 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromoting Segment Anything Model towards Highly Accurate Dichotomous Image Segmentation
Dec 30, 2023



Segmenting any object represents a crucial step towards achieving artificial general intelligence, and the "Segment Anything Model" (SAM) has significantly advanced the development of foundational models in computer vision. We have high expectations regarding whether SAM can enhance highly accurate dichotomous image segmentation. In fact, the evidence presented in this article demonstrates that by inputting SAM with simple prompt boxes and utilizing the results output by SAM as input for IS5Net, we can greatly improve the effectiveness of highly accurate dichotomous image segmentation.
Salient Object Detection in RGB-D Videos
Oct 24, 2023



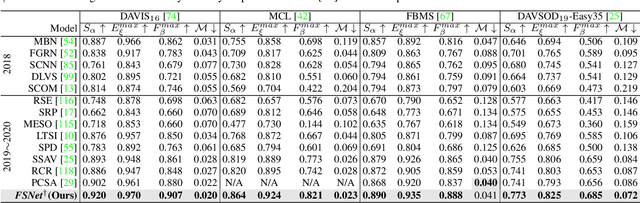
Given the widespread adoption of depth-sensing acquisition devices, RGB-D videos and related data/media have gained considerable traction in various aspects of daily life. Consequently, conducting salient object detection (SOD) in RGB-D videos presents a highly promising and evolving avenue. Despite the potential of this area, SOD in RGB-D videos remains somewhat under-explored, with RGB-D SOD and video SOD (VSOD) traditionally studied in isolation. To explore this emerging field, this paper makes two primary contributions: the dataset and the model. On one front, we construct the RDVS dataset, a new RGB-D VSOD dataset with realistic depth and characterized by its diversity of scenes and rigorous frame-by-frame annotations. We validate the dataset through comprehensive attribute and object-oriented analyses, and provide training and testing splits. Moreover, we introduce DCTNet+, a three-stream network tailored for RGB-D VSOD, with an emphasis on RGB modality and treats depth and optical flow as auxiliary modalities. In pursuit of effective feature enhancement, refinement, and fusion for precise final prediction, we propose two modules: the multi-modal attention module (MAM) and the refinement fusion module (RFM). To enhance interaction and fusion within RFM, we design a universal interaction module (UIM) and then integrate holistic multi-modal attentive paths (HMAPs) for refining multi-modal low-level features before reaching RFMs. Comprehensive experiments, conducted on pseudo RGB-D video datasets alongside our RDVS, highlight the superiority of DCTNet+ over 17 VSOD models and 14 RGB-D SOD models. Ablation experiments were performed on both pseudo and realistic RGB-D video datasets to demonstrate the advantages of individual modules as well as the necessity of introducing realistic depth. Our code together with RDVS dataset will be available at https://github.com/kerenfu/RDVS/.
Guided Focal Stack Refinement Network for Light Field Salient Object Detection
May 09, 2023



Light field salient object detection (SOD) is an emerging research direction attributed to the richness of light field data. However, most existing methods lack effective handling of focal stacks, therefore making the latter involved in a lot of interfering information and degrade the performance of SOD. To address this limitation, we propose to utilize multi-modal features to refine focal stacks in a guided manner, resulting in a novel guided focal stack refinement network called GFRNet. To this end, we propose a guided refinement and fusion module (GRFM) to refine focal stacks and aggregate multi-modal features. In GRFM, all-in-focus (AiF) and depth modalities are utilized to refine focal stacks separately, leading to two novel sub-modules for different modalities, namely AiF-based refinement module (ARM) and depth-based refinement module (DRM). Such refinement modules enhance structural and positional information of salient objects in focal stacks, and are able to improve SOD accuracy. Experimental results on four benchmark datasets demonstrate the superiority of our GFRNet model against 12 state-of-the-art models.
Depth Quality-Inspired Feature Manipulation for Efficient RGB-D and Video Salient Object Detection
Aug 08, 2022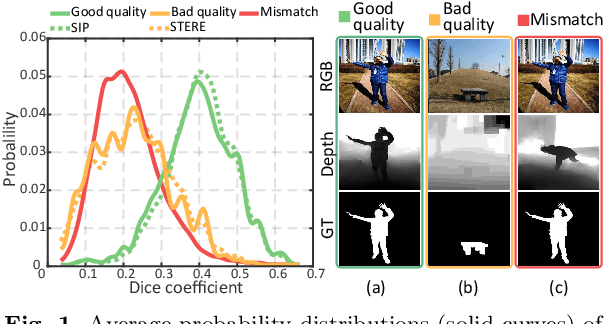
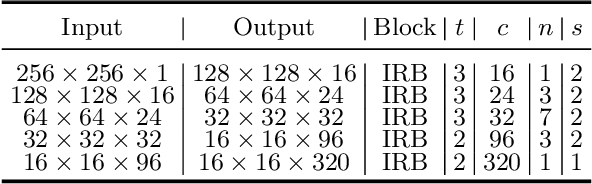
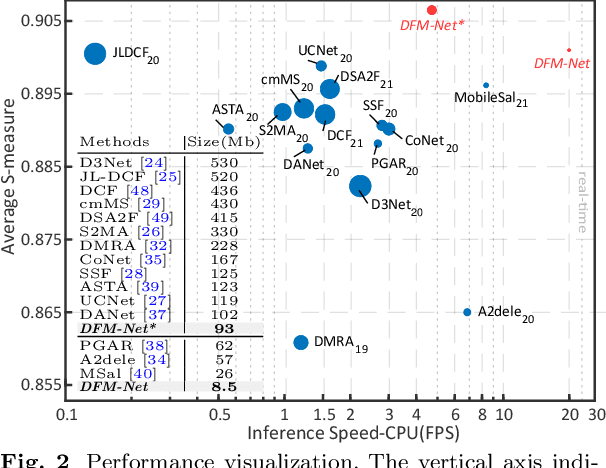
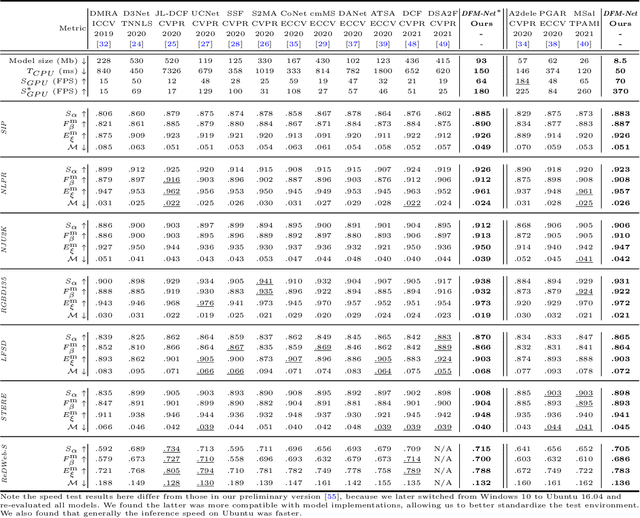
Recently CNN-based RGB-D salient object detection (SOD) has obtained significant improvement on detection accuracy. However, existing models often fail to perform well in terms of efficiency and accuracy simultaneously. This hinders their potential applications on mobile devices as well as many real-world problems. To bridge the accuracy gap between lightweight and large models for RGB-D SOD, in this paper, an efficient module that can greatly improve the accuracy but adds little computation is proposed. Inspired by the fact that depth quality is a key factor influencing the accuracy, we propose an efficient depth quality-inspired feature manipulation (DQFM) process, which can dynamically filter depth features according to depth quality. The proposed DQFM resorts to the alignment of low-level RGB and depth features, as well as holistic attention of the depth stream to explicitly control and enhance cross-modal fusion. We embed DQFM to obtain an efficient lightweight RGB-D SOD model called DFM-Net, where we in addition design a tailored depth backbone and a two-stage decoder as basic parts. Extensive experimental results on nine RGB-D datasets demonstrate that our DFM-Net outperforms recent efficient models, running at about 20 FPS on CPU with only 8.5Mb model size, and meanwhile being 2.9/2.4 times faster and 6.7/3.1 times smaller than the latest best models A2dele and MobileSal. It also maintains state-of-the-art accuracy when even compared to non-efficient models. Interestingly, further statistics and analyses verify the ability of DQFM in distinguishing depth maps of various qualities without any quality labels. Last but not least, we further apply DFM-Net to deal with video SOD (VSOD), achieving comparable performance against recent efficient models while being 3/2.3 times faster/smaller than the prior best in this field. Our code is available at https://github.com/zwbx/DFM-Net.
Depth-Cooperated Trimodal Network for Video Salient Object Detection
Feb 12, 2022
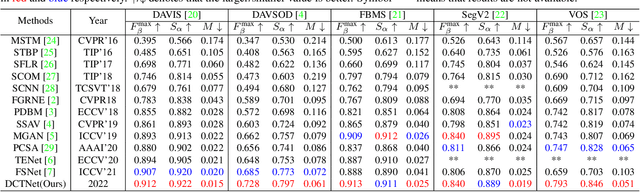
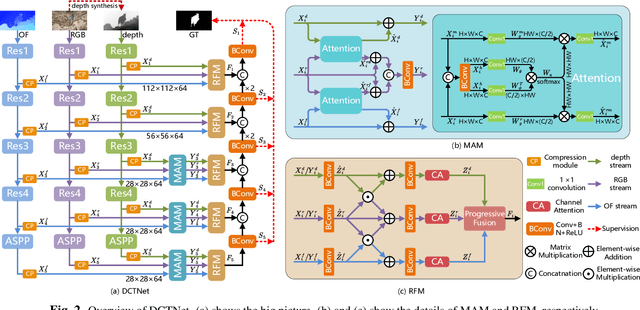
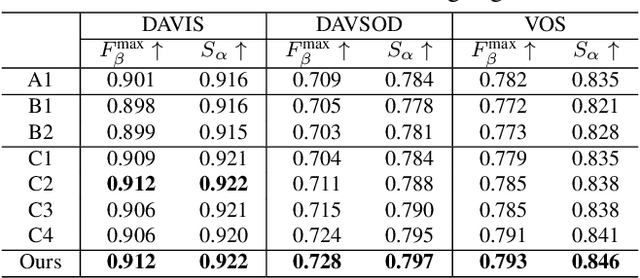
Depth can provide useful geographical cues for salient object detection (SOD), and has been proven helpful in recent RGB-D SOD methods. However, existing video salient object detection (VSOD) methods only utilize spatiotemporal information and seldom exploit depth information for detection. In this paper, we propose a depth-cooperated trimodal network, called DCTNet for VSOD, which is a pioneering work to incorporate depth information to assist VSOD. To this end, we first generate depth from RGB frames, and then propose an approach to treat the three modalities unequally. Specifically, a multi-modal attention module (MAM) is designed to model multi-modal long-range dependencies between the main modality (RGB) and the two auxiliary modalities (depth, optical flow). We also introduce a refinement fusion module (RFM) to suppress noises in each modality and select useful information dynamically for further feature refinement. Lastly, a progressive fusion strategy is adopted after the refined features to achieve final cross-modal fusion. Experiments on five benchmark datasets demonstrate the superiority of our depth-cooperated model against 12 state-of-the-art methods, and the necessity of depth is also validated.
Fast Camouflaged Object Detection via Edge-based Reversible Re-calibration Network
Nov 05, 2021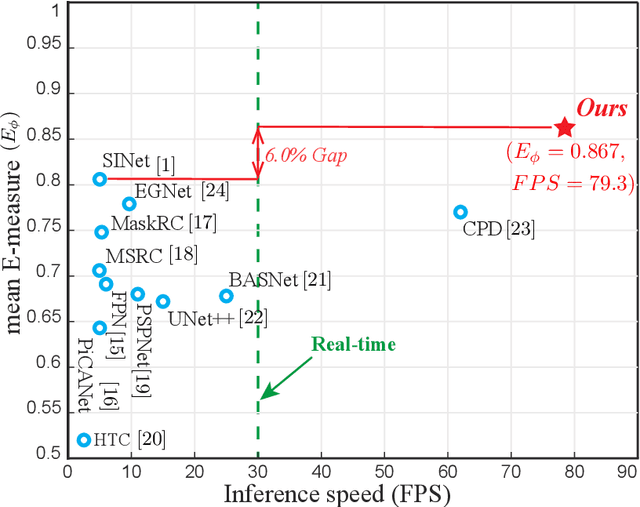
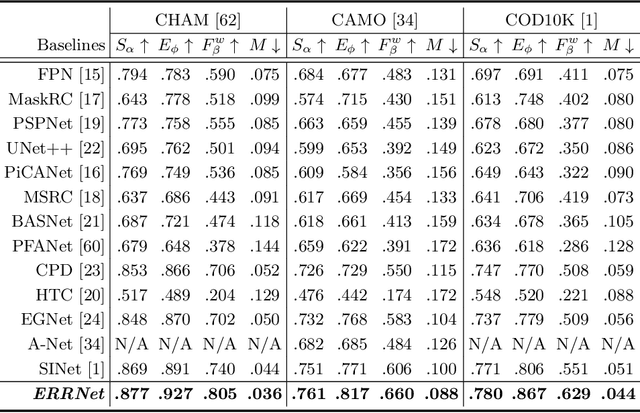
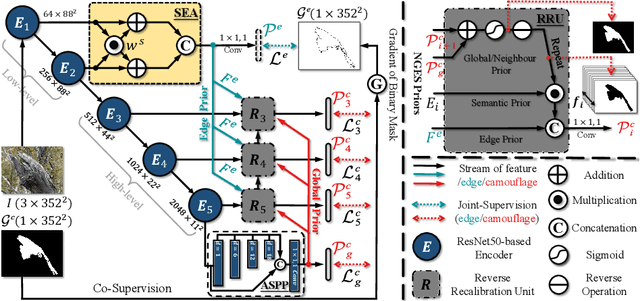
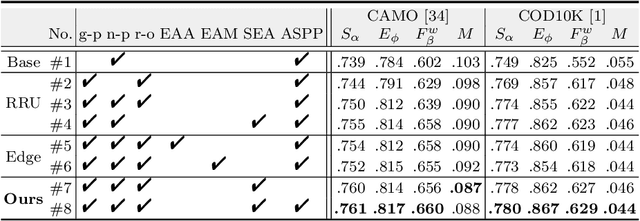
Camouflaged Object Detection (COD) aims to detect objects with similar patterns (e.g., texture, intensity, colour, etc) to their surroundings, and recently has attracted growing research interest. As camouflaged objects often present very ambiguous boundaries, how to determine object locations as well as their weak boundaries is challenging and also the key to this task. Inspired by the biological visual perception process when a human observer discovers camouflaged objects, this paper proposes a novel edge-based reversible re-calibration network called ERRNet. Our model is characterized by two innovative designs, namely Selective Edge Aggregation (SEA) and Reversible Re-calibration Unit (RRU), which aim to model the visual perception behaviour and achieve effective edge prior and cross-comparison between potential camouflaged regions and background. More importantly, RRU incorporates diverse priors with more comprehensive information comparing to existing COD models. Experimental results show that ERRNet outperforms existing cutting-edge baselines on three COD datasets and five medical image segmentation datasets. Especially, compared with the existing top-1 model SINet, ERRNet significantly improves the performance by $\sim$6% (mean E-measure) with notably high speed (79.3 FPS), showing that ERRNet could be a general and robust solution for the COD task.
Full-Duplex Strategy for Video Object Segmentation
Sep 03, 2021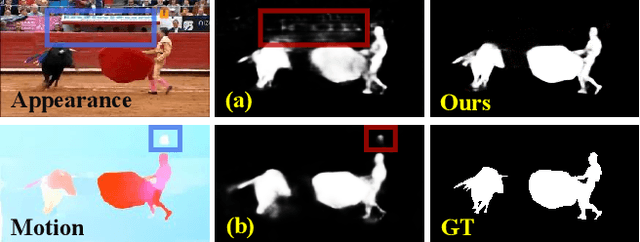

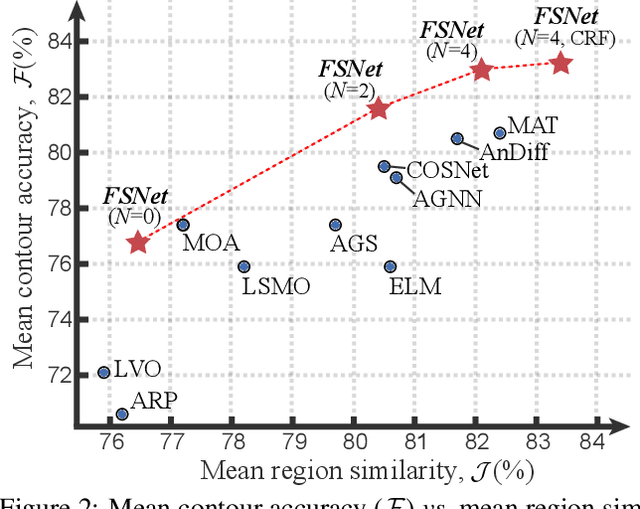
Previous video object segmentation approaches mainly focus on using simplex solutions between appearance and motion, limiting feature collaboration efficiency among and across these two cues. In this work, we study a novel and efficient full-duplex strategy network (FSNet) to address this issue, by considering a better mutual restraint scheme between motion and appearance in exploiting the cross-modal features from the fusion and decoding stage. Specifically, we introduce the relational cross-attention module (RCAM) to achieve bidirectional message propagation across embedding sub-spaces. To improve the model's robustness and update the inconsistent features from the spatial-temporal embeddings, we adopt the bidirectional purification module (BPM) after the RCAM. Extensive experiments on five popular benchmarks show that our FSNet is robust to various challenging scenarios (e.g., motion blur, occlusion) and achieves favourable performance against existing cutting-edges both in the video object segmentation and video salient object detection tasks. The project is publicly available at: https://dpfan.net/FSNet.
Depth Quality-Inspired Feature Manipulation for Efficient RGB-D Salient Object Detection
Jul 06, 2021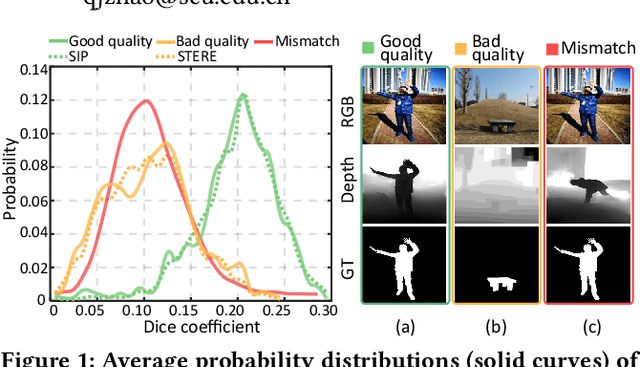
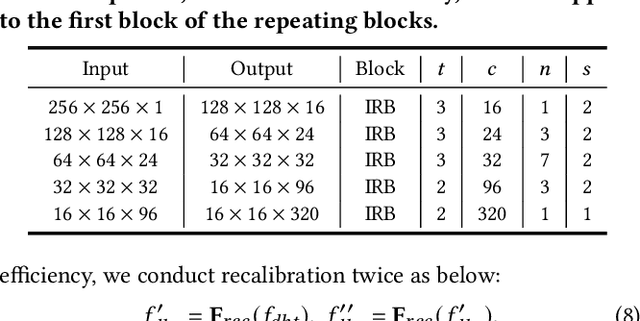
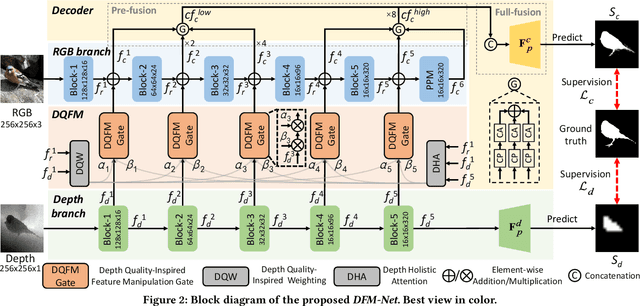
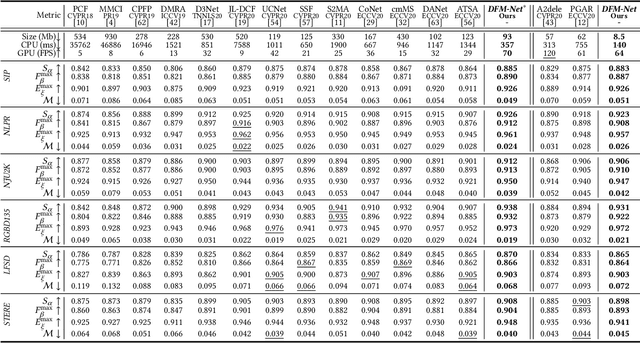
RGB-D salient object detection (SOD) recently has attracted increasing research interest by benefiting conventional RGB SOD with extra depth information. However, existing RGB-D SOD models often fail to perform well in terms of both efficiency and accuracy, which hinders their potential applications on mobile devices and real-world problems. An underlying challenge is that the model accuracy usually degrades when the model is simplified to have few parameters. To tackle this dilemma and also inspired by the fact that depth quality is a key factor influencing the accuracy, we propose a novel depth quality-inspired feature manipulation (DQFM) process, which is efficient itself and can serve as a gating mechanism for filtering depth features to greatly boost the accuracy. DQFM resorts to the alignment of low-level RGB and depth features, as well as holistic attention of the depth stream to explicitly control and enhance cross-modal fusion. We embed DQFM to obtain an efficient light-weight model called DFM-Net, where we also design a tailored depth backbone and a two-stage decoder for further efficiency consideration. Extensive experimental results demonstrate that our DFM-Net achieves state-of-the-art accuracy when comparing to existing non-efficient models, and meanwhile runs at 140ms on CPU (2.2$\times$ faster than the prior fastest efficient model) with only $\sim$8.5Mb model size (14.9% of the prior lightest). Our code will be available at https://github.com/zwbx/DFM-Net.
BTS-Net: Bi-directional Transfer-and-Selection Network For RGB-D Salient Object Detection
Apr 05, 2021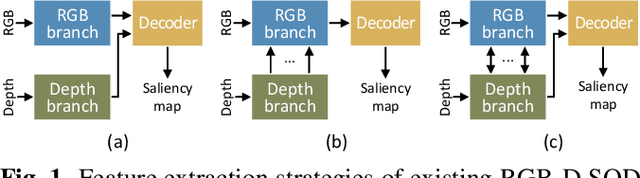
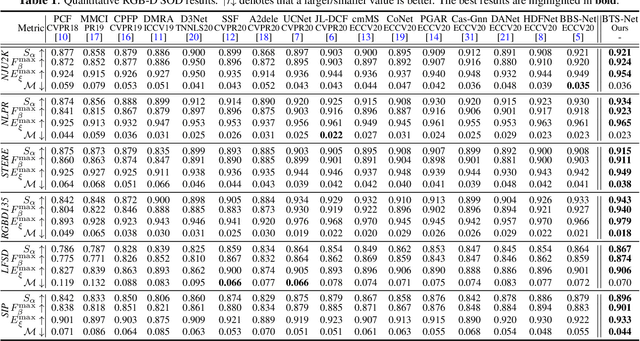
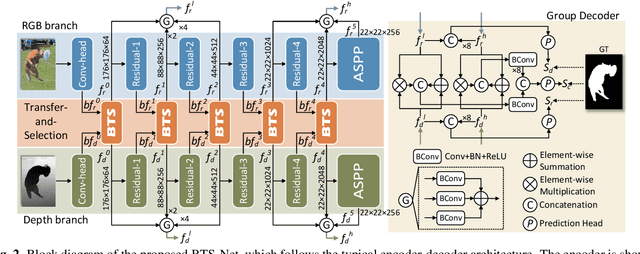
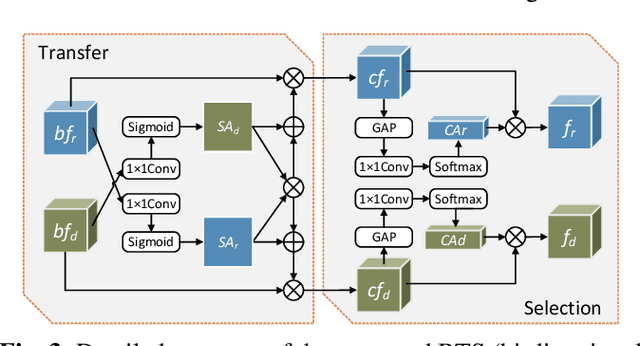
Depth information has been proved beneficial in RGB-D salient object detection (SOD). However, depth maps obtained often suffer from low quality and inaccuracy. Most existing RGB-D SOD models have no cross-modal interactions or only have unidirectional interactions from depth to RGB in their encoder stages, which may lead to inaccurate encoder features when facing low quality depth. To address this limitation, we propose to conduct progressive bi-directional interactions as early in the encoder stage, yielding a novel bi-directional transfer-and-selection network named BTS-Net, which adopts a set of bi-directional transfer-and-selection (BTS) modules to purify features during encoding. Based on the resulting robust encoder features, we also design an effective light-weight group decoder to achieve accurate final saliency prediction. Comprehensive experiments on six widely used datasets demonstrate that BTS-Net surpasses 16 latest state-of-the-art approaches in terms of four key metrics.
RGB-D Salient Object Detection via 3D Convolutional Neural Networks
Jan 25, 2021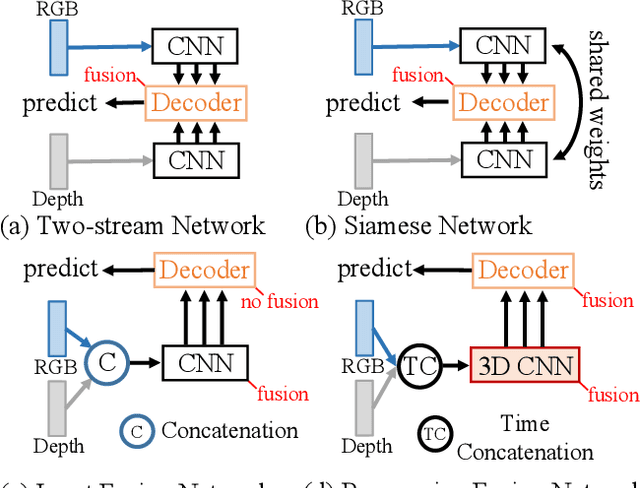
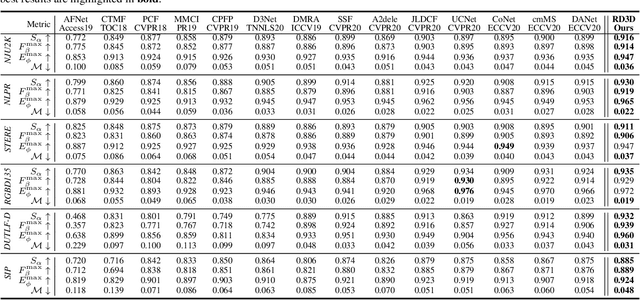
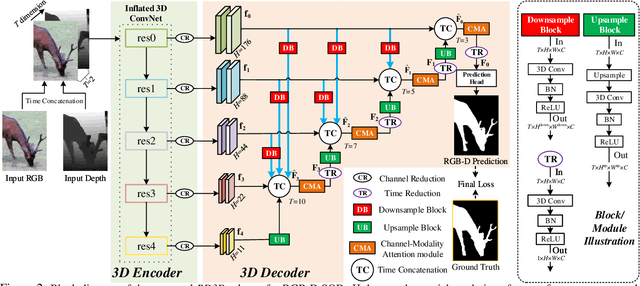

RGB-D salient object detection (SOD) recently has attracted increasing research interest and many deep learning methods based on encoder-decoder architectures have emerged. However, most existing RGB-D SOD models conduct feature fusion either in the single encoder or the decoder stage, which hardly guarantees sufficient cross-modal fusion ability. In this paper, we make the first attempt in addressing RGB-D SOD through 3D convolutional neural networks. The proposed model, named RD3D, aims at pre-fusion in the encoder stage and in-depth fusion in the decoder stage to effectively promote the full integration of RGB and depth streams. Specifically, RD3D first conducts pre-fusion across RGB and depth modalities through an inflated 3D encoder, and later provides in-depth feature fusion by designing a 3D decoder equipped with rich back-projection paths (RBPP) for leveraging the extensive aggregation ability of 3D convolutions. With such a progressive fusion strategy involving both the encoder and decoder, effective and thorough interaction between the two modalities can be exploited and boost the detection accuracy. Extensive experiments on six widely used benchmark datasets demonstrate that RD3D performs favorably against 14 state-of-the-art RGB-D SOD approaches in terms of four key evaluation metrics. Our code will be made publicly available: https://github.com/PPOLYpubki/RD3D.