 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Detection with Shadow Transformer (and View-Coherent Data Augmentation)
Aug 12, 2021
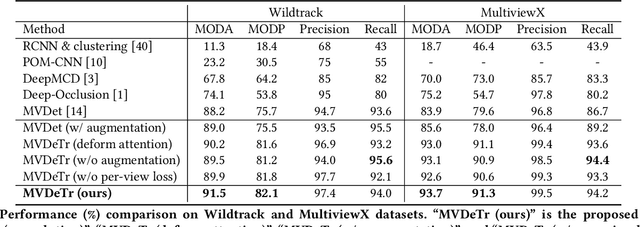
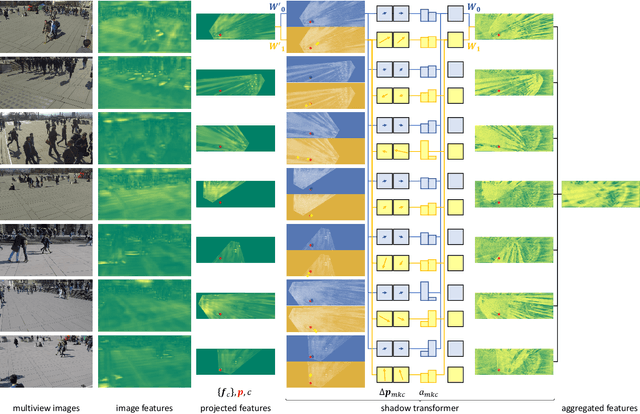

Multiview detection incorporates multiple camera views to deal with occlusions, and its central problem is multiview aggregation. Given feature map projections from multiple views onto a common ground plane, the state-of-the-art method addresses this problem via convolution, which applies the same calculation regardless of object locations. However, such translation-invariant behaviors might not be the best choice, as object features undergo various projection distortions according to their positions and cameras. In this paper, we propose a novel multiview detector, MVDeTr, that adopts a newly introduced shadow transformer to aggregate multiview information. Unlike convolutions, shadow transformer attends differently at different positions and cameras to deal with various shadow-like distortions. We propose an effective training scheme that includes a new view-coherent data augmentation method, which applies random augmentations while maintaining multiview consistency. On two multiview detection benchmarks, we report new state-of-the-art accuracy with the proposed system. Code is available at https://github.com/hou-yz/MVDeTr.
Synthetic Data Are as Good as the Real for Association Knowledge Learning in Multi-object Tracking
Jul 02, 2021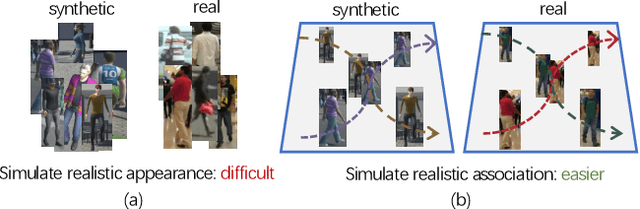
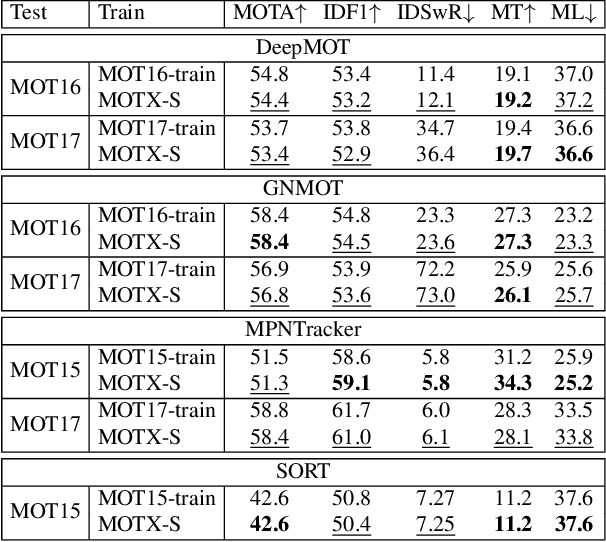

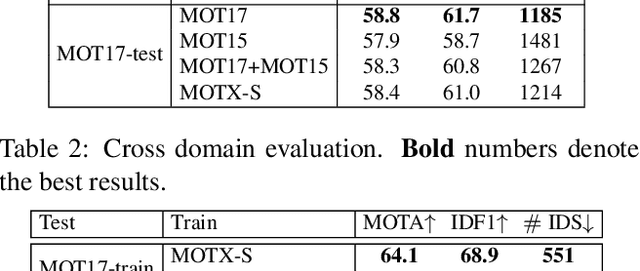
Association, aiming to link bounding boxes of the same identity in a video sequence, is a central component in multi-object tracking (MOT). To train association modules, e.g., parametric networks, real video data are usually used. However, annotating person tracks in consecutive video frames is expensive, and such real data, due to its inflexibility, offer us limited opportunities to evaluate the system performance w.r.t changing tracking scenarios. In this paper, we study whether 3D synthetic data can replace real-world videos for association training. Specifically, we introduce a large-scale synthetic data engine named MOTX, where the motion characteristics of cameras and objects are manually configured to be similar to those in real-world datasets. We show that compared with real data, association knowledge obtained from synthetic data can achieve very similar performance on real-world test sets without domain adaption techniques. Our intriguing observation is credited to two factors. First and foremost, 3D engines can well simulate motion factors such as camera movement, camera view and object movement, so that the simulated videos can provide association modules with effective motion features. Second, experimental results show that the appearance domain gap hardly harms the learning of association knowledge. In addition, the strong customization ability of MOTX allows us to quantitatively assess the impact of motion factors on MOT, which brings new insights to the community.
Invertible Attention
Jun 27, 2021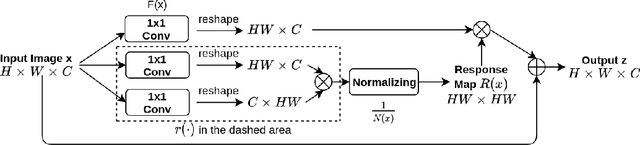


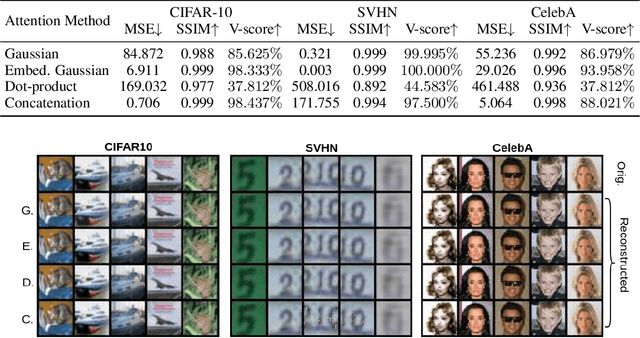
Attention has been proved to be an efficient mechanism to capture long-range dependencies. However, so far it has not been deployed in invertible networks. This is due to the fact that in order to make a network invertible, every component within the network needs to be a bijective transformation, but a normal attention block is not. In this paper, we propose invertible attention that can be plugged into existing invertible models. We mathematically and experimentally prove that the invertibility of an attention model can be achieved by carefully constraining its Lipschitz constant. We validate the invertibility of our invertible attention on image reconstruction task with 3 popular datasets: CIFAR-10, SVHN, and CelebA. We also show that our invertible attention achieves similar performance in comparison with normal non-invertible attention on dense prediction tasks. The code is available at https://github.com/Schwartz-Zha/InvertibleAttention
What Does Rotation Prediction Tell Us about Classifier Accuracy under Varying Testing Environments?
Jun 10, 2021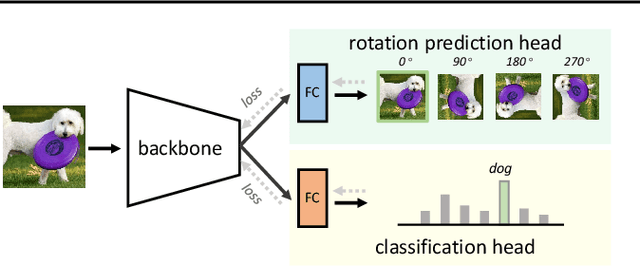
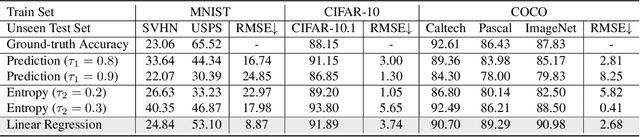

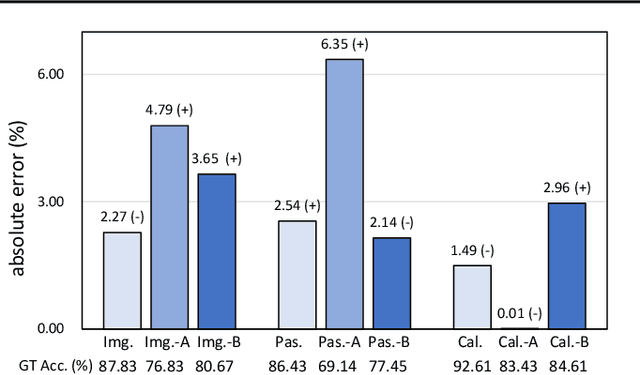
Understanding classifier decision under novel environments is central to the community, and a common practice is evaluating it on labeled test sets. However, in real-world testing, image annotations are difficult and expensive to obtain, especially when the test environment is changing. A natural question then arises: given a trained classifier, can we evaluate its accuracy on varying unlabeled test sets? In this work, we train semantic classification and rotation prediction in a multi-task way. On a series of datasets, we report an interesting finding, i.e., the semantic classification accuracy exhibits a strong linear relationship with the accuracy of the rotation prediction task (Pearson's Correlation r > 0.88). This finding allows us to utilize linear regression to estimate classifier performance from the accuracy of rotation prediction which can be obtained on the test set through the freely generated rotation labels.
The 5th AI City Challenge
May 24, 2021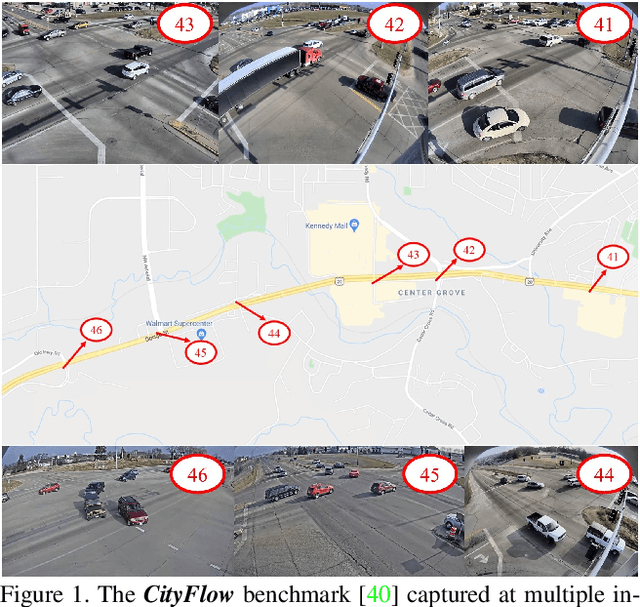
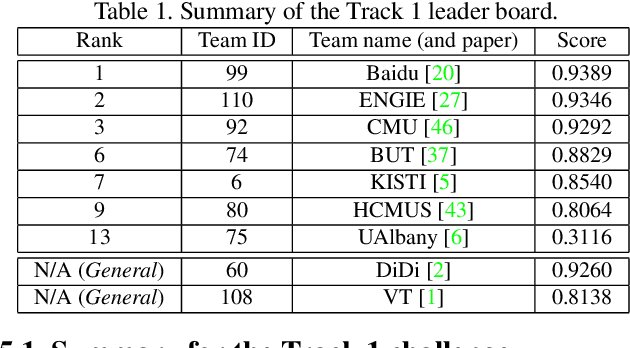
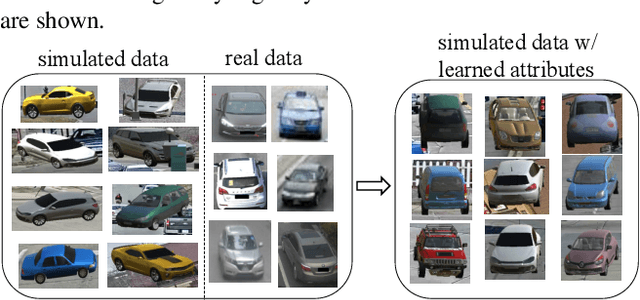
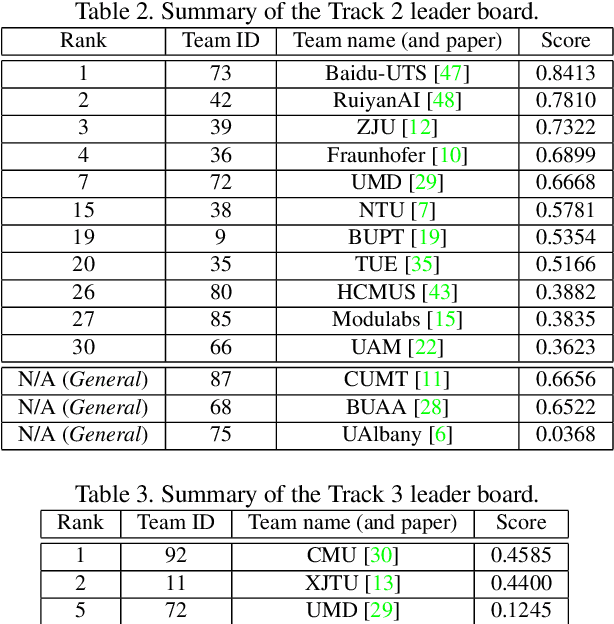
The AI City Challenge was created with two goals in mind: (1) pushing the boundaries of research and development in intelligent video analysis for smarter cities use cases, and (2) assessing tasks where the level of performance is enough to cause real-world adoption. Transportation is a segment ripe for such adoption. The fifth AI City Challenge attracted 305 participating teams across 38 countries, who leveraged city-scale real traffic data and high-quality synthetic data to compete in five challenge tracks. Track 1 addressed video-based automatic vehicle counting, where the evaluation being conducted on both algorithmic effectiveness and computational efficiency. Track 2 addressed city-scale vehicle re-identification with augmented synthetic data to substantially increase the training set for the task. Track 3 addressed city-scale multi-target multi-camera vehicle tracking. Track 4 addressed traffic anomaly detection. Track 5 was a new track addressing vehicle retrieval using natural language descriptions. The evaluation system shows a general leader board of all submitted results, and a public leader board of results limited to the contest participation rules, where teams are not allowed to use external data in their work. The public leader board shows results more close to real-world situations where annotated data is limited. Results show the promise of AI in Smarter Transportation. State-of-the-art performance for some tasks shows that these technologies are ready for adoption in real-world systems.
VTNet: Visual Transformer Network for Object Goal Navigation
May 20, 2021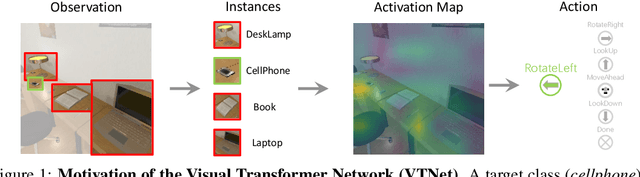
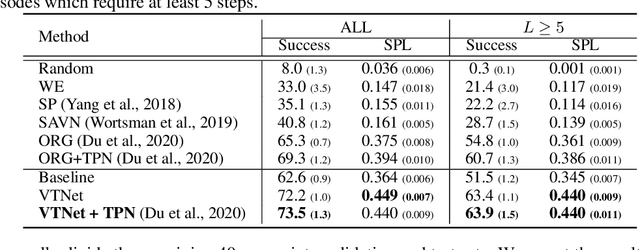
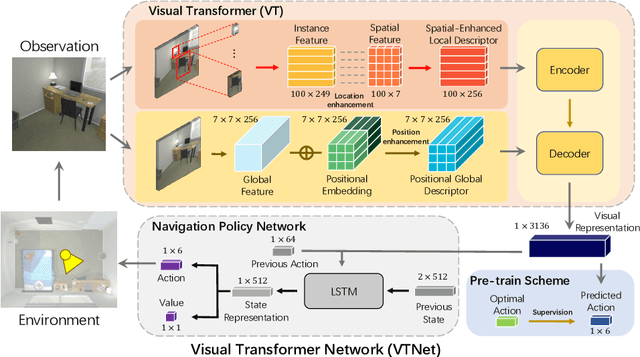
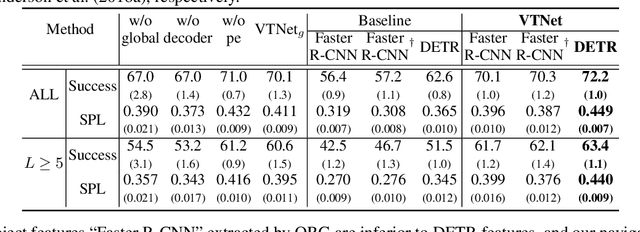
Object goal navigation aims to steer an agent towards a target object based on observations of the agent. It is of pivotal importance to design effective visual representations of the observed scene in determining navigation actions. In this paper, we introduce a Visual Transformer Network (VTNet) for learning informative visual representation in navigation. VTNet is a highly effective structure that embodies two key properties for visual representations: First, the relationships among all the object instances in a scene are exploited; Second, the spatial locations of objects and image regions are emphasized so that directional navigation signals can be learned. Furthermore, we also develop a pre-training scheme to associate the visual representations with navigation signals, and thus facilitate navigation policy learning. In a nutshell, VTNet embeds object and region features with their location cues as spatial-aware descriptors and then incorporates all the encoded descriptors through attention operations to achieve informative representation for navigation. Given such visual representations, agents are able to explore the correlations between visual observations and navigation actions. For example, an agent would prioritize "turning right" over "turning left" when the visual representation emphasizes on the right side of activation map. Experiments in the artificial environment AI2-Thor demonstrate that VTNet significantly outperforms state-of-the-art methods in unseen testing environments.
Boosting Semi-Supervised Face Recognition with Noise Robustness
May 10, 2021
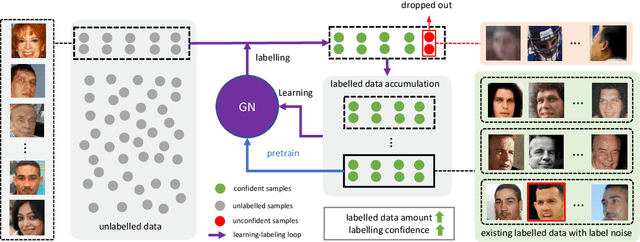


Although deep face recognition benefits significantly from large-scale training data, a current bottleneck is the labelling cost. A feasible solution to this problem is semi-supervised learning, exploiting a small portion of labelled data and large amounts of unlabelled data. The major challenge, however, is the accumulated label errors through auto-labelling, compromising the training. This paper presents an effective solution to semi-supervised face recognition that is robust to the label noise aroused by the auto-labelling. Specifically, we introduce a multi-agent method, named GroupNet (GN), to endow our solution with the ability to identify the wrongly labelled samples and preserve the clean samples. We show that GN alone achieves the leading accuracy in traditional supervised face recognition even when the noisy labels take over 50\% of the training data. Further, we develop a semi-supervised face recognition solution, named Noise Robust Learning-Labelling (NRoLL), which is based on the robust training ability empowered by GN. It starts with a small amount of labelled data and consequently conducts high-confidence labelling on a large amount of unlabelled data to boost further training. The more data is labelled by NRoLL, the higher confidence is with the label in the dataset. To evaluate the competitiveness of our method, we run NRoLL with a rough condition that only one-fifth of the labelled MSCeleb is available and the rest is used as unlabelled data. On a wide range of benchmarks, our method compares favorably against the state-of-the-art methods.
Visualizing Adapted Knowledge in Domain Transfer
May 01, 2021
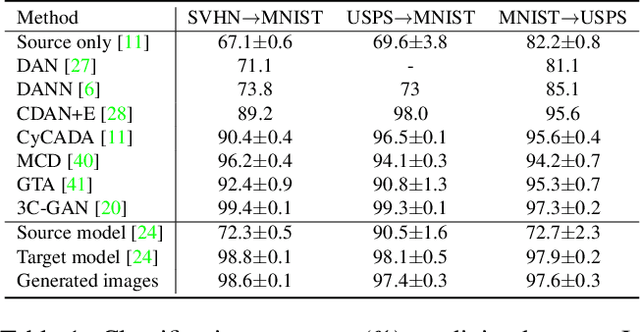
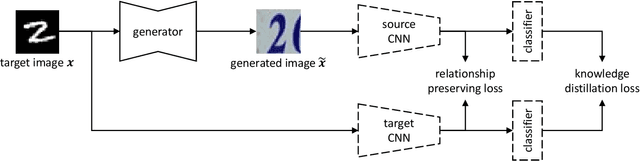
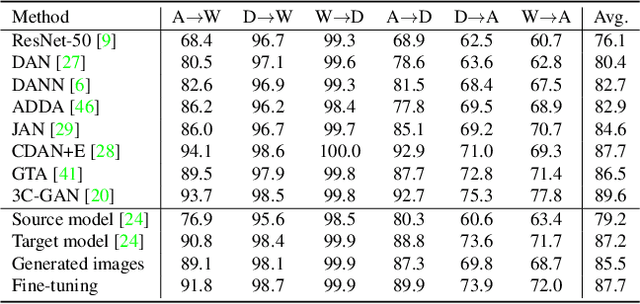
A source model trained on source data and a target model learned through unsupervised domain adaptation (UDA) usually encode different knowledge. To understand the adaptation process, we portray their knowledge difference with image translation. Specifically, we feed a translated image and its original version to the two models respectively, formulating two branches. Through updating the translated image, we force similar outputs from the two branches. When such requirements are met, differences between the two images can compensate for and hence represent the knowledge difference between models. To enforce similar outputs from the two branches and depict the adapted knowledge, we propose a source-free image translation method that generates source-style images using only target images and the two models. We visualize the adapted knowledge on several datasets with different UDA methods and find that generated images successfully capture the style difference between the two domains. For application, we show that generated images enable further tuning of the target model without accessing source data. Code available at https://github.com/hou-yz/DA_visualization.
Positive Sample Propagation along the Audio-Visual Event Line
Apr 05, 2021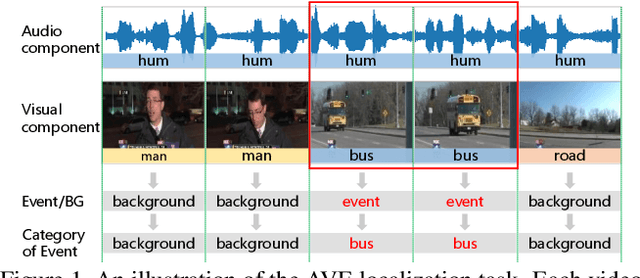
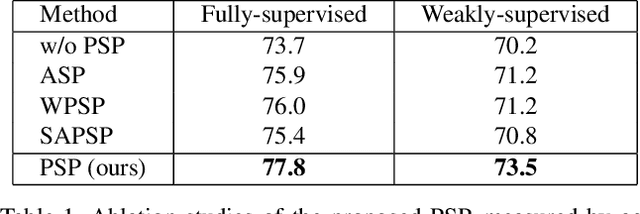
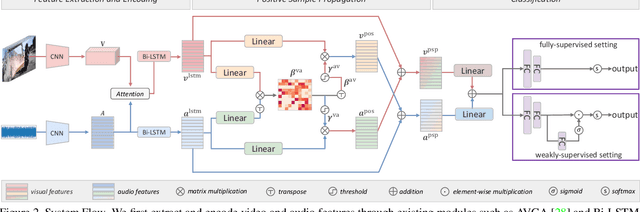
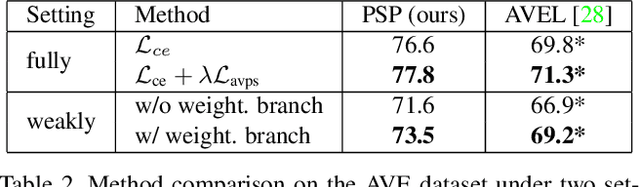
Visual and audio signals often coexist in natural environments, forming audio-visual events (AVEs). Given a video, we aim to localize video segments containing an AVE and identify its category. In order to learn discriminative features for a classifier, it is pivotal to identify the helpful (or positive) audio-visual segment pairs while filtering out the irrelevant ones, regardless whether they are synchronized or not. To this end, we propose a new positive sample propagation (PSP) module to discover and exploit the closely related audio-visual pairs by evaluating the relationship within every possible pair. It can be done by constructing an all-pair similarity map between each audio and visual segment, and only aggregating the features from the pairs with high similarity scores. To encourage the network to extract high correlated features for positive samples, a new audio-visual pair similarity loss is proposed. We also propose a new weighting branch to better exploit the temporal correlations in weakly supervised setting. We perform extensive experiments on the public AVE dataset and achieve new state-of-the-art accuracy in both fully and weakly supervised settings, thus verifying the effectiveness of our method.
Sparse Attention Guided Dynamic Value Estimation for Single-Task Multi-Scene Reinforcement Learning
Feb 14, 2021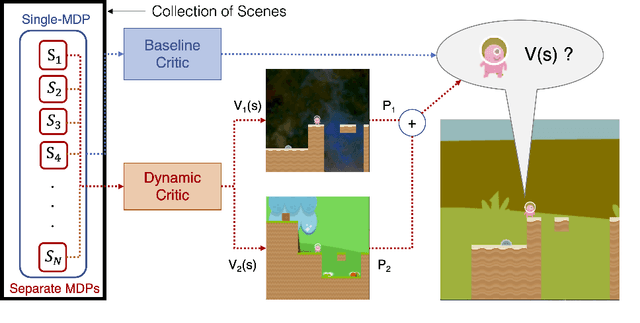
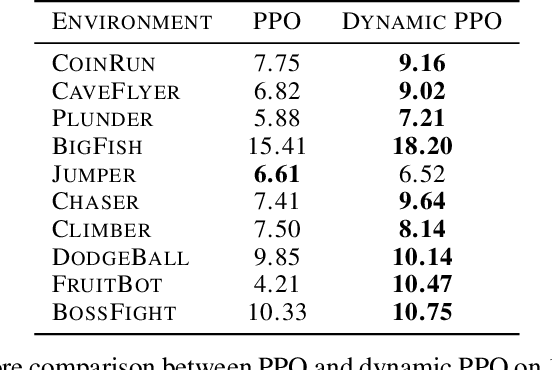
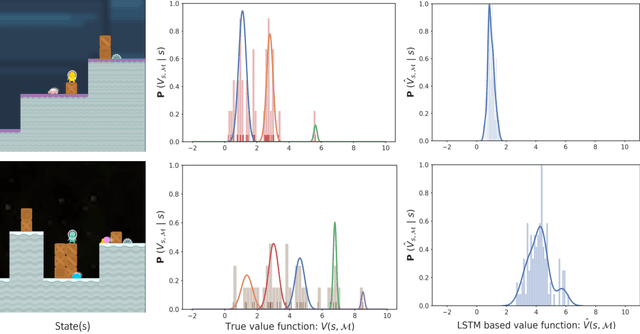
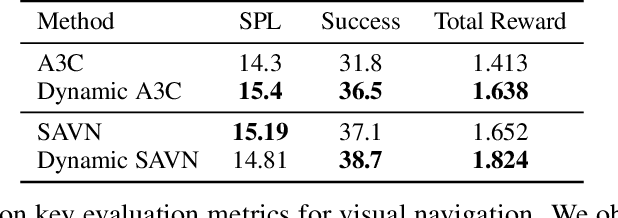
Training deep reinforcement learning agents on environments with multiple levels / scenes from the same task, has become essential for many applications aiming to achieve generalization and domain transfer from simulation to the real world. While such a strategy is helpful with generalization, the use of multiple scenes significantly increases the variance of samples collected for policy gradient computations. Current methods, effectively continue to view this collection of scenes as a single Markov decision process (MDP), and thus learn a scene-generic value function V(s). However, we argue that the sample variance for a multi-scene environment is best minimized by treating each scene as a distinct MDP, and then learning a joint value function V(s,M) dependent on both state s and MDP M. We further demonstrate that the true joint value function for a multi-scene environment, follows a multi-modal distribution which is not captured by traditional CNN / LSTM based critic networks. To this end, we propose a dynamic value estimation (DVE) technique, which approximates the true joint value function through a sparse attention mechanism over multiple value function hypothesis / modes. The resulting agent not only shows significant improvements in the final reward score across a range of OpenAI ProcGen environments, but also exhibits enhanced navigation efficiency and provides an implicit mechanism for unsupervised state-space skill decomposition.