 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraining Effective Field Theories with Machine Learning
Jul 26, 2018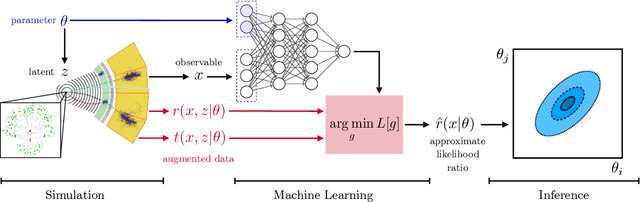
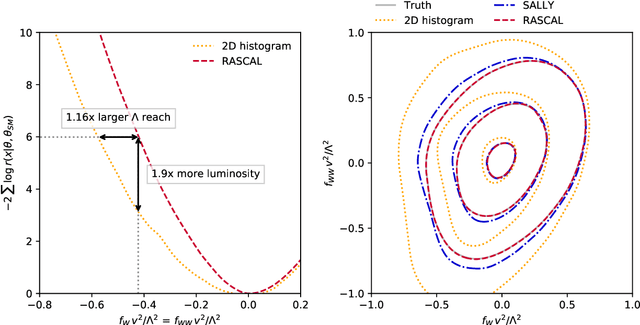
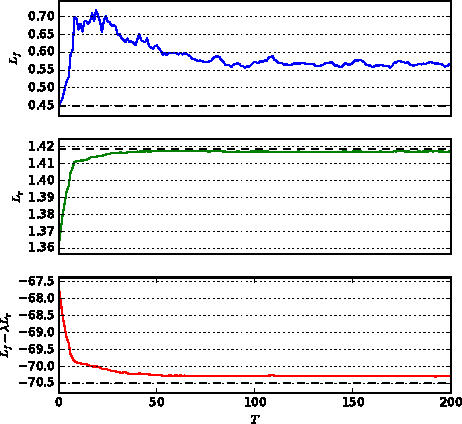
We present powerful new analysis techniques to constrain effective field theories at the LHC. By leveraging the structure of particle physics processes, we extract extra information from Monte-Carlo simulations, which can be used to train neural network models that estimate the likelihood ratio. These methods scale well to processes with many observables and theory parameters, do not require any approximations of the parton shower or detector response, and can be evaluated in microseconds. We show that they allow us to put significantly stronger bounds on dimension-six operators than existing methods, demonstrating their potential to improve the precision of the LHC legacy constraints.
* See also the companion publication "A Guide to Constraining Effective Field Theories with Machine Learning" at arXiv:1805.00020, an in-depth analysis of machine learning techniques for LHC measurements. The code for these studies is available at https://github.com/johannbrehmer/higgs_inference . v2: New schematic figure explaining the new algorithms, added references. v3, v4: Added references
QCD-Aware Recursive Neural Networks for Jet Physics
Jul 13, 2018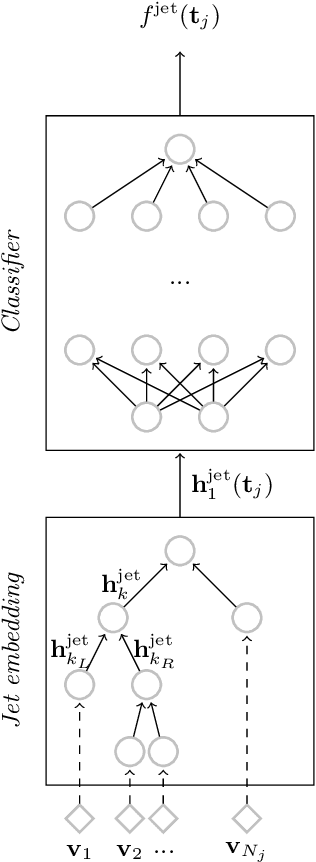
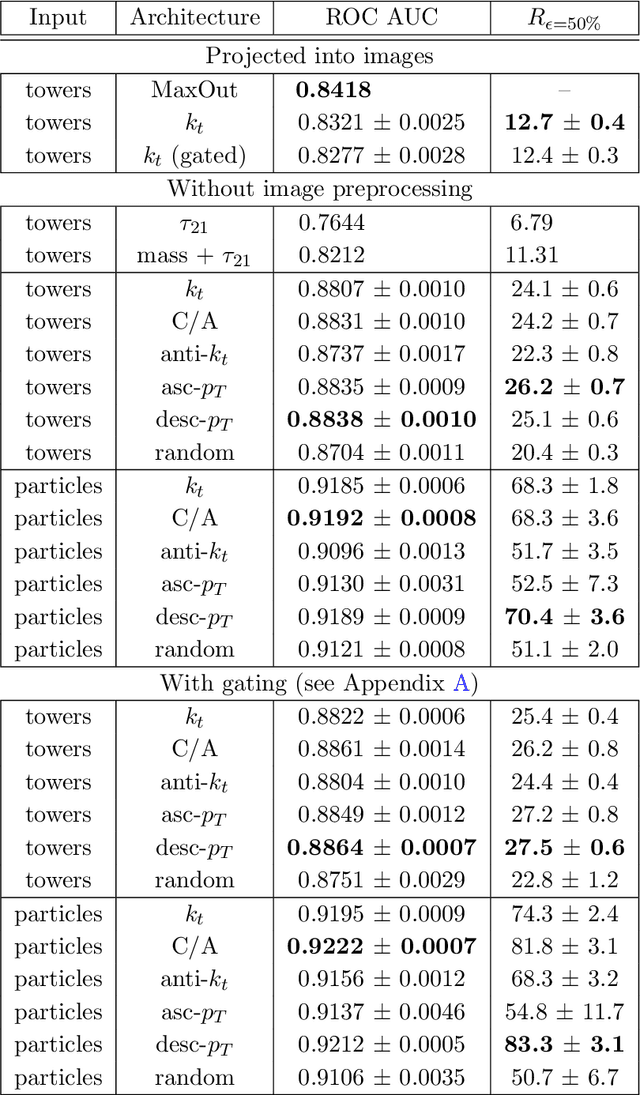
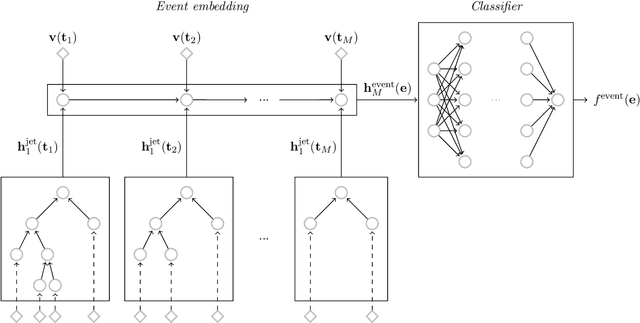
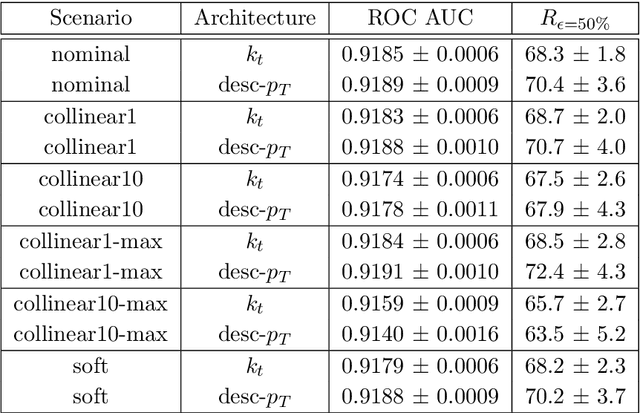
Recent progress in applying machine learning for jet physics has been built upon an analogy between calorimeters and images. In this work, we present a novel class of recursive neural networks built instead upon an analogy between QCD and natural languages. In the analogy, four-momenta are like words and the clustering history of sequential recombination jet algorithms is like the parsing of a sentence. Our approach works directly with the four-momenta of a variable-length set of particles, and the jet-based tree structure varies on an event-by-event basis. Our experiments highlight the flexibility of our method for building task-specific jet embeddings and show that recursive architectures are significantly more accurate and data efficient than previous image-based networks. We extend the analogy from individual jets (sentences) to full events (paragraphs), and show for the first time an event-level classifier operating on all the stable particles produced in an LHC event.
Machine Learning in High Energy Physics Community White Paper
Jul 08, 2018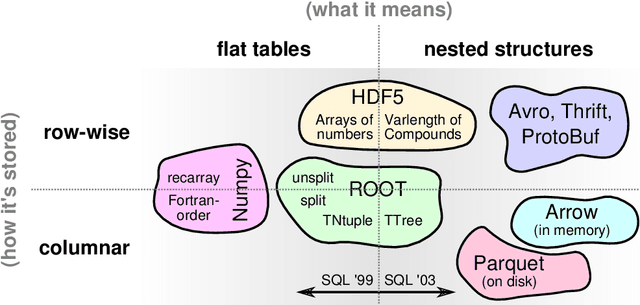
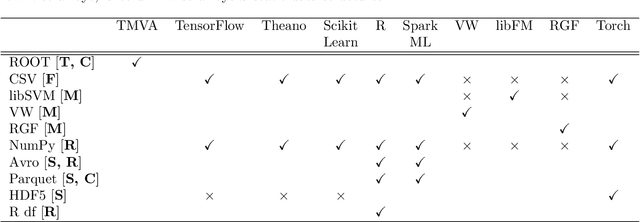

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.
Backdrop: Stochastic Backpropagation
Jun 04, 2018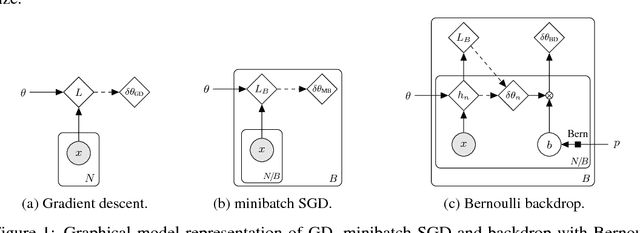
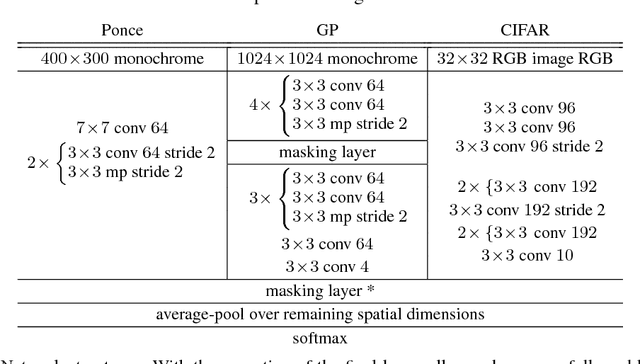
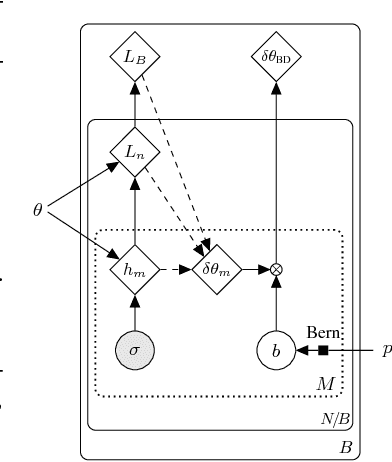
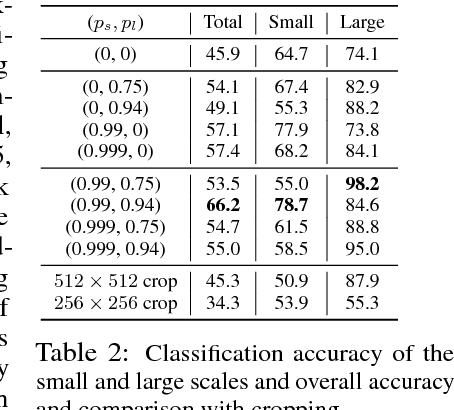
We introduce backdrop, a flexible and simple-to-implement method, intuitively described as dropout acting only along the backpropagation pipeline. Backdrop is implemented via one or more masking layers which are inserted at specific points along the network. Each backdrop masking layer acts as the identity in the forward pass, but randomly masks parts of the backward gradient propagation. Intuitively, inserting a backdrop layer after any convolutional layer leads to stochastic gradients corresponding to features of that scale. Therefore, backdrop is well suited for problems in which the data have a multi-scale, hierarchical structure. Backdrop can also be applied to problems with non-decomposable loss functions where standard SGD methods are not well suited. We perform a number of experiments and demonstrate that backdrop leads to significant improvements in generalization.
Improvements to Inference Compilation for Probabilistic Programming in Large-Scale Scientific Simulators
Dec 21, 2017
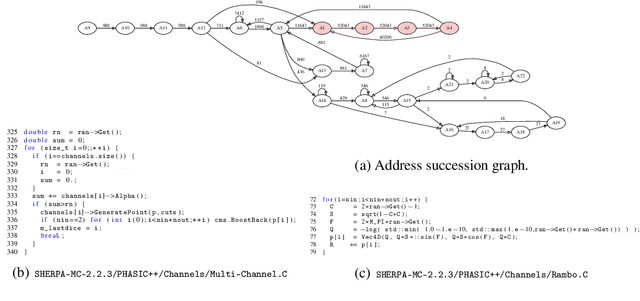
We consider the problem of Bayesian inference in the family of probabilistic models implicitly defined by stochastic generative models of data. In scientific fields ranging from population biology to cosmology, low-level mechanistic components are composed to create complex generative models. These models lead to intractable likelihoods and are typically non-differentiable, which poses challenges for traditional approaches to inference. We extend previous work in "inference compilation", which combines universal probabilistic programming and deep learning methods, to large-scale scientific simulators, and introduce a C++ based probabilistic programming library called CPProb. We successfully use CPProb to interface with SHERPA, a large code-base used in particle physics. Here we describe the technical innovations realized and planned for this library.
Learning to Pivot with Adversarial Networks
Jun 01, 2017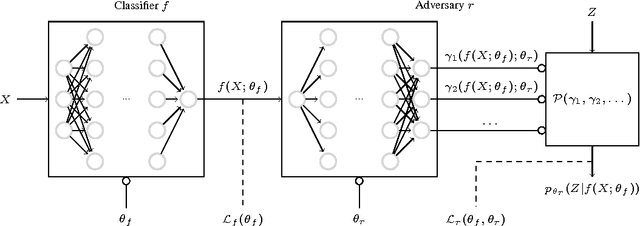
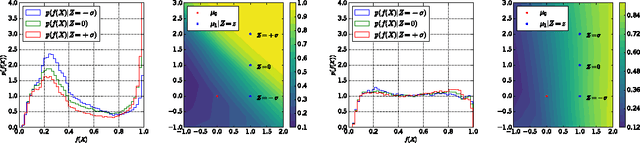
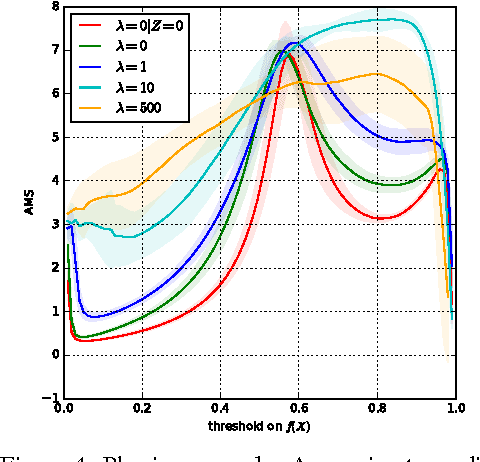
Several techniques for domain adaptation have been proposed to account for differences in the distribution of the data used for training and testing. The majority of this work focuses on a binary domain label. Similar problems occur in a scientific context where there may be a continuous family of plausible data generation processes associated to the presence of systematic uncertainties. Robust inference is possible if it is based on a pivot -- a quantity whose distribution does not depend on the unknown values of the nuisance parameters that parametrize this family of data generation processes. In this work, we introduce and derive theoretical results for a training procedure based on adversarial networks for enforcing the pivotal property (or, equivalently, fairness with respect to continuous attributes) on a predictive model. The method includes a hyperparameter to control the trade-off between accuracy and robustness. We demonstrate the effectiveness of this approach with a toy example and examples from particle physics.
Approximating Likelihood Ratios with Calibrated Discriminative Classifiers
Mar 18, 2016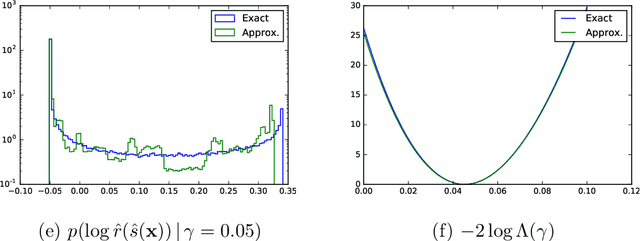
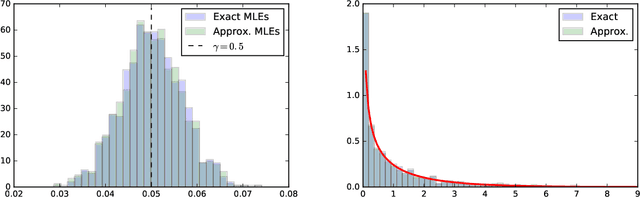
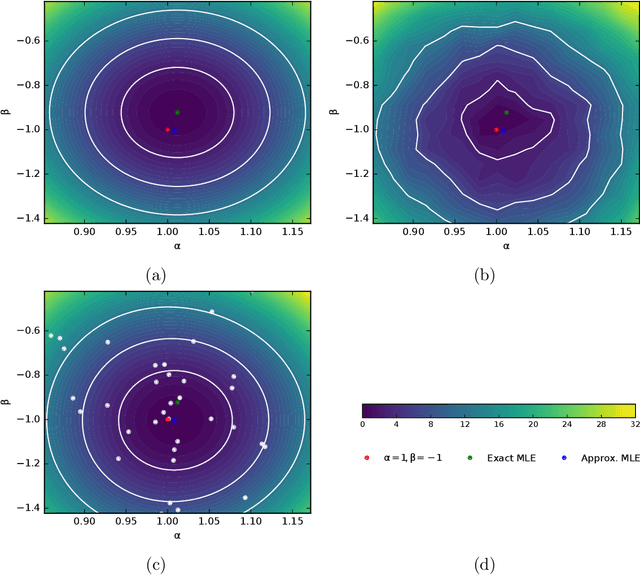
In many fields of science, generalized likelihood ratio tests are established tools for statistical inference. At the same time, it has become increasingly common that a simulator (or generative model) is used to describe complex processes that tie parameters $\theta$ of an underlying theory and measurement apparatus to high-dimensional observations $\mathbf{x}\in \mathbb{R}^p$. However, simulator often do not provide a way to evaluate the likelihood function for a given observation $\mathbf{x}$, which motivates a new class of likelihood-free inference algorithms. In this paper, we show that likelihood ratios are invariant under a specific class of dimensionality reduction maps $\mathbb{R}^p \mapsto \mathbb{R}$. As a direct consequence, we show that discriminative classifiers can be used to approximate the generalized likelihood ratio statistic when only a generative model for the data is available. This leads to a new machine learning-based approach to likelihood-free inference that is complementary to Approximate Bayesian Computation, and which does not require a prior on the model parameters. Experimental results on artificial problems with known exact likelihoods illustrate the potential of the proposed method.
Parameterized Machine Learning for High-Energy Physics
Jan 28, 2016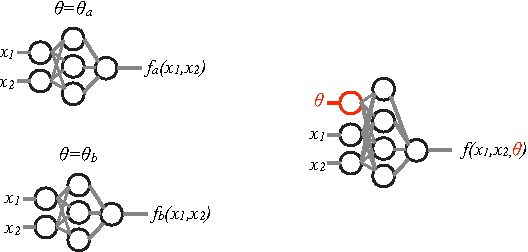
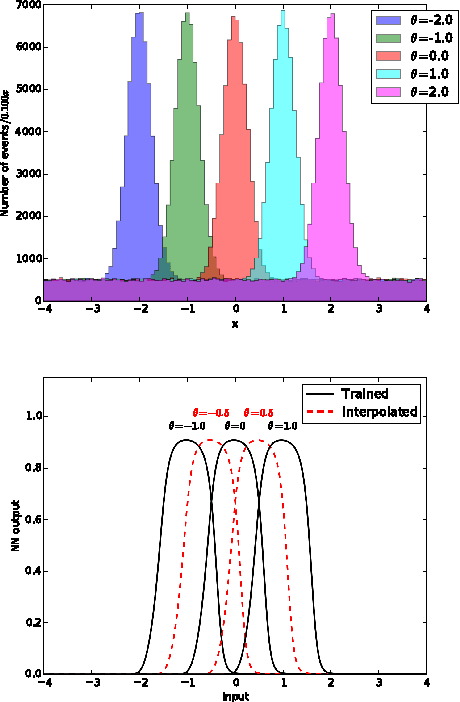
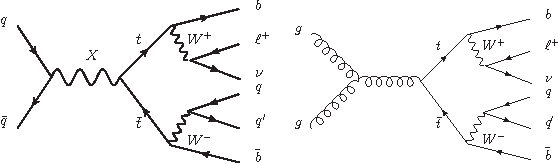
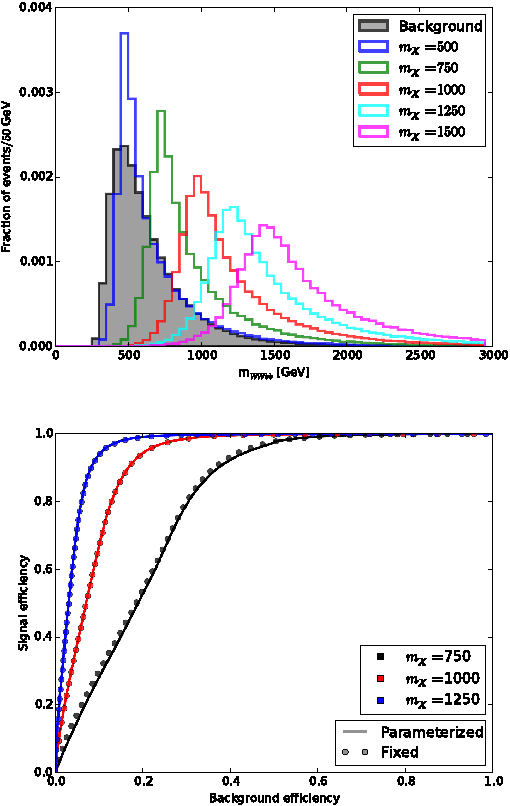
We investigate a new structure for machine learning classifiers applied to problems in high-energy physics by expanding the inputs to include not only measured features but also physics parameters. The physics parameters represent a smoothly varying learning task, and the resulting parameterized classifier can smoothly interpolate between them and replace sets of classifiers trained at individual values. This simplifies the training process and gives improved performance at intermediate values, even for complex problems requiring deep learning. Applications include tools parameterized in terms of theoretical model parameters, such as the mass of a particle, which allow for a single network to provide improved discrimination across a range of masses. This concept is simple to implement and allows for optimized interpolatable results.