 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Embedding Probes Fail to Generalize Across Learner Corpora
Apr 08, 2026Do multilingual embedding models encode a language-general representation of proficiency? We investigate this by training linear and non-linear probes on hidden-state activations from Qwen3-Embedding (0.6B, 4B, 8B) to predict CEFR proficiency levels from learner texts across nine corpora and seven languages. We compare five probing architectures against a baseline trained on surface-level text features. Under in-distribution evaluation, probes achieve strong performance ($QWK\approx0.7$), substantially outperforming the surface baseline, with middle layers consistently yielding the best predictions. However, in cross-corpus evaluation performance collapses across all probe types and model sizes. Residual analysis reveals that out-of-distribution probes converge towards predicting uniformly distributed labels, indicating that the learned mappings capture corpus-specific distributional properties (topic, language, task type, rating methodology) rather than an abstract, transferable proficiency dimension. These results suggest that current multilingual embeddings do not straightforwardly encode language-general proficiency, with implications for representation-based approaches to proficiency-adaptive language technology.
Is Sentiment Banana-Shaped? Exploring the Geometry and Portability of Sentiment Concept Vectors
Jan 12, 2026Use cases of sentiment analysis in the humanities often require contextualized, continuous scores. Concept Vector Projections (CVP) offer a recent solution: by modeling sentiment as a direction in embedding space, they produce continuous, multilingual scores that align closely with human judgments. Yet the method's portability across domains and underlying assumptions remain underexplored. We evaluate CVP across genres, historical periods, languages, and affective dimensions, finding that concept vectors trained on one corpus transfer well to others with minimal performance loss. To understand the patterns of generalization, we further examine the linearity assumption underlying CVP. Our findings suggest that while CVP is a portable approach that effectively captures generalizable patterns, its linearity assumption is approximate, pointing to potential for further development.
Continuous sentiment scores for literary and multilingual contexts
Aug 20, 2025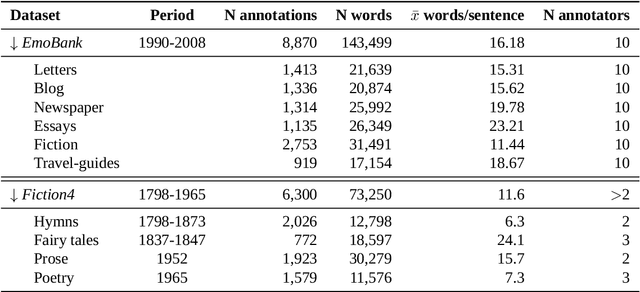



Sentiment Analysis is widely used to quantify sentiment in text, but its application to literary texts poses unique challenges due to figurative language, stylistic ambiguity, as well as sentiment evocation strategies. Traditional dictionary-based tools often underperform, especially for low-resource languages, and transformer models, while promising, typically output coarse categorical labels that limit fine-grained analysis. We introduce a novel continuous sentiment scoring method based on concept vector projection, trained on multilingual literary data, which more effectively captures nuanced sentiment expressions across genres, languages, and historical periods. Our approach outperforms existing tools on English and Danish texts, producing sentiment scores whose distribution closely matches human ratings, enabling more accurate analysis and sentiment arc modeling in literature.