 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Style Augmentation for Domain Generalization
Jan 30, 2023It is well-known that the performance of well-trained deep neural networks may degrade significantly when they are applied to data with even slightly shifted distributions. Recent studies have shown that introducing certain perturbation on feature statistics (\eg, mean and standard deviation) during training can enhance the cross-domain generalization ability. Existing methods typically conduct such perturbation by utilizing the feature statistics within a mini-batch, limiting their representation capability. Inspired by the domain generalization objective, we introduce a novel Adversarial Style Augmentation (ASA) method, which explores broader style spaces by generating more effective statistics perturbation via adversarial training. Specifically, we first search for the most sensitive direction and intensity for statistics perturbation by maximizing the task loss. By updating the model against the adversarial statistics perturbation during training, we allow the model to explore the worst-case domain and hence improve its generalization performance. To facilitate the application of ASA, we design a simple yet effective module, namely AdvStyle, which instantiates the ASA method in a plug-and-play manner. We justify the efficacy of AdvStyle on tasks of cross-domain classification and instance retrieval. It achieves higher mean accuracy and lower performance fluctuation. Especially, our method significantly outperforms its competitors on the PACS dataset under the single source generalization setting, \eg, boosting the classification accuracy from 61.2\% to 67.1\% with a ResNet50 backbone. Our code will be available at \url{https://github.com/YBZh/AdvStyle}.
Generative Scene Synthesis via Incremental View Inpainting using RGBD Diffusion Models
Dec 12, 2022We address the challenge of recovering an underlying scene geometry and colors from a sparse set of RGBD view observations. In this work, we present a new solution that sequentially generates novel RGBD views along a camera trajectory, and the scene geometry is simply the fusion result of these views. More specifically, we maintain an intermediate surface mesh used for rendering new RGBD views, which subsequently becomes complete by an inpainting network; each rendered RGBD view is later back-projected as a partial surface and is supplemented into the intermediate mesh. The use of intermediate mesh and camera projection helps solve the refractory problem of multi-view inconsistency. We practically implement the RGBD inpainting network as a versatile RGBD diffusion model, which is previously used for 2D generative modeling; we make a modification to its reverse diffusion process to enable our use. We evaluate our approach on the task of 3D scene synthesis from sparse RGBD inputs; extensive experiments on the ScanNet dataset demonstrate the superiority of our approach over existing ones. Project page: https://jblei.site/project-pages/rgbd-diffusion.html
Point-DAE: Denoising Autoencoders for Self-supervised Point Cloud Learning
Nov 13, 2022



Masked autoencoder has demonstrated its effectiveness in self-supervised point cloud learning. Considering that masking is a kind of corruption, in this work we explore a more general denoising autoencoder for point cloud learning (Point-DAE) by investigating more types of corruptions beyond masking. Specifically, we degrade the point cloud with certain corruptions as input, and learn an encoder-decoder model to reconstruct the original point cloud from its corrupted version. Three corruption families (i.e., density/masking, noise, and affine transformation) and a total of fourteen corruption types are investigated. Interestingly, the affine transformation-based Point-DAE generally outperforms others (e.g., the popular masking corruptions), suggesting a promising direction for self-supervised point cloud learning. More importantly, we find a statistically significant linear relationship between task relatedness and model performance on downstream tasks. This finding partly demystifies the advantage of affine transformation-based Point-DAE, given that such Point-DAE variants are closely related to the downstream classification task. Additionally, we reveal that most Point-DAE variants unintentionally benefit from the manually-annotated canonical poses in the pre-training dataset. To tackle such an issue, we promote a new dataset setting by estimating object poses automatically. The codes will be available at \url{https://github.com/YBZh/Point-DAE.}
TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition
Oct 20, 2022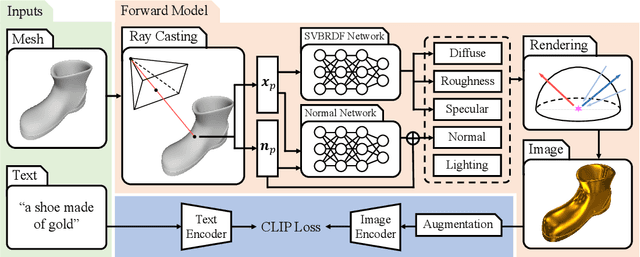



Creation of 3D content by stylization is a promising yet challenging problem in computer vision and graphics research. In this work, we focus on stylizing photorealistic appearance renderings of a given surface mesh of arbitrary topology. Motivated by the recent surge of cross-modal supervision of the Contrastive Language-Image Pre-training (CLIP) model, we propose TANGO, which transfers the appearance style of a given 3D shape according to a text prompt in a photorealistic manner. Technically, we propose to disentangle the appearance style as the spatially varying bidirectional reflectance distribution function, the local geometric variation, and the lighting condition, which are jointly optimized, via supervision of the CLIP loss, by a spherical Gaussians based differentiable renderer. As such, TANGO enables photorealistic 3D style transfer by automatically predicting reflectance effects even for bare, low-quality meshes, without training on a task-specific dataset. Extensive experiments show that TANGO outperforms existing methods of text-driven 3D style transfer in terms of photorealistic quality, consistency of 3D geometry, and robustness when stylizing low-quality meshes. Our codes and results are available at our project webpage https://cyw-3d.github.io/tango/.
DCL-Net: Deep Correspondence Learning Network for 6D Pose Estimation
Oct 11, 2022
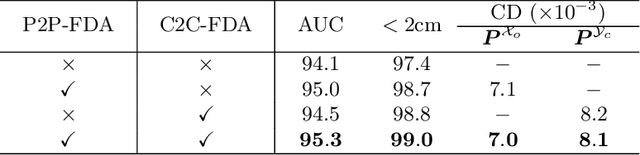
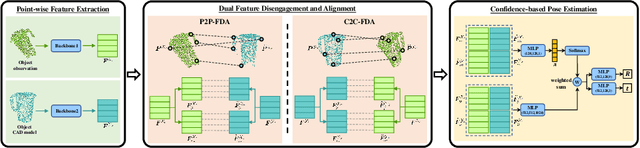

Establishment of point correspondence between camera and object coordinate systems is a promising way to solve 6D object poses. However, surrogate objectives of correspondence learning in 3D space are a step away from the true ones of object pose estimation, making the learning suboptimal for the end task. In this paper, we address this shortcoming by introducing a new method of Deep Correspondence Learning Network for direct 6D object pose estimation, shortened as DCL-Net. Specifically, DCL-Net employs dual newly proposed Feature Disengagement and Alignment (FDA) modules to establish, in the feature space, partial-to-partial correspondence and complete-to-complete one for partial object observation and its complete CAD model, respectively, which result in aggregated pose and match feature pairs from two coordinate systems; these two FDA modules thus bring complementary advantages. The match feature pairs are used to learn confidence scores for measuring the qualities of deep correspondence, while the pose feature pairs are weighted by confidence scores for direct object pose regression. A confidence-based pose refinement network is also proposed to further improve pose precision in an iterative manner. Extensive experiments show that DCL-Net outperforms existing methods on three benchmarking datasets, including YCB-Video, LineMOD, and Oclussion-LineMOD; ablation studies also confirm the efficacy of our novel designs.
Counterfactual Supervision-based Information Bottleneck for Out-of-Distribution Generalization
Aug 16, 2022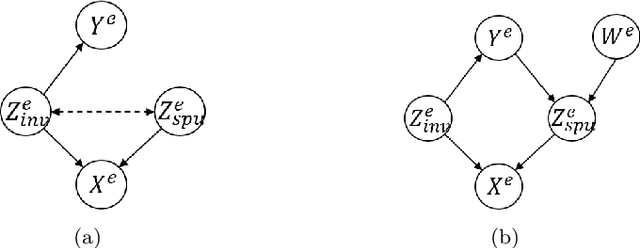

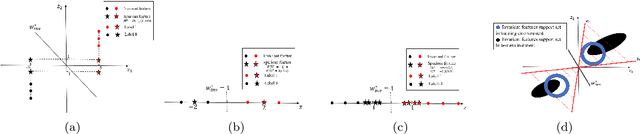
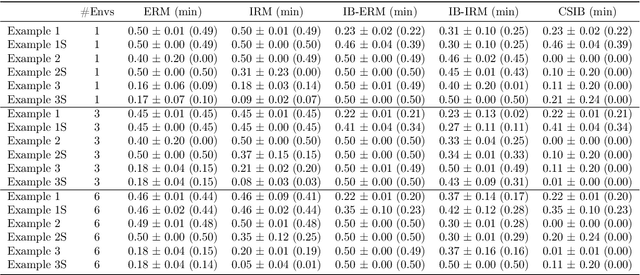
Learning invariant (causal) features for out-of-distribution (OOD) generalization has attracted extensive attention recently, and among the proposals invariant risk minimization (IRM) (Arjovsky et al., 2019) is a notable solution. In spite of its theoretical promise for linear regression, the challenges of using IRM in linear classification problems yet remain (Rosenfeld et al.,2020, Nagarajan et al., 2021). Along this line, a recent study (Arjovsky et al., 2019) has made a first step and proposes a learning principle of information bottleneck based invariant risk minimization (IB-IRM). In this paper, we first show that the key assumption of support overlap of invariant features used in (Arjovsky et al., 2019) is rather strong for the guarantee of OOD generalization and it is still possible to achieve the optimal solution without such assumption. To further answer the question of whether IB-IRM is sufficient for learning invariant features in linear classification problems, we show that IB-IRM would still fail in two cases whether or not the invariant features capture all information about the label. To address such failures, we propose a \textit{Counterfactual Supervision-based Information Bottleneck (CSIB)} learning algorithm that provably recovers the invariant features. The proposed algorithm works even when accessing data from a single environment, and has theoretically consistent results for both binary and multi-class problems. We present empirical experiments on three synthetic datasets that verify the efficacy of our proposed method.
Convolutional Fine-Grained Classification with Self-Supervised Target Relation Regularization
Aug 03, 2022



Fine-grained visual classification can be addressed by deep representation learning under supervision of manually pre-defined targets (e.g., one-hot or the Hadamard codes). Such target coding schemes are less flexible to model inter-class correlation and are sensitive to sparse and imbalanced data distribution as well. In light of this, this paper introduces a novel target coding scheme -- dynamic target relation graphs (DTRG), which, as an auxiliary feature regularization, is a self-generated structural output to be mapped from input images. Specifically, online computation of class-level feature centers is designed to generate cross-category distance in the representation space, which can thus be depicted by a dynamic graph in a non-parametric manner. Explicitly minimizing intra-class feature variations anchored on those class-level centers can encourage learning of discriminative features. Moreover, owing to exploiting inter-class dependency, the proposed target graphs can alleviate data sparsity and imbalanceness in representation learning. Inspired by recent success of the mixup style data augmentation, this paper introduces randomness into soft construction of dynamic target relation graphs to further explore relation diversity of target classes. Experimental results can demonstrate the effectiveness of our method on a number of diverse benchmarks of multiple visual classification tasks, especially achieving the state-of-the-art performance on popular fine-grained object benchmarks and superior robustness against sparse and imbalanced data. Source codes are made publicly available at https://github.com/AkonLau/DTRG.
Category-Level 6D Object Pose and Size Estimation using Self-Supervised Deep Prior Deformation Networks
Jul 12, 2022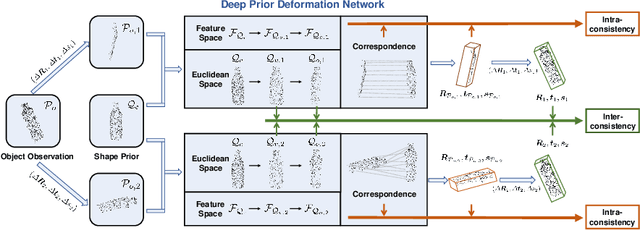
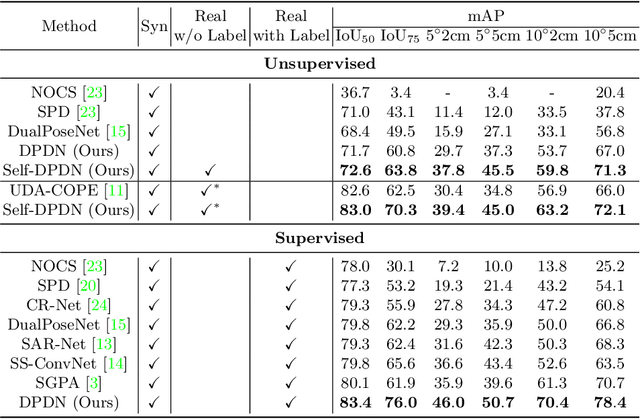
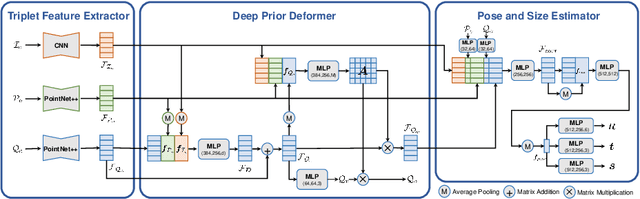
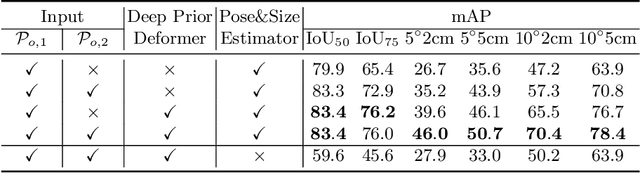
It is difficult to precisely annotate object instances and their semantics in 3D space, and as such, synthetic data are extensively used for these tasks, e.g., category-level 6D object pose and size estimation. However, the easy annotations in synthetic domains bring the downside effect of synthetic-to-real (Sim2Real) domain gap. In this work, we aim to address this issue in the task setting of Sim2Real, unsupervised domain adaptation for category-level 6D object pose and size estimation. We propose a method that is built upon a novel Deep Prior Deformation Network, shortened as DPDN. DPDN learns to deform features of categorical shape priors to match those of object observations, and is thus able to establish deep correspondence in the feature space for direct regression of object poses and sizes. To reduce the Sim2Real domain gap, we formulate a novel self-supervised objective upon DPDN via consistency learning; more specifically, we apply two rigid transformations to each object observation in parallel, and feed them into DPDN respectively to yield dual sets of predictions; on top of the parallel learning, an inter-consistency term is employed to keep cross consistency between dual predictions for improving the sensitivity of DPDN to pose changes, while individual intra-consistency ones are used to enforce self-adaptation within each learning itself. We train DPDN on both training sets of the synthetic CAMERA25 and real-world REAL275 datasets; our results outperform the existing methods on REAL275 test set under both the unsupervised and supervised settings. Ablation studies also verify the efficacy of our designs. Our code is released publicly at https://github.com/JiehongLin/Self-DPDN.
Style Interleaved Learning for Generalizable Person Re-identification
Jul 07, 2022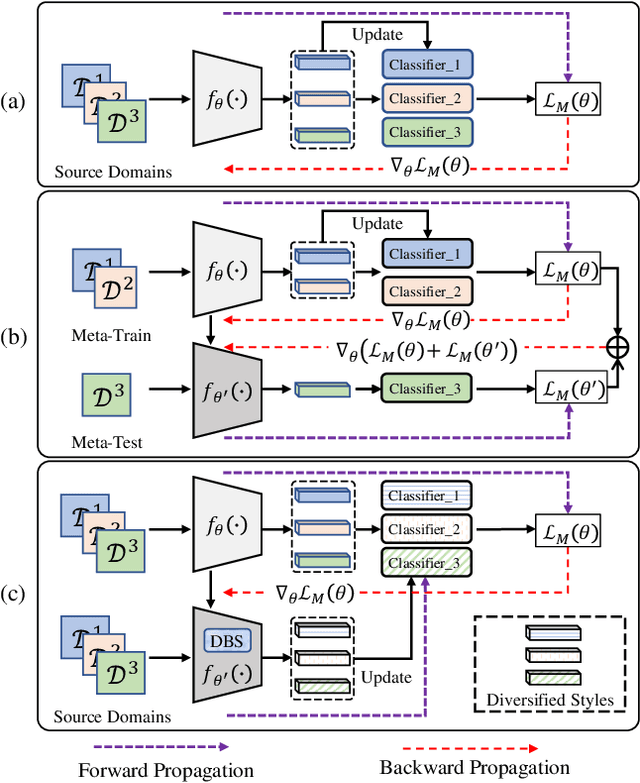
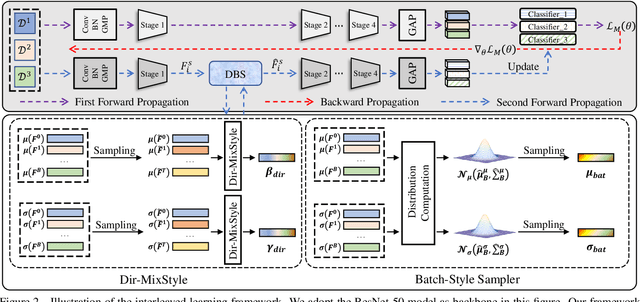
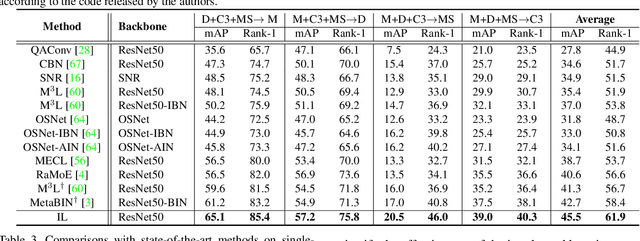
Domain generalization (DG) for person re-identification (ReID) is a challenging problem, as there is no access to target domain data permitted during the training process. Most existing DG ReID methods employ the same features for the updating of the feature extractor and classifier parameters. This common practice causes the model to overfit to existing feature styles in the source domain, resulting in sub-optimal generalization ability on target domains even if meta-learning is used. To solve this problem, we propose a novel style interleaved learning framework. Unlike conventional learning strategies, interleaved learning incorporates two forward propagations and one backward propagation for each iteration. We employ the features of interleaved styles to update the feature extractor and classifiers using different forward propagations, which helps the model avoid overfitting to certain domain styles. In order to fully explore the advantages of style interleaved learning, we further propose a novel feature stylization approach to diversify feature styles. This approach not only mixes the feature styles of multiple training samples, but also samples new and meaningful feature styles from batch-level style distribution. Extensive experimental results show that our model consistently outperforms state-of-the-art methods on large-scale benchmarks for DG ReID, yielding clear advantages in computational efficiency. Code is available at https://github.com/WentaoTan/Interleaved-Learning.
Masked Surfel Prediction for Self-Supervised Point Cloud Learning
Jul 07, 2022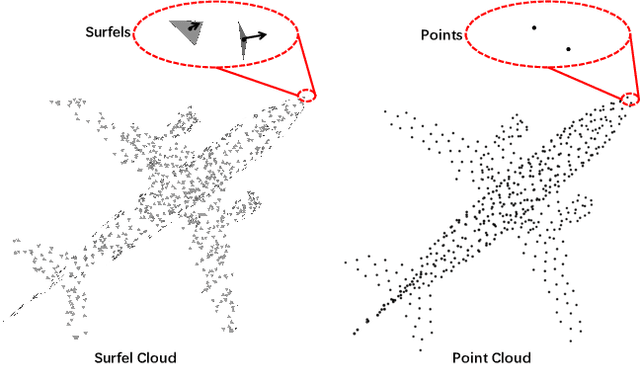
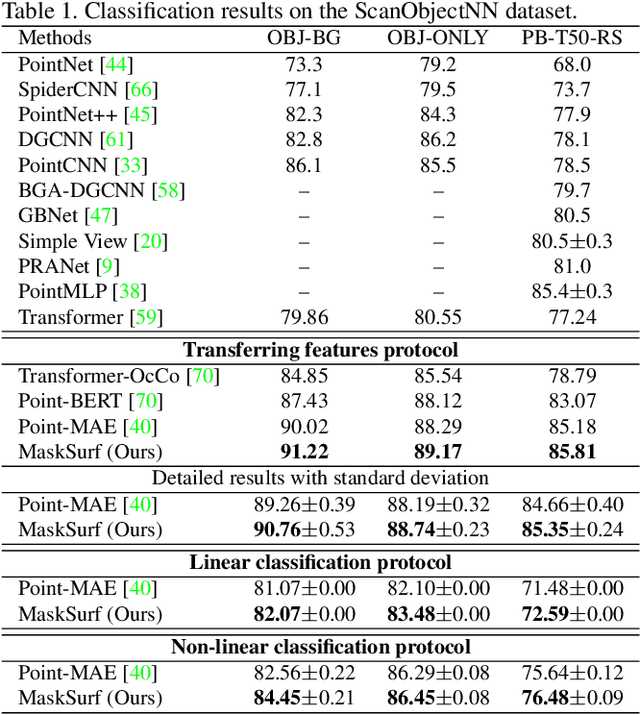

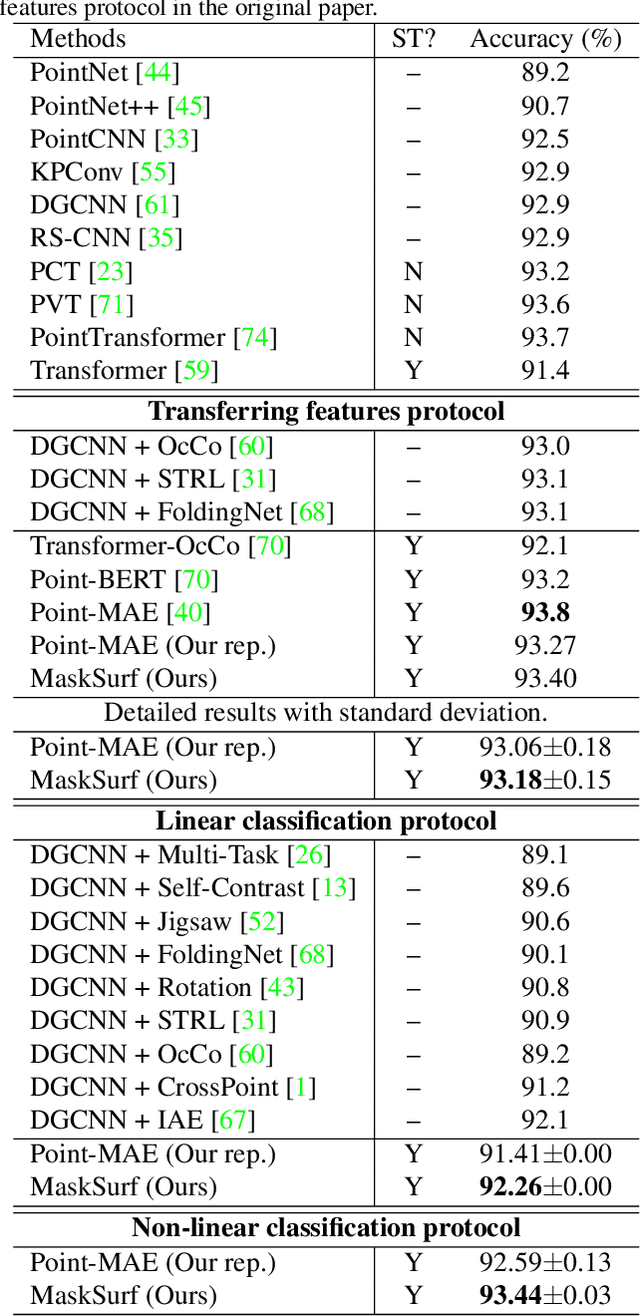
Masked auto-encoding is a popular and effective self-supervised learning approach to point cloud learning. However, most of the existing methods reconstruct only the masked points and overlook the local geometry information, which is also important to understand the point cloud data. In this work, we make the first attempt, to the best of our knowledge, to consider the local geometry information explicitly into the masked auto-encoding, and propose a novel Masked Surfel Prediction (MaskSurf) method. Specifically, given the input point cloud masked at a high ratio, we learn a transformer-based encoder-decoder network to estimate the underlying masked surfels by simultaneously predicting the surfel positions (i.e., points) and per-surfel orientations (i.e., normals). The predictions of points and normals are supervised by the Chamfer Distance and a newly introduced Position-Indexed Normal Distance in a set-to-set manner. Our MaskSurf is validated on six downstream tasks under three fine-tuning strategies. In particular, MaskSurf outperforms its closest competitor, Point-MAE, by 1.2\% on the real-world dataset of ScanObjectNN under the OBJ-BG setting, justifying the advantages of masked surfel prediction over masked point cloud reconstruction. Codes will be available at https://github.com/YBZh/MaskSurf.