 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNISP: Pruning Networks using Neuron Importance Score Propagation
Mar 21, 2018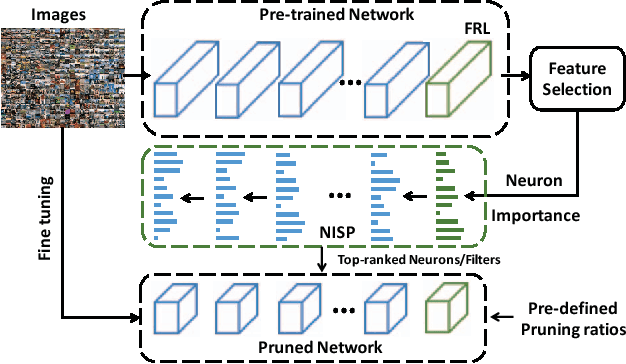
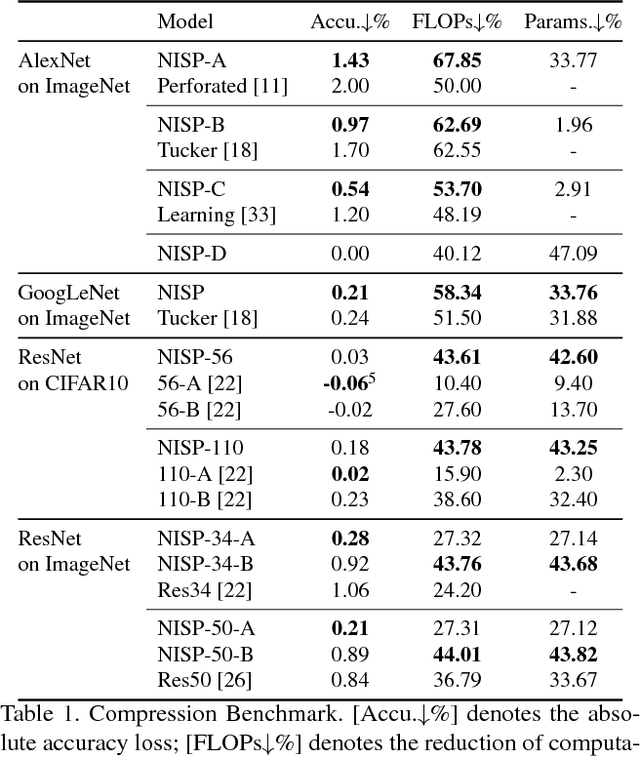
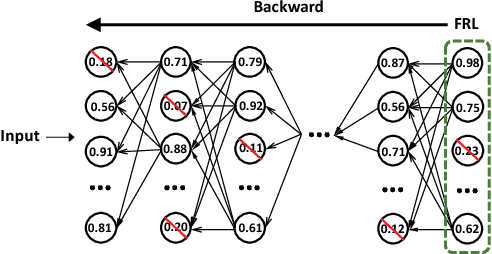
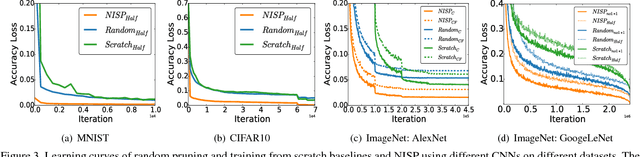
To reduce the significant redundancy in deep Convolutional Neural Networks (CNNs), most existing methods prune neurons by only considering statistics of an individual layer or two consecutive layers (e.g., prune one layer to minimize the reconstruction error of the next layer), ignoring the effect of error propagation in deep networks. In contrast, we argue that it is essential to prune neurons in the entire neuron network jointly based on a unified goal: minimizing the reconstruction error of important responses in the "final response layer" (FRL), which is the second-to-last layer before classification, for a pruned network to retrain its predictive power. Specifically, we apply feature ranking techniques to measure the importance of each neuron in the FRL, and formulate network pruning as a binary integer optimization problem and derive a closed-form solution to it for pruning neurons in earlier layers. Based on our theoretical analysis, we propose the Neuron Importance Score Propagation (NISP) algorithm to propagate the importance scores of final responses to every neuron in the network. The CNN is pruned by removing neurons with least importance, and then fine-tuned to retain its predictive power. NISP is evaluated on several datasets with multiple CNN models and demonstrated to achieve significant acceleration and compression with negligible accuracy loss.
ActionFlowNet: Learning Motion Representation for Action Recognition
Feb 16, 2018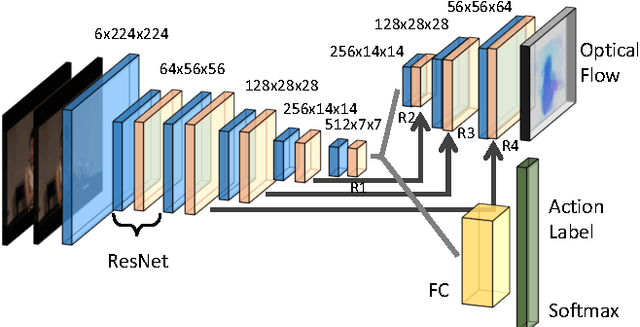
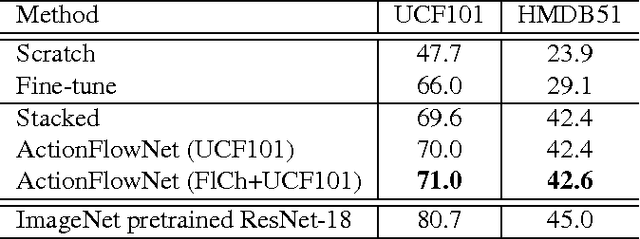
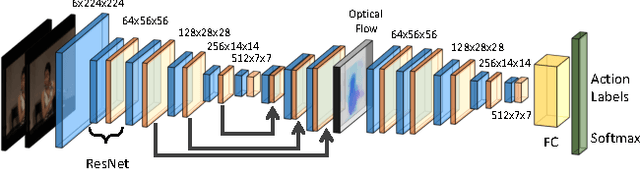
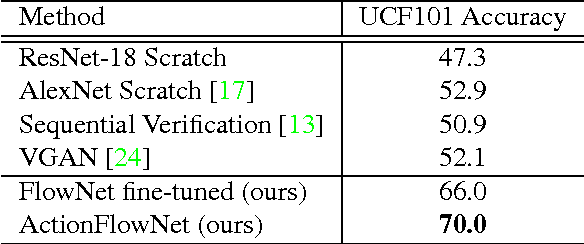
Even with the recent advances in convolutional neural networks (CNN) in various visual recognition tasks, the state-of-the-art action recognition system still relies on hand crafted motion feature such as optical flow to achieve the best performance. We propose a multitask learning model ActionFlowNet to train a single stream network directly from raw pixels to jointly estimate optical flow while recognizing actions with convolutional neural networks, capturing both appearance and motion in a single model. We additionally provide insights to how the quality of the learned optical flow affects the action recognition. Our model significantly improves action recognition accuracy by a large margin 31% compared to state-of-the-art CNN-based action recognition models trained without external large scale data and additional optical flow input. Without pretraining on large external labeled datasets, our model, by well exploiting the motion information, achieves competitive recognition accuracy to the models trained with large labeled datasets such as ImageNet and Sport-1M.
On Encoding Temporal Evolution for Real-time Action Prediction
Feb 08, 2018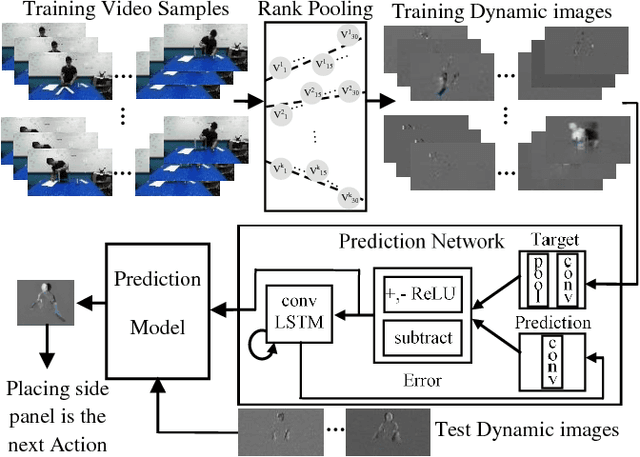
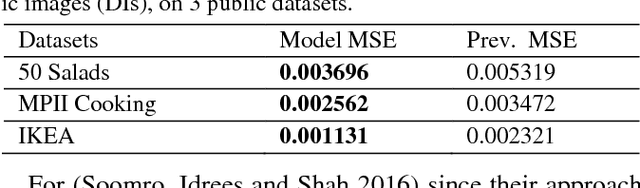

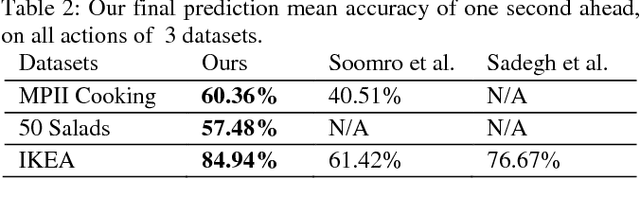
Anticipating future actions is a key component of intelligence, specifically when it applies to real-time systems, such as robots or autonomous cars. While recent works have addressed prediction of raw RGB pixel values, we focus on anticipating the motion evolution in future video frames. To this end, we construct dynamic images (DIs) by summarising moving pixels through a sequence of future frames. We train a convolutional LSTMs to predict the next DIs based on an unsupervised learning process, and then recognise the activity associated with the predicted DI. We demonstrate the effectiveness of our approach on 3 benchmark action datasets showing that despite running on videos with complex activities, our approach is able to anticipate the next human action with high accuracy and obtain better results than the state-of-the-art methods.
ReMotENet: Efficient Relevant Motion Event Detection for Large-scale Home Surveillance Videos
Jan 06, 2018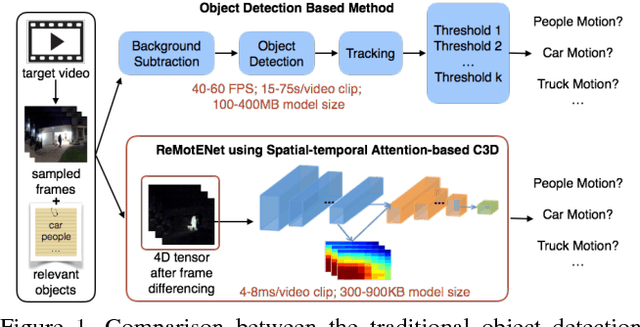
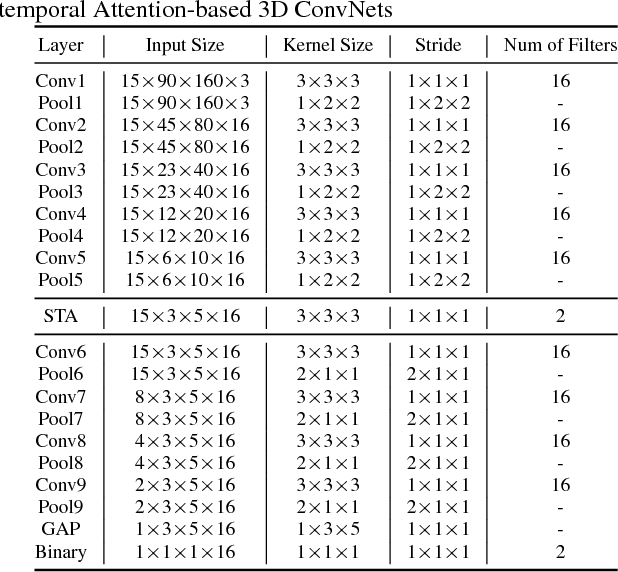
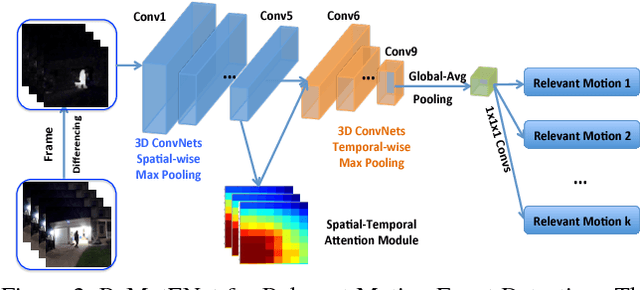
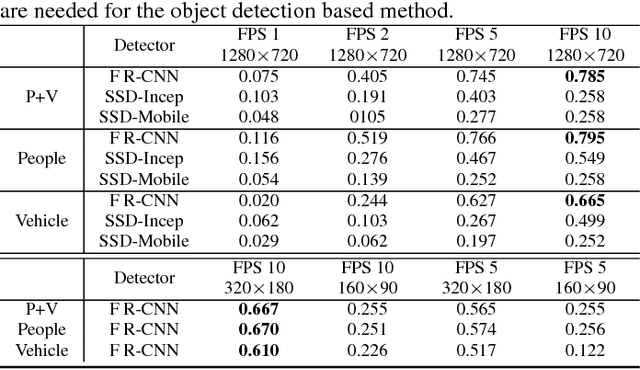
This paper addresses the problem of detecting relevant motion caused by objects of interest (e.g., person and vehicles) in large scale home surveillance videos. The traditional method usually consists of two separate steps, i.e., detecting moving objects with background subtraction running on the camera, and filtering out nuisance motion events (e.g., trees, cloud, shadow, rain/snow, flag) with deep learning based object detection and tracking running on cloud. The method is extremely slow and therefore not cost effective, and does not fully leverage the spatial-temporal redundancies with a pre-trained off-the-shelf object detector. To dramatically speedup relevant motion event detection and improve its performance, we propose a novel network for relevant motion event detection, ReMotENet, which is a unified, end-to-end data-driven method using spatial-temporal attention-based 3D ConvNets to jointly model the appearance and motion of objects-of-interest in a video. ReMotENet parses an entire video clip in one forward pass of a neural network to achieve significant speedup. Meanwhile, it exploits the properties of home surveillance videos, e.g., relevant motion is sparse both spatially and temporally, and enhances 3D ConvNets with a spatial-temporal attention model and reference-frame subtraction to encourage the network to focus on the relevant moving objects. Experiments demonstrate that our method can achieve comparable or event better performance than the object detection based method but with three to four orders of magnitude speedup (up to 20k times) on GPU devices. Our network is efficient, compact and light-weight. It can detect relevant motion on a 15s surveillance video clip within 4-8 milliseconds on a GPU and a fraction of second (0.17-0.39) on a CPU with a model size of less than 1MB.
Deception Detection in Videos
Dec 12, 2017
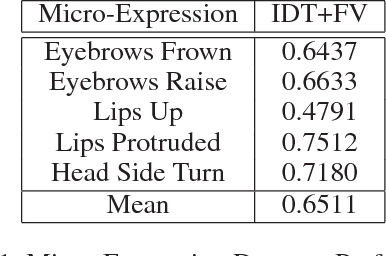
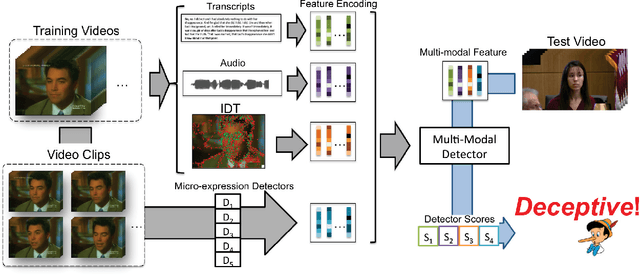
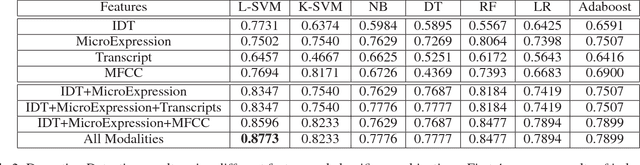
We present a system for covert automated deception detection in real-life courtroom trial videos. We study the importance of different modalities like vision, audio and text for this task. On the vision side, our system uses classifiers trained on low level video features which predict human micro-expressions. We show that predictions of high-level micro-expressions can be used as features for deception prediction. Surprisingly, IDT (Improved Dense Trajectory) features which have been widely used for action recognition, are also very good at predicting deception in videos. We fuse the score of classifiers trained on IDT features and high-level micro-expressions to improve performance. MFCC (Mel-frequency Cepstral Coefficients) features from the audio domain also provide a significant boost in performance, while information from transcripts is not very beneficial for our system. Using various classifiers, our automated system obtains an AUC of 0.877 (10-fold cross-validation) when evaluated on subjects which were not part of the training set. Even though state-of-the-art methods use human annotations of micro-expressions for deception detection, our fully automated approach outperforms them by 5%. When combined with human annotations of micro-expressions, our AUC improves to 0.922. We also present results of a user-study to analyze how well do average humans perform on this task, what modalities they use for deception detection and how they perform if only one modality is accessible. Our project page can be found at \url{https://doubaibai.github.io/DARE/}.
R-FCN-3000 at 30fps: Decoupling Detection and Classification
Dec 05, 2017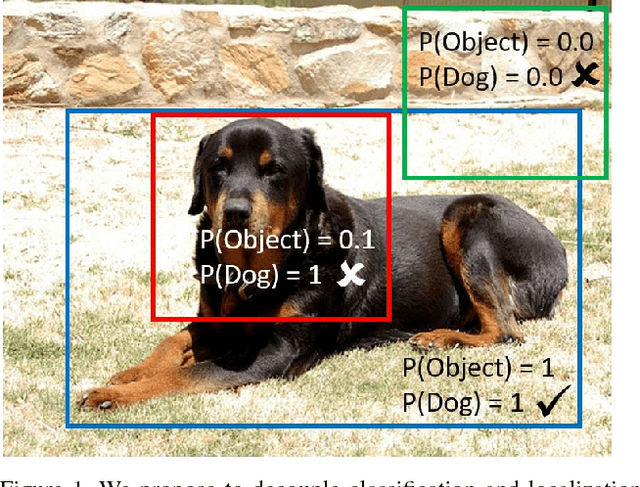
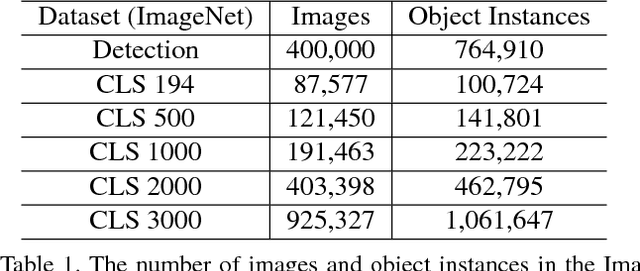
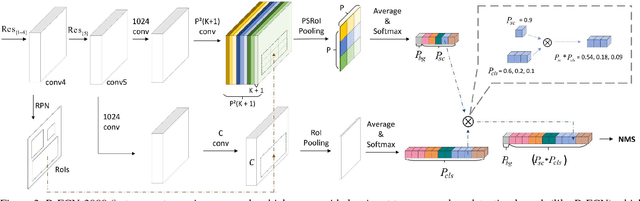

We present R-FCN-3000, a large-scale real-time object detector in which objectness detection and classification are decoupled. To obtain the detection score for an RoI, we multiply the objectness score with the fine-grained classification score. Our approach is a modification of the R-FCN architecture in which position-sensitive filters are shared across different object classes for performing localization. For fine-grained classification, these position-sensitive filters are not needed. R-FCN-3000 obtains an mAP of 34.9% on the ImageNet detection dataset and outperforms YOLO-9000 by 18% while processing 30 images per second. We also show that the objectness learned by R-FCN-3000 generalizes to novel classes and the performance increases with the number of training object classes - supporting the hypothesis that it is possible to learn a universal objectness detector. Code will be made available.
Soft-NMS -- Improving Object Detection With One Line of Code
Aug 08, 2017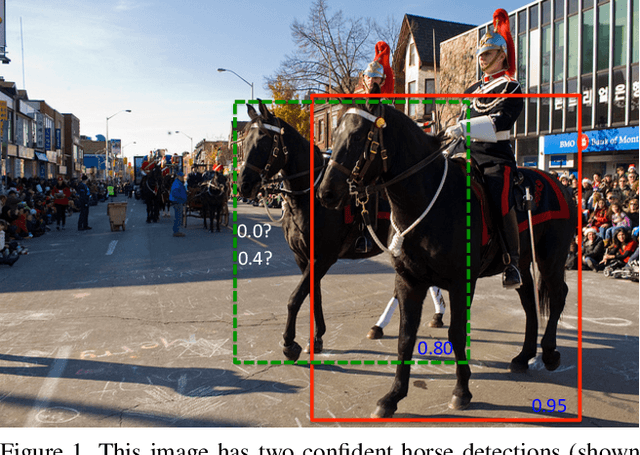
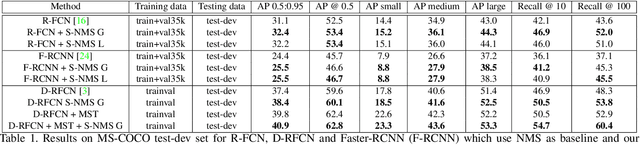
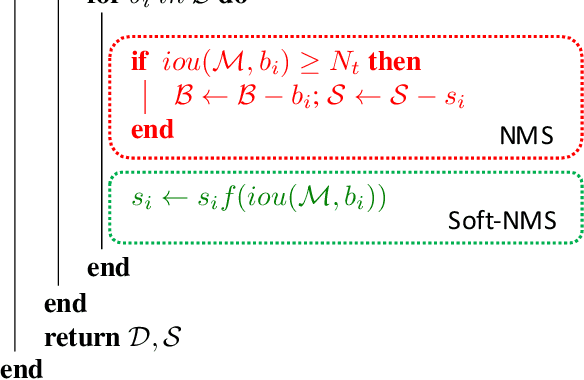

Non-maximum suppression is an integral part of the object detection pipeline. First, it sorts all detection boxes on the basis of their scores. The detection box M with the maximum score is selected and all other detection boxes with a significant overlap (using a pre-defined threshold) with M are suppressed. This process is recursively applied on the remaining boxes. As per the design of the algorithm, if an object lies within the predefined overlap threshold, it leads to a miss. To this end, we propose Soft-NMS, an algorithm which decays the detection scores of all other objects as a continuous function of their overlap with M. Hence, no object is eliminated in this process. Soft-NMS obtains consistent improvements for the coco-style mAP metric on standard datasets like PASCAL VOC 2007 (1.7% for both R-FCN and Faster-RCNN) and MS-COCO (1.3% for R-FCN and 1.1% for Faster-RCNN) by just changing the NMS algorithm without any additional hyper-parameters. Using Deformable-RFCN, Soft-NMS improves state-of-the-art in object detection from 39.8% to 40.9% with a single model. Further, the computational complexity of Soft-NMS is the same as traditional NMS and hence it can be efficiently implemented. Since Soft-NMS does not require any extra training and is simple to implement, it can be easily integrated into any object detection pipeline. Code for Soft-NMS is publicly available on GitHub (http://bit.ly/2nJLNMu).
Temporal Context Network for Activity Localization in Videos
Aug 08, 2017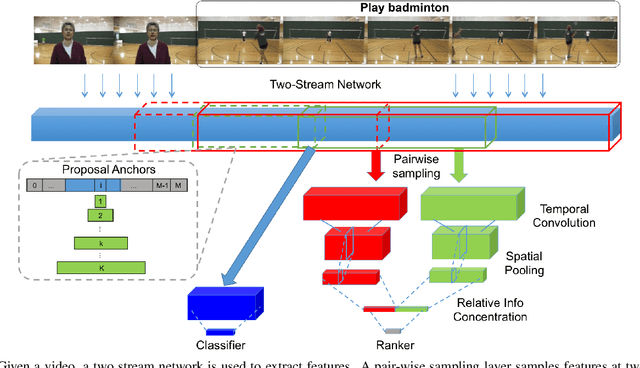

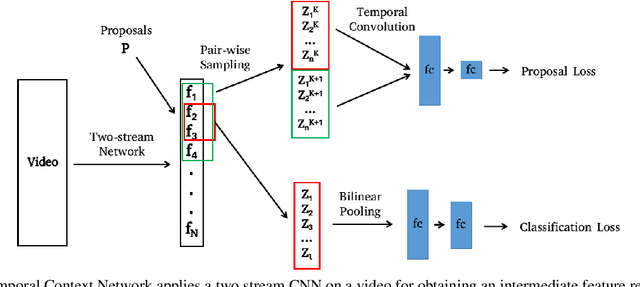
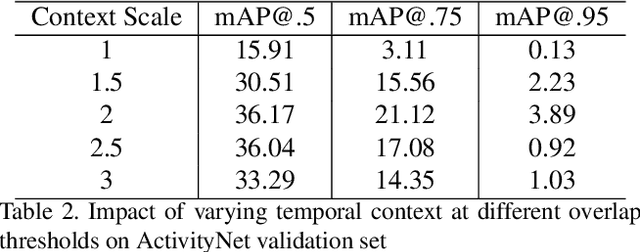
We present a Temporal Context Network (TCN) for precise temporal localization of human activities. Similar to the Faster-RCNN architecture, proposals are placed at equal intervals in a video which span multiple temporal scales. We propose a novel representation for ranking these proposals. Since pooling features only inside a segment is not sufficient to predict activity boundaries, we construct a representation which explicitly captures context around a proposal for ranking it. For each temporal segment inside a proposal, features are uniformly sampled at a pair of scales and are input to a temporal convolutional neural network for classification. After ranking proposals, non-maximum suppression is applied and classification is performed to obtain final detections. TCN outperforms state-of-the-art methods on the ActivityNet dataset and the THUMOS14 dataset.
Automatic Spatially-aware Fashion Concept Discovery
Aug 03, 2017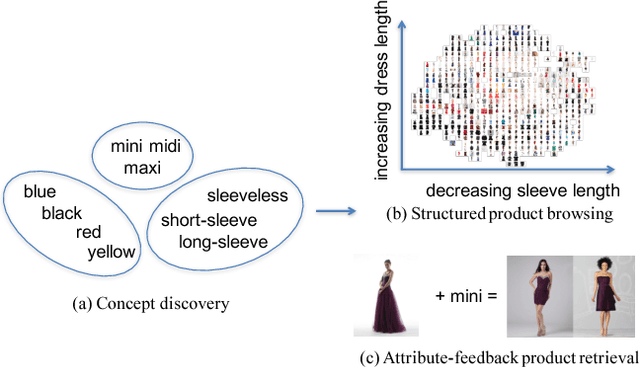
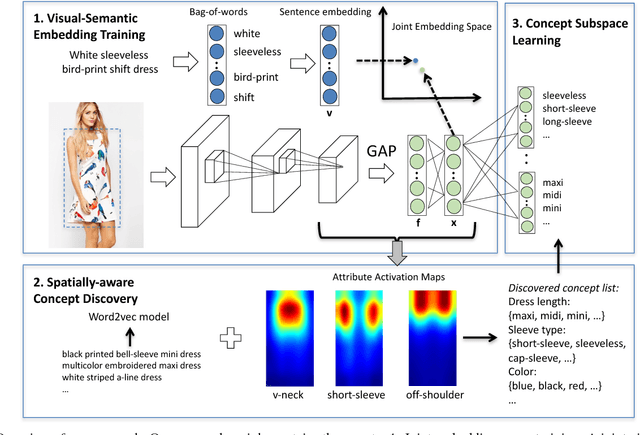


This paper proposes an automatic spatially-aware concept discovery approach using weakly labeled image-text data from shopping websites. We first fine-tune GoogleNet by jointly modeling clothing images and their corresponding descriptions in a visual-semantic embedding space. Then, for each attribute (word), we generate its spatially-aware representation by combining its semantic word vector representation with its spatial representation derived from the convolutional maps of the fine-tuned network. The resulting spatially-aware representations are further used to cluster attributes into multiple groups to form spatially-aware concepts (e.g., the neckline concept might consist of attributes like v-neck, round-neck, etc). Finally, we decompose the visual-semantic embedding space into multiple concept-specific subspaces, which facilitates structured browsing and attribute-feedback product retrieval by exploiting multimodal linguistic regularities. We conducted extensive experiments on our newly collected Fashion200K dataset, and results on clustering quality evaluation and attribute-feedback product retrieval task demonstrate the effectiveness of our automatically discovered spatially-aware concepts.
Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation
Aug 03, 2017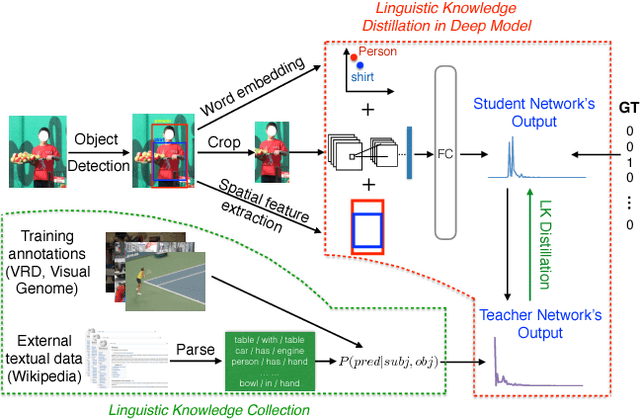
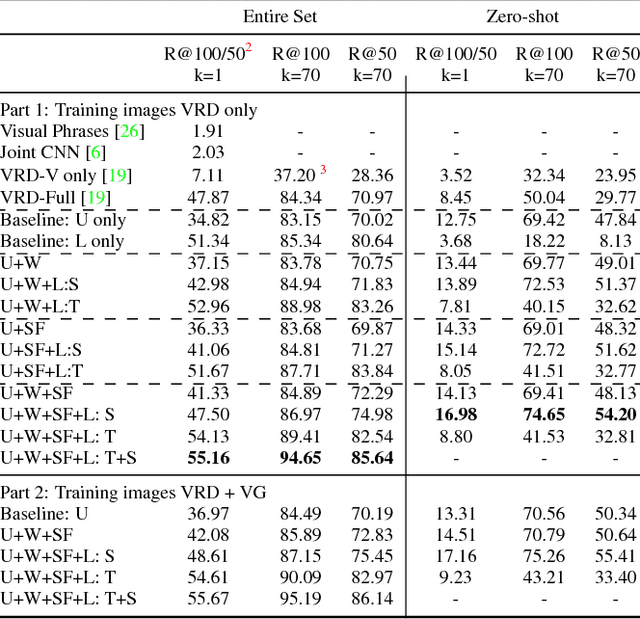

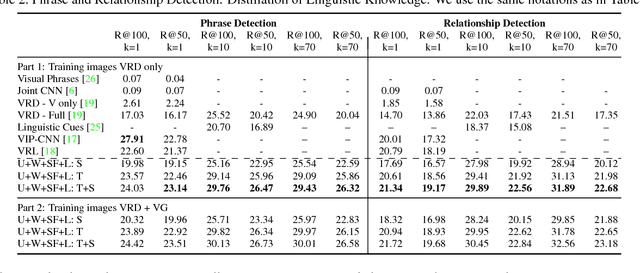
Understanding visual relationships involves identifying the subject, the object, and a predicate relating them. We leverage the strong correlations between the predicate and the (subj,obj) pair (both semantically and spatially) to predict the predicates conditioned on the subjects and the objects. Modeling the three entities jointly more accurately reflects their relationships, but complicates learning since the semantic space of visual relationships is huge and the training data is limited, especially for the long-tail relationships that have few instances. To overcome this, we use knowledge of linguistic statistics to regularize visual model learning. We obtain linguistic knowledge by mining from both training annotations (internal knowledge) and publicly available text, e.g., Wikipedia (external knowledge), computing the conditional probability distribution of a predicate given a (subj,obj) pair. Then, we distill the knowledge into a deep model to achieve better generalization. Our experimental results on the Visual Relationship Detection (VRD) and Visual Genome datasets suggest that with this linguistic knowledge distillation, our model outperforms the state-of-the-art methods significantly, especially when predicting unseen relationships (e.g., recall improved from 8.45% to 19.17% on VRD zero-shot testing set).