 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Political Zero-Shot Relation Classification via Codebook Knowledge, NLI, and ChatGPT
Aug 15, 2023



Recent supervised models for event coding vastly outperform pattern-matching methods. However, their reliance solely on new annotations disregards the vast knowledge within expert databases, hindering their applicability to fine-grained classification. To address these limitations, we explore zero-shot approaches for political event ontology relation classification, by leveraging knowledge from established annotation codebooks. Our study encompasses both ChatGPT and a novel natural language inference (NLI) based approach named ZSP. ZSP adopts a tree-query framework that deconstructs the task into context, modality, and class disambiguation levels. This framework improves interpretability, efficiency, and adaptability to schema changes. By conducting extensive experiments on our newly curated datasets, we pinpoint the instability issues within ChatGPT and highlight the superior performance of ZSP. ZSP achieves an impressive 40% improvement in F1 score for fine-grained Rootcode classification. ZSP demonstrates competitive performance compared to supervised BERT models, positioning it as a valuable tool for event record validation and ontology development. Our work underscores the potential of leveraging transfer learning and existing expertise to enhance the efficiency and scalability of research in the field.
Towards Fair Disentangled Online Learning for Changing Environments
May 31, 2023



In the problem of online learning for changing environments, data are sequentially received one after another over time, and their distribution assumptions may vary frequently. Although existing methods demonstrate the effectiveness of their learning algorithms by providing a tight bound on either dynamic regret or adaptive regret, most of them completely ignore learning with model fairness, defined as the statistical parity across different sub-population (e.g., race and gender). Another drawback is that when adapting to a new environment, an online learner needs to update model parameters with a global change, which is costly and inefficient. Inspired by the sparse mechanism shift hypothesis, we claim that changing environments in online learning can be attributed to partial changes in learned parameters that are specific to environments and the rest remain invariant to changing environments. To this end, in this paper, we propose a novel algorithm under the assumption that data collected at each time can be disentangled with two representations, an environment-invariant semantic factor and an environment-specific variation factor. The semantic factor is further used for fair prediction under a group fairness constraint. To evaluate the sequence of model parameters generated by the learner, a novel regret is proposed in which it takes a mixed form of dynamic and static regret metrics followed by a fairness-aware long-term constraint. The detailed analysis provides theoretical guarantees for loss regret and violation of cumulative fairness constraints. Empirical evaluations on real-world datasets demonstrate our proposed method sequentially outperforms baseline methods in model accuracy and fairness.
An Automated Vulnerability Detection Framework for Smart Contracts
Jan 20, 2023With the increase of the adoption of blockchain technology in providing decentralized solutions to various problems, smart contracts have become more popular to the point that billions of US Dollars are currently exchanged every day through such technology. Meanwhile, various vulnerabilities in smart contracts have been exploited by attackers to steal cryptocurrencies worth millions of dollars. The automatic detection of smart contract vulnerabilities therefore is an essential research problem. Existing solutions to this problem particularly rely on human experts to define features or different rules to detect vulnerabilities. However, this often causes many vulnerabilities to be ignored, and they are inefficient in detecting new vulnerabilities. In this study, to overcome such challenges, we propose a framework to automatically detect vulnerabilities in smart contracts on the blockchain. More specifically, first, we utilize novel feature vector generation techniques from bytecode of smart contract since the source code of smart contracts are rarely available in public. Next, the collected vectors are fed into our novel metric learning-based deep neural network(DNN) to get the detection result. We conduct comprehensive experiments on large-scale benchmarks, and the quantitative results demonstrate the effectiveness and efficiency of our approach.
Controllable Fake Document Infilling for Cyber Deception
Oct 18, 2022
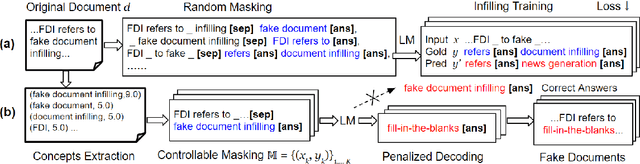

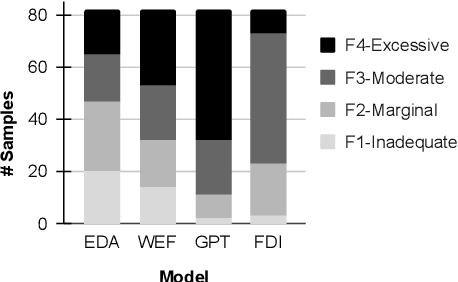
Recent works in cyber deception study how to deter malicious intrusion by generating multiple fake versions of a critical document to impose costs on adversaries who need to identify the correct information. However, existing approaches are context-agnostic, resulting in sub-optimal and unvaried outputs. We propose a novel context-aware model, Fake Document Infilling (FDI), by converting the problem to a controllable mask-then-infill procedure. FDI masks important concepts of varied lengths in the document, then infills a realistic but fake alternative considering both the previous and future contexts. We conduct comprehensive evaluations on technical documents and news stories. Results show that FDI outperforms the baselines in generating highly believable fakes with moderate modification to protect critical information and deceive adversaries.
Adaptive Fairness-Aware Online Meta-Learning for Changing Environments
May 26, 2022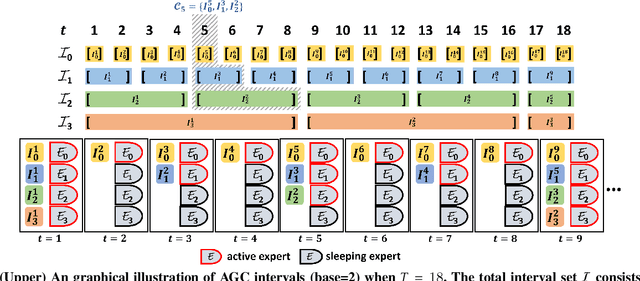

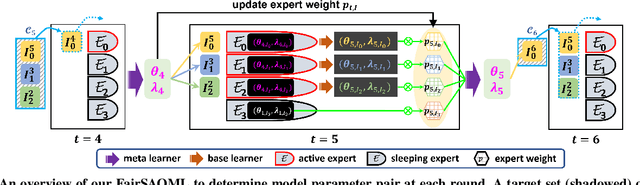

The fairness-aware online learning framework has arisen as a powerful tool for the continual lifelong learning setting. The goal for the learner is to sequentially learn new tasks where they come one after another over time and the learner ensures the statistic parity of the new coming task across different protected sub-populations (e.g. race and gender). A major drawback of existing methods is that they make heavy use of the i.i.d assumption for data and hence provide static regret analysis for the framework. However, low static regret cannot imply a good performance in changing environments where tasks are sampled from heterogeneous distributions. To address the fairness-aware online learning problem in changing environments, in this paper, we first construct a novel regret metric FairSAR by adding long-term fairness constraints onto a strongly adapted loss regret. Furthermore, to determine a good model parameter at each round, we propose a novel adaptive fairness-aware online meta-learning algorithm, namely FairSAOML, which is able to adapt to changing environments in both bias control and model precision. The problem is formulated in the form of a bi-level convex-concave optimization with respect to the model's primal and dual parameters that are associated with the model's accuracy and fairness, respectively. The theoretic analysis provides sub-linear upper bounds for both loss regret and violation of cumulative fairness constraints. Our experimental evaluation on different real-world datasets with settings of changing environments suggests that the proposed FairSAOML significantly outperforms alternatives based on the best prior online learning approaches.
Uncertainty-Aware Reliable Text Classification
Jul 15, 2021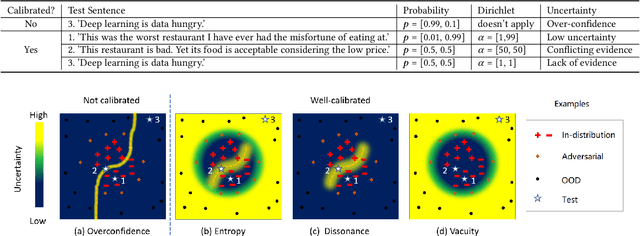
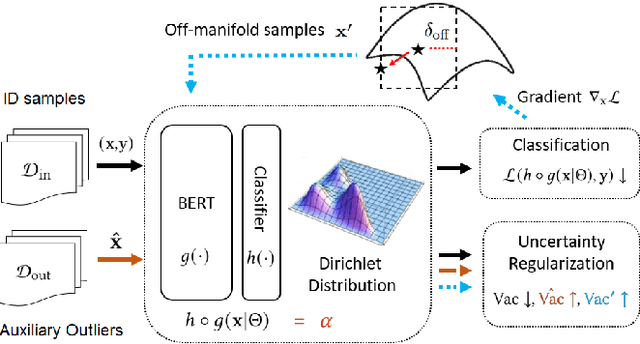
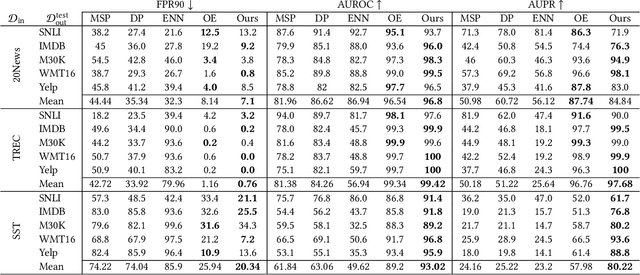
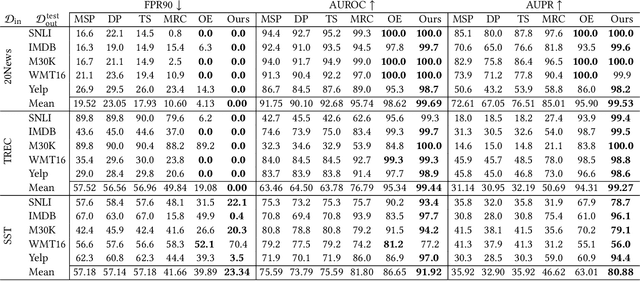
Deep neural networks have significantly contributed to the success in predictive accuracy for classification tasks. However, they tend to make over-confident predictions in real-world settings, where domain shifting and out-of-distribution (OOD) examples exist. Most research on uncertainty estimation focuses on computer vision because it provides visual validation on uncertainty quality. However, few have been presented in the natural language process domain. Unlike Bayesian methods that indirectly infer uncertainty through weight uncertainties, current evidential uncertainty-based methods explicitly model the uncertainty of class probabilities through subjective opinions. They further consider inherent uncertainty in data with different root causes, vacuity (i.e., uncertainty due to a lack of evidence) and dissonance (i.e., uncertainty due to conflicting evidence). In our paper, we firstly apply evidential uncertainty in OOD detection for text classification tasks. We propose an inexpensive framework that adopts both auxiliary outliers and pseudo off-manifold samples to train the model with prior knowledge of a certain class, which has high vacuity for OOD samples. Extensive empirical experiments demonstrate that our model based on evidential uncertainty outperforms other counterparts for detecting OOD examples. Our approach can be easily deployed to traditional recurrent neural networks and fine-tuned pre-trained transformers.
Towards Self-Adaptive Metric Learning On the Fly
Apr 03, 2021
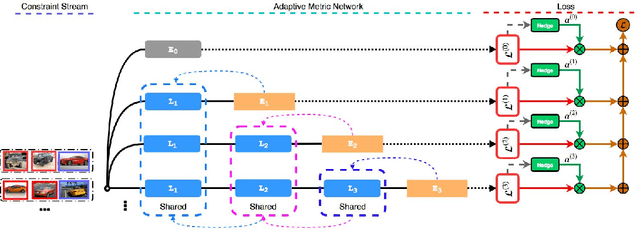
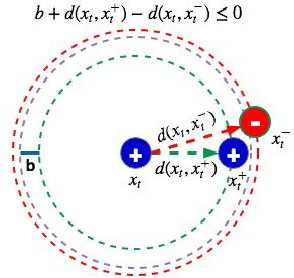
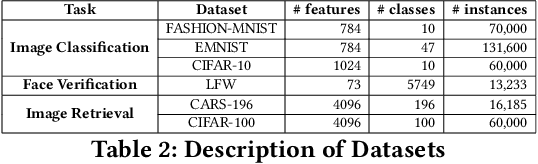
Good quality similarity metrics can significantly facilitate the performance of many large-scale, real-world applications. Existing studies have proposed various solutions to learn a Mahalanobis or bilinear metric in an online fashion by either restricting distances between similar (dissimilar) pairs to be smaller (larger) than a given lower (upper) bound or requiring similar instances to be separated from dissimilar instances with a given margin. However, these linear metrics learned by leveraging fixed bounds or margins may not perform well in real-world applications, especially when data distributions are complex. We aim to address the open challenge of "Online Adaptive Metric Learning" (OAML) for learning adaptive metric functions on the fly. Unlike traditional online metric learning methods, OAML is significantly more challenging since the learned metric could be non-linear and the model has to be self-adaptive as more instances are observed. In this paper, we present a new online metric learning framework that attempts to tackle the challenge by learning an ANN-based metric with adaptive model complexity from a stream of constraints. In particular, we propose a novel Adaptive-Bound Triplet Loss (ABTL) to effectively utilize the input constraints and present a novel Adaptive Hedge Update (AHU) method for online updating the model parameters. We empirically validate the effectiveness and efficacy of our framework on various applications such as real-world image classification, facial verification, and image retrieval.
SetConv: A New Approach for Learning from Imbalanced Data
Apr 03, 2021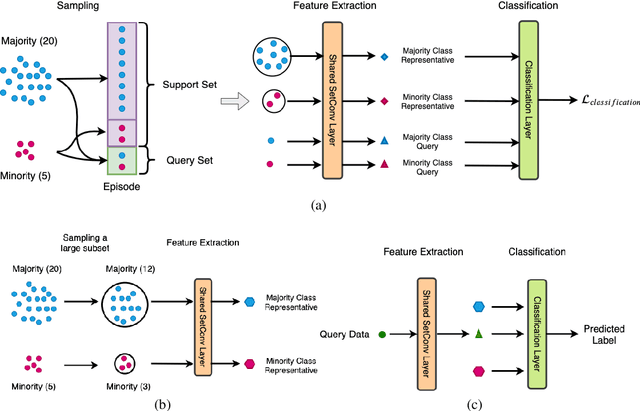
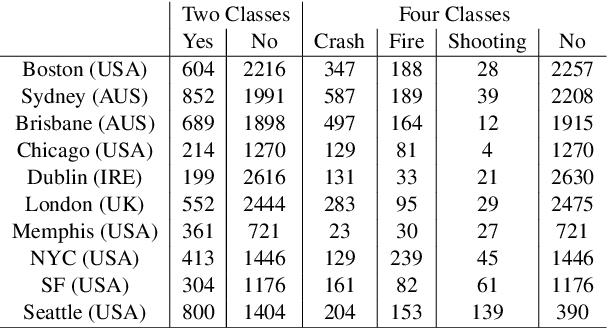
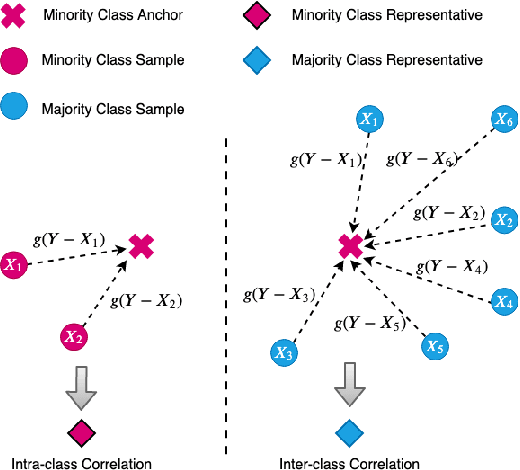
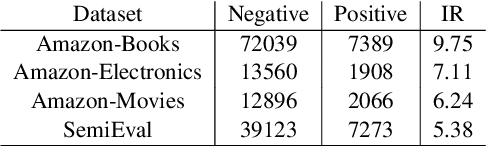
For many real-world classification problems, e.g., sentiment classification, most existing machine learning methods are biased towards the majority class when the Imbalance Ratio (IR) is high. To address this problem, we propose a set convolution (SetConv) operation and an episodic training strategy to extract a single representative for each class, so that classifiers can later be trained on a balanced class distribution. We prove that our proposed algorithm is permutation-invariant despite the order of inputs, and experiments on multiple large-scale benchmark text datasets show the superiority of our proposed framework when compared to other SOTA methods.
PDFM: A Primal-Dual Fairness-Aware Framework for Meta-learning
Oct 05, 2020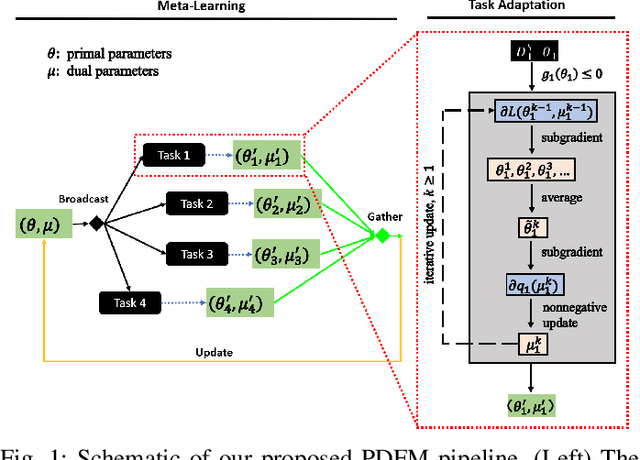
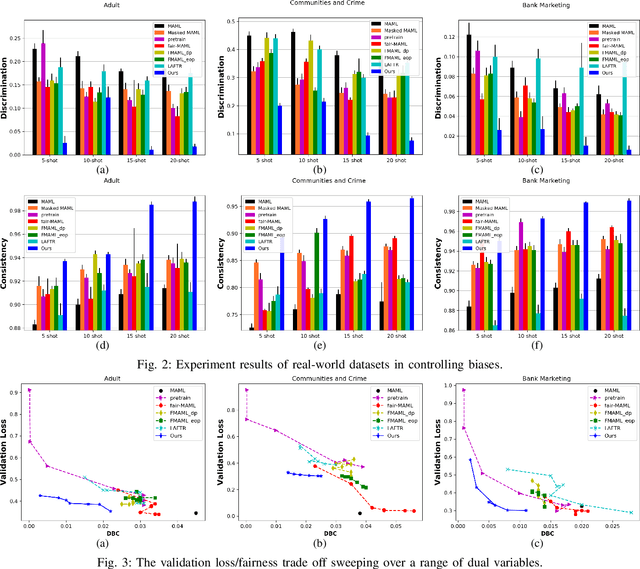
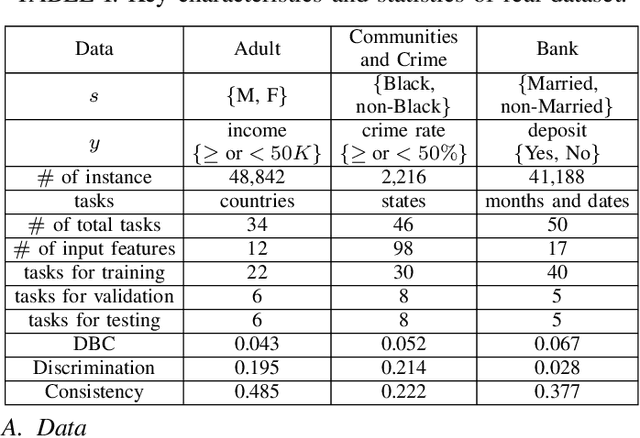
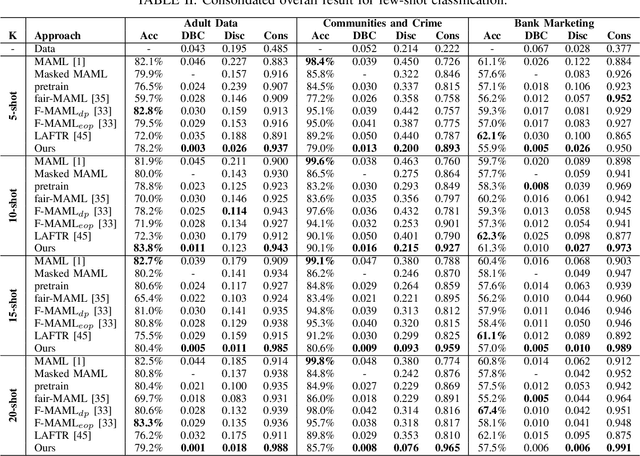
The problem of learning to generalize to unseen classes during training, known as few-shot classification, has attracted considerable attention. Initialization based methods, such as the gradient-based model agnostic meta-learning (MAML), tackle the few-shot learning problem by "learning to fine-tune". The goal of these approaches is to learn proper model initialization, so that the classifiers for new classes can be learned from a few labeled examples with a small number of gradient update steps. Few shot meta-learning is well-known with its fast-adapted capability and accuracy generalization onto unseen tasks. Learning fairly with unbiased outcomes is another significant hallmark of human intelligence, which is rarely touched in few-shot meta-learning. In this work, we propose a Primal-Dual Fair Meta-learning framework, namely PDFM, which learns to train fair machine learning models using only a few examples based on data from related tasks. The key idea is to learn a good initialization of a fair model's primal and dual parameters so that it can adapt to a new fair learning task via a few gradient update steps. Instead of manually tuning the dual parameters as hyperparameters via a grid search, PDFM optimizes the initialization of the primal and dual parameters jointly for fair meta-learning via a subgradient primal-dual approach. We further instantiate examples of bias controlling using mean difference and decision boundary covariance as fairness constraints to each task for supervised regression and classification, respectively. We demonstrate the versatility of our proposed approach by applying our approach to various real-world datasets. Our experiments show substantial improvements over the best prior work for this setting.
Deep Learning on Knowledge Graph for Recommender System: A Survey
Mar 25, 2020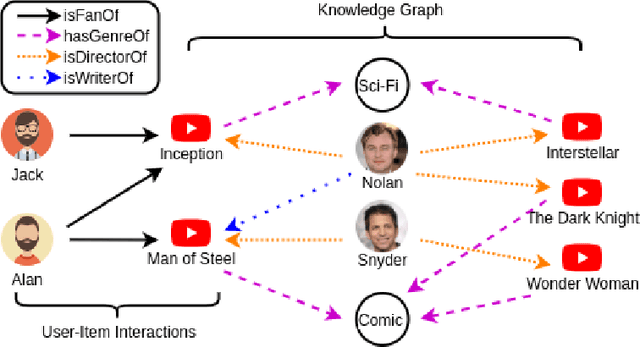
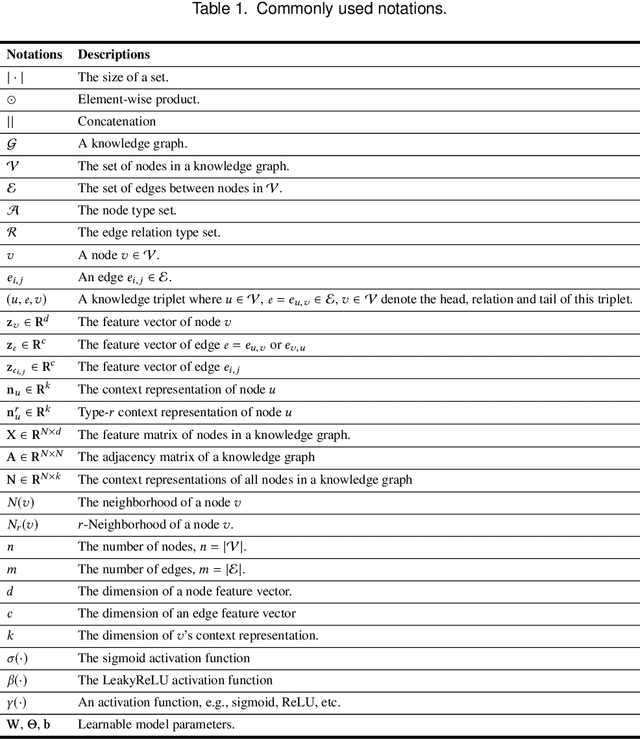
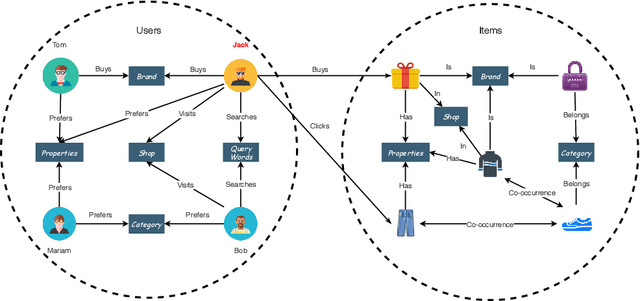

Recent advances in research have demonstrated the effectiveness of knowledge graphs (KG) in providing valuable external knowledge to improve recommendation systems (RS). A knowledge graph is capable of encoding high-order relations that connect two objects with one or multiple related attributes. With the help of the emerging Graph Neural Networks (GNN), it is possible to extract both object characteristics and relations from KG, which is an essential factor for successful recommendations. In this paper, we provide a comprehensive survey of the GNN-based knowledge-aware deep recommender systems. Specifically, we discuss the state-of-the-art frameworks with a focus on their core component, i.e., the graph embedding module, and how they address practical recommendation issues such as scalability, cold-start and so on. We further summarize the commonly-used benchmark datasets, evaluation metrics as well as open-source codes. Finally, we conclude the survey and propose potential research directions in this rapidly growing field.