 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Discounted Stochastic Two-Player Games with Near-Optimal Time and Sample Complexity
Aug 29, 2019In this paper, we settle the sampling complexity of solving discounted two-player turn-based zero-sum stochastic games up to polylogarithmic factors. Given a stochastic game with discount factor $\gamma\in(0,1)$ we provide an algorithm that computes an $\epsilon$-optimal strategy with high-probability given $\tilde{O}((1 - \gamma)^{-3} \epsilon^{-2})$ samples from the transition function for each state-action-pair. Our algorithm runs in time nearly linear in the number of samples and uses space nearly linear in the number of state-action pairs. As stochastic games generalize Markov decision processes (MDPs) our runtime and sample complexities are optimal due to Azar et al (2013). We achieve our results by showing how to generalize a near-optimal Q-learning based algorithms for MDP, in particular Sidford et al (2018), to two-player strategy computation algorithms. This overcomes limitations of standard Q-learning and strategy iteration or alternating minimization based approaches and we hope will pave the way for future reinforcement learning results by facilitating the extension of MDP results to multi-agent settings with little loss.
On the Optimality of Sparse Model-Based Planning for Markov Decision Processes
Jul 04, 2019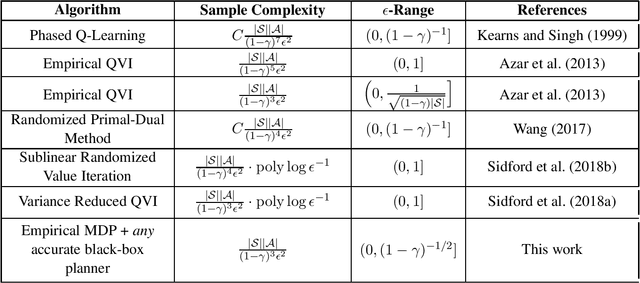
This work considers the sample complexity of obtaining an $\epsilon$-optimal policy in a discounted Markov Decision Process (MDP), given only access to a generative model. In this model, the learner accesses the underlying transition model via a sampling oracle that provides a sample of the next state, when given any state-action pair as input. In this work, we study the effectiveness of the most natural plug-in approach to model-based planning: we build the maximum likelihood estimate of the transition model in the MDP from observations and then find an optimal policy in this empirical MDP. We ask arguably the most basic and unresolved question in model-based planning: is the na\"ive "plug-in" approach, non-asymptotically, minimax optimal in the quality of the policy it finds, given a fixed sample size? With access to a generative model, we resolve this question in the strongest possible sense: our main result shows that \emph{any} high accuracy solution in the plug-in model constructed with $N$ samples, provides an $\epsilon$-optimal policy in the true underlying MDP. In comparison, all prior (non-asymptotically) minimax optimal results use model-free approaches, such as the Variance Reduced Q-value iteration algorithm (Sidford et al 2018), while the best known model-based results (e.g. Azar et al 2013) require larger sample sample sizes in their dependence on the planning horizon or the state space. Notably, we show that the model-based approach allows the use of \emph{any} efficient planning algorithm in the empirical MDP, which simplifies the algorithm design as this approach does not tie the algorithm to the sampling procedure. The core of our analysis is a novel "absorbing MDP" construction to address the statistical dependency issues that arise in the analysis of model-based planning approaches, a construction which may be helpful more generally.
Reinforcement Learning in Feature Space: Matrix Bandit, Kernels, and Regret Bound
Jun 13, 2019Exploration in reinforcement learning (RL) suffers from the curse of dimensionality when the state-action space is large. A common practice is to parameterize the high-dimensional value and policy functions using given features. However existing methods either have no theoretical guarantee or suffer a regret that is exponential in the planning horizon $H$. In this paper, we propose an online RL algorithm, namely the MatrixRL, that leverages ideas from linear bandit to learn a low-dimensional representation of the probability transition model while carefully balancing the exploitation-exploration tradeoff. We show that MatrixRL achieves a regret bound ${O}\big(H^2d\log T\sqrt{T}\big)$ where $d$ is the number of features. MatrixRL has an equivalent kernelized version, which is able to work with an arbitrary kernel Hilbert space without using explicit features. In this case, the kernelized MatrixRL satisfies a regret bound ${O}\big(H^2\widetilde{d}\log T\sqrt{T}\big)$, where $\widetilde{d}$ is the effective dimension of the kernel space. To our best knowledge, for RL using features or kernels, our results are the first regret bounds that are near-optimal in time $T$ and dimension $d$ (or $\widetilde{d}$) and polynomial in the planning horizon $H$.
Feature-Based Q-Learning for Two-Player Stochastic Games
Jun 02, 2019Consider a two-player zero-sum stochastic game where the transition function can be embedded in a given feature space. We propose a two-player Q-learning algorithm for approximating the Nash equilibrium strategy via sampling. The algorithm is shown to find an $\epsilon$-optimal strategy using sample size linear to the number of features. To further improve its sample efficiency, we develop an accelerated algorithm by adopting techniques such as variance reduction, monotonicity preservation and two-sided strategy approximation. We prove that the algorithm is guaranteed to find an $\epsilon$-optimal strategy using no more than $\tilde{\mathcal{O}}(K/(\epsilon^{2}(1-\gamma)^{4}))$ samples with high probability, where $K$ is the number of features and $\gamma$ is a discount factor. The sample, time and space complexities of the algorithm are independent of original dimensions of the game.
Learning to Control in Metric Space with Optimal Regret
May 05, 2019We study online reinforcement learning for finite-horizon deterministic control systems with {\it arbitrary} state and action spaces. Suppose that the transition dynamics and reward function is unknown, but the state and action space is endowed with a metric that characterizes the proximity between different states and actions. We provide a surprisingly simple upper-confidence reinforcement learning algorithm that uses a function approximation oracle to estimate optimistic Q functions from experiences. We show that the regret of the algorithm after $K$ episodes is $O(HL(KH)^{\frac{d-1}{d}}) $ where $L$ is a smoothness parameter, and $d$ is the doubling dimension of the state-action space with respect to the given metric. We also establish a near-matching regret lower bound. The proposed method can be adapted to work for more structured transition systems, including the finite-state case and the case where value functions are linear combinations of features, where the method also achieve the optimal regret.
Sample-Optimal Parametric Q-Learning with Linear Transition Models
Feb 13, 2019Consider a Markov decision process (MDP) that admits a set of state-action features, which can linearly express the process's probabilistic transition model. We propose a parametric Q-learning algorithm that finds an approximate-optimal policy using a sample size proportional to the feature dimension $K$ and invariant with respect to the size of the state space. To further improve its sample efficiency, we exploit the monotonicity property and intrinsic noise structure of the Bellman operator, provided the existence of anchor state-actions that imply implicit non-negativity in the feature space. We augment the algorithm using techniques of variance reduction, monotonicity preservation, and confidence bounds. It is proved to find a policy which is $\epsilon$-optimal from any initial state with high probability using $\widetilde{O}(K/\epsilon^2(1-\gamma)^3)$ sample transitions for arbitrarily large-scale MDP with a discount factor $\gamma\in(0,1)$. A matching information-theoretical lower bound is proved, confirming the sample optimality of the proposed method with respect to all parameters (up to polylog factors).
Towards a Theoretical Understanding of Hashing-Based Neural Nets
Dec 26, 2018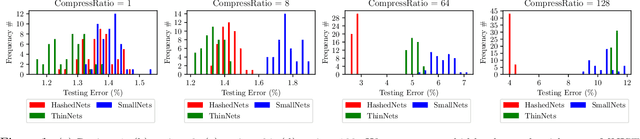
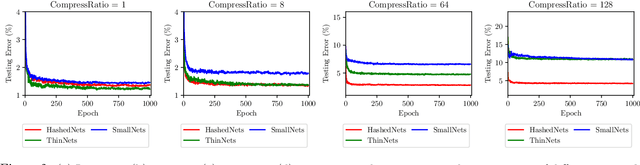
Parameter reduction has been an important topic in deep learning due to the ever-increasing size of deep neural network models and the need to train and run them on resource limited machines. Despite many efforts in this area, there were no rigorous theoretical guarantees on why existing neural net compression methods should work. In this paper, we provide provable guarantees on some hashing-based parameter reduction methods in neural nets. First, we introduce a neural net compression scheme based on random linear sketching (which is usually implemented efficiently via hashing), and show that the sketched (smaller) network is able to approximate the original network on all input data coming from any smooth and well-conditioned low-dimensional manifold. The sketched network can also be trained directly via back-propagation. Next, we study the previously proposed HashedNets architecture and show that the optimization landscape of one-hidden-layer HashedNets has a local strong convexity property similar to a normal fully connected neural network. We complement our theoretical results with empirical verifications.
The Physical Systems Behind Optimization Algorithms
Oct 25, 2018
We use differential equations based approaches to provide some {\it \textbf{physics}} insights into analyzing the dynamics of popular optimization algorithms in machine learning. In particular, we study gradient descent, proximal gradient descent, coordinate gradient descent, proximal coordinate gradient, and Newton's methods as well as their Nesterov's accelerated variants in a unified framework motivated by a natural connection of optimization algorithms to physical systems. Our analysis is applicable to more general algorithms and optimization problems {\it \textbf{beyond}} convexity and strong convexity, e.g. Polyak-\L ojasiewicz and error bound conditions (possibly nonconvex).
On Landscape of Lagrangian Functions and Stochastic Search for Constrained Nonconvex Optimization
Oct 02, 2018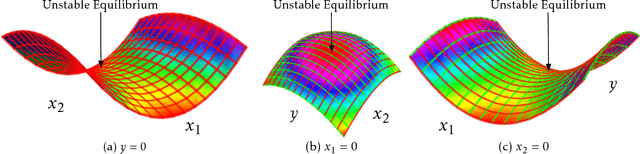
We study constrained nonconvex optimization problems in machine learning, signal processing, and stochastic control. It is well-known that these problems can be rewritten to a minimax problem in a Lagrangian form. However, due to the lack of convexity, their landscape is not well understood and how to find the stable equilibria of the Lagrangian function is still unknown. To bridge the gap, we study the landscape of the Lagrangian function. Further, we define a special class of Lagrangian functions. They enjoy two properties: 1.Equilibria are either stable or unstable (Formal definition in Section 2); 2.Stable equilibria correspond to the global optima of the original problem. We show that a generalized eigenvalue (GEV) problem, including canonical correlation analysis and other problems, belongs to the class. Specifically, we characterize its stable and unstable equilibria by leveraging an invariant group and symmetric property (more details in Section 3). Motivated by these neat geometric structures, we propose a simple, efficient, and stochastic primal-dual algorithm solving the online GEV problem. Theoretically, we provide sufficient conditions, based on which we establish an asymptotic convergence rate and obtain the first sample complexity result for the online GEV problem by diffusion approximations, which are widely used in applied probability and stochastic control. Numerical results are provided to support our theory.
Variance Reduction Methods for Sublinear Reinforcement Learning
Aug 25, 2018
This work considers the problem of provably optimal reinforcement learning for episodic finite horizon MDPs, i.e. how an agent learns to maximize his/her long term reward in an uncertain environment. The main contribution is in providing a novel algorithm --- Variance-reduced Upper Confidence Q-learning (vUCQ) --- which enjoys a regret bound of $\widetilde{O}(\sqrt{HSAT} + H^5SA)$, where the $T$ is the number of time steps the agent acts in the MDP, $S$ is the number of states, $A$ is the number of actions, and $H$ is the (episodic) horizon time. This is the first regret bound that is both sub-linear in the model size and asymptotically optimal. The algorithm is sub-linear in that the time to achieve $\epsilon$-average regret for any constant $\epsilon$ is $O(SA)$, which is a number of samples that is far less than that required to learn any non-trivial estimate of the transition model (the transition model is specified by $O(S^2A)$ parameters). The importance of sub-linear algorithms is largely the motivation for algorithms such as $Q$-learning and other "model free" approaches. vUCQ algorithm also enjoys minimax optimal regret in the long run, matching the $\Omega(\sqrt{HSAT})$ lower bound. Variance-reduced Upper Confidence Q-learning (vUCQ) is a successive refinement method in which the algorithm reduces the variance in $Q$-value estimates and couples this estimation scheme with an upper confidence based algorithm. Technically, the coupling of both of these techniques is what leads to the algorithm enjoying both the sub-linear regret property and the asymptotically optimal regret.