 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Boosted Feature Selection
Jan 13, 2019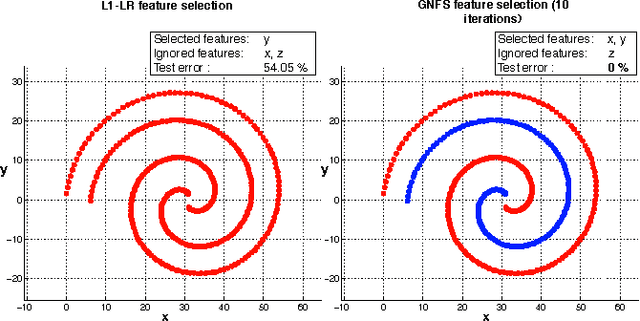

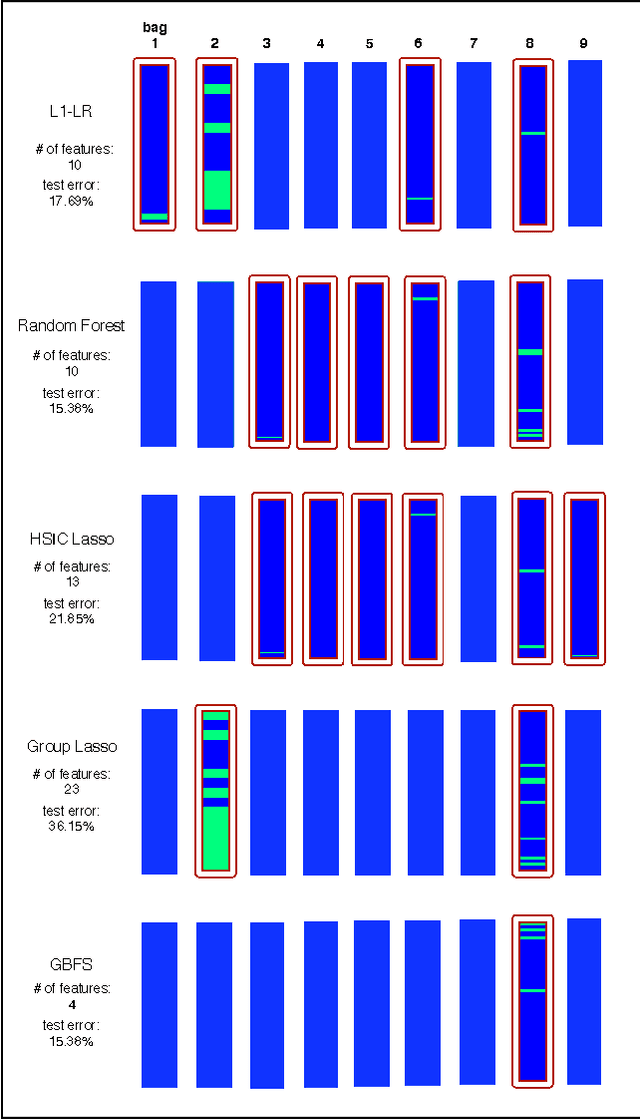
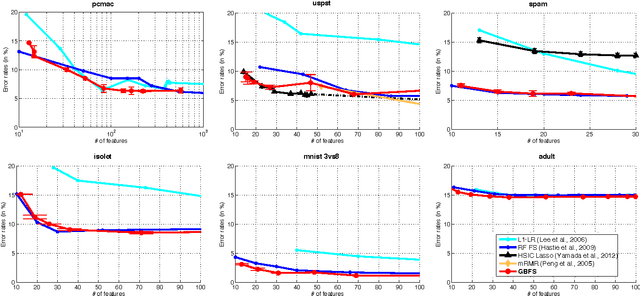
A feature selection algorithm should ideally satisfy four conditions: reliably extract relevant features; be able to identify non-linear feature interactions; scale linearly with the number of features and dimensions; allow the incorporation of known sparsity structure. In this work we propose a novel feature selection algorithm, Gradient Boosted Feature Selection (GBFS), which satisfies all four of these requirements. The algorithm is flexible, scalable, and surprisingly straight-forward to implement as it is based on a modification of Gradient Boosted Trees. We evaluate GBFS on several real world data sets and show that it matches or out-performs other state of the art feature selection algorithms. Yet it scales to larger data set sizes and naturally allows for domain-specific side information.
GPyTorch: Blackbox Matrix-Matrix Gaussian Process Inference with GPU Acceleration
Oct 29, 2018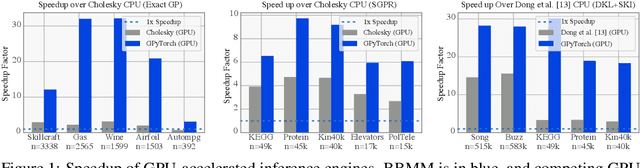
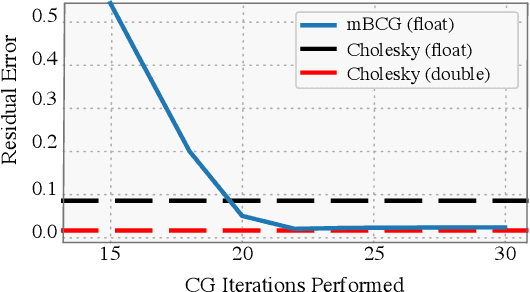
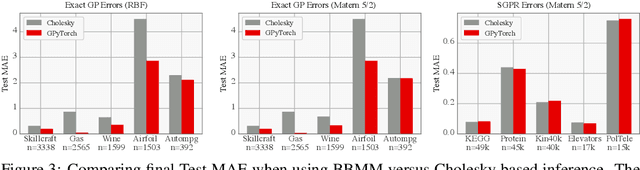
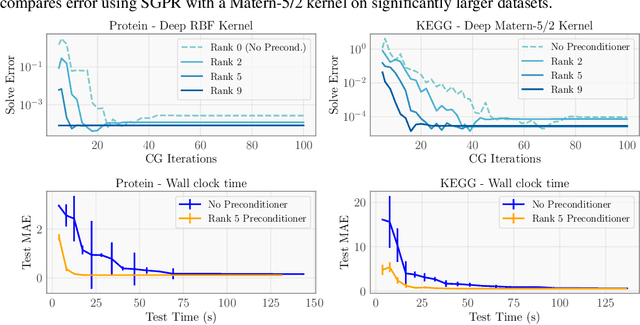
Despite advances in scalable models, the inference tools used for Gaussian processes (GPs) have yet to fully capitalize on developments in computing hardware. We present an efficient and general approach to GP inference based on Blackbox Matrix-Matrix multiplication (BBMM). BBMM inference uses a modified batched version of the conjugate gradients algorithm to derive all terms for training and inference in a single call. BBMM reduces the asymptotic complexity of exact GP inference from $O(n^3)$ to $O(n^2)$. Adapting this algorithm to scalable approximations and complex GP models simply requires a routine for efficient matrix-matrix multiplication with the kernel and its derivative. In addition, BBMM uses a specialized preconditioner to substantially speed up convergence. In experiments we show that BBMM effectively uses GPU hardware to dramatically accelerate both exact GP inference and scalable approximations. Additionally, we provide GPyTorch, a software platform for scalable GP inference via BBMM, built on PyTorch.
Anytime Stereo Image Depth Estimation on Mobile Devices
Oct 26, 2018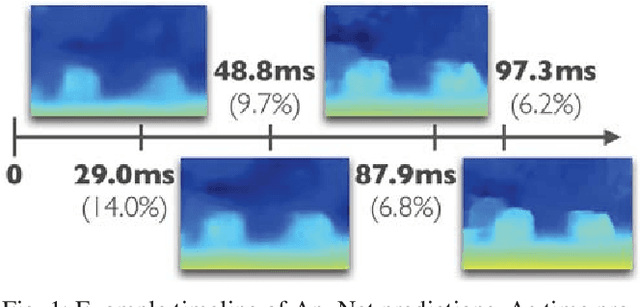
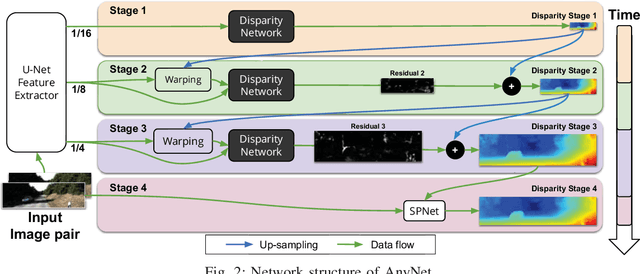
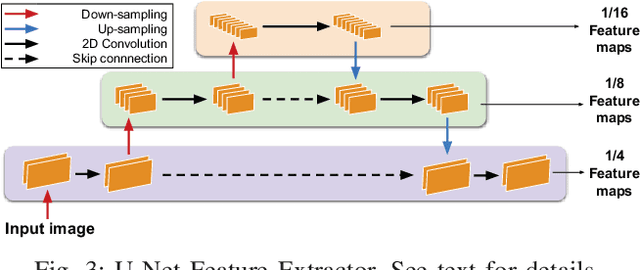
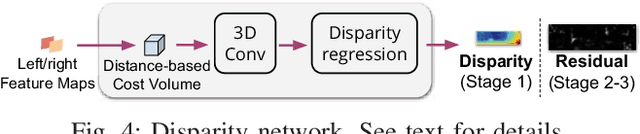
Many real-world applications of stereo depth estimation in robotics require the generation of accurate disparity maps in real time under significant computational constraints. Current state-of-the-art algorithms can either generate accurate but slow mappings, or fast but inaccurate ones, and typically require far too many parameters for power- or memory-constrained devices. Motivated by this shortcoming, we propose a novel approach for disparity prediction in the anytime setting. In contrast to prior work, our end-to-end learned approach can trade off computation and accuracy at inference time. The depth estimation is performed in stages, during which the model can be queried at any time to output its current best estimate. Our final model can process 1242$ \times $375 resolution images within a range of 10-35 FPS on an NVIDIA Jetson TX2 module with only marginal increases in error -- using two orders of magnitude fewer parameters than the most competitive baseline. Our code is available as open source on https://github.com/mileyan/AnyNet .
Deep Person Re-identification for Probabilistic Data Association in Multiple Pedestrian Tracking
Oct 19, 2018

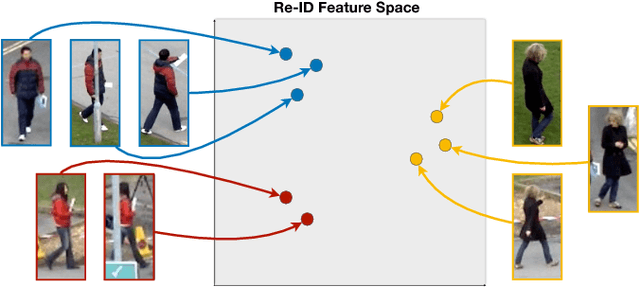

We present a data association method for vision-based multiple pedestrian tracking, using deep convolutional features to distinguish between different people based on their appearances. These re-identification (re-ID) features are learned such that they are invariant to transformations such as rotation, translation, and changes in the background, allowing consistent identification of a pedestrian moving through a scene. We incorporate re-ID features into a general data association likelihood model for multiple person tracking, experimentally validate this model by using it to perform tracking in two evaluation video sequences, and examine the performance improvements gained as compared to several baseline approaches. Our results demonstrate that using deep person re-ID for data association greatly improves tracking robustness to challenges such as occlusions and path crossings.
Resource Aware Person Re-identification across Multiple Resolutions
Oct 02, 2018
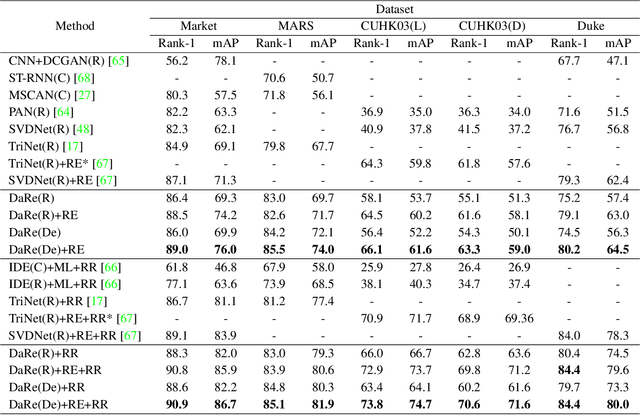
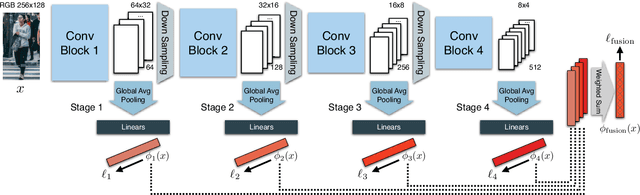
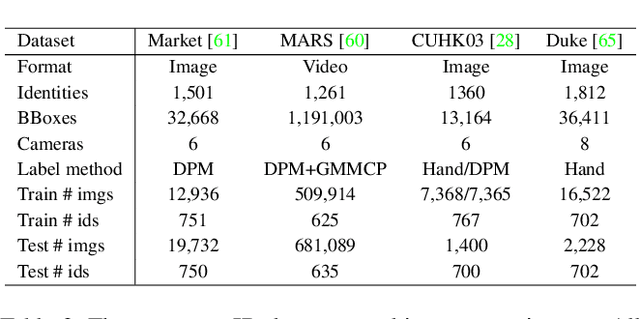
Not all people are equally easy to identify: color statistics might be enough for some cases while others might require careful reasoning about high- and low-level details. However, prevailing person re-identification(re-ID) methods use one-size-fits-all high-level embeddings from deep convolutional networks for all cases. This might limit their accuracy on difficult examples or makes them needlessly expensive for the easy ones. To remedy this, we present a new person re-ID model that combines effective embeddings built on multiple convolutional network layers, trained with deep-supervision. On traditional re-ID benchmarks, our method improves substantially over the previous state-of-the-art results on all five datasets that we evaluate on. We then propose two new formulations of the person re-ID problem under resource-constraints, and show how our model can be used to effectively trade off accuracy and computation in the presence of resource constraints. Code and pre-trained models are available at https://github.com/mileyan/DARENet.
Low Frequency Adversarial Perturbation
Sep 24, 2018

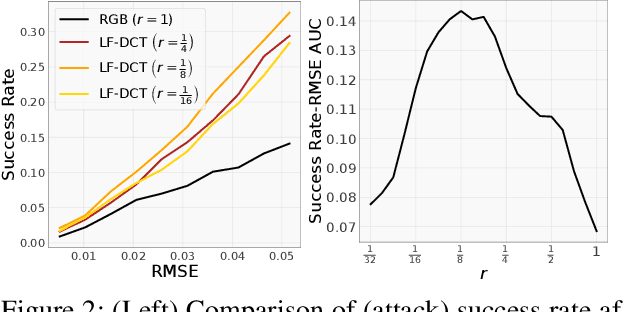

Recently, machine learning security has received significant attention. Many computer vision and speech recognition systems have been compromised by adversarially but imperceptibly perturbed input. To identify potential perturbations, attackers search the high dimensional input space to find directions in which the model lacks robustness. The exponential number of such directions makes the existence of these adversarial perturbations likely, but also creates significant challenges in the black-box setting: First, in the absence of gradient information the search problem becomes expensive, resulting in high query complexity. Second, the constructed perturbations are typically high-frequency in nature and can be successfully defended against through denoising transformations. In this paper we propose to restrict the search for adversarial images to a low frequency domain. This approach is compatible with existing white-box and black-box attacks, and has remarkable benefits in the latter setting. In particular, we achieve state-of-the-art black-box query efficiency and improve over prior work by an order of magnitude. Further, we can circumvent image transformation defenses even when both the model and the defense strategy are unknown. Finally, we demonstrate the efficacy of this technique by fooling the Google Cloud Vision platform with an unprecedented low number of model queries.
Understanding Batch Normalization
Sep 16, 2018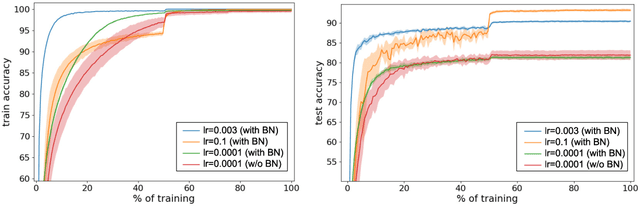
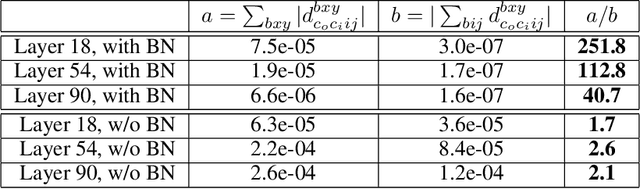
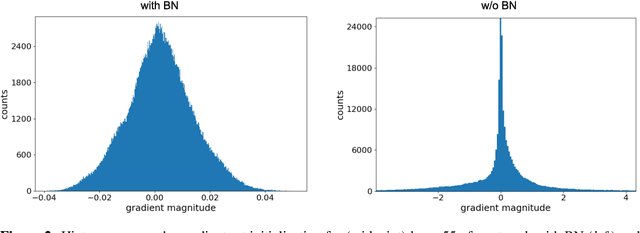
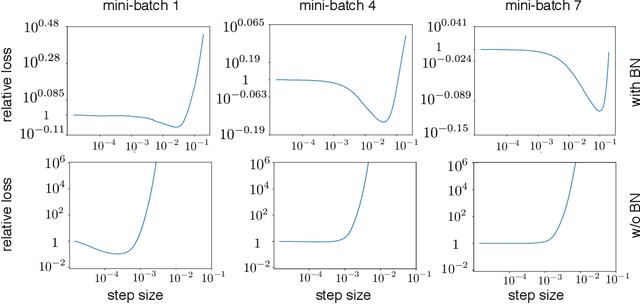
Batch normalization is a ubiquitous deep learning technique that normalizes activations in intermediate layers. It is associated with improved accuracy and faster learning, but despite its enormous success there is little consensus regarding why it works. We aim to rectify this and take an empirical approach to understanding batch normalization. Our primary observation is that the higher learning rates that batch normalization enables have a regularizing effect that dramatically improves generalization of normalized networks, which is both demonstrated empirically and motivated theoretically. We show how activations become large and how the convolutional channels become increasingly ill-behaved for layers deep in unnormalized networks, and how this results in larger input-independent gradients. Beyond just gradient scaling, we demonstrate how the learning rate in unnormalized networks is further limited by the magnitude of activations growing exponentially with network depth for large parameter updates, a problem batch normalization trivially avoids. Motivated by recent results in random matrix theory, we argue that ill-conditioning of the activations is due to fluctuations in random initialization, shedding new light on classical initialization schemes and their consequences.
Constant-Time Predictive Distributions for Gaussian Processes
Jun 20, 2018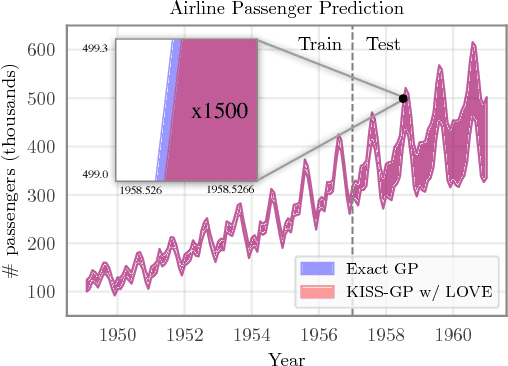

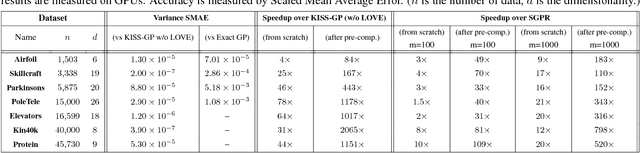
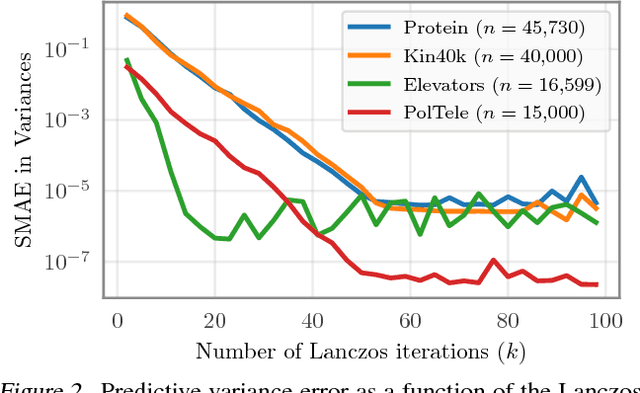
One of the most compelling features of Gaussian process (GP) regression is its ability to provide well-calibrated posterior distributions. Recent advances in inducing point methods have sped up GP marginal likelihood and posterior mean computations, leaving posterior covariance estimation and sampling as the remaining computational bottlenecks. In this paper we address these shortcomings by using the Lanczos algorithm to rapidly approximate the predictive covariance matrix. Our approach, which we refer to as LOVE (LanczOs Variance Estimates), substantially improves time and space complexity. In our experiments, LOVE computes covariances up to 2,000 times faster and draws samples 18,000 times faster than existing methods, all without sacrificing accuracy.
CondenseNet: An Efficient DenseNet using Learned Group Convolutions
Jun 07, 2018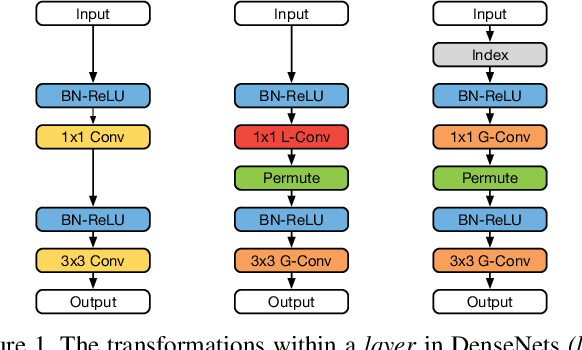
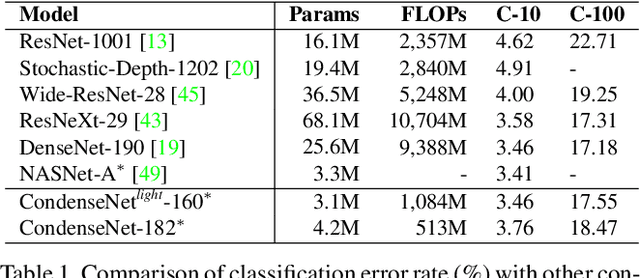
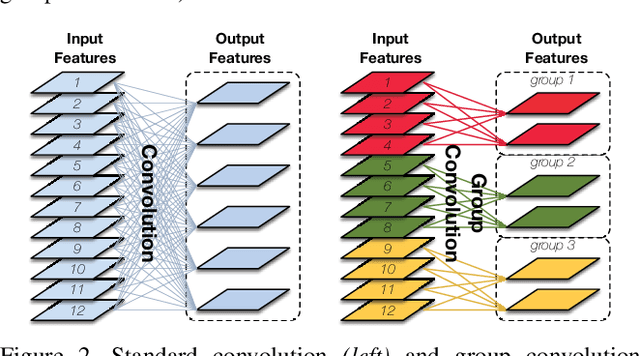
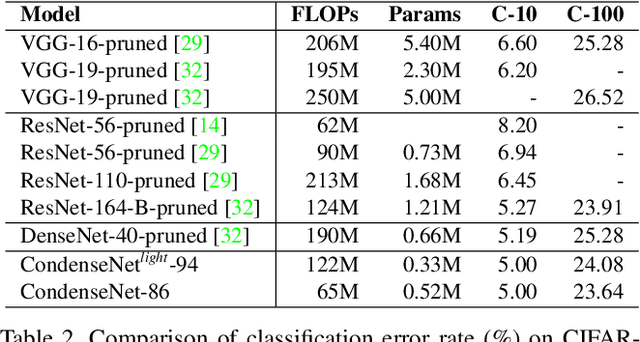
Deep neural networks are increasingly used on mobile devices, where computational resources are limited. In this paper we develop CondenseNet, a novel network architecture with unprecedented efficiency. It combines dense connectivity with a novel module called learned group convolution. The dense connectivity facilitates feature re-use in the network, whereas learned group convolutions remove connections between layers for which this feature re-use is superfluous. At test time, our model can be implemented using standard group convolutions, allowing for efficient computation in practice. Our experiments show that CondenseNets are far more efficient than state-of-the-art compact convolutional networks such as MobileNets and ShuffleNets.
Multi-Scale Dense Networks for Resource Efficient Image Classification
Jun 07, 2018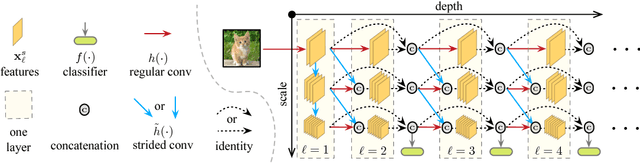
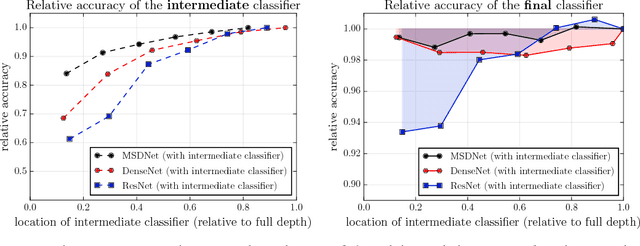

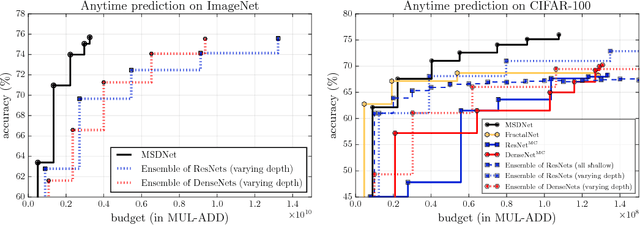
In this paper we investigate image classification with computational resource limits at test time. Two such settings are: 1. anytime classification, where the network's prediction for a test example is progressively updated, facilitating the output of a prediction at any time; and 2. budgeted batch classification, where a fixed amount of computation is available to classify a set of examples that can be spent unevenly across "easier" and "harder" inputs. In contrast to most prior work, such as the popular Viola and Jones algorithm, our approach is based on convolutional neural networks. We train multiple classifiers with varying resource demands, which we adaptively apply during test time. To maximally re-use computation between the classifiers, we incorporate them as early-exits into a single deep convolutional neural network and inter-connect them with dense connectivity. To facilitate high quality classification early on, we use a two-dimensional multi-scale network architecture that maintains coarse and fine level features all-throughout the network. Experiments on three image-classification tasks demonstrate that our framework substantially improves the existing state-of-the-art in both settings.