 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
Feb 24, 2023



Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN-Wiki by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with the largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pretrained models yield different strengths: while PaLI-based models obtain higher overall performance, CLIP-based models are better at recognizing tail entities.
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
Oct 07, 2022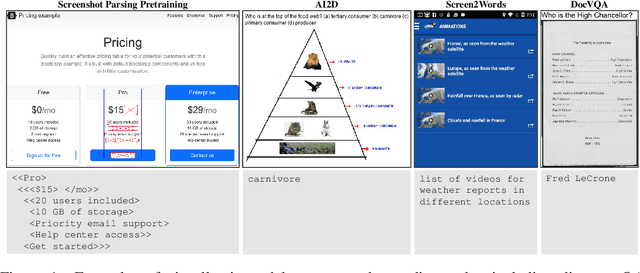


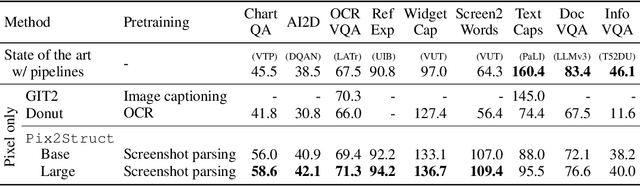
Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
Evaluating the Impact of Model Scale for Compositional Generalization in Semantic Parsing
May 24, 2022
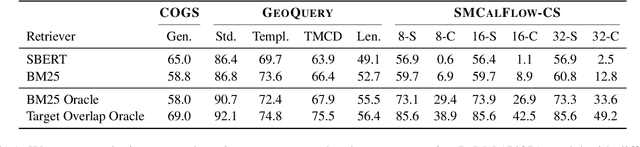
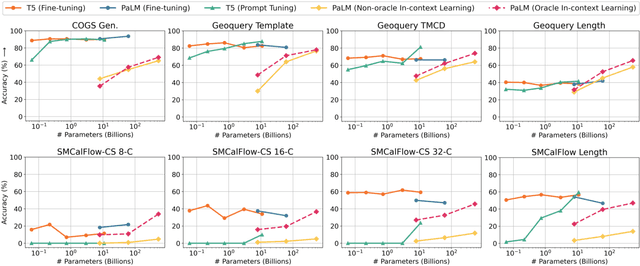
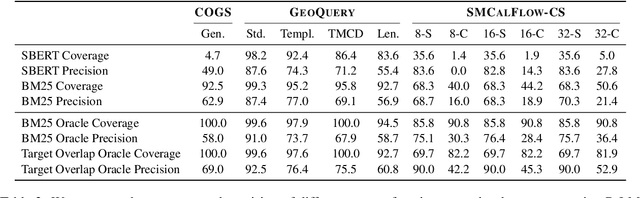
Despite their strong performance on many tasks, pre-trained language models have been shown to struggle on out-of-distribution compositional generalization. Meanwhile, recent work has shown considerable improvements on many NLP tasks from model scaling. Can scaling up model size also improve compositional generalization in semantic parsing? We evaluate encoder-decoder models up to 11B parameters and decoder-only models up to 540B parameters, and compare model scaling curves for three different methods for transfer learning: fine-tuning all parameters, prompt tuning, and in-context learning. We observe that fine-tuning generally has flat or negative scaling curves on out-of-distribution compositional generalization in semantic parsing evaluations. In-context learning has positive scaling curves, but is generally outperformed by much smaller fine-tuned models. Prompt-tuning can outperform fine-tuning, suggesting further potential improvements from scaling as it exhibits a more positive scaling curve. Additionally, we identify several error trends that vary with model scale. For example, larger models are generally better at modeling the syntax of the output space, but are also more prone to certain types of overfitting. Overall, our study highlights limitations of current techniques for effectively leveraging model scale for compositional generalization, while our analysis also suggests promising directions for future work.
Generating recommendations for entity-oriented exploratory search
Apr 02, 2022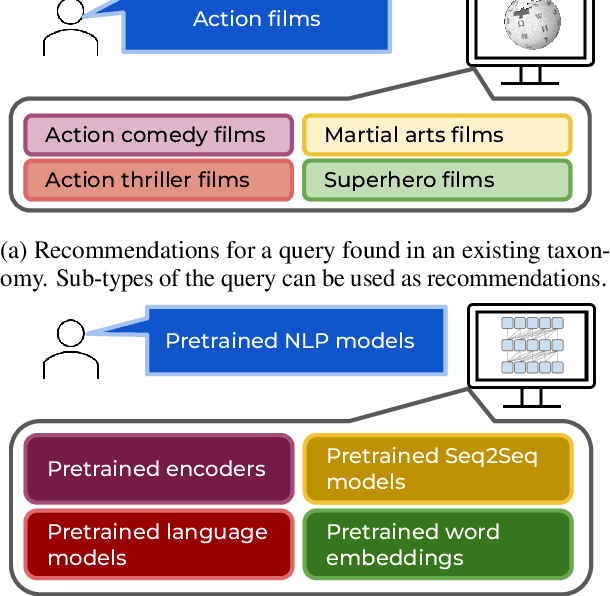
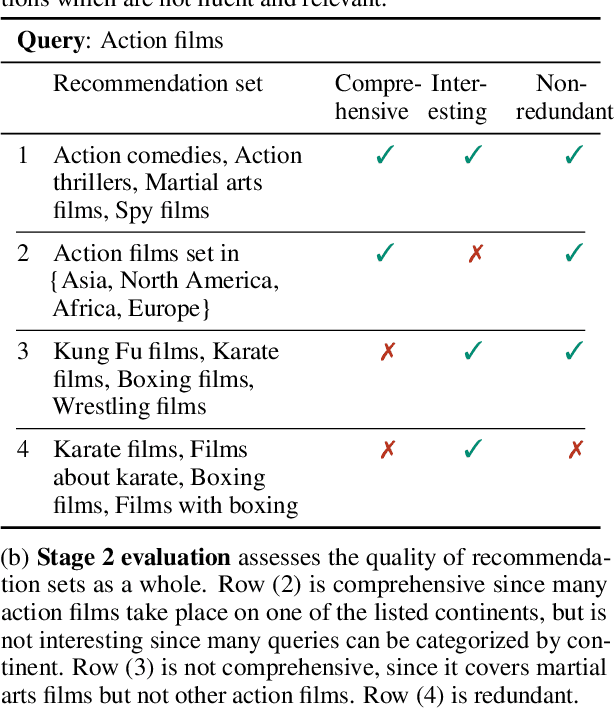
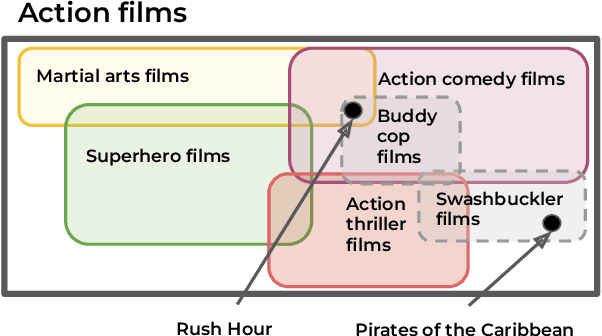

We introduce the task of recommendation set generation for entity-oriented exploratory search. Given an input search query which is open-ended or under-specified, the task is to present the user with an easily-understandable collection of query recommendations, with the goal of facilitating domain exploration or clarifying user intent. Traditional query recommendation systems select recommendations by identifying salient keywords in retrieved documents, or by querying an existing taxonomy or knowledge base for related concepts. In this work, we build a text-to-text model capable of generating a collection of recommendations directly, using the language model as a "soft" knowledge base capable of proposing new concepts not found in an existing taxonomy or set of retrieved documents. We train the model to generate recommendation sets which optimize a cost function designed to encourage comprehensiveness, interestingness, and non-redundancy. In thorough evaluations performed by crowd workers, we confirm the generalizability of our approach and the high quality of the generated recommendations.
Improving Compositional Generalization with Latent Structure and Data Augmentation
Dec 14, 2021
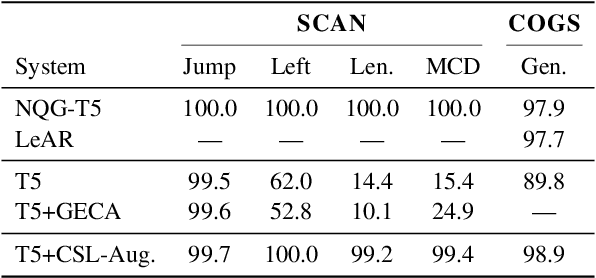
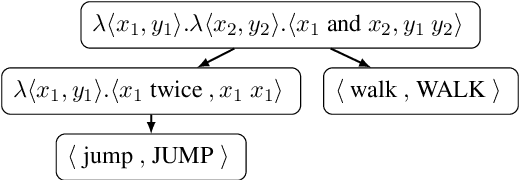
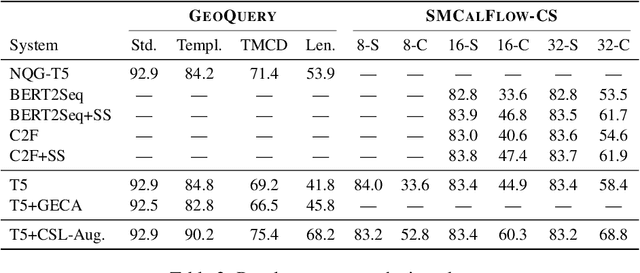
Generic unstructured neural networks have been shown to struggle on out-of-distribution compositional generalization. Compositional data augmentation via example recombination has transferred some prior knowledge about compositionality to such black-box neural models for several semantic parsing tasks, but this often required task-specific engineering or provided limited gains. We present a more powerful data recombination method using a model called Compositional Structure Learner (CSL). CSL is a generative model with a quasi-synchronous context-free grammar backbone, which we induce from the training data. We sample recombined examples from CSL and add them to the fine-tuning data of a pre-trained sequence-to-sequence model (T5). This procedure effectively transfers most of CSL's compositional bias to T5 for diagnostic tasks, and results in a model even stronger than a T5-CSL ensemble on two real world compositional generalization tasks. This results in new state-of-the-art performance for these challenging semantic parsing tasks requiring generalization to both natural language variation and novel compositions of elements.
Revisiting the Primacy of English in Zero-shot Cross-lingual Transfer
Jun 30, 2021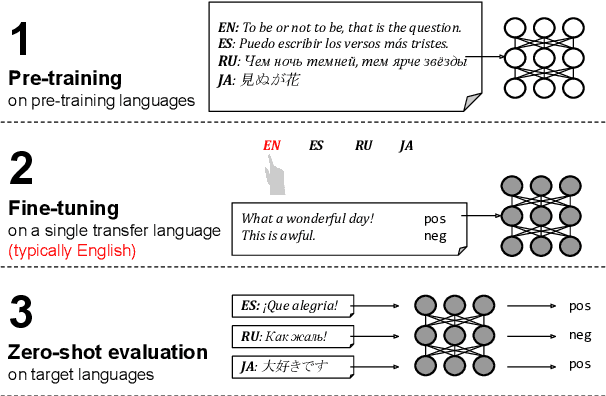
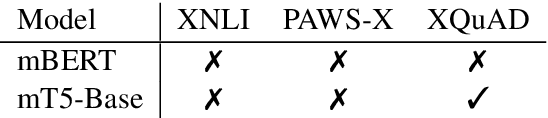
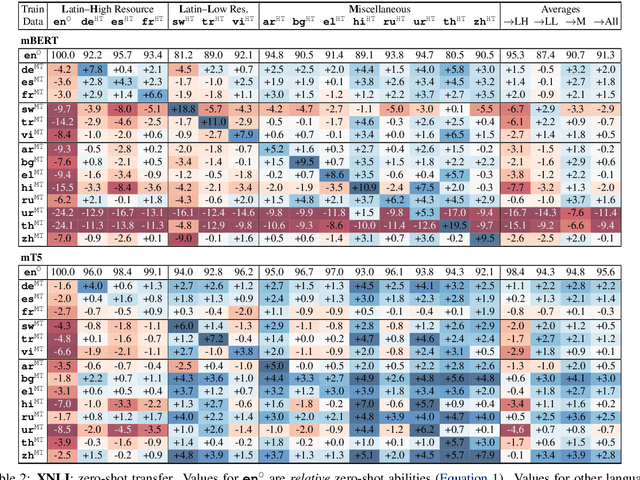
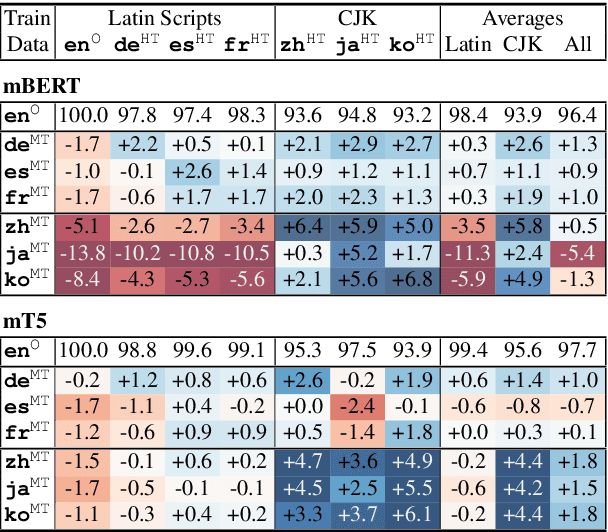
Despite their success, large pre-trained multilingual models have not completely alleviated the need for labeled data, which is cumbersome to collect for all target languages. Zero-shot cross-lingual transfer is emerging as a practical solution: pre-trained models later fine-tuned on one transfer language exhibit surprising performance when tested on many target languages. English is the dominant source language for transfer, as reinforced by popular zero-shot benchmarks. However, this default choice has not been systematically vetted. In our study, we compare English against other transfer languages for fine-tuning, on two pre-trained multilingual models (mBERT and mT5) and multiple classification and question answering tasks. We find that other high-resource languages such as German and Russian often transfer more effectively, especially when the set of target languages is diverse or unknown a priori. Unexpectedly, this can be true even when the training sets were automatically translated from English. This finding can have immediate impact on multilingual zero-shot systems, and should inform future benchmark designs.
Joint Passage Ranking for Diverse Multi-Answer Retrieval
Apr 17, 2021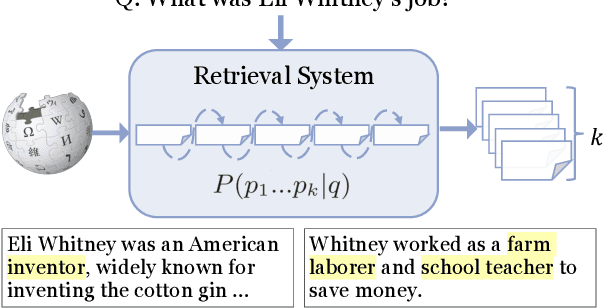

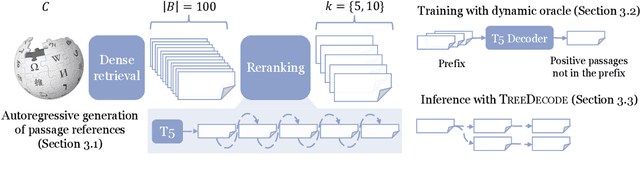
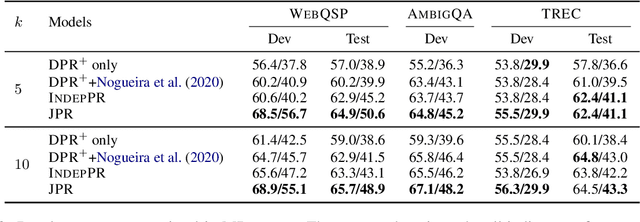
We study multi-answer retrieval, an under-explored problem that requires retrieving passages to cover multiple distinct answers for a given question. This task requires joint modeling of retrieved passages, as models should not repeatedly retrieve passages containing the same answer at the cost of missing a different valid answer. Prior work focusing on single-answer retrieval is limited as it cannot reason about the set of passages jointly. In this paper, we introduce JPR, a joint passage retrieval model focusing on reranking. To model the joint probability of the retrieved passages, JPR makes use of an autoregressive reranker that selects a sequence of passages, equipped with novel training and decoding algorithms. Compared to prior approaches, JPR achieves significantly better answer coverage on three multi-answer datasets. When combined with downstream question answering, the improved retrieval enables larger answer generation models since they need to consider fewer passages, establishing a new state-of-the-art.
Representations for Question Answering from Documents with Tables and Text
Jan 26, 2021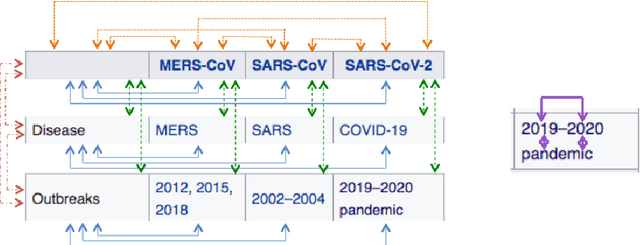
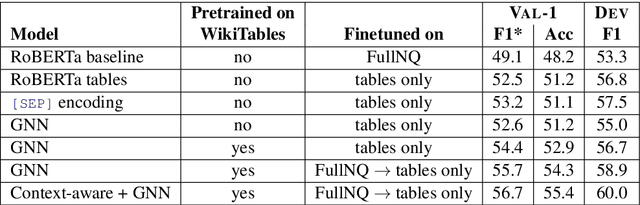
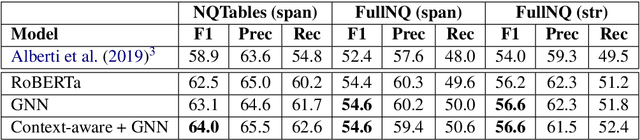
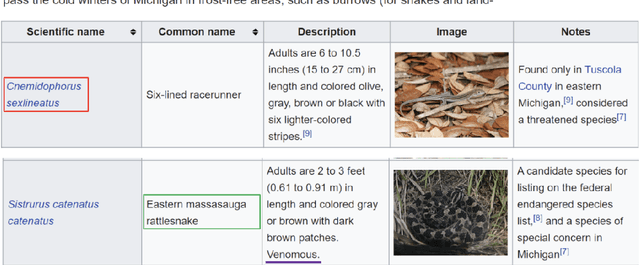
Tables in Web documents are pervasive and can be directly used to answer many of the queries searched on the Web, motivating their integration in question answering. Very often information presented in tables is succinct and hard to interpret with standard language representations. On the other hand, tables often appear within textual context, such as an article describing the table. Using the information from an article as additional context can potentially enrich table representations. In this work we aim to improve question answering from tables by refining table representations based on information from surrounding text. We also present an effective method to combine text and table-based predictions for question answering from full documents, obtaining significant improvements on the Natural Questions dataset.
Compositional Generalization and Natural Language Variation: Can a Semantic Parsing Approach Handle Both?
Oct 24, 2020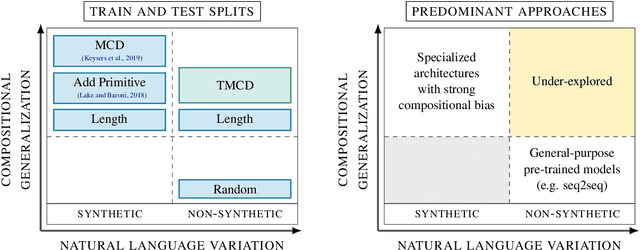

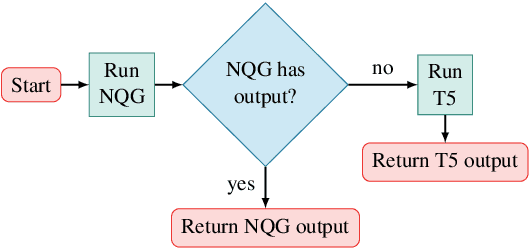
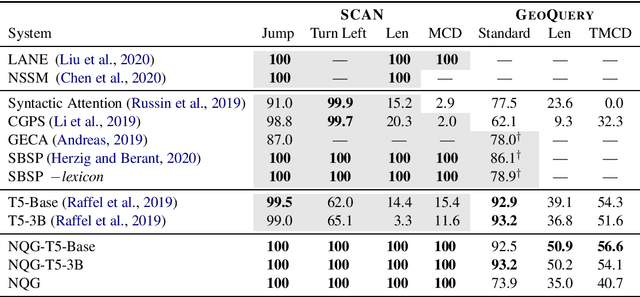
Sequence-to-sequence models excel at handling natural language variation, but have been shown to struggle with out-of-distribution compositional generalization. This has motivated new specialized architectures with stronger compositional biases, but most of these approaches have only been evaluated on synthetically-generated datasets, which are not representative of natural language variation. In this work we ask: can we develop a semantic parsing approach that handles both natural language variation and compositional generalization? To better assess this capability, we propose new train and test splits of non-synthetic datasets. We demonstrate that strong existing semantic parsing approaches do not yet perform well across a broad set of evaluations. We also propose NQG-T5, a hybrid model that combines a high-precision grammar-based approach with a pre-trained sequence-to-sequence model. It outperforms existing approaches across several compositional generalization challenges, while also being competitive with the state-of-the-art on standard evaluations. While still far from solving this problem, our study highlights the importance of diverse evaluations and the open challenge of handling both compositional generalization and natural language variation in semantic parsing.
Probabilistic Assumptions Matter: Improved Models for Distantly-Supervised Document-Level Question Answering
May 05, 2020
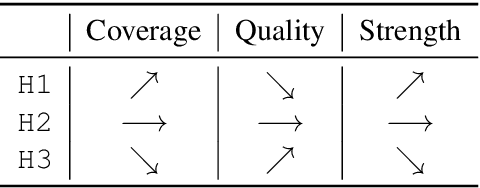
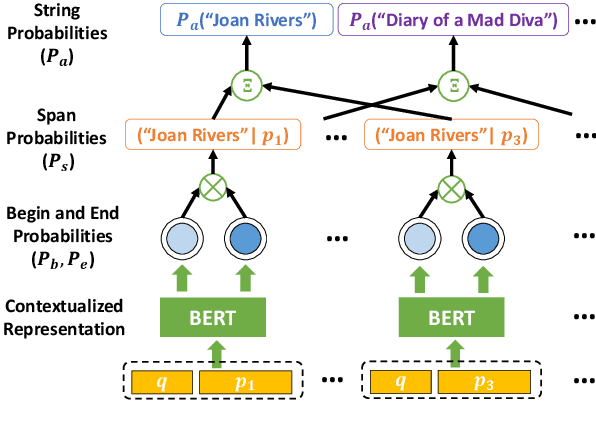
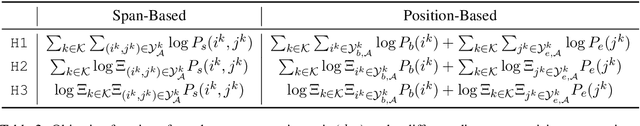
We address the problem of extractive question answering using document-level distant super-vision, pairing questions and relevant documents with answer strings. We compare previously used probability space and distant super-vision assumptions (assumptions on the correspondence between the weak answer string labels and possible answer mention spans). We show that these assumptions interact, and that different configurations provide complementary benefits. We demonstrate that a multi-objective model can efficiently combine the advantages of multiple assumptions and out-perform the best individual formulation. Our approach outperforms previous state-of-the-art models by 4.3 points in F1 on TriviaQA-Wiki and 1.7 points in Rouge-L on NarrativeQA summaries.