 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIN: Fast and Accurate Sequence Labeling with Approximate Inference Network
Oct 12, 2020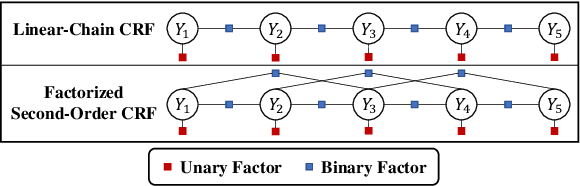
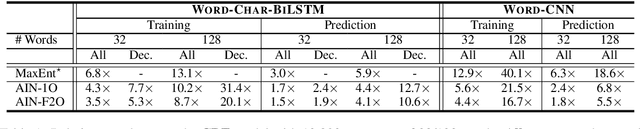
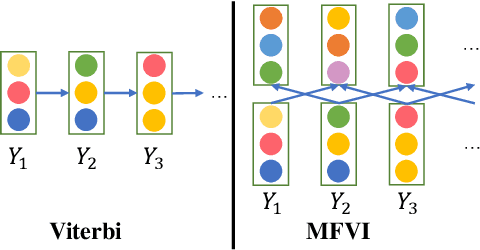

The linear-chain Conditional Random Field (CRF) model is one of the most widely-used neural sequence labeling approaches. Exact probabilistic inference algorithms such as the forward-backward and Viterbi algorithms are typically applied in training and prediction stages of the CRF model. However, these algorithms require sequential computation that makes parallelization impossible. In this paper, we propose to employ a parallelizable approximate variational inference algorithm for the CRF model. Based on this algorithm, we design an approximate inference network that can be connected with the encoder of the neural CRF model to form an end-to-end network, which is amenable to parallelization for faster training and prediction. The empirical results show that our proposed approaches achieve a 12.7-fold improvement in decoding speed with long sentences and a competitive accuracy compared with the traditional CRF approach.
Structural Knowledge Distillation
Oct 10, 2020
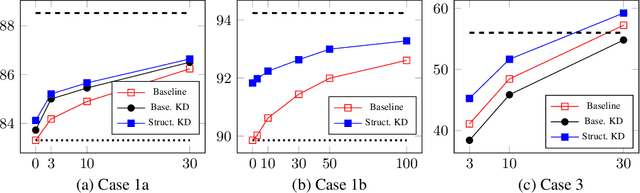
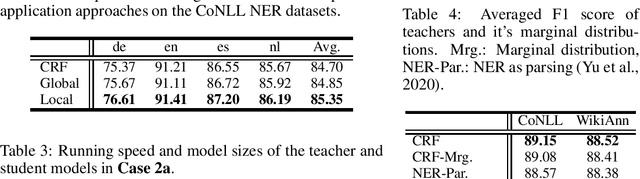
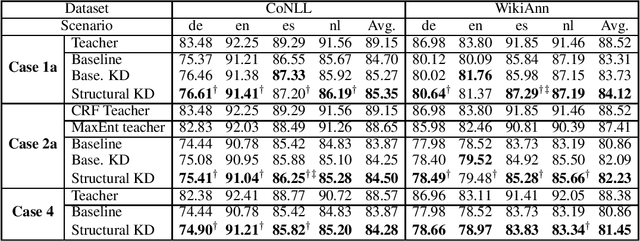
Knowledge distillation is a critical technique to transfer knowledge between models, typically from a large model (the teacher) to a smaller one (the student). The objective function of knowledge distillation is typically the cross-entropy between the teacher and the student's output distributions. However, for structured prediction problems, the output space is exponential in size; therefore, the cross-entropy objective becomes intractable to compute and optimize directly. In this paper, we derive a factorized form of the knowledge distillation objective for structured prediction, which is tractable for many typical choices of the teacher and student models. In particular, we show the tractability and empirical effectiveness of structural knowledge distillation between sequence labeling and dependency parsing models under four different scenarios: 1) the teacher and student share the same factorization form of the output structure scoring function; 2) the student factorization produces smaller substructures than the teacher factorization; 3) the teacher factorization produces smaller substructures than the student factorization; 4) the factorization forms from the teacher and the student are incompatible.
Automated Concatenation of Embeddings for Structured Prediction
Oct 10, 2020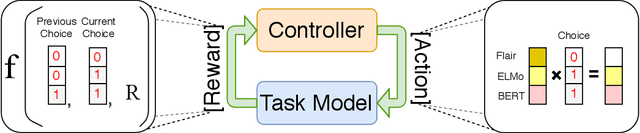
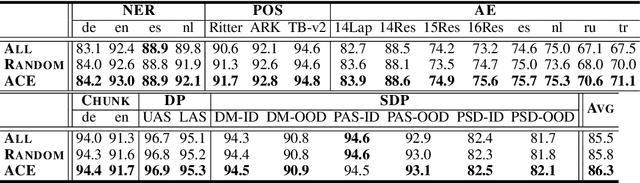
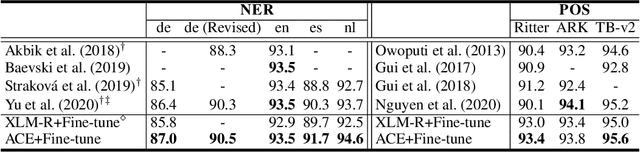
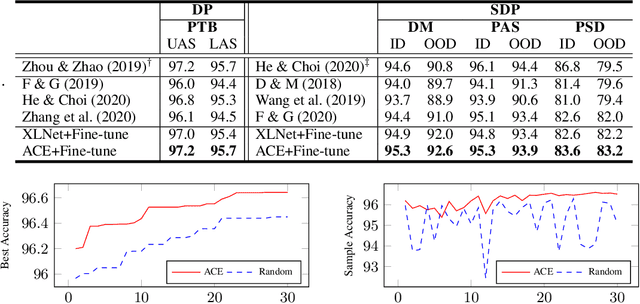
Pretrained contextualized embeddings are powerful word representations for structured prediction tasks. Recent work found that better word representations can be obtained by concatenating different types of embeddings. However, the selection of embeddings to form the best concatenated representation usually varies depending on the task and the collection of candidate embeddings, and the ever-increasing number of embedding types makes it a more difficult problem. In this paper, we propose Automated Concatenation of Embeddings (ACE) to automate the process of finding better concatenations of embeddings for structured prediction tasks, based on a formulation inspired by recent progress on neural architecture search. Specifically, a controller alternately samples a concatenation of embeddings, according to its current belief of the effectiveness of individual embedding types in consideration for a task, and updates the belief based on a reward. We follow strategies in reinforcement learning to optimize the parameters of the controller and compute the reward based on the accuracy of a task model, which is fed with the sampled concatenation as input and trained on a task dataset. Empirical results on 6 tasks and 23 datasets show that our approach outperforms strong baselines and achieves state-of-the-art performance with fine-tuned embeddings in the vast majority of evaluations.
More Embeddings, Better Sequence Labelers?
Oct 10, 2020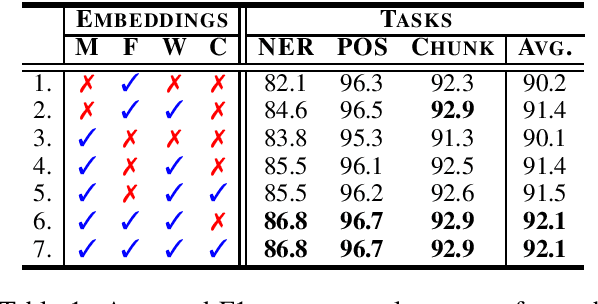
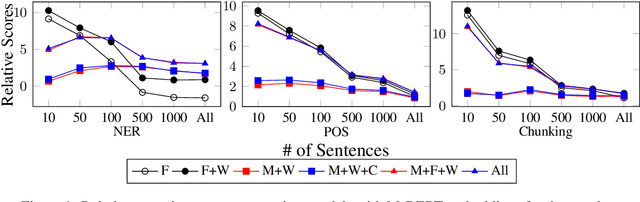

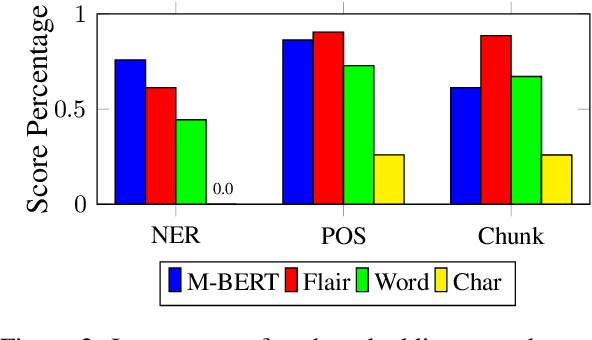
Recent work proposes a family of contextual embeddings that significantly improves the accuracy of sequence labelers over non-contextual embeddings. However, there is no definite conclusion on whether we can build better sequence labelers by combining different kinds of embeddings in various settings. In this paper, we conduct extensive experiments on 3 tasks over 18 datasets and 8 languages to study the accuracy of sequence labeling with various embedding concatenations and make three observations: (1) concatenating more embedding variants leads to better accuracy in rich-resource and cross-domain settings and some conditions of low-resource settings; (2) concatenating additional contextual sub-word embeddings with contextual character embeddings hurts the accuracy in extremely low-resource settings; (3) based on the conclusion of (1), concatenating additional similar contextual embeddings cannot lead to further improvements. We hope these conclusions can help people build stronger sequence labelers in various settings.
Second-Order Neural Dependency Parsing with Message Passing and End-to-End Training
Oct 10, 2020
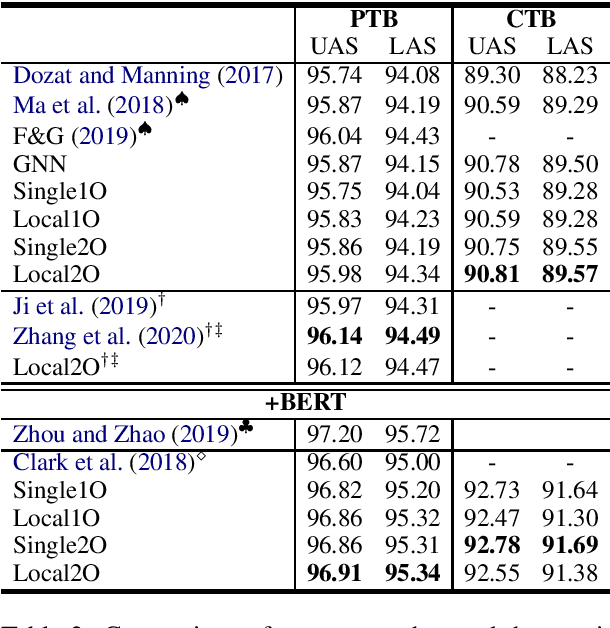
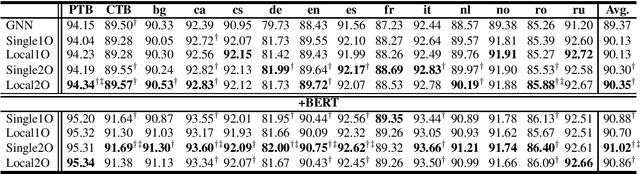
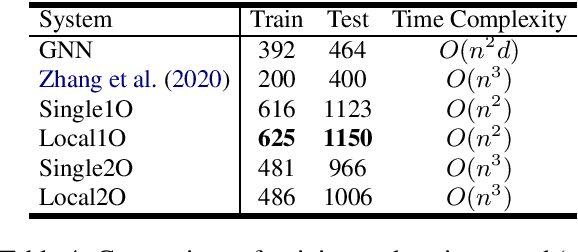
In this paper, we propose second-order graph-based neural dependency parsing using message passing and end-to-end neural networks. We empirically show that our approaches match the accuracy of very recent state-of-the-art second-order graph-based neural dependency parsers and have significantly faster speed in both training and testing. We also empirically show the advantage of second-order parsing over first-order parsing and observe that the usefulness of the head-selection structured constraint vanishes when using BERT embedding.
A Survey of Unsupervised Dependency Parsing
Oct 04, 2020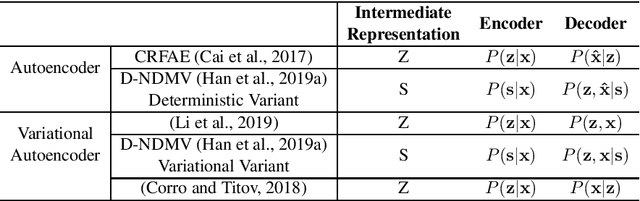
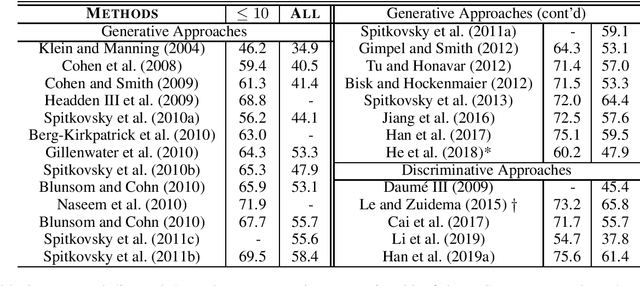
Syntactic dependency parsing is an important task in natural language processing. Unsupervised dependency parsing aims to learn a dependency parser from sentences that have no annotation of their correct parse trees. Despite its difficulty, unsupervised parsing is an interesting research direction because of its capability of utilizing almost unlimited unannotated text data. It also serves as the basis for other research in low-resource parsing. In this paper, we survey existing approaches to unsupervised dependency parsing, identify two major classes of approaches, and discuss recent trends. We hope that our survey can provide insights for researchers and facilitate future research on this topic.
Enhanced Universal Dependency Parsing with Second-Order Inference and Mixture of Training Data
Jun 11, 2020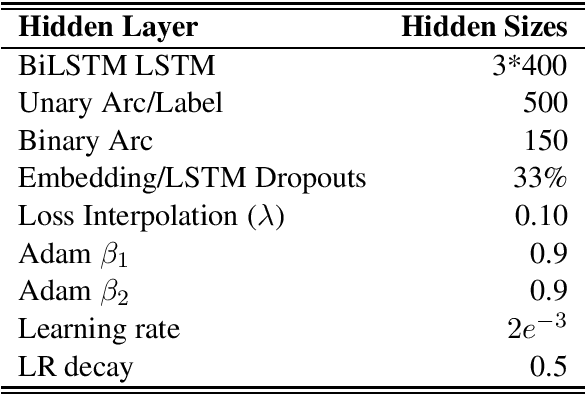
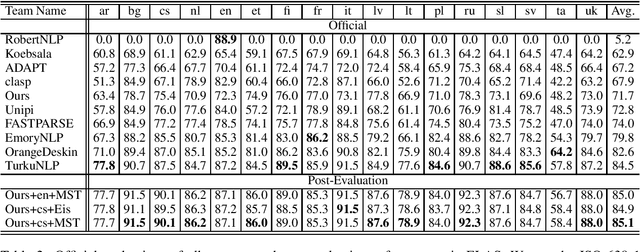
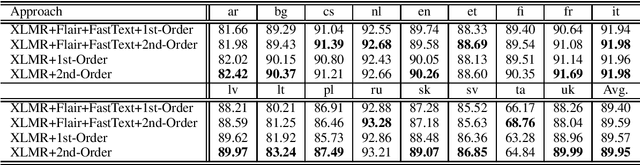
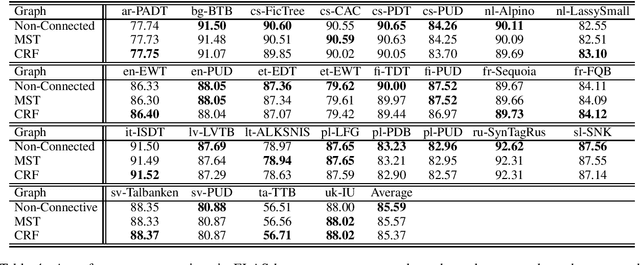
This paper presents the system used in our submission to the \textit{IWPT 2020 Shared Task}. Our system is a graph-based parser with second-order inference. For the low-resource Tamil corpus, we specially mixed the training data of Tamil with other languages and significantly improved the performance of Tamil. Due to our misunderstanding of the submission requirements, we submitted graphs that are not connected, which makes our system only rank \textbf{6th} over 10 teams. However, after we fixed this problem, our system is 0.6 ELAS higher than the team that ranked \textbf{1st} in the official results.
Structure-Level Knowledge Distillation For Multilingual Sequence Labeling
Apr 29, 2020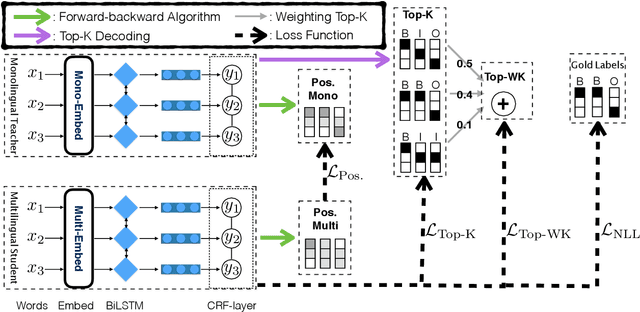
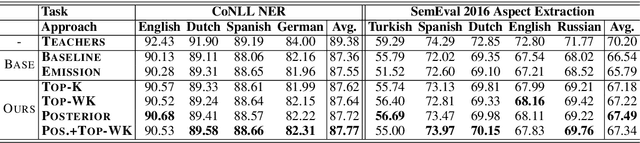
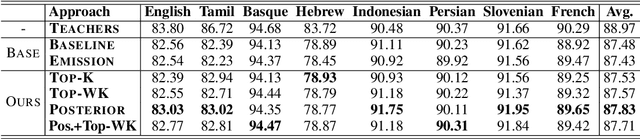
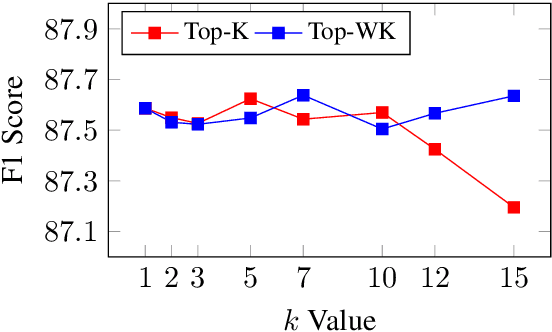
Multilingual sequence labeling is a task of predicting label sequences using a single unified model for multiple languages. Compared with relying on multiple monolingual models, using a multilingual model has the benefit of a smaller model size, easier in online serving, and generalizability to low-resource languages. However, current multilingual models still underperform individual monolingual models significantly due to model capacity limitations. In this paper, we propose to reduce the gap between monolingual models and the unified multilingual model by distilling the structural knowledge of several monolingual models (teachers) to the unified multilingual model (student). We propose two novel KD methods based on structure-level information: (1) approximately minimizes the distance between the student's and the teachers' structure level probability distributions, (2) aggregates the structure-level knowledge to local distributions and minimizes the distance between two local probability distributions. Our experiments on 4 multilingual tasks with 25 datasets show that our approaches outperform several strong baselines and have stronger zero-shot generalizability than both the baseline model and teacher models.
ShanghaiTech at MRP 2019: Sequence-to-Graph Transduction with Second-Order Edge Inference for Cross-Framework Meaning Representation Parsing
Apr 08, 2020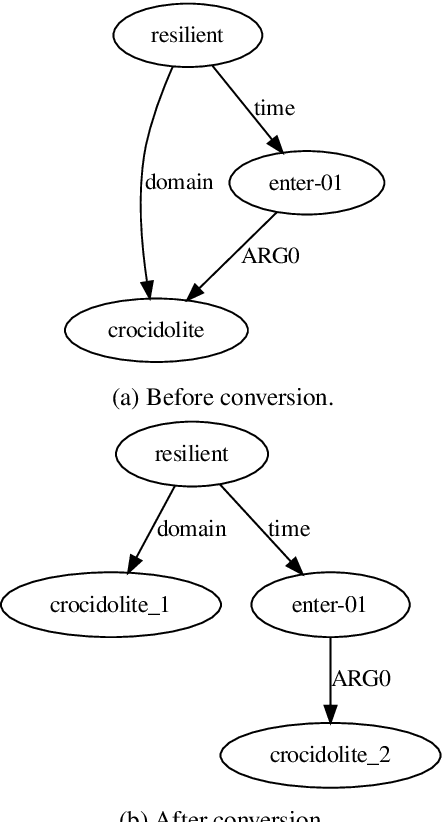
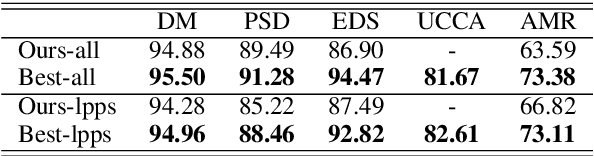
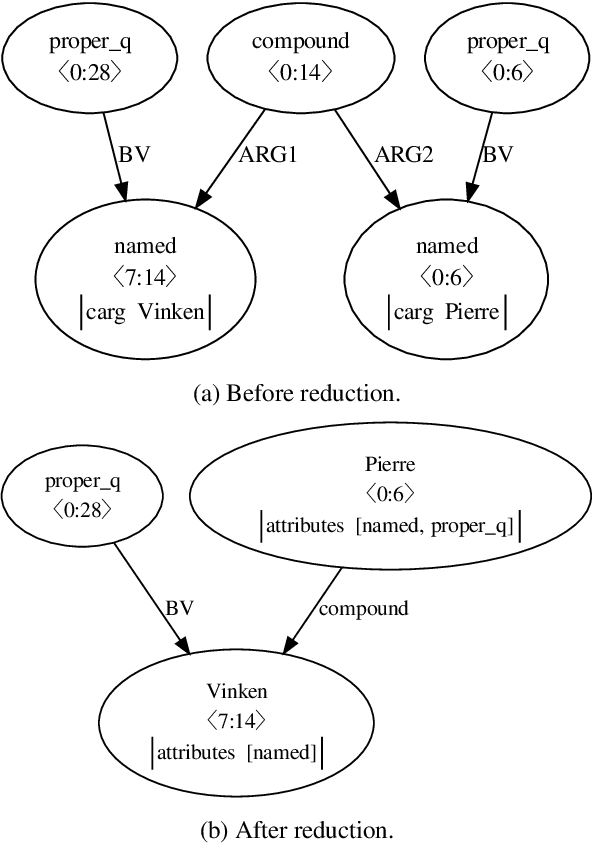
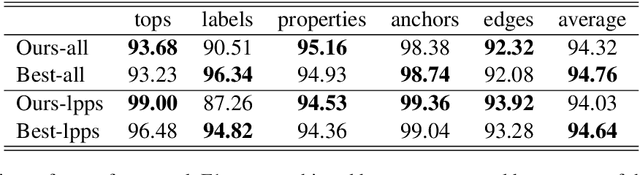
This paper presents the system used in our submission to the \textit{CoNLL 2019 shared task: Cross-Framework Meaning Representation Parsing}. Our system is a graph-based parser which combines an extended pointer-generator network that generates nodes and a second-order mean field variational inference module that predicts edges. Our system achieved \nth{1} and \nth{2} place for the DM and PSD frameworks respectively on the in-framework ranks and achieved \nth{3} place for the DM framework on the cross-framework ranks.
Learning Numeral Embeddings
Jan 11, 2020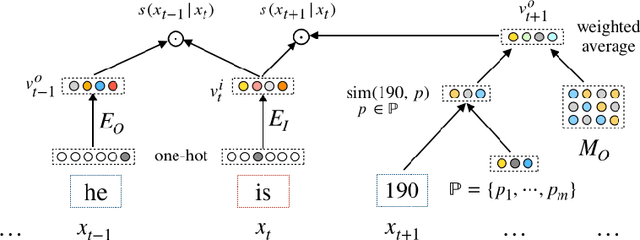

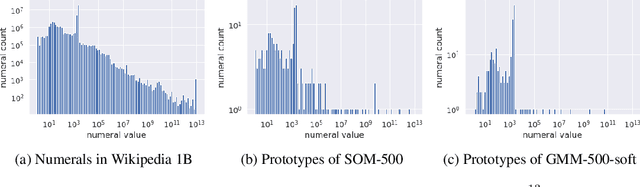
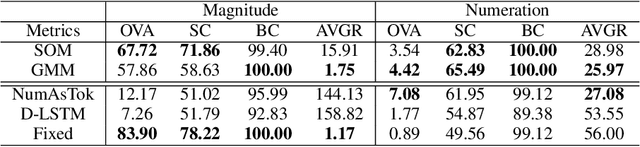
Word embedding is an essential building block for deep learning methods for natural language processing. Although word embedding has been extensively studied over the years, the problem of how to effectively embed numerals, a special subset of words, is still underexplored. Existing word embedding methods do not learn numeral embeddings well because there are an infinite number of numerals and their individual appearances in training corpora are highly scarce. In this paper, we propose two novel numeral embedding methods that can handle the out-of-vocabulary (OOV) problem for numerals. We first induce a finite set of prototype numerals using either a self-organizing map or a Gaussian mixture model. We then represent the embedding of a numeral as a weighted average of the prototype number embeddings. Numeral embeddings represented in this manner can be plugged into existing word embedding learning approaches such as skip-gram for training. We evaluated our methods and showed its effectiveness on four intrinsic and extrinsic tasks: word similarity, embedding numeracy, numeral prediction, and sequence labeling.