 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Prototyping and Hierarchical Alignment for Unsupervised Video-based Visible-Infrared Person Re-Identification
Apr 23, 2026Visible-infrared person re-identification (VI-ReID) enables cross-modality identity matching for all-day surveillance, yet existing methods predominantly focus on the image level or rely heavily on costly identity annotations. While video-based VI-ReID has recently emerged to exploit temporal dynamics for improved robustness, existing studies remain limited to supervised settings. Crucially, the unsupervised video VI-ReID problem, where models must learn from RGB and infrared tracklets without identity labels, remains largely unexplored despite its practical importance in real-world deployment. To bridge this gap, we propose HiTPro (Hierarchical Temporal Prototyping), a prototype-driven framework without explicit hard pseudo-label assignment for unsupervised video-based VI-ReID. HiTPro begins with an efficient Temporal-aware Feature Encoder that first extracts discriminative frame-level features and then aggregates them into a robust tracklet-level representation. Building upon these features, HiTPro first constructs reliable intra-camera prototypes via Intra-Camera Tracklet Prototyping by aggregating features from temporally partitioned sub-tracklets. Through Hierarchical Cross-Prototype Alignment, we perform a two-stage positive mining process: progressing from within-modality associations to cross-modality matching, enhanced by Dynamic Threshold Strategy and Soft Weight Assignment. Finally, {Hierarchical Contrastive Learning} progressively optimizes feature-prototype alignment across three levels: intra-camera discrimination, cross-camera same-modality consistency, and cross-modality invariance. Extensive experiments on HITSZ-VCM and BUPTCampus demonstrate that HiTPro achieves state-of-the-art performance under fully unsupervised settings, significantly outperforming adapted baselines and establishes a strong baseline for future research.
Learning to simulate complex scenes
Jun 25, 2020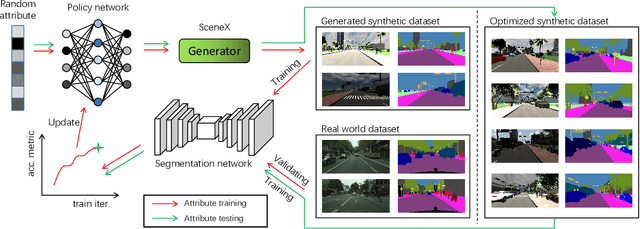
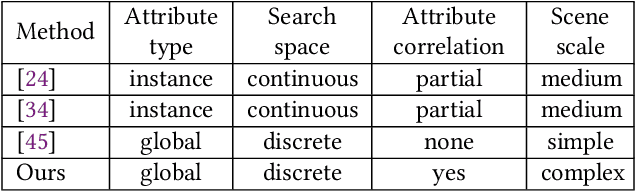

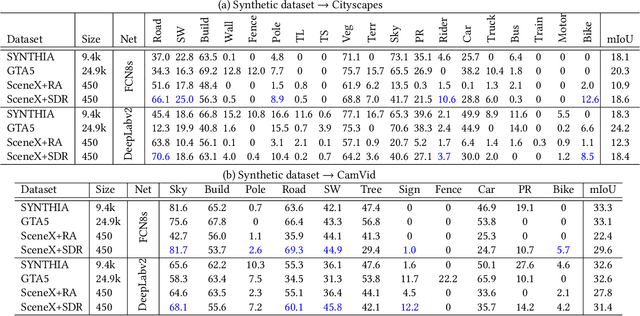
Data simulation engines like Unity are becoming an increasingly important data source that allows us to acquire ground truth labels conveniently. Moreover, we can flexibly edit the content of an image in the engine, such as objects (position, orientation) and environments (illumination, occlusion). When using simulated data as training sets, its editable content can be leveraged to mimic the distribution of real-world data, and thus reduce the content difference between the synthetic and real domains. This paper explores content adaptation in the context of semantic segmentation, where the complex street scenes are fully synthesized using 19 classes of virtual objects from a first person driver perspective and controlled by 23 attributes. To optimize the attribute values and obtain a training set of similar content to real-world data, we propose a scalable discretization-and-relaxation (SDR) approach. Under a reinforcement learning framework, we formulate attribute optimization as a random-to-optimized mapping problem using a neural network. Our method has three characteristics. 1) Instead of editing attributes of individual objects, we focus on global attributes that have large influence on the scene structure, such as object density and illumination. 2) Attributes are quantized to discrete values, so as to reduce search space and training complexity. 3) Correlated attributes are jointly optimized in a group, so as to avoid meaningless scene structures and find better convergence points. Experiment shows our system can generate reasonable and useful scenes, from which we obtain promising real-world segmentation accuracy compared with existing synthetic training sets.