 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrgan Segmentation From Full-size CT Images Using Memory-Efficient FCN
Mar 24, 2020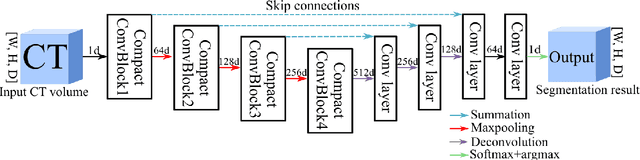
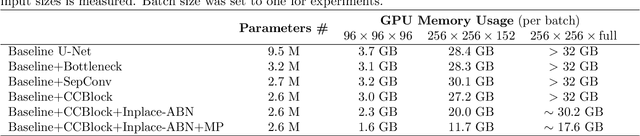
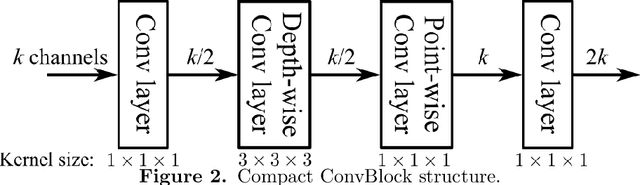
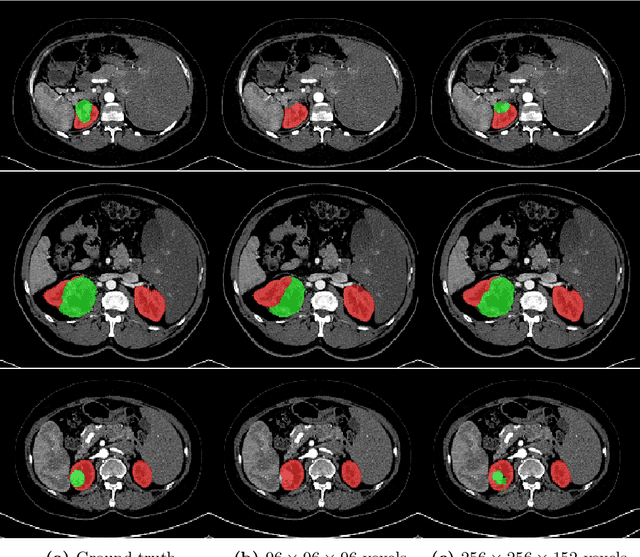
In this work, we present a memory-efficient fully convolutional network (FCN) incorporated with several memory-optimized techniques to reduce the run-time GPU memory demand during training phase. In medical image segmentation tasks, subvolume cropping has become a common preprocessing. Subvolumes (or small patch volumes) were cropped to reduce GPU memory demand. However, small patch volumes capture less spatial context that leads to lower accuracy. As a pilot study, the purpose of this work is to propose a memory-efficient FCN which enables us to train the model on full size CT image directly without subvolume cropping, while maintaining the segmentation accuracy. We optimize our network from both architecture and implementation. With the development of computing hardware, such as graphics processing unit (GPU) and tensor processing unit (TPU), now deep learning applications is able to train networks with large datasets within acceptable time. Among these applications, semantic segmentation using fully convolutional network (FCN) also has gained a significant improvement against traditional image processing approaches in both computer vision and medical image processing fields. However, unlike general color images used in computer vision tasks, medical images have larger scales than color images such as 3D computed tomography (CT) images, micro CT images, and histopathological images. For training these medical images, the large demand of computing resource become a severe problem. In this paper, we present a memory-efficient FCN to tackle the high GPU memory demand challenge in organ segmentation problem from clinical CT images. The experimental results demonstrated that our GPU memory demand is about 40% of baseline architecture, parameter amount is about 30% of the baseline.
Visualizing intestines for diagnostic assistance of ileus based on intestinal region segmentation from 3D CT images
Mar 03, 2020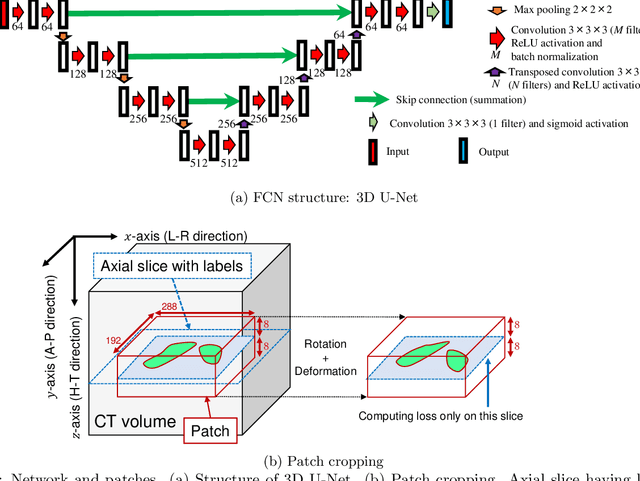
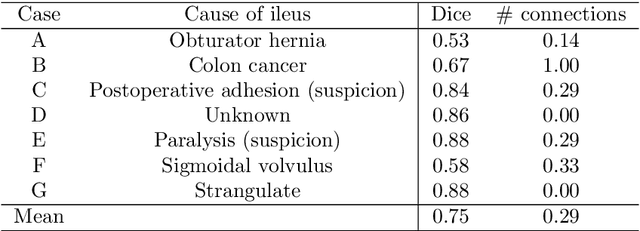
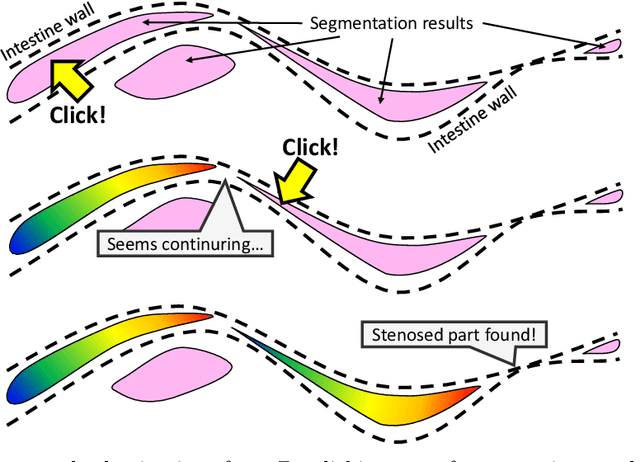
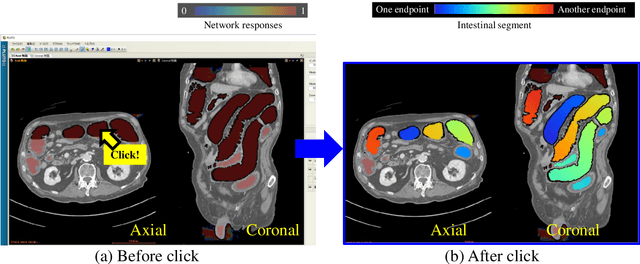
This paper presents a visualization method of intestine (the small and large intestines) regions and their stenosed parts caused by ileus from CT volumes. Since it is difficult for non-expert clinicians to find stenosed parts, the intestine and its stenosed parts should be visualized intuitively. Furthermore, the intestine regions of ileus cases are quite hard to be segmented. The proposed method segments intestine regions by 3D FCN (3D U-Net). Intestine regions are quite difficult to be segmented in ileus cases since the inside the intestine is filled with fluids. These fluids have similar intensities with intestinal wall on 3D CT volumes. We segment the intestine regions by using 3D U-Net trained by a weak annotation approach. Weak-annotation makes possible to train the 3D U-Net with small manually-traced label images of the intestine. This avoids us to prepare many annotation labels of the intestine that has long and winding shape. Each intestine segment is volume-rendered and colored based on the distance from its endpoint in volume rendering. Stenosed parts (disjoint points of an intestine segment) can be easily identified on such visualization. In the experiments, we showed that stenosed parts were intuitively visualized as endpoints of segmented regions, which are colored by red or blue.
Multi-modality super-resolution loss for GAN-based super-resolution of clinical CT images using micro CT image database
Dec 30, 2019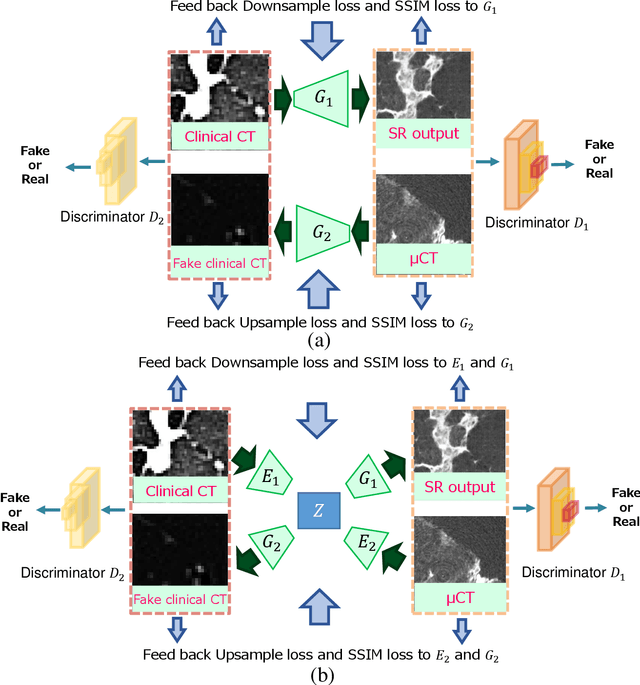
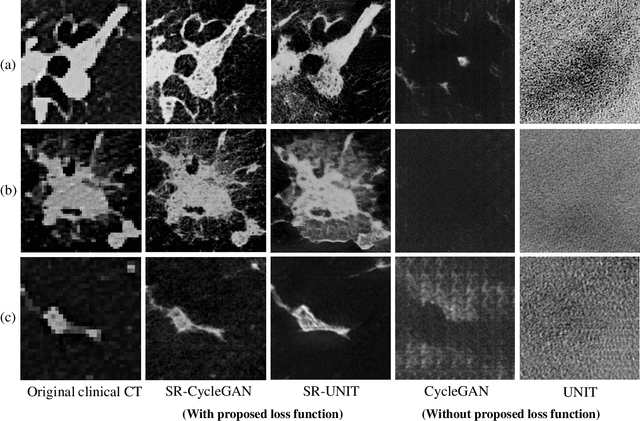
This paper newly introduces multi-modality loss function for GAN-based super-resolution that can maintain image structure and intensity on unpaired training dataset of clinical CT and micro CT volumes. Precise non-invasive diagnosis of lung cancer mainly utilizes 3D multidetector computed-tomography (CT) data. On the other hand, we can take micro CT images of resected lung specimen in 50 micro meter or higher resolution. However, micro CT scanning cannot be applied to living human imaging. For obtaining highly detailed information such as cancer invasion area from pre-operative clinical CT volumes of lung cancer patients, super-resolution (SR) of clinical CT volumes to $\mu$CT level might be one of substitutive solutions. While most SR methods require paired low- and high-resolution images for training, it is infeasible to obtain precisely paired clinical CT and micro CT volumes. We aim to propose unpaired SR approaches for clincial CT using micro CT images based on unpaired image translation methods such as CycleGAN or UNIT. Since clinical CT and micro CT are very different in structure and intensity, direct application of GAN-based unpaired image translation methods in super-resolution tends to generate arbitrary images. Aiming to solve this problem, we propose new loss function called multi-modality loss function to maintain the similarity of input images and corresponding output images in super-resolution task. Experimental results demonstrated that the newly proposed loss function made CycleGAN and UNIT to successfully perform SR of clinical CT images of lung cancer patients into micro CT level resolution, while original CycleGAN and UNIT failed in super-resolution.
Intelligent image synthesis to attack a segmentation CNN using adversarial learning
Sep 24, 2019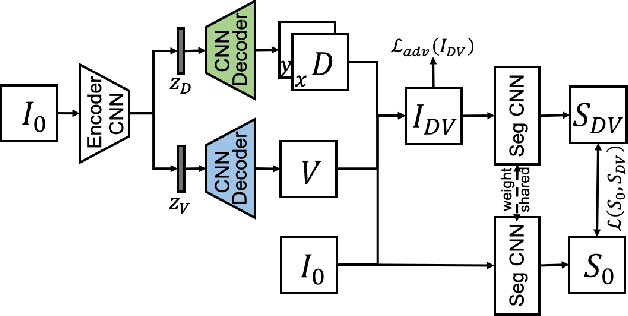
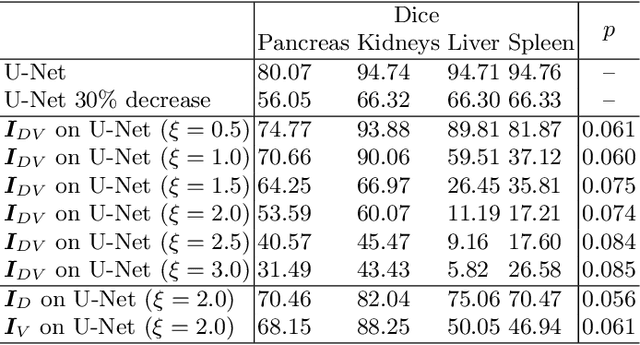
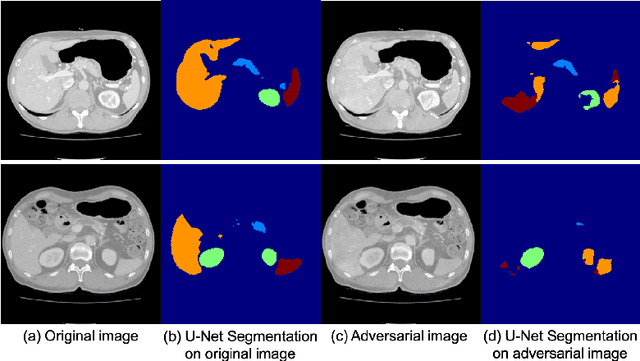
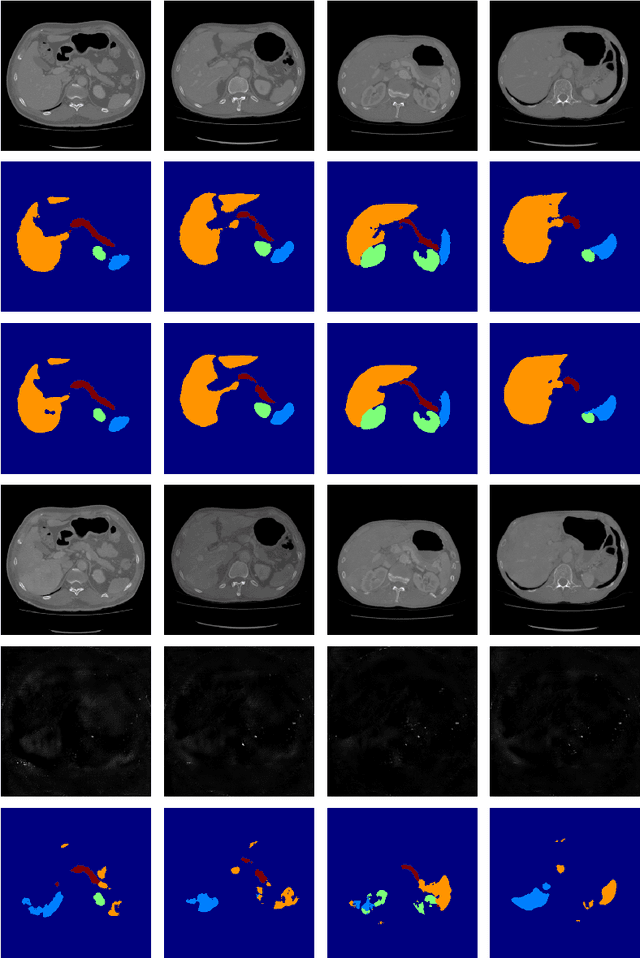
Deep learning approaches based on convolutional neural networks (CNNs) have been successful in solving a number of problems in medical imaging, including image segmentation. In recent years, it has been shown that CNNs are vulnerable to attacks in which the input image is perturbed by relatively small amounts of noise so that the CNN is no longer able to perform a segmentation of the perturbed image with sufficient accuracy. Therefore, exploring methods on how to attack CNN-based models as well as how to defend models against attacks have become a popular topic as this also provides insights into the performance and generalization abilities of CNNs. However, most of the existing work assumes unrealistic attack models, i.e. the resulting attacks were specified in advance. In this paper, we propose a novel approach for generating adversarial examples to attack CNN-based segmentation models for medical images. Our approach has three key features: 1) The generated adversarial examples exhibit anatomical variations (in form of deformations) as well as appearance perturbations; 2) The adversarial examples attack segmentation models so that the Dice scores decrease by a pre-specified amount; 3) The attack is not required to be specified beforehand. We have evaluated our approach on CNN-based approaches for the multi-organ segmentation problem in 2D CT images. We show that the proposed approach can be used to attack different CNN-based segmentation models.
Precise Estimation of Renal Vascular Dominant Regions Using Spatially Aware Fully Convolutional Networks, Tensor-Cut and Voronoi Diagrams
Aug 05, 2019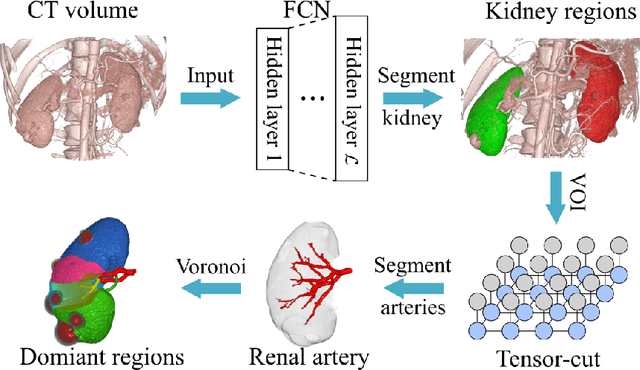
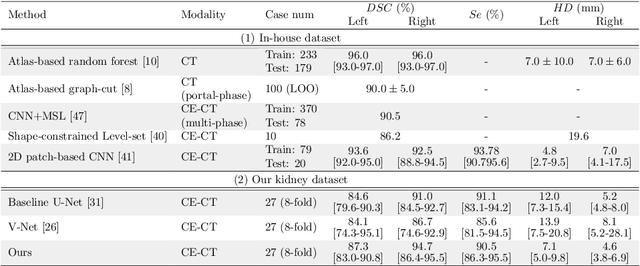

This paper presents a new approach for precisely estimating the renal vascular dominant region using a Voronoi diagram. To provide computer-assisted diagnostics for the pre-surgical simulation of partial nephrectomy surgery, we must obtain information on the renal arteries and the renal vascular dominant regions. We propose a fully automatic segmentation method that combines a neural network and tensor-based graph-cut methods to precisely extract the kidney and renal arteries. First, we use a convolutional neural network to localize the kidney regions and extract tiny renal arteries with a tensor-based graph-cut method. Then we generate a Voronoi diagram to estimate the renal vascular dominant regions based on the segmented kidney and renal arteries. The accuracy of kidney segmentation in 27 cases with 8-fold cross validation reached a Dice score of 95%. The accuracy of renal artery segmentation in 8 cases obtained a centerline overlap ratio of 80%. Each partition region corresponds to a renal vascular dominant region. The final dominant-region estimation accuracy achieved a Dice coefficient of 80%. A clinical application showed the potential of our proposed estimation approach in a real clinical surgical environment. Further validation using large-scale database is our future work.
3D FCN Feature Driven Regression Forest-Based Pancreas Localization and Segmentation
Jun 08, 2018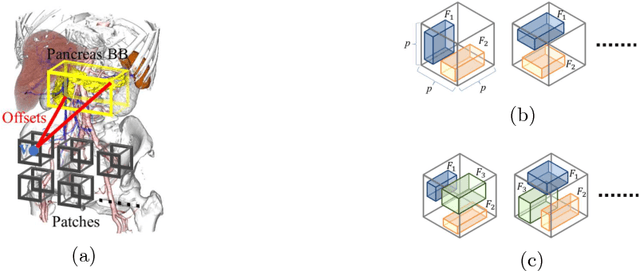
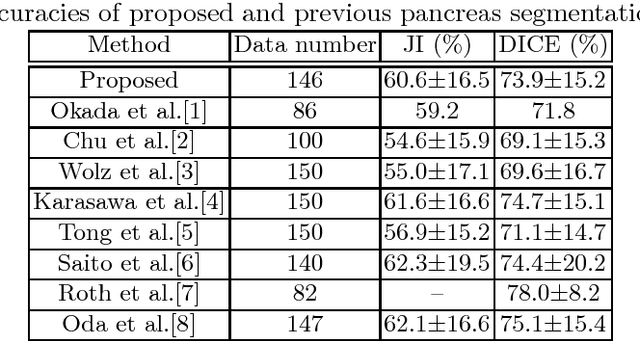
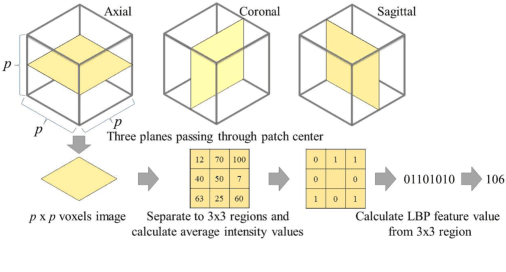
This paper presents a fully automated atlas-based pancreas segmentation method from CT volumes utilizing 3D fully convolutional network (FCN) feature-based pancreas localization. Segmentation of the pancreas is difficult because it has larger inter-patient spatial variations than other organs. Previous pancreas segmentation methods failed to deal with such variations. We propose a fully automated pancreas segmentation method that contains novel localization and segmentation. Since the pancreas neighbors many other organs, its position and size are strongly related to the positions of the surrounding organs. We estimate the position and the size of the pancreas (localized) from global features by regression forests. As global features, we use intensity differences and 3D FCN deep learned features, which include automatically extracted essential features for segmentation. We chose 3D FCN features from a trained 3D U-Net, which is trained to perform multi-organ segmentation. The global features include both the pancreas and surrounding organ information. After localization, a patient-specific probabilistic atlas-based pancreas segmentation is performed. In evaluation results with 146 CT volumes, we achieved 60.6% of the Jaccard index and 73.9% of the Dice overlap.
* Presented in MICCAI 2017 workshop, DLMIA 2017 (Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support)
Machine learning-based colon deformation estimation method for colonoscope tracking
Jun 08, 2018This paper presents a colon deformation estimation method, which can be used to estimate colon deformations during colonoscope insertions. Colonoscope tracking or navigation system that navigates a physician to polyp positions during a colonoscope insertion is required to reduce complications such as colon perforation. A previous colonoscope tracking method obtains a colonoscope position in the colon by registering a colonoscope shape and a colon shape. The colonoscope shape is obtained using an electromagnetic sensor, and the colon shape is obtained from a CT volume. However, large tracking errors were observed due to colon deformations occurred during colonoscope insertions. Such deformations make the registration difficult. Because the colon deformation is caused by a colonoscope, there is a strong relationship between the colon deformation and the colonoscope shape. An estimation method of colon deformations occur during colonoscope insertions is necessary to reduce tracking errors. We propose a colon deformation estimation method. This method is used to estimate a deformed colon shape from a colonoscope shape. We use the regression forests algorithm to estimate a deformed colon shape. The regression forests algorithm is trained using pairs of colon and colonoscope shapes, which contains deformations occur during colonoscope insertions. As a preliminary study, we utilized the method to estimate deformations of a colon phantom. In our experiments, the proposed method correctly estimated deformed colon phantom shapes.
* Accepted paper for oral presentation at SPIE Medical Imaging 2018, Houston, TX, USA
A multi-scale pyramid of 3D fully convolutional networks for abdominal multi-organ segmentation
Jun 06, 2018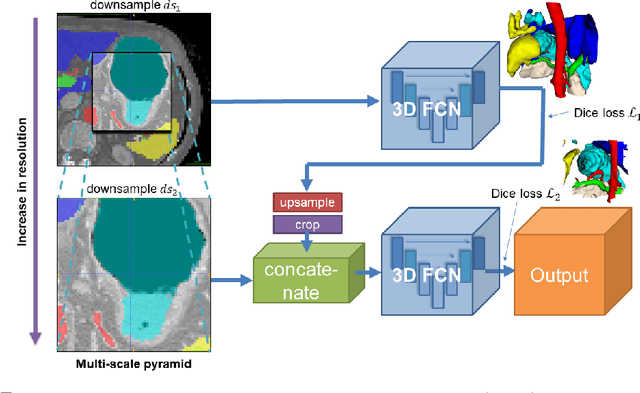
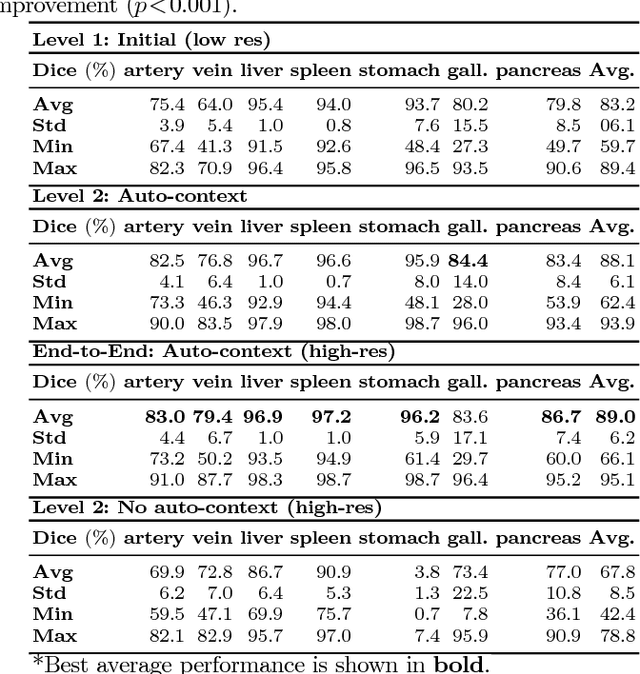
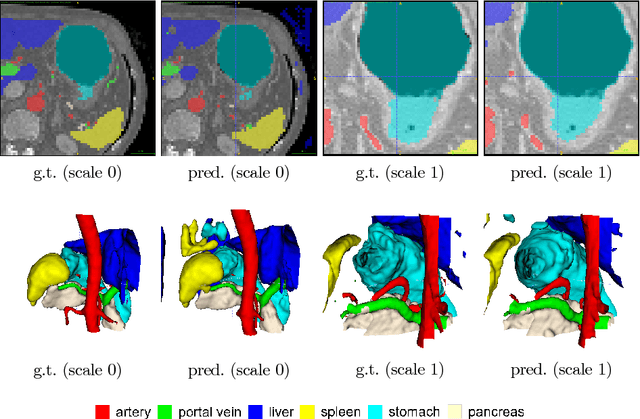
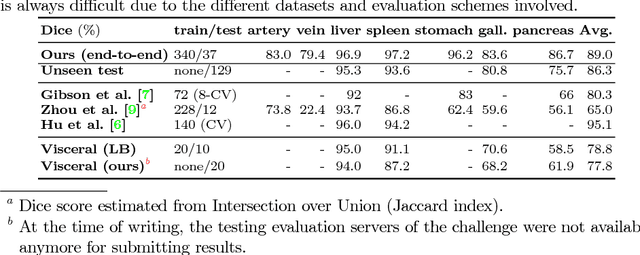
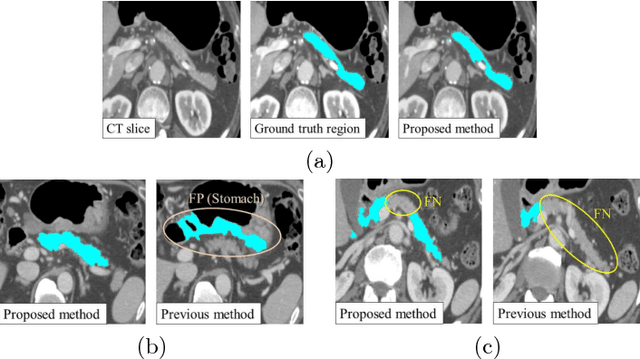
Recent advances in deep learning, like 3D fully convolutional networks (FCNs), have improved the state-of-the-art in dense semantic segmentation of medical images. However, most network architectures require severely downsampling or cropping the images to meet the memory limitations of today's GPU cards while still considering enough context in the images for accurate segmentation. In this work, we propose a novel approach that utilizes auto-context to perform semantic segmentation at higher resolutions in a multi-scale pyramid of stacked 3D FCNs. We train and validate our models on a dataset of manually annotated abdominal organs and vessels from 377 clinical CT images used in gastric surgery, and achieve promising results with close to 90% Dice score on average. For additional evaluation, we perform separate testing on datasets from different sources and achieve competitive results, illustrating the robustness of the model and approach.
Attention U-Net: Learning Where to Look for the Pancreas
May 20, 2018We propose a novel attention gate (AG) model for medical imaging that automatically learns to focus on target structures of varying shapes and sizes. Models trained with AGs implicitly learn to suppress irrelevant regions in an input image while highlighting salient features useful for a specific task. This enables us to eliminate the necessity of using explicit external tissue/organ localisation modules of cascaded convolutional neural networks (CNNs). AGs can be easily integrated into standard CNN architectures such as the U-Net model with minimal computational overhead while increasing the model sensitivity and prediction accuracy. The proposed Attention U-Net architecture is evaluated on two large CT abdominal datasets for multi-class image segmentation. Experimental results show that AGs consistently improve the prediction performance of U-Net across different datasets and training sizes while preserving computational efficiency. The code for the proposed architecture is publicly available.
Unsupervised Segmentation of 3D Medical Images Based on Clustering and Deep Representation Learning
Apr 11, 2018This paper presents a novel unsupervised segmentation method for 3D medical images. Convolutional neural networks (CNNs) have brought significant advances in image segmentation. However, most of the recent methods rely on supervised learning, which requires large amounts of manually annotated data. Thus, it is challenging for these methods to cope with the growing amount of medical images. This paper proposes a unified approach to unsupervised deep representation learning and clustering for segmentation. Our proposed method consists of two phases. In the first phase, we learn deep feature representations of training patches from a target image using joint unsupervised learning (JULE) that alternately clusters representations generated by a CNN and updates the CNN parameters using cluster labels as supervisory signals. We extend JULE to 3D medical images by utilizing 3D convolutions throughout the CNN architecture. In the second phase, we apply k-means to the deep representations from the trained CNN and then project cluster labels to the target image in order to obtain the fully segmented image. We evaluated our methods on three images of lung cancer specimens scanned with micro-computed tomography (micro-CT). The automatic segmentation of pathological regions in micro-CT could further contribute to the pathological examination process. Hence, we aim to automatically divide each image into the regions of invasive carcinoma, noninvasive carcinoma, and normal tissue. Our experiments show the potential abilities of unsupervised deep representation learning for medical image segmentation.
* This paper was presented at SPIE Medical Imaging 2018, Houston, TX, USA