 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Human-AI Coordination via Preparatory Language-based Convention
Nov 01, 2023



Developing intelligent agents capable of seamless coordination with humans is a critical step towards achieving artificial general intelligence. Existing methods for human-AI coordination typically train an agent to coordinate with a diverse set of policies or with human models fitted from real human data. However, the massively diverse styles of human behavior present obstacles for AI systems with constrained capacity, while high quality human data may not be readily available in real-world scenarios. In this study, we observe that prior to coordination, humans engage in communication to establish conventions that specify individual roles and actions, making their coordination proceed in an orderly manner. Building upon this observation, we propose employing the large language model (LLM) to develop an action plan (or equivalently, a convention) that effectively guides both human and AI. By inputting task requirements, human preferences, the number of agents, and other pertinent information into the LLM, it can generate a comprehensive convention that facilitates a clear understanding of tasks and responsibilities for all parties involved. Furthermore, we demonstrate that decomposing the convention formulation problem into sub-problems with multiple new sessions being sequentially employed and human feedback, will yield a more efficient coordination convention. Experimental evaluations conducted in the Overcooked-AI environment, utilizing a human proxy model, highlight the superior performance of our proposed method compared to existing learning-based approaches. When coordinating with real humans, our method achieves better alignment with human preferences and an average performance improvement of 15% compared to the state-of-the-art.
Robust multi-agent coordination via evolutionary generation of auxiliary adversarial attackers
May 10, 2023



Cooperative multi-agent reinforcement learning (CMARL) has shown to be promising for many real-world applications. Previous works mainly focus on improving coordination ability via solving MARL-specific challenges (e.g., non-stationarity, credit assignment, scalability), but ignore the policy perturbation issue when testing in a different environment. This issue hasn't been considered in problem formulation or efficient algorithm design. To address this issue, we firstly model the problem as a limited policy adversary Dec-POMDP (LPA-Dec-POMDP), where some coordinators from a team might accidentally and unpredictably encounter a limited number of malicious action attacks, but the regular coordinators still strive for the intended goal. Then, we propose Robust Multi-Agent Coordination via Evolutionary Generation of Auxiliary Adversarial Attackers (ROMANCE), which enables the trained policy to encounter diversified and strong auxiliary adversarial attacks during training, thus achieving high robustness under various policy perturbations. Concretely, to avoid the ego-system overfitting to a specific attacker, we maintain a set of attackers, which is optimized to guarantee the attackers high attacking quality and behavior diversity. The goal of quality is to minimize the ego-system coordination effect, and a novel diversity regularizer based on sparse action is applied to diversify the behaviors among attackers. The ego-system is then paired with a population of attackers selected from the maintained attacker set, and alternately trained against the constantly evolving attackers. Extensive experiments on multiple scenarios from SMAC indicate our ROMANCE provides comparable or better robustness and generalization ability than other baselines.
Communication-Robust Multi-Agent Learning by Adaptable Auxiliary Multi-Agent Adversary Generation
May 09, 2023Communication can promote coordination in cooperative Multi-Agent Reinforcement Learning (MARL). Nowadays, existing works mainly focus on improving the communication efficiency of agents, neglecting that real-world communication is much more challenging as there may exist noise or potential attackers. Thus the robustness of the communication-based policies becomes an emergent and severe issue that needs more exploration. In this paper, we posit that the ego system trained with auxiliary adversaries may handle this limitation and propose an adaptable method of Multi-Agent Auxiliary Adversaries Generation for robust Communication, dubbed MA3C, to obtain a robust communication-based policy. In specific, we introduce a novel message-attacking approach that models the learning of the auxiliary attacker as a cooperative problem under a shared goal to minimize the coordination ability of the ego system, with which every information channel may suffer from distinct message attacks. Furthermore, as naive adversarial training may impede the generalization ability of the ego system, we design an attacker population generation approach based on evolutionary learning. Finally, the ego system is paired with an attacker population and then alternatively trained against the continuously evolving attackers to improve its robustness, meaning that both the ego system and the attackers are adaptable. Extensive experiments on multiple benchmarks indicate that our proposed MA3C provides comparable or better robustness and generalization ability than other baselines.
Multi-agent Continual Coordination via Progressive Task Contextualization
May 07, 2023Cooperative Multi-agent Reinforcement Learning (MARL) has attracted significant attention and played the potential for many real-world applications. Previous arts mainly focus on facilitating the coordination ability from different aspects (e.g., non-stationarity, credit assignment) in single-task or multi-task scenarios, ignoring the stream of tasks that appear in a continual manner. This ignorance makes the continual coordination an unexplored territory, neither in problem formulation nor efficient algorithms designed. Towards tackling the mentioned issue, this paper proposes an approach Multi-Agent Continual Coordination via Progressive Task Contextualization, dubbed MACPro. The key point lies in obtaining a factorized policy, using shared feature extraction layers but separated independent task heads, each specializing in a specific class of tasks. The task heads can be progressively expanded based on the learned task contextualization. Moreover, to cater to the popular CTDE paradigm in MARL, each agent learns to predict and adopt the most relevant policy head based on local information in a decentralized manner. We show in multiple multi-agent benchmarks that existing continual learning methods fail, while MACPro is able to achieve close-to-optimal performance. More results also disclose the effectiveness of MACPro from multiple aspects like high generalization ability.
Robust Multi-agent Communication via Multi-view Message Certification
May 07, 2023



Many multi-agent scenarios require message sharing among agents to promote coordination, hastening the robustness of multi-agent communication when policies are deployed in a message perturbation environment. Major relevant works tackle this issue under specific assumptions, like a limited number of message channels would sustain perturbations, limiting the efficiency in complex scenarios. In this paper, we take a further step addressing this issue by learning a robust multi-agent communication policy via multi-view message certification, dubbed CroMAC. Agents trained under CroMAC can obtain guaranteed lower bounds on state-action values to identify and choose the optimal action under a worst-case deviation when the received messages are perturbed. Concretely, we first model multi-agent communication as a multi-view problem, where every message stands for a view of the state. Then we extract a certificated joint message representation by a multi-view variational autoencoder (MVAE) that uses a product-of-experts inference network. For the optimization phase, we do perturbations in the latent space of the state for a certificate guarantee. Then the learned joint message representation is used to approximate the certificated state representation during training. Extensive experiments in several cooperative multi-agent benchmarks validate the effectiveness of the proposed CroMAC.
Efficient Communication via Self-supervised Information Aggregation for Online and Offline Multi-agent Reinforcement Learning
Feb 19, 2023Utilizing messages from teammates can improve coordination in cooperative Multi-agent Reinforcement Learning (MARL). Previous works typically combine raw messages of teammates with local information as inputs for policy. However, neglecting message aggregation poses significant inefficiency for policy learning. Motivated by recent advances in representation learning, we argue that efficient message aggregation is essential for good coordination in cooperative MARL. In this paper, we propose Multi-Agent communication via Self-supervised Information Aggregation (MASIA), where agents can aggregate the received messages into compact representations with high relevance to augment the local policy. Specifically, we design a permutation invariant message encoder to generate common information-aggregated representation from messages and optimize it via reconstructing and shooting future information in a self-supervised manner. Hence, each agent would utilize the most relevant parts of the aggregated representation for decision-making by a novel message extraction mechanism. Furthermore, considering the potential of offline learning for real-world applications, we build offline benchmarks for multi-agent communication, which is the first as we know. Empirical results demonstrate the superiority of our method in both online and offline settings. We also release the built offline benchmarks in this paper as a testbed for communication ability validation to facilitate further future research.
Self-Motivated Multi-Agent Exploration
Jan 05, 2023



In cooperative multi-agent reinforcement learning (CMARL), it is critical for agents to achieve a balance between self-exploration and team collaboration. However, agents can hardly accomplish the team task without coordination and they would be trapped in a local optimum where easy cooperation is accessed without enough individual exploration. Recent works mainly concentrate on agents' coordinated exploration, which brings about the exponentially grown exploration of the state space. To address this issue, we propose Self-Motivated Multi-Agent Exploration (SMMAE), which aims to achieve success in team tasks by adaptively finding a trade-off between self-exploration and team cooperation. In SMMAE, we train an independent exploration policy for each agent to maximize their own visited state space. Each agent learns an adjustable exploration probability based on the stability of the joint team policy. The experiments on highly cooperative tasks in StarCraft II micromanagement benchmark (SMAC) demonstrate that SMMAE can explore task-related states more efficiently, accomplish coordinated behaviours and boost the learning performance.
Multi-agent Dynamic Algorithm Configuration
Oct 13, 2022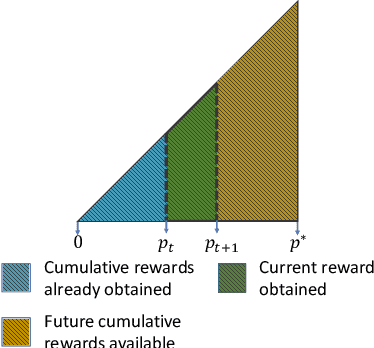

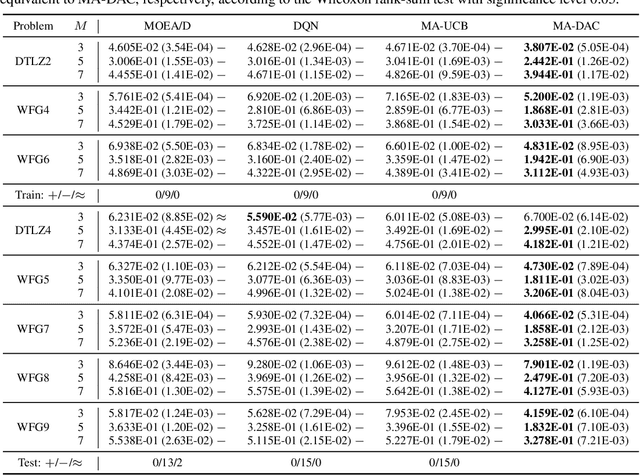
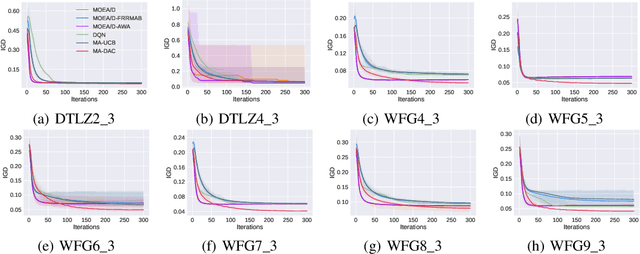
Automated algorithm configuration relieves users from tedious, trial-and-error tuning tasks. A popular algorithm configuration tuning paradigm is dynamic algorithm configuration (DAC), in which an agent learns dynamic configuration policies across instances by reinforcement learning (RL). However, in many complex algorithms, there may exist different types of configuration hyperparameters, and such heterogeneity may bring difficulties for classic DAC which uses a single-agent RL policy. In this paper, we aim to address this issue and propose multi-agent DAC (MA-DAC), with one agent working for one type of configuration hyperparameter. MA-DAC formulates the dynamic configuration of a complex algorithm with multiple types of hyperparameters as a contextual multi-agent Markov decision process and solves it by a cooperative multi-agent RL (MARL) algorithm. To instantiate, we apply MA-DAC to a well-known optimization algorithm for multi-objective optimization problems. Experimental results show the effectiveness of MA-DAC in not only achieving superior performance compared with other configuration tuning approaches based on heuristic rules, multi-armed bandits, and single-agent RL, but also being capable of generalizing to different problem classes. Furthermore, we release the environments in this paper as a benchmark for testing MARL algorithms, with the hope of facilitating the application of MARL.
Heterogeneous Multi-agent Zero-Shot Coordination by Coevolution
Aug 09, 2022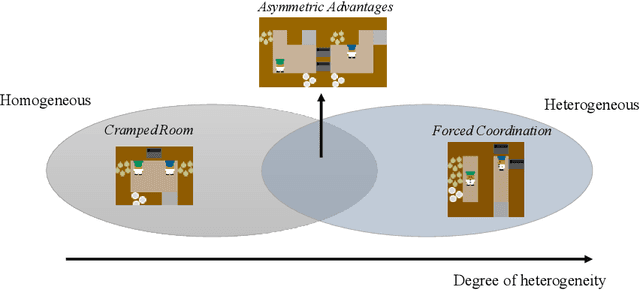
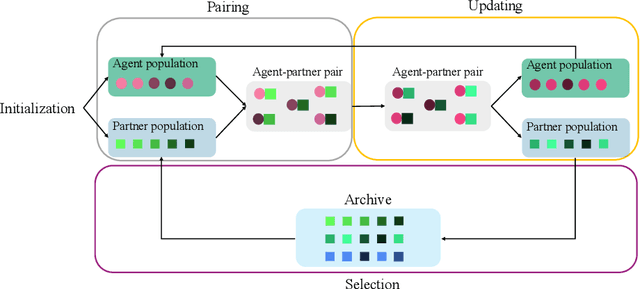
Generating agents that can achieve Zero-Shot Coordination (ZSC) with unseen partners is a new challenge in cooperative Multi-Agent Reinforcement Learning (MARL). Recently, some studies have made progress in ZSC by exposing the agents to diverse partners during the training process. They usually involve self-play when training the partners, implicitly assuming that the tasks are homogeneous. However, many real-world tasks are heterogeneous, and hence previous methods may fail. In this paper, we study the heterogeneous ZSC problem for the first time and propose a general method based on coevolution, which coevolves two populations of agents and partners through three sub-processes: pairing, updating and selection. Experimental results on a collaborative cooking task show the necessity of considering the heterogeneous setting and illustrate that our proposed method is a promising solution for heterogeneous cooperative MARL.
Model Generation with Provable Coverability for Offline Reinforcement Learning
Jun 08, 2022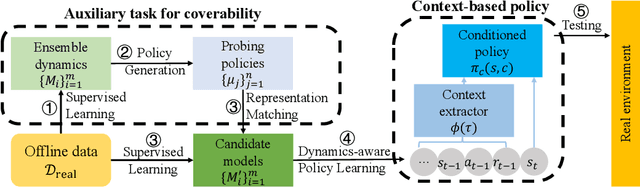
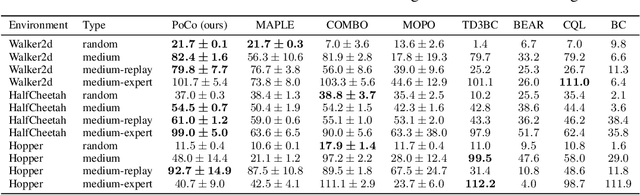
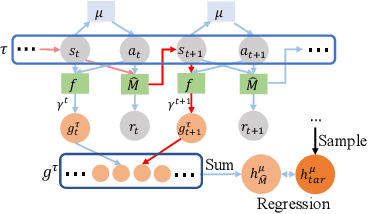
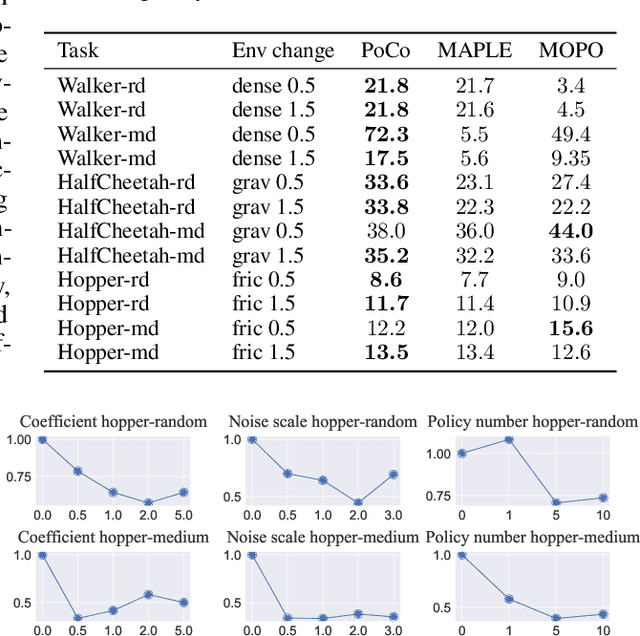
Model-based offline optimization with dynamics-aware policy provides a new perspective for policy learning and out-of-distribution generalization, where the learned policy could adapt to different dynamics enumerated at the training stage. But due to the limitation under the offline setting, the learned model could not mimic real dynamics well enough to support reliable out-of-distribution exploration, which still hinders policy to generalize well. To narrow the gap, previous works roughly ensemble randomly initialized models to better approximate the real dynamics. However, such practice is costly and inefficient, and provides no guarantee on how well the real dynamics could be approximated by the learned models, which we name coverability in this paper. We actively address this issue by generating models with provable ability to cover real dynamics in an efficient and controllable way. To that end, we design a distance metric for dynamic models based on the occupancy of policies under the dynamics, and propose an algorithm to generate models optimizing their coverage for the real dynamics. We give a theoretical analysis on the model generation process and proves that our algorithm could provide enhanced coverability. As a downstream task, we train a dynamics-aware policy with minor or no conservative penalty, and experiments demonstrate that our algorithm outperforms prior offline methods on existing offline RL benchmarks. We also discover that policies learned by our method have better zero-shot transfer performance, implying their better generalization.