 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-guided Bayesian Optimization
Jun 25, 2020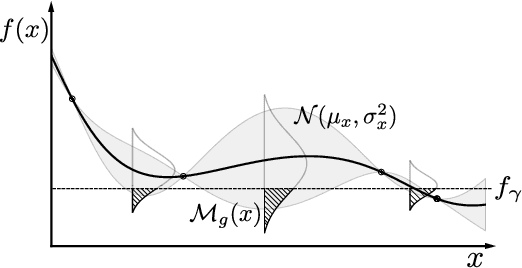
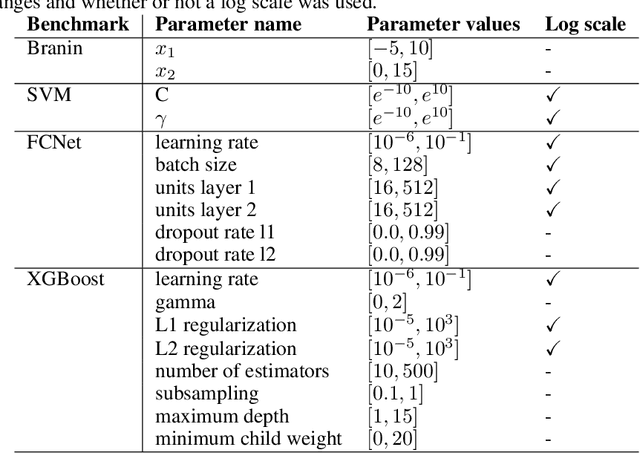
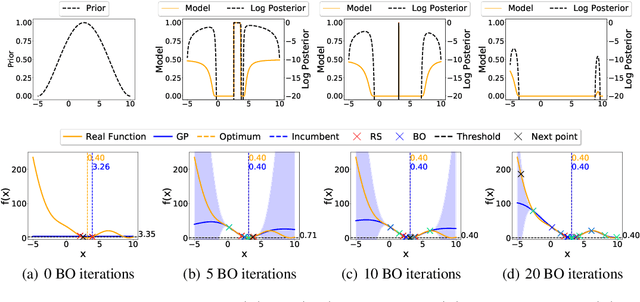
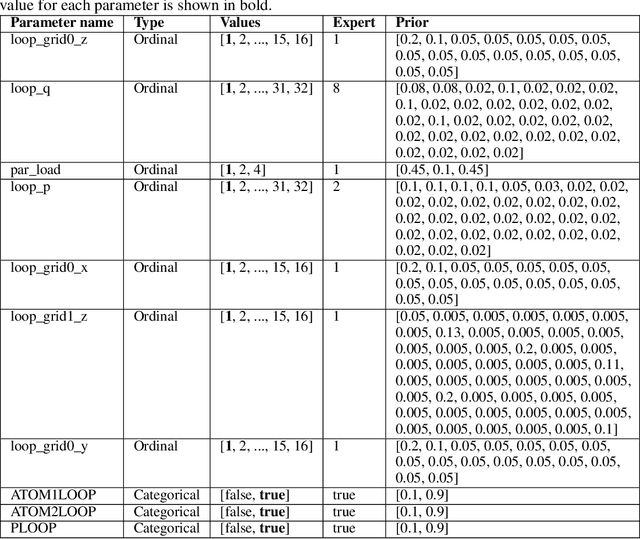
While Bayesian Optimization (BO) is a very popular method for optimizing expensive black-box functions, it fails to leverage the experience of domain experts. This causes BO to waste function evaluations on commonly known bad regions of design choices, e.g., hyperparameters of a machine learning algorithm. To address this issue, we introduce Prior-guided Bayesian Optimization (PrBO). PrBO allows users to inject their knowledge into the optimization process in the form of priors about which parts of the input space will yield the best performance, rather than BO's standard priors over functions which are much less intuitive for users. PrBO then combines these priors with BO's standard probabilistic model to yield a posterior. We show that PrBO is more sample efficient than state-of-the-art methods without user priors and 10,000$\times$ faster than random search, on a common suite of benchmarks and a real-world hardware design application. We also show that PrBO converges faster even if the user priors are not entirely accurate and that it robustly recovers from misleading priors.
Taurus: An Intelligent Data Plane
Feb 12, 2020
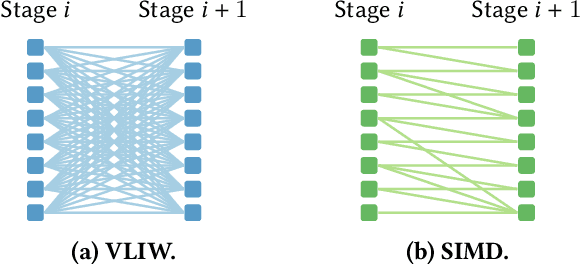
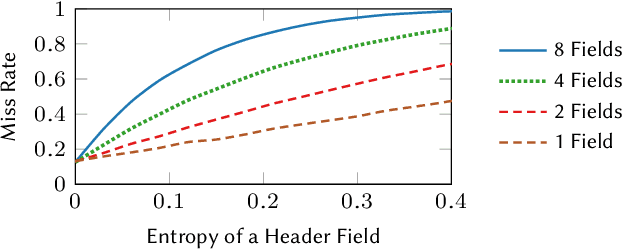
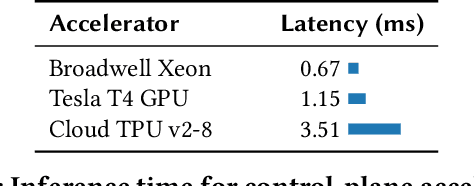
Emerging applications -- cloud computing, the internet of things, and augmented/virtual reality -- need responsive, available, secure, ubiquitous, and scalable datacenter networks. Network management currently uses simple, per-packet, data-plane heuristics (e.g., ECMP and sketches) under an intelligent, millisecond-latency control plane that runs data-driven performance and security policies. However, to meet users' quality-of-service expectations in a modern data center, networks must operate intelligently at line rate. In this paper, we present Taurus, an intelligent data plane capable of machine-learning inference at line rate. Taurus adds custom hardware based on a map-reduce abstraction to programmable network devices, such as switches and NICs; this new hardware uses pipelined and SIMD parallelism for fast inference. Our evaluation of a Taurus-enabled switch ASIC -- supporting several real-world benchmarks -- shows that Taurus operates three orders of magnitude faster than a server-based control plane, while increasing area by 24% and latency, on average, by 178 ns. On the long road to self-driving networks, Taurus is the equivalent of adaptive cruise control: deterministic rules steer flows, while machine learning tunes performance and heightens security.
Serving Recurrent Neural Networks Efficiently with a Spatial Accelerator
Sep 26, 2019
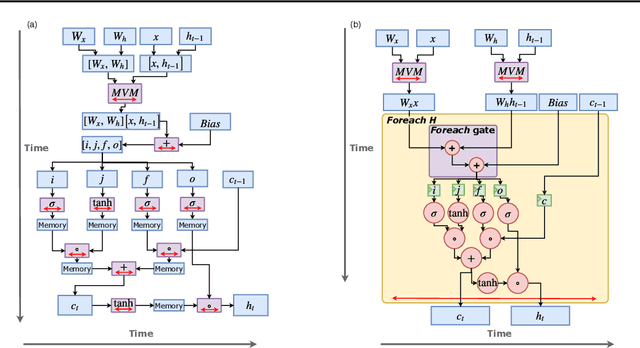

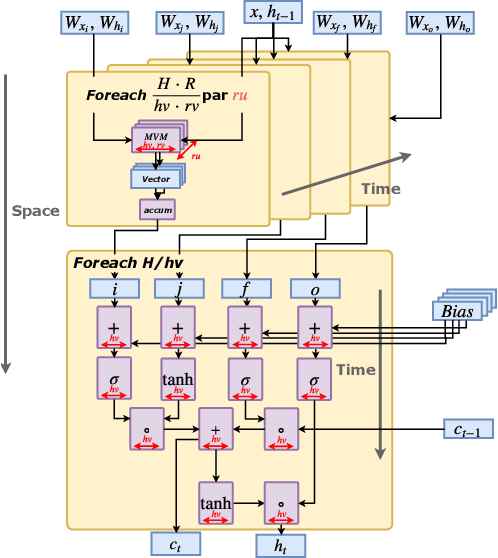
Recurrent Neural Network (RNN) applications form a major class of AI-powered, low-latency data center workloads. Most execution models for RNN acceleration break computation graphs into BLAS kernels, which lead to significant inter-kernel data movement and resource underutilization. We show that by supporting more general loop constructs that capture design parameters in accelerators, it is possible to improve resource utilization using cross-kernel optimization without sacrificing programmability. Such abstraction level enables a design space search that can lead to efficient usage of on-chip resources on a spatial architecture across a range of problem sizes. We evaluate our optimization strategy on such abstraction with DeepBench using a configurable spatial accelerator. We demonstrate that this implementation provides a geometric speedup of 30x in performance, 1.6x in area, and 2x in power efficiency compared to a Tesla V100 GPU, and a geometric speedup of 2x compared to Microsoft Brainwave implementation on a Stratix 10 FPGA.
Polystore++: Accelerated Polystore System for Heterogeneous Workloads
May 24, 2019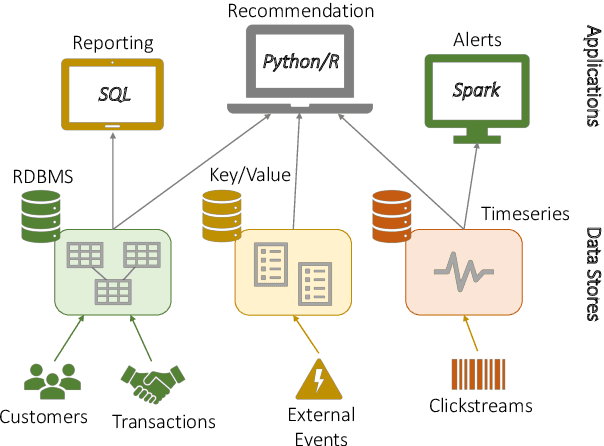
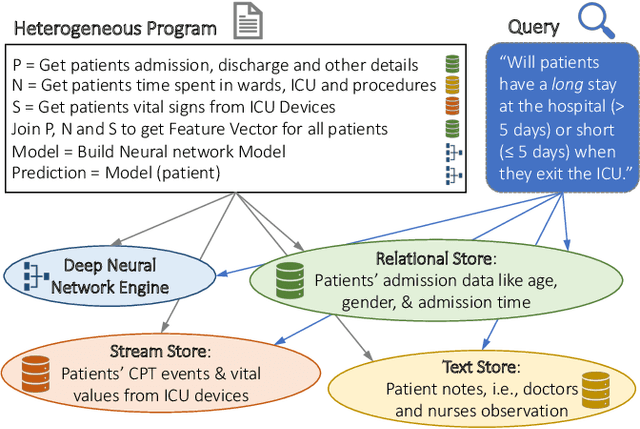
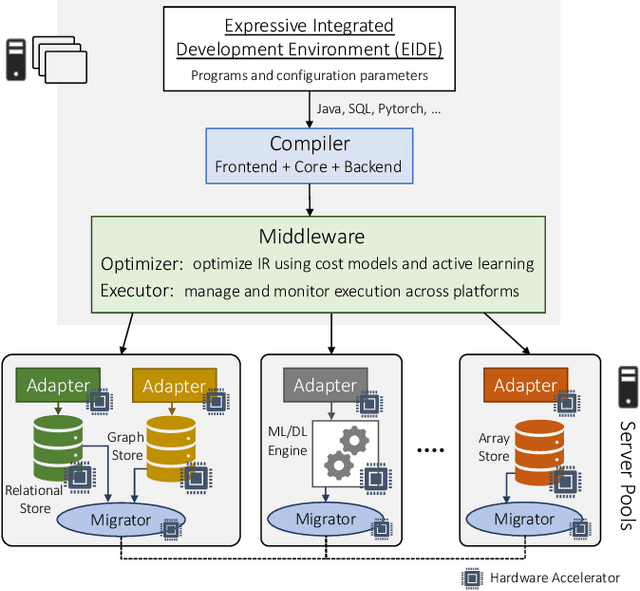
Modern real-time business analytic consist of heterogeneous workloads (e.g, database queries, graph processing, and machine learning). These analytic applications need programming environments that can capture all aspects of the constituent workloads (including data models they work on and movement of data across processing engines). Polystore systems suit such applications; however, these systems currently execute on CPUs and the slowdown of Moore's Law means they cannot meet the performance and efficiency requirements of modern workloads. We envision Polystore++, an architecture to accelerate existing polystore systems using hardware accelerators (e.g, FPGAs, CGRAs, and GPUs). Polystore++ systems can achieve high performance at low power by identifying and offloading components of a polystore system that are amenable to acceleration using specialized hardware. Building a Polystore++ system is challenging and introduces new research problems motivated by the use of hardware accelerators (e.g, optimizing and mapping query plans across heterogeneous computing units and exploiting hardware pipelining and parallelism to improve performance). In this paper, we discuss these challenges in detail and list possible approaches to address these problems.
* 11 pages, Accepted in ICDCS 2019
DeepFreak: Learning Crystallography Diffraction Patterns with Automated Machine Learning
May 03, 2019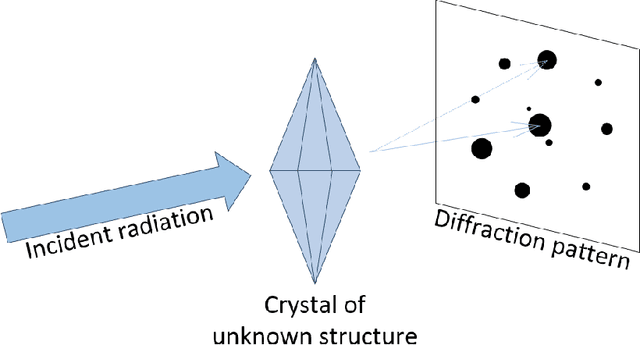

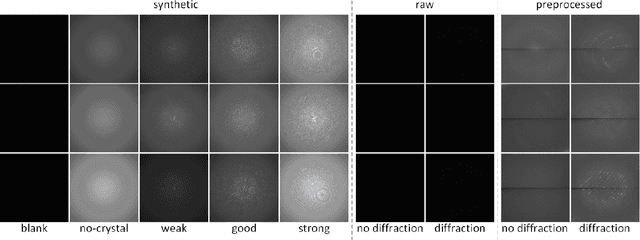
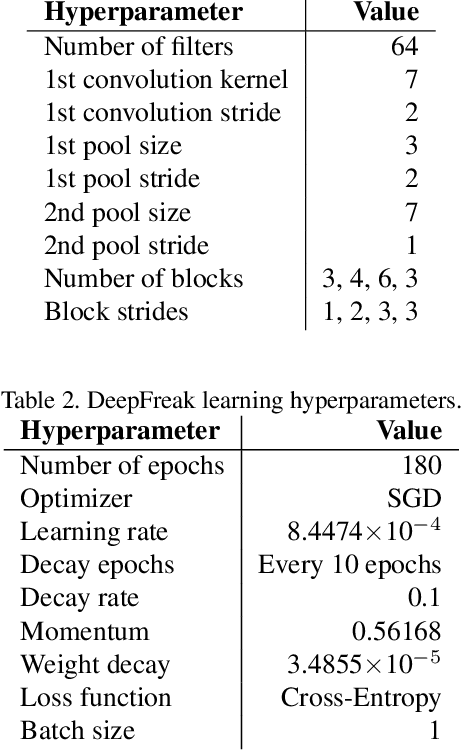
Serial crystallography is the field of science that studies the structure and properties of crystals via diffraction patterns. In this paper, we introduce a new serial crystallography dataset comprised of real and synthetic images; the synthetic images are generated through the use of a simulator that is both scalable and accurate. The resulting dataset is called DiffraNet, and it is composed of 25,457 512x512 grayscale labeled images. We explore several computer vision approaches for classification on DiffraNet such as standard feature extraction algorithms associated with Random Forests and Support Vector Machines but also an end-to-end CNN topology dubbed DeepFreak tailored to work on this new dataset. All implementations are publicly available and have been fine-tuned using off-the-shelf AutoML optimization tools for a fair comparison. Our best model achieves 98.5% accuracy on synthetic images and 94.51% accuracy on real images. We believe that the DiffraNet dataset and its classification methods will have in the long term a positive impact in accelerating discoveries in many disciplines, including chemistry, geology, biology, materials science, metallurgy, and physics.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Practical Design Space Exploration
Oct 11, 2018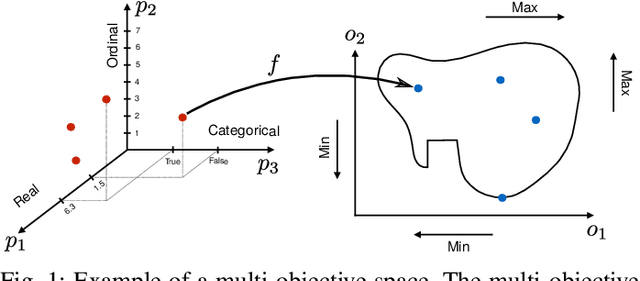
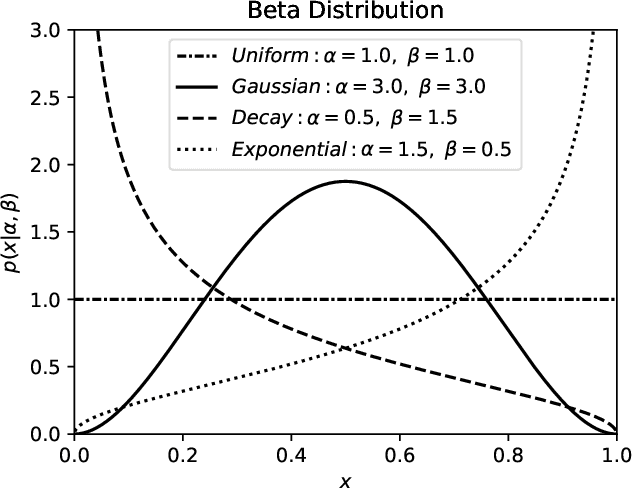
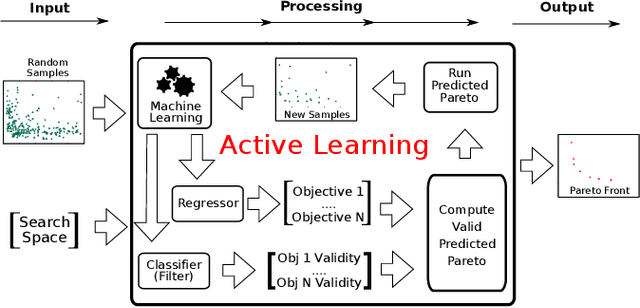
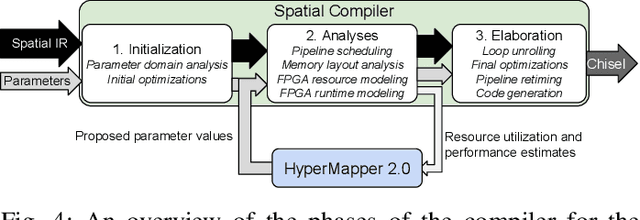
Multi-objective optimization is a crucial matter in computer systems design space exploration because real-world applications often rely on a trade-off between several objectives. Derivatives are usually not available or impractical to compute and the feasibility of an experiment can not always be determined in advance. These problems are particularly difficult when the feasible region is relatively small, and it may be prohibitive to even find a feasible experiment, let alone an optimal one. We introduce a new methodology and corresponding software framework, HyperMapper 2.0, which handles multi-objective optimization, unknown feasibility constraints, and categorical/ordinal variables. This new methodology also supports injection of user prior knowledge in the search when available. All of these features are common requirements in computer systems but rarely exposed in existing design space exploration systems. The proposed methodology follows a white-box model which is simple to understand and interpret (unlike, for example, neural networks) and can be used by the user to better understand the results of the automatic search. We apply and evaluate the new methodology to automatic static tuning of hardware accelerators within the recently introduced Spatial programming language, with minimization of design runtime and compute logic under the constraint of the design fitting in a target field programmable gate array chip. Our results show that HyperMapper 2.0 provides better Pareto fronts compared to state-of-the-art baselines, with better or competitive hypervolume indicator and with 8x improvement in sampling budget for most of the benchmarks explored.
Analysis of DAWNBench, a Time-to-Accuracy Machine Learning Performance Benchmark
Jun 04, 2018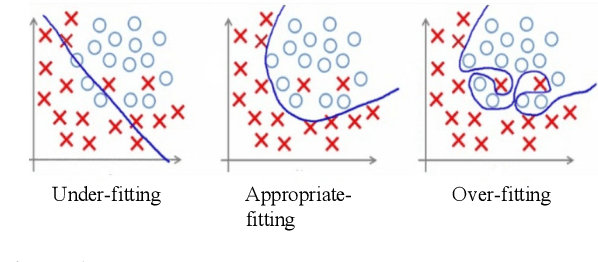

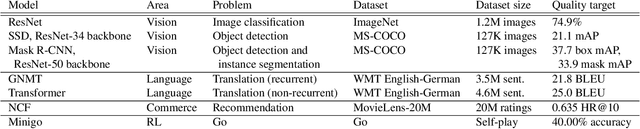

The deep learning community has proposed optimizations spanning hardware, software, and learning theory to improve the computational performance of deep learning workloads. While some of these optimizations perform the same operations faster (e.g., switching from a NVIDIA K80 to P100), many modify the semantics of the training procedure (e.g., large minibatch training, reduced precision), which can impact a model's generalization ability. Due to a lack of standard evaluation criteria that considers these trade-offs, it has become increasingly difficult to compare these different advances. To address this shortcoming, DAWNBENCH and the upcoming MLPERF benchmarks use time-to-accuracy as the primary metric for evaluation, with the accuracy threshold set close to state-of-the-art and measured on a held-out dataset not used in training; the goal is to train to this accuracy threshold as fast as possible. In DAWNBENCH , the winning entries improved time-to-accuracy on ImageNet by two orders of magnitude over the seed entries. Despite this progress, it is unclear how sensitive time-to-accuracy is to the chosen threshold as well as the variance between independent training runs, and how well models optimized for time-to-accuracy generalize. In this paper, we provide evidence to suggest that time-to-accuracy has a low coefficient of variance and that the models tuned for it generalize nearly as well as pre-trained models. We additionally analyze the winning entries to understand the source of these speedups, and give recommendations for future benchmarking efforts.
High-Accuracy Low-Precision Training
Mar 09, 2018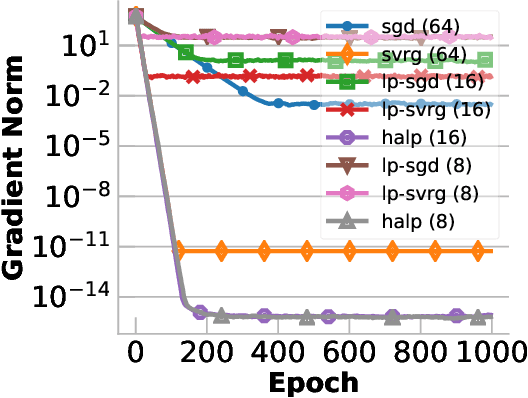
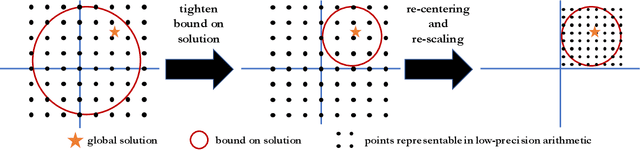
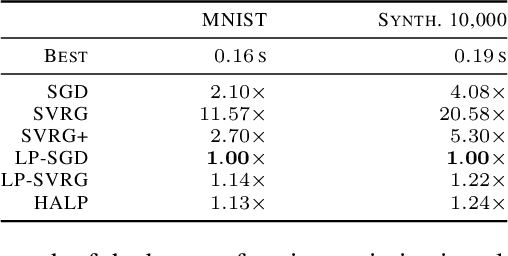
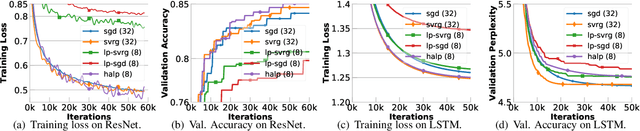
Low-precision computation is often used to lower the time and energy cost of machine learning, and recently hardware accelerators have been developed to support it. Still, it has been used primarily for inference - not training. Previous low-precision training algorithms suffered from a fundamental tradeoff: as the number of bits of precision is lowered, quantization noise is added to the model, which limits statistical accuracy. To address this issue, we describe a simple low-precision stochastic gradient descent variant called HALP. HALP converges at the same theoretical rate as full-precision algorithms despite the noise introduced by using low precision throughout execution. The key idea is to use SVRG to reduce gradient variance, and to combine this with a novel technique called bit centering to reduce quantization error. We show that on the CPU, HALP can run up to $4 \times$ faster than full-precision SVRG and can match its convergence trajectory. We implemented HALP in TensorQuant, and show that it exceeds the validation performance of plain low-precision SGD on two deep learning tasks.
Infrastructure for Usable Machine Learning: The Stanford DAWN Project
Jun 09, 2017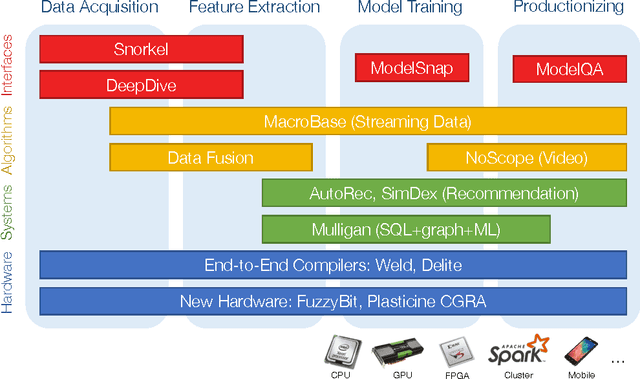
Despite incredible recent advances in machine learning, building machine learning applications remains prohibitively time-consuming and expensive for all but the best-trained, best-funded engineering organizations. This expense comes not from a need for new and improved statistical models but instead from a lack of systems and tools for supporting end-to-end machine learning application development, from data preparation and labeling to productionization and monitoring. In this document, we outline opportunities for infrastructure supporting usable, end-to-end machine learning applications in the context of the nascent DAWN (Data Analytics for What's Next) project at Stanford.