi-Layer Perceptron for Non-autoregressive Generation
Oct 14, 2023Autoregressive~(AR) generation almost dominates sequence generation for its efficacy. Recently, non-autoregressive~(NAR) generation gains increasing popularity for its efficiency and growing efficacy. However, its efficiency is still bottlenecked by quadratic complexity in sequence lengths, which is prohibitive for scaling to long sequence generation and few works have been done to mitigate this problem. In this paper, we propose a novel MLP variant, \textbf{A}ttentive \textbf{M}ulti-\textbf{L}ayer \textbf{P}erceptron~(AMLP), to produce a generation model with linear time and space complexity. Different from classic MLP with static and learnable projection matrices, AMLP leverages adaptive projections computed from inputs in an attentive mode. The sample-aware adaptive projections enable communications among tokens in a sequence, and model the measurement between the query and key space. Furthermore, we marry AMLP with popular NAR models, deriving a highly efficient NAR-AMLP architecture with linear time and space complexity. Empirical results show that such marriage architecture surpasses competitive efficient NAR models, by a significant margin on text-to-speech synthesis and machine translation. We also test AMLP's self- and cross-attention ability separately with extensive ablation experiments, and find them comparable or even superior to the other efficient models. The efficiency analysis further shows that AMLP extremely reduces the memory cost against vanilla non-autoregressive models for long sequences.
Universal Sleep Decoder: Aligning awake and sleep neural representation across subjects
Sep 28, 2023



Decoding memory content from brain activity during sleep has long been a goal in neuroscience. While spontaneous reactivation of memories during sleep in rodents is known to support memory consolidation and offline learning, capturing memory replay in humans is challenging due to the absence of well-annotated sleep datasets and the substantial differences in neural patterns between wakefulness and sleep. To address these challenges, we designed a novel cognitive neuroscience experiment and collected a comprehensive, well-annotated electroencephalography (EEG) dataset from 52 subjects during both wakefulness and sleep. Leveraging this benchmark dataset, we developed the Universal Sleep Decoder (USD) to align neural representations between wakefulness and sleep across subjects. Our model achieves up to 16.6% top-1 zero-shot accuracy on unseen subjects, comparable to decoding performances using individual sleep data. Furthermore, fine-tuning USD on test subjects enhances decoding accuracy to 25.9% top-1 accuracy, a substantial improvement over the baseline chance of 6.7%. Model comparison and ablation analyses reveal that our design choices, including the use of (i) an additional contrastive objective to integrate awake and sleep neural signals and (ii) the pretrain-finetune paradigm to incorporate different subjects, significantly contribute to these performances. Collectively, our findings and methodologies represent a significant advancement in the field of sleep decoding.
K-means Clustering Based Feature Consistency Alignment for Label-free Model Evaluation
Apr 17, 2023The label-free model evaluation aims to predict the model performance on various test sets without relying on ground truths. The main challenge of this task is the absence of labels in the test data, unlike in classical supervised model evaluation. This paper presents our solutions for the 1st DataCV Challenge of the Visual Dataset Understanding workshop at CVPR 2023. Firstly, we propose a novel method called K-means Clustering Based Feature Consistency Alignment (KCFCA), which is tailored to handle the distribution shifts of various datasets. KCFCA utilizes the K-means algorithm to cluster labeled training sets and unlabeled test sets, and then aligns the cluster centers with feature consistency. Secondly, we develop a dynamic regression model to capture the relationship between the shifts in distribution and model accuracy. Thirdly, we design an algorithm to discover the outlier model factors, eliminate the outlier models, and combine the strengths of multiple autoeval models. On the DataCV Challenge leaderboard, our approach secured 2nd place with an RMSE of 6.8526. Our method significantly improved over the best baseline method by 36\% (6.8526 vs. 10.7378). Furthermore, our method achieves a relatively more robust and optimal single model performance on the validation dataset.
Retrieved Sequence Augmentation for Protein Representation Learning
Feb 24, 2023Protein language models have excelled in a variety of tasks, ranging from structure prediction to protein engineering. However, proteins are highly diverse in functions and structures, and current state-of-the-art models including the latest version of AlphaFold rely on Multiple Sequence Alignments (MSA) to feed in the evolutionary knowledge. Despite their success, heavy computational overheads, as well as the de novo and orphan proteins remain great challenges in protein representation learning. In this work, we show that MSAaugmented models inherently belong to retrievalaugmented methods. Motivated by this finding, we introduce Retrieved Sequence Augmentation(RSA) for protein representation learning without additional alignment or pre-processing. RSA links query protein sequences to a set of sequences with similar structures or properties in the database and combines these sequences for downstream prediction. We show that protein language models benefit from the retrieval enhancement on both structure prediction and property prediction tasks, with a 5% improvement on MSA Transformer on average while being 373 times faster. In addition, we show that our model can transfer to new protein domains better and outperforms MSA Transformer on de novo protein prediction. Our study fills a much-encountered gap in protein prediction and brings us a step closer to demystifying the domain knowledge needed to understand protein sequences. Code is available on https://github.com/HKUNLP/RSA.
A Reparameterized Discrete Diffusion Model for Text Generation
Feb 11, 2023This work studies discrete diffusion probabilistic models with applications to natural language generation. We derive an alternative yet equivalent formulation of the sampling from discrete diffusion processes and leverage this insight to develop a family of reparameterized discrete diffusion models. The derived generic framework is highly flexible, offers a fresh perspective of the generation process in discrete diffusion models, and features more effective training and decoding techniques. We conduct extensive experiments to evaluate the text generation capability of our model, demonstrating significant improvements over existing diffusion models.
Efficient Attention via Control Variates
Feb 09, 2023Random-feature-based attention (RFA) is an efficient approximation of softmax attention with linear runtime and space complexity. However, the approximation gap between RFA and conventional softmax attention is not well studied. Built upon previous progress of RFA, we characterize this gap through the lens of control variates and show that RFA can be decomposed into a sum of multiple control variate estimators for each element in the sequence. This new framework reveals that exact softmax attention can be recovered from RFA by manipulating each control variate. Besides, it allows us to develop a more flexible form of control variates, resulting in a novel attention mechanism that significantly reduces the approximation gap while maintaining linear complexity. Extensive experiments demonstrate that our model outperforms state-of-the-art efficient attention mechanisms on both vision and language tasks.
CAB: Comprehensive Attention Benchmarking on Long Sequence Modeling
Oct 19, 2022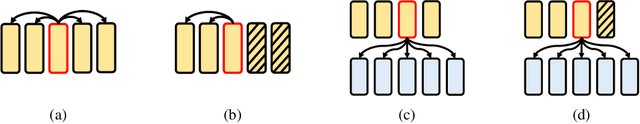
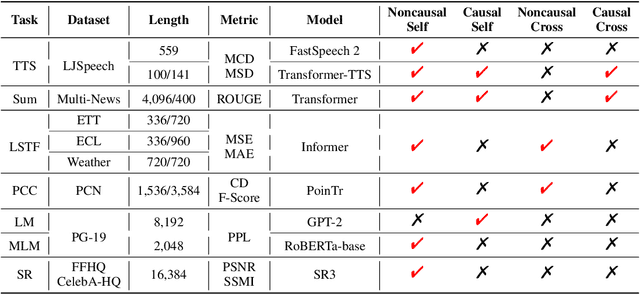
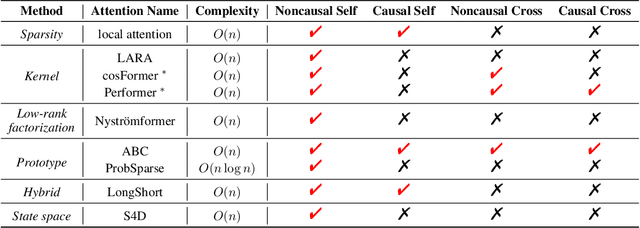
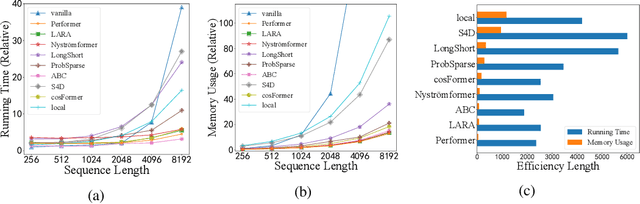
Transformer has achieved remarkable success in language, image, and speech processing. Recently, various efficient attention architectures have been proposed to improve transformer's efficiency while largely preserving its efficacy, especially in modeling long sequences. A widely-used benchmark to test these efficient methods' capability on long-range modeling is Long Range Arena (LRA). However, LRA only focuses on the standard bidirectional (or noncausal) self attention, and completely ignores cross attentions and unidirectional (or causal) attentions, which are equally important to downstream applications. Although designing cross and causal variants of an attention method is straightforward for vanilla attention, it is often challenging for efficient attentions with subquadratic time and memory complexity. In this paper, we propose Comprehensive Attention Benchmark (CAB) under a fine-grained attention taxonomy with four distinguishable attention patterns, namely, noncausal self, causal self, noncausal cross, and causal cross attentions. CAB collects seven real-world tasks from different research areas to evaluate efficient attentions under the four attention patterns. Among these tasks, CAB validates efficient attentions in eight backbone networks to show their generalization across neural architectures. We conduct exhaustive experiments to benchmark the performances of nine widely-used efficient attention architectures designed with different philosophies on CAB. Extensive experimental results also shed light on the fundamental problems of efficient attentions, such as efficiency length against vanilla attention, performance consistency across attention patterns, the benefit of attention mechanisms, and interpolation/extrapolation on long-context language modeling.
Learning Feature Disentanglement and Dynamic Fusion for Recaptured Image Forensic
Jun 13, 2022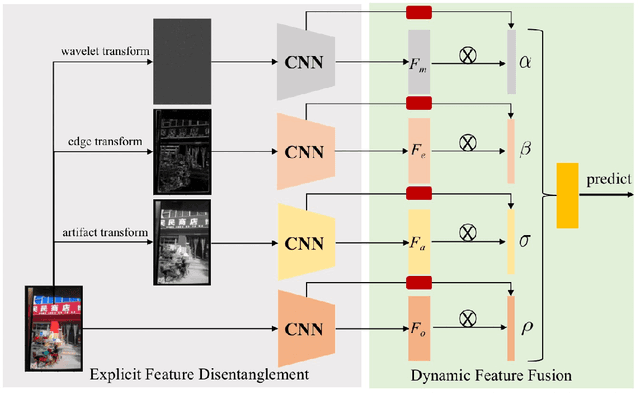
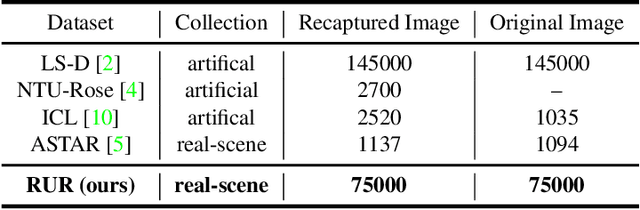
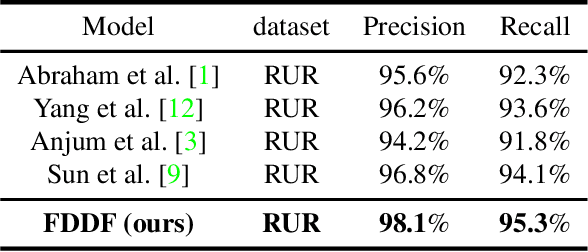
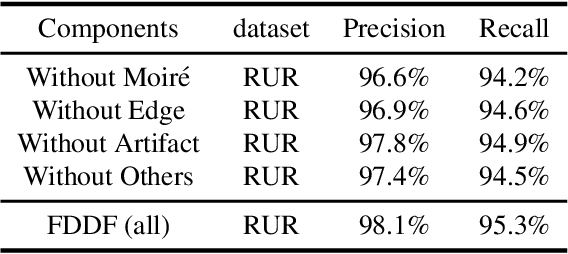
Image recapture seriously breaks the fairness of artificial intelligent (AI) systems, which deceives the system by recapturing others' images. Most of the existing recapture models can only address a single pattern of recapture (e.g., moire, edge, artifact, and others) based on the datasets with simulated recaptured images using fixed electronic devices. In this paper, we explicitly redefine image recapture forensic task as four patterns of image recapture recognition, i.e., moire recapture, edge recapture, artifact recapture, and other recapture. Meanwhile, we propose a novel Feature Disentanglement and Dynamic Fusion (FDDF) model to adaptively learn the most effective recapture feature representation for covering different recapture pattern recognition. Furthermore, we collect a large-scale Real-scene Universal Recapture (RUR) dataset containing various recapture patterns, which is about five times the number of previously published datasets. To the best of our knowledge, we are the first to propose a general model and a general real-scene large-scale dataset for recaptured image forensic. Extensive experiments show that our proposed FDDF can achieve state-of-the-art performance on the RUR dataset.