 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear Sample-Optimal Reduction-based Policy Learning for Average Reward MDP
Dec 01, 2022
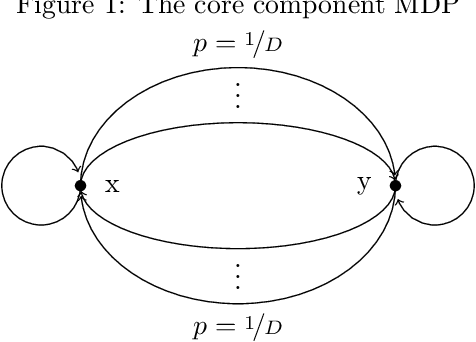
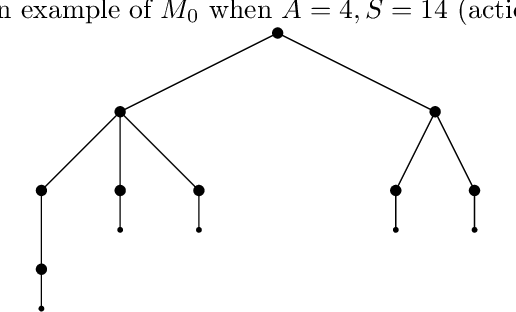
This work considers the sample complexity of obtaining an $\varepsilon$-optimal policy in an average reward Markov Decision Process (AMDP), given access to a generative model (simulator). When the ground-truth MDP is weakly communicating, we prove an upper bound of $\widetilde O(H \varepsilon^{-3} \ln \frac{1}{\delta})$ samples per state-action pair, where $H := sp(h^*)$ is the span of bias of any optimal policy, $\varepsilon$ is the accuracy and $\delta$ is the failure probability. This bound improves the best-known mixing-time-based approaches in [Jin & Sidford 2021], which assume the mixing-time of every deterministic policy is bounded. The core of our analysis is a proper reduction bound from AMDP problems to discounted MDP (DMDP) problems, which may be of independent interests since it allows the application of DMDP algorithms for AMDP in other settings. We complement our upper bound by proving a minimax lower bound of $\Omega(|\mathcal S| |\mathcal A| H \varepsilon^{-2} \ln \frac{1}{\delta})$ total samples, showing that a linear dependent on $H$ is necessary and that our upper bound matches the lower bound in all parameters of $(|\mathcal S|, |\mathcal A|, H, \ln \frac{1}{\delta})$ up to some logarithmic factors.
Contexts can be Cheap: Solving Stochastic Contextual Bandits with Linear Bandit Algorithms
Nov 08, 2022
In this paper, we address the stochastic contextual linear bandit problem, where a decision maker is provided a context (a random set of actions drawn from a distribution). The expected reward of each action is specified by the inner product of the action and an unknown parameter. The goal is to design an algorithm that learns to play as close as possible to the unknown optimal policy after a number of action plays. This problem is considered more challenging than the linear bandit problem, which can be viewed as a contextual bandit problem with a \emph{fixed} context. Surprisingly, in this paper, we show that the stochastic contextual problem can be solved as if it is a linear bandit problem. In particular, we establish a novel reduction framework that converts every stochastic contextual linear bandit instance to a linear bandit instance, when the context distribution is known. When the context distribution is unknown, we establish an algorithm that reduces the stochastic contextual instance to a sequence of linear bandit instances with small misspecifications and achieves nearly the same worst-case regret bound as the algorithm that solves the misspecified linear bandit instances. As a consequence, our results imply a $O(d\sqrt{T\log T})$ high-probability regret bound for contextual linear bandits, making progress in resolving an open problem in (Li et al., 2019), (Li et al., 2021). Our reduction framework opens up a new way to approach stochastic contextual linear bandit problems, and enables improved regret bounds in a number of instances including the batch setting, contextual bandits with misspecifications, contextual bandits with sparse unknown parameters, and contextual bandits with adversarial corruption.
Near-Optimal Sample Complexity Bounds for Constrained MDPs
Jun 13, 2022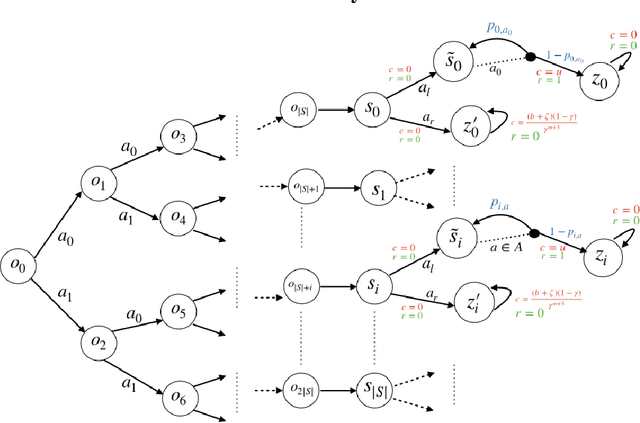
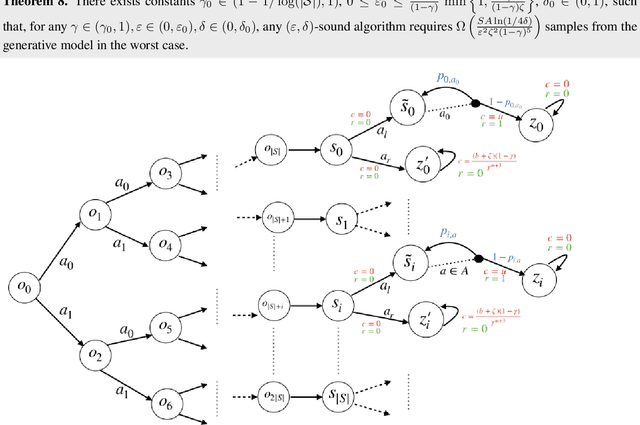
In contrast to the advances in characterizing the sample complexity for solving Markov decision processes (MDPs), the optimal statistical complexity for solving constrained MDPs (CMDPs) remains unknown. We resolve this question by providing minimax upper and lower bounds on the sample complexity for learning near-optimal policies in a discounted CMDP with access to a generative model (simulator). In particular, we design a model-based algorithm that addresses two settings: (i) relaxed feasibility, where small constraint violations are allowed, and (ii) strict feasibility, where the output policy is required to satisfy the constraint. For (i), we prove that our algorithm returns an $\epsilon$-optimal policy with probability $1 - \delta$, by making $\tilde{O}\left(\frac{S A \log(1/\delta)}{(1 - \gamma)^3 \epsilon^2}\right)$ queries to the generative model, thus matching the sample-complexity for unconstrained MDPs. For (ii), we show that the algorithm's sample complexity is upper-bounded by $\tilde{O} \left(\frac{S A \, \log(1/\delta)}{(1 - \gamma)^5 \, \epsilon^2 \zeta^2} \right)$ where $\zeta$ is the problem-dependent Slater constant that characterizes the size of the feasible region. Finally, we prove a matching lower-bound for the strict feasibility setting, thus obtaining the first near minimax optimal bounds for discounted CMDPs. Our results show that learning CMDPs is as easy as MDPs when small constraint violations are allowed, but inherently more difficult when we demand zero constraint violation.
Learning in Distributed Contextual Linear Bandits Without Sharing the Context
Jun 08, 2022Contextual linear bandits is a rich and theoretically important model that has many practical applications. Recently, this setup gained a lot of interest in applications over wireless where communication constraints can be a performance bottleneck, especially when the contexts come from a large $d$-dimensional space. In this paper, we consider a distributed memoryless contextual linear bandit learning problem, where the agents who observe the contexts and take actions are geographically separated from the learner who performs the learning while not seeing the contexts. We assume that contexts are generated from a distribution and propose a method that uses $\approx 5d$ bits per context for the case of unknown context distribution and $0$ bits per context if the context distribution is known, while achieving nearly the same regret bound as if the contexts were directly observable. The former bound improves upon existing bounds by a $\log(T)$ factor, where $T$ is the length of the horizon, while the latter achieves information theoretical tightness.
Provably Efficient Lifelong Reinforcement Learning with Linear Function Approximation
Jun 01, 2022We study lifelong reinforcement learning (RL) in a regret minimization setting of linear contextual Markov decision process (MDP), where the agent needs to learn a multi-task policy while solving a streaming sequence of tasks. We propose an algorithm, called UCB Lifelong Value Distillation (UCBlvd), that provably achieves sublinear regret for any sequence of tasks, which may be adaptively chosen based on the agent's past behaviors. Remarkably, our algorithm uses only sublinear number of planning calls, which means that the agent eventually learns a policy that is near optimal for multiple tasks (seen or unseen) without the need of deliberate planning. A key to this property is a new structural assumption that enables computation sharing across tasks during exploration. Specifically, for $K$ task episodes of horizon $H$, our algorithm has a regret bound $\tilde{\mathcal{O}}(\sqrt{(d^3+d^\prime d)H^4K})$ based on $\mathcal{O}(dH\log(K))$ number of planning calls, where $d$ and $d^\prime$ are the feature dimensions of the dynamics and rewards, respectively. This theoretical guarantee implies that our algorithm can enable a lifelong learning agent to accumulate experiences and learn to rapidly solve new tasks.
Distributed Contextual Linear Bandits with Minimax Optimal Communication Cost
May 26, 2022

We study distributed contextual linear bandits with stochastic contexts, where $N$ agents act cooperatively to solve a linear bandit-optimization problem with $d$-dimensional features. For this problem, we propose a distributed batch elimination version of the LinUCB algorithm, DisBE-LUCB, where the agents share information among each other through a central server. We prove that over $T$ rounds ($NT$ actions in total) the communication cost of DisBE-LUCB is only $\tilde{\mathcal{O}}(dN)$ and its regret is at most $\tilde{\mathcal{O}}(\sqrt{dNT})$, which is of the same order as that incurred by an optimal single-agent algorithm for $NT$ rounds. Remarkably, we derive an information-theoretic lower bound on the communication cost of the distributed contextual linear bandit problem with stochastic contexts, and prove that our proposed algorithm is nearly minimax optimal in terms of \emph{both regret and communication cost}. Finally, we propose DecBE-LUCB, a fully decentralized version of DisBE-LUCB, which operates without a central server, where agents share information with their \emph{immediate neighbors} through a carefully designed consensus procedure.
Solving Multi-Arm Bandit Using a Few Bits of Communication
Nov 11, 2021
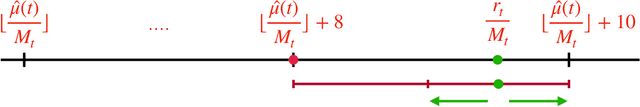
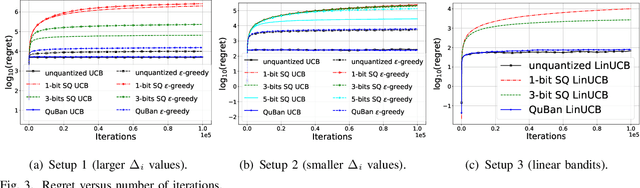
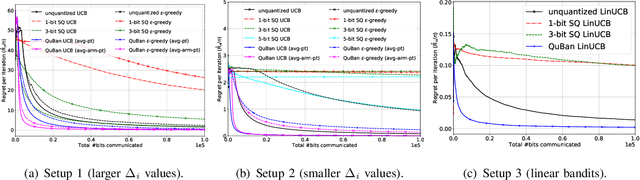
The multi-armed bandit (MAB) problem is an active learning framework that aims to select the best among a set of actions by sequentially observing rewards. Recently, it has become popular for a number of applications over wireless networks, where communication constraints can form a bottleneck. Existing works usually fail to address this issue and can become infeasible in certain applications. In this paper we address the communication problem by optimizing the communication of rewards collected by distributed agents. By providing nearly matching upper and lower bounds, we tightly characterize the number of bits needed per reward for the learner to accurately learn without suffering additional regret. In particular, we establish a generic reward quantization algorithm, QuBan, that can be applied on top of any (no-regret) MAB algorithm to form a new communication-efficient counterpart, that requires only a few (as low as 3) bits to be sent per iteration while preserving the same regret bound. Our lower bound is established via constructing hard instances from a subgaussian distribution. Our theory is further corroborated by numerically experiments.
Settling the Horizon-Dependence of Sample Complexity in Reinforcement Learning
Nov 01, 2021Recently there is a surge of interest in understanding the horizon-dependence of the sample complexity in reinforcement learning (RL). Notably, for an RL environment with horizon length $H$, previous work have shown that there is a probably approximately correct (PAC) algorithm that learns an $O(1)$-optimal policy using $\mathrm{polylog}(H)$ episodes of environment interactions when the number of states and actions is fixed. It is yet unknown whether the $\mathrm{polylog}(H)$ dependence is necessary or not. In this work, we resolve this question by developing an algorithm that achieves the same PAC guarantee while using only $O(1)$ episodes of environment interactions, completely settling the horizon-dependence of the sample complexity in RL. We achieve this bound by (i) establishing a connection between value functions in discounted and finite-horizon Markov decision processes (MDPs) and (ii) a novel perturbation analysis in MDPs. We believe our new techniques are of independent interest and could be applied in related questions in RL.
Breaking the Moments Condition Barrier: No-Regret Algorithm for Bandits with Super Heavy-Tailed Payoffs
Oct 26, 2021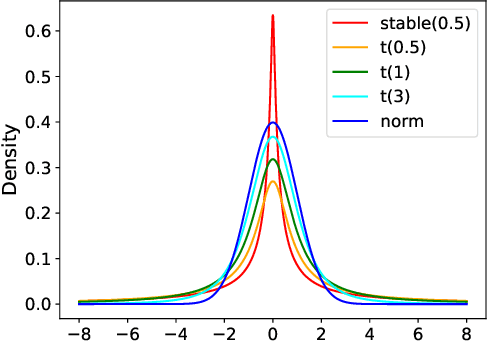
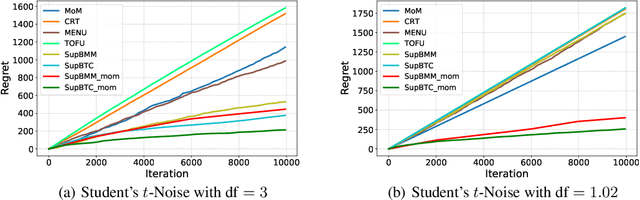
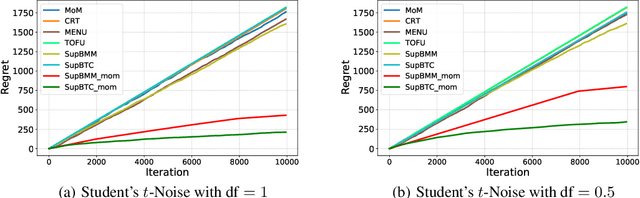
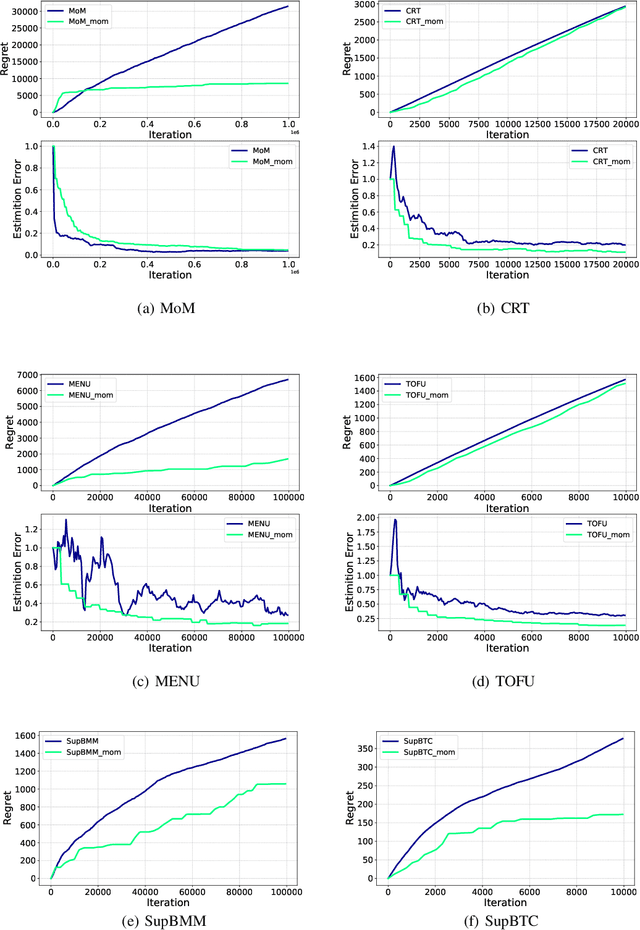
Despite a large amount of effort in dealing with heavy-tailed error in machine learning, little is known when moments of the error can become non-existential: the random noise $\eta$ satisfies Pr$\left[|\eta| > |y|\right] \le 1/|y|^{\alpha}$ for some $\alpha > 0$. We make the first attempt to actively handle such super heavy-tailed noise in bandit learning problems: We propose a novel robust statistical estimator, mean of medians, which estimates a random variable by computing the empirical mean of a sequence of empirical medians. We then present a generic reductionist algorithmic framework for solving bandit learning problems (including multi-armed and linear bandit problem): the mean of medians estimator can be applied to nearly any bandit learning algorithm as a black-box filtering for its reward signals and obtain similar regret bound as if the reward is sub-Gaussian. We show that the regret bound is near-optimal even with very heavy-tailed noise. We also empirically demonstrate the effectiveness of the proposed algorithm, which further corroborates our theoretical results.
Decentralized Cooperative Multi-Agent Reinforcement Learning with Exploration
Oct 12, 2021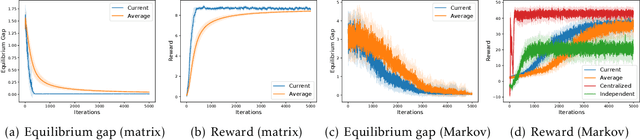

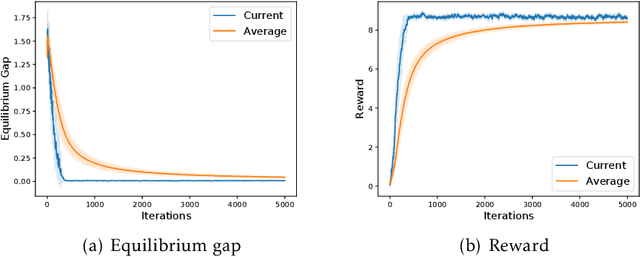
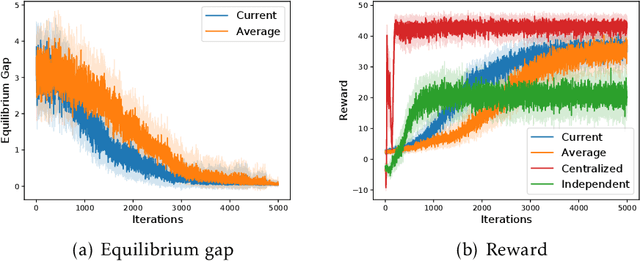
Many real-world applications of multi-agent reinforcement learning (RL), such as multi-robot navigation and decentralized control of cyber-physical systems, involve the cooperation of agents as a team with aligned objectives. We study multi-agent RL in the most basic cooperative setting -- Markov teams -- a class of Markov games where the cooperating agents share a common reward. We propose an algorithm in which each agent independently runs stage-based V-learning (a Q-learning style algorithm) to efficiently explore the unknown environment, while using a stochastic gradient descent (SGD) subroutine for policy updates. We show that the agents can learn an $\epsilon$-approximate Nash equilibrium policy in at most $\propto\widetilde{O}(1/\epsilon^4)$ episodes. Our results advocate the use of a novel \emph{stage-based} V-learning approach to create a stage-wise stationary environment. We also show that under certain smoothness assumptions of the team, our algorithm can achieve a nearly \emph{team-optimal} Nash equilibrium. Simulation results corroborate our theoretical findings. One key feature of our algorithm is being \emph{decentralized}, in the sense that each agent has access to only the state and its local actions, and is even \emph{oblivious} to the presence of the other agents. Neither communication among teammates nor coordination by a central controller is required during learning. Hence, our algorithm can readily generalize to an arbitrary number of agents, without suffering from the exponential dependence on the number of agents.