 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Spatio-Temporal Pretext Learning for Self-supervised Video Representation
Dec 19, 2021
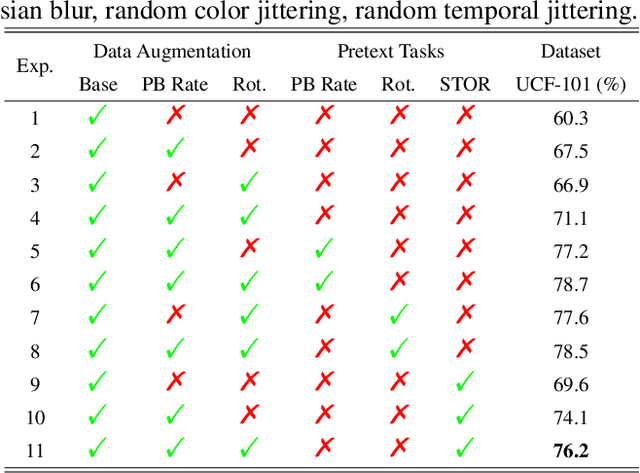
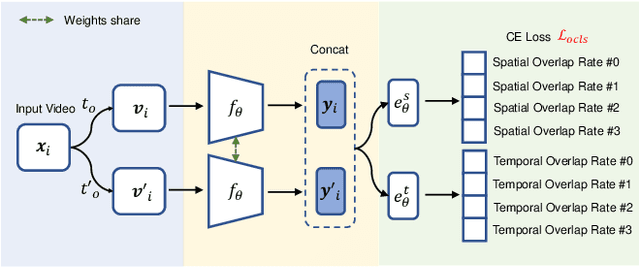
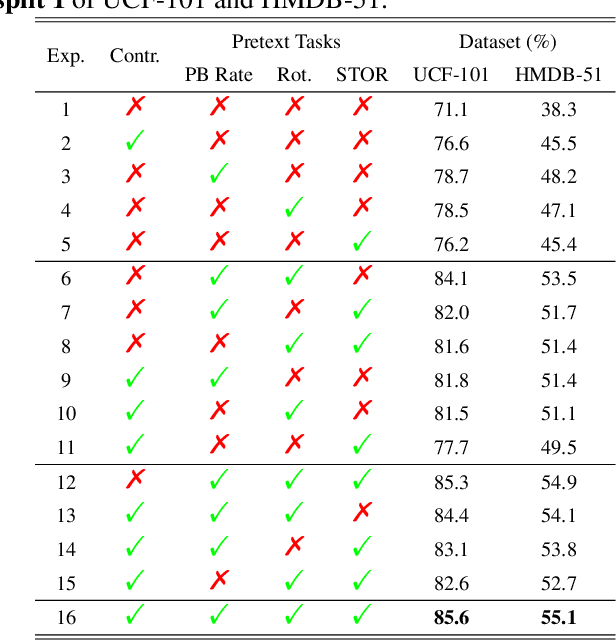
Spatio-temporal representation learning is critical for video self-supervised representation. Recent approaches mainly use contrastive learning and pretext tasks. However, these approaches learn representation by discriminating sampled instances via feature similarity in the latent space while ignoring the intermediate state of the learned representations, which limits the overall performance. In this work, taking into account the degree of similarity of sampled instances as the intermediate state, we propose a novel pretext task - spatio-temporal overlap rate (STOR) prediction. It stems from the observation that humans are capable of discriminating the overlap rates of videos in space and time. This task encourages the model to discriminate the STOR of two generated samples to learn the representations. Moreover, we employ a joint optimization combining pretext tasks with contrastive learning to further enhance the spatio-temporal representation learning. We also study the mutual influence of each component in the proposed scheme. Extensive experiments demonstrate that our proposed STOR task can favor both contrastive learning and pretext tasks. The joint optimization scheme can significantly improve the spatio-temporal representation in video understanding. The code is available at https://github.com/Katou2/CSTP.
CSRNet: Cascaded Selective Resolution Network for Real-time Semantic Segmentation
Jun 08, 2021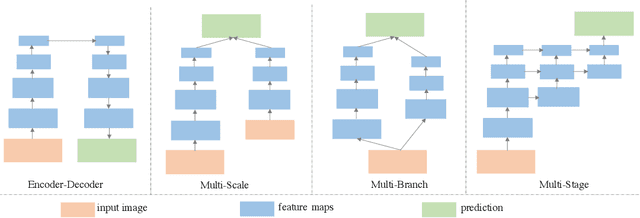
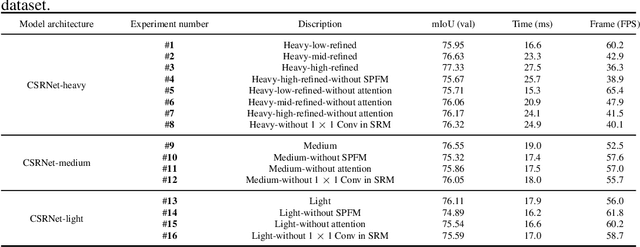
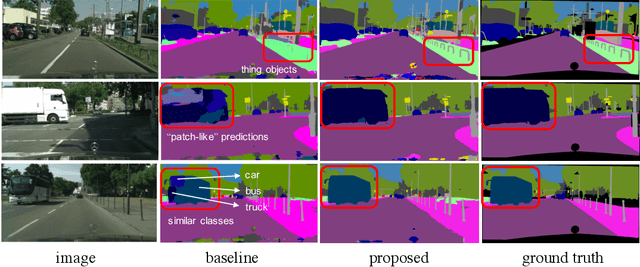
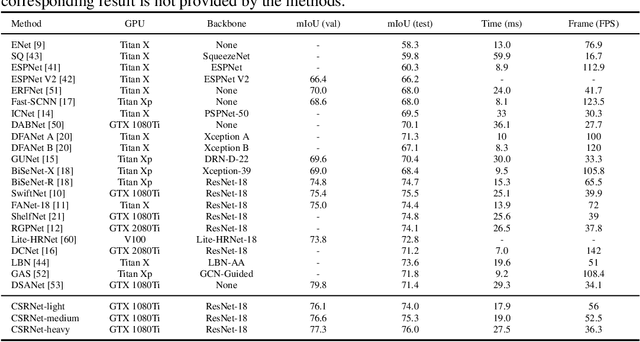
Real-time semantic segmentation has received considerable attention due to growing demands in many practical applications, such as autonomous vehicles, robotics, etc. Existing real-time segmentation approaches often utilize feature fusion to improve segmentation accuracy. However, they fail to fully consider the feature information at different resolutions and the receptive fields of the networks are relatively limited, thereby compromising the performance. To tackle this problem, we propose a light Cascaded Selective Resolution Network (CSRNet) to improve the performance of real-time segmentation through multiple context information embedding and enhanced feature aggregation. The proposed network builds a three-stage segmentation system, which integrates feature information from low resolution to high resolution and achieves feature refinement progressively. CSRNet contains two critical modules: the Shorted Pyramid Fusion Module (SPFM) and the Selective Resolution Module (SRM). The SPFM is a computationally efficient module to incorporate the global context information and significantly enlarge the receptive field at each stage. The SRM is designed to fuse multi-resolution feature maps with various receptive fields, which assigns soft channel attentions across the feature maps and helps to remedy the problem caused by multi-scale objects. Comprehensive experiments on two well-known datasets demonstrate that the proposed CSRNet effectively improves the performance for real-time segmentation.
VCGAN: Video Colorization with Hybrid Generative Adversarial Network
Apr 26, 2021



We propose a hybrid recurrent Video Colorization with Hybrid Generative Adversarial Network (VCGAN), an improved approach to video colorization using end-to-end learning. The VCGAN addresses two prevalent issues in the video colorization domain: Temporal consistency and unification of colorization network and refinement network into a single architecture. To enhance colorization quality and spatiotemporal consistency, the mainstream of generator in VCGAN is assisted by two additional networks, i.e., global feature extractor and placeholder feature extractor, respectively. The global feature extractor encodes the global semantics of grayscale input to enhance colorization quality, whereas the placeholder feature extractor acts as a feedback connection to encode the semantics of the previous colorized frame in order to maintain spatiotemporal consistency. If changing the input for placeholder feature extractor as grayscale input, the hybrid VCGAN also has the potential to perform image colorization. To improve the consistency of far frames, we propose a dense long-term loss that smooths the temporal disparity of every two remote frames. Trained with colorization and temporal losses jointly, VCGAN strikes a good balance between color vividness and video continuity. Experimental results demonstrate that VCGAN produces higher-quality and temporally more consistent colorful videos than existing approaches.
Spatial Content Alignment For Pose Transfer
Mar 31, 2021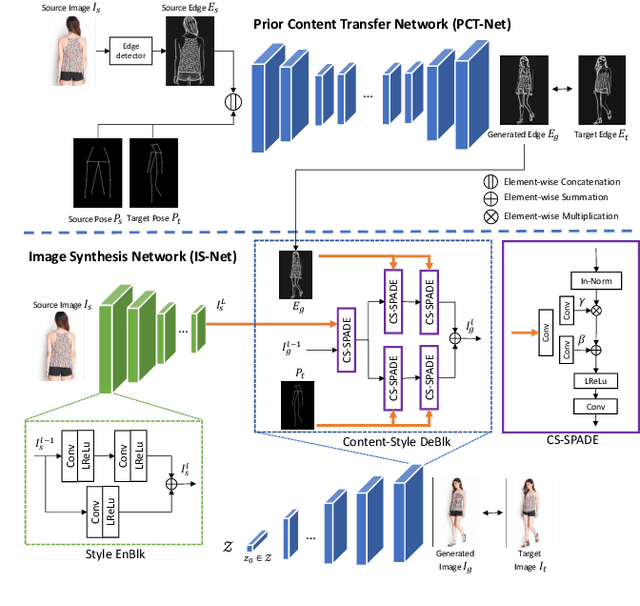
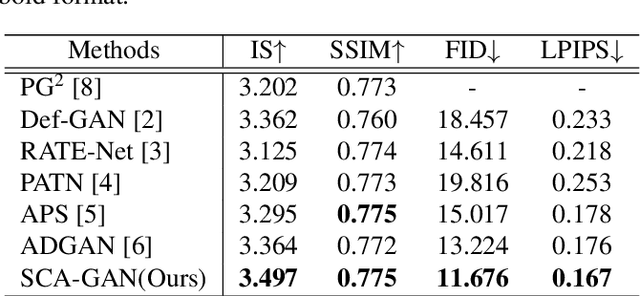
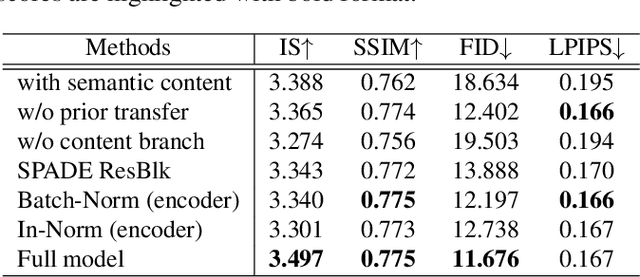

Due to unreliable geometric matching and content misalignment, most conventional pose transfer algorithms fail to generate fine-trained person images. In this paper, we propose a novel framework Spatial Content Alignment GAN (SCAGAN) which aims to enhance the content consistency of garment textures and the details of human characteristics. We first alleviate the spatial misalignment by transferring the edge content to the target pose in advance. Secondly, we introduce a new Content-Style DeBlk which can progressively synthesize photo-realistic person images based on the appearance features of the source image, the target pose heatmap and the prior transferred content in edge domain. We compare the proposed framework with several state-of-the-art methods to show its superiority in quantitative and qualitative analysis. Moreover, detailed ablation study results demonstrate the efficacy of our contributions. Codes are publicly available at github.com/rocketappslab/SCA-GAN.
SCGAN: Saliency Map-guided Colorization with Generative Adversarial Network
Nov 23, 2020



Given a grayscale photograph, the colorization system estimates a visually plausible colorful image. Conventional methods often use semantics to colorize grayscale images. However, in these methods, only classification semantic information is embedded, resulting in semantic confusion and color bleeding in the final colorized image. To address these issues, we propose a fully automatic Saliency Map-guided Colorization with Generative Adversarial Network (SCGAN) framework. It jointly predicts the colorization and saliency map to minimize semantic confusion and color bleeding in the colorized image. Since the global features from pre-trained VGG-16-Gray network are embedded to the colorization encoder, the proposed SCGAN can be trained with much less data than state-of-the-art methods to achieve perceptually reasonable colorization. In addition, we propose a novel saliency map-based guidance method. Branches of the colorization decoder are used to predict the saliency map as a proxy target. Moreover, two hierarchical discriminators are utilized for the generated colorization and saliency map, respectively, in order to strengthen visual perception performance. The proposed system is evaluated on ImageNet validation set. Experimental results show that SCGAN can generate more reasonable colorized images than state-of-the-art techniques.
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020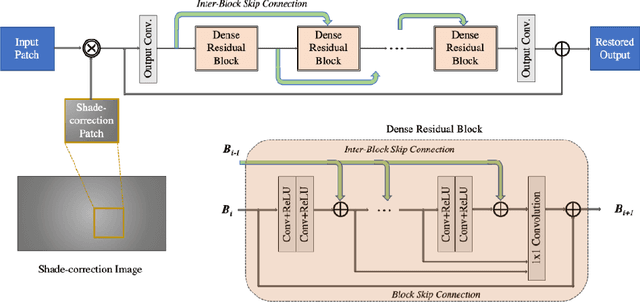
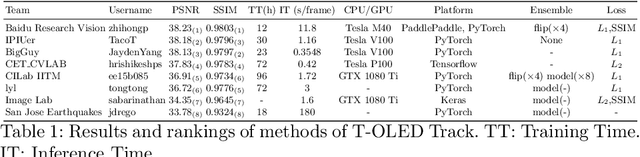
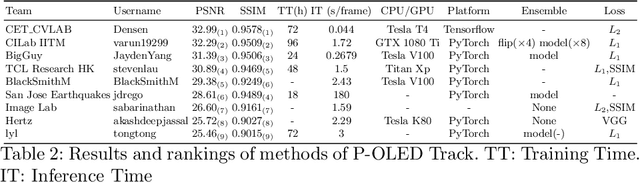
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.
Hierarchical Regression Network for Spectral Reconstruction from RGB Images
May 10, 2020
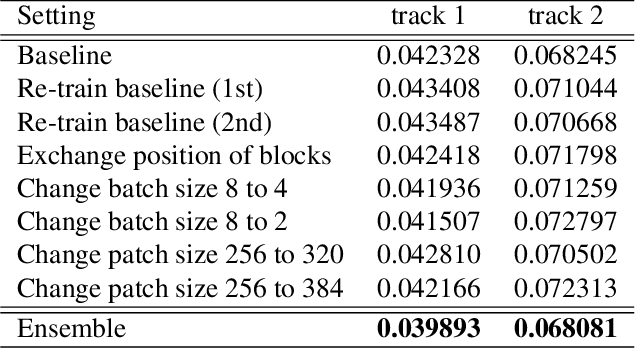
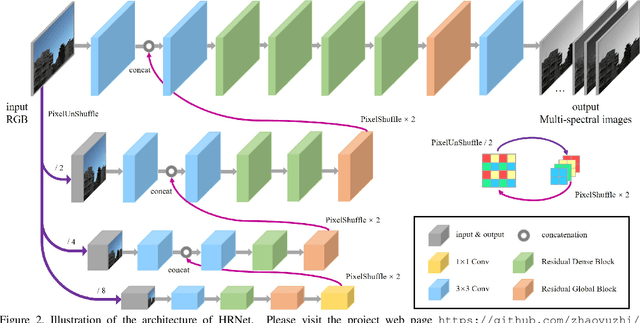
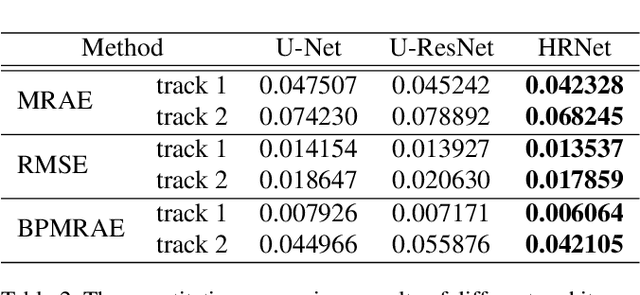
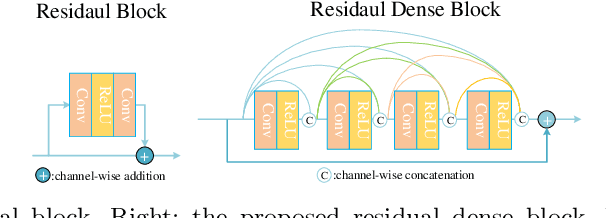
Capturing visual image with a hyperspectral camera has been successfully applied to many areas due to its narrow-band imaging technology. Hyperspectral reconstruction from RGB images denotes a reverse process of hyperspectral imaging by discovering an inverse response function. Current works mainly map RGB images directly to corresponding spectrum but do not consider context information explicitly. Moreover, the use of encoder-decoder pair in current algorithms leads to loss of information. To address these problems, we propose a 4-level Hierarchical Regression Network (HRNet) with PixelShuffle layer as inter-level interaction. Furthermore, we adopt a residual dense block to remove artifacts of real world RGB images and a residual global block to build attention mechanism for enlarging perceptive field. We evaluate proposed HRNet with other architectures and techniques by participating in NTIRE 2020 Challenge on Spectral Reconstruction from RGB Images. The HRNet is the winning method of track 2 - real world images and ranks 3rd on track 1 - clean images. Please visit the project web page https://github.com/zhaoyuzhi/Hierarchical-Regression-Network-for-Spectral-Reconstruction-from-RGB-Images to try our codes and pre-trained models.