 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Efficient Private Neighbor Generation for Subgraph Federated Learning
Jan 19, 2024Behemoth graphs are often fragmented and separately stored by multiple data owners as distributed subgraphs in many realistic applications. Without harming data privacy, it is natural to consider the subgraph federated learning (subgraph FL) scenario, where each local client holds a subgraph of the entire global graph, to obtain globally generalized graph mining models. To overcome the unique challenge of incomplete information propagation on local subgraphs due to missing cross-subgraph neighbors, previous works resort to the augmentation of local neighborhoods through the joint FL of missing neighbor generators and GNNs. Yet their technical designs have profound limitations regarding the utility, efficiency, and privacy goals of FL. In this work, we propose FedDEP to comprehensively tackle these challenges in subgraph FL. FedDEP consists of a series of novel technical designs: (1) Deep neighbor generation through leveraging the GNN embeddings of potential missing neighbors; (2) Efficient pseudo-FL for neighbor generation through embedding prototyping; and (3) Privacy protection through noise-less edge-local-differential-privacy. We analyze the correctness and efficiency of FedDEP, and provide theoretical guarantees on its privacy. Empirical results on four real-world datasets justify the clear benefits of proposed techniques.
ASPEN: High-Throughput LoRA Fine-Tuning of Large Language Models with a Single GPU
Dec 05, 2023

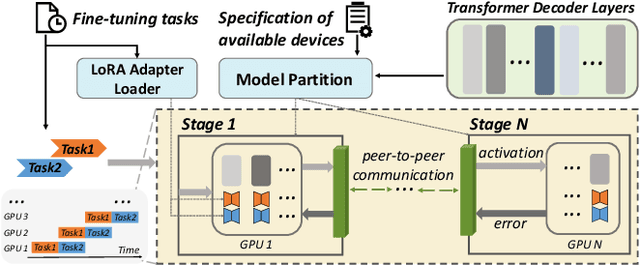
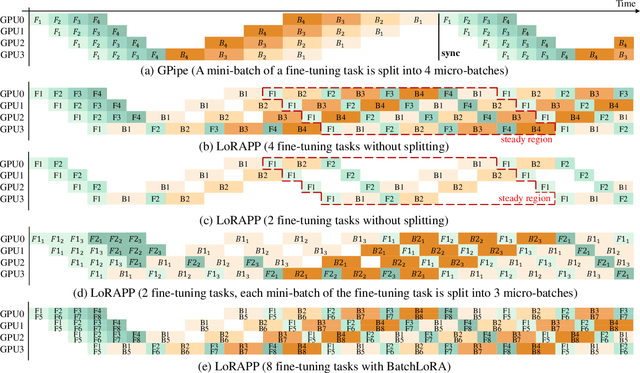
Transformer-based large language models (LLMs) have demonstrated outstanding performance across diverse domains, particularly when fine-turned for specific domains. Recent studies suggest that the resources required for fine-tuning LLMs can be economized through parameter-efficient methods such as Low-Rank Adaptation (LoRA). While LoRA effectively reduces computational burdens and resource demands, it currently supports only a single-job fine-tuning setup. In this paper, we present ASPEN, a high-throughput framework for fine-tuning LLMs. ASPEN efficiently trains multiple jobs on a single GPU using the LoRA method, leveraging shared pre-trained model and adaptive scheduling. ASPEN is compatible with transformer-based language models like LLaMA and ChatGLM, etc. Experiments show that ASPEN saves 53% of GPU memory when training multiple LLaMA-7B models on NVIDIA A100 80GB GPU and boosts training throughput by about 17% compared to existing methods when training with various pre-trained models on different GPUs. The adaptive scheduling algorithm reduces turnaround time by 24%, end-to-end training latency by 12%, prioritizing jobs and preventing out-of-memory issues.
AGD: an Auto-switchable Optimizer using Stepwise Gradient Difference for Preconditioning Matrix
Dec 04, 2023



Adaptive optimizers, such as Adam, have achieved remarkable success in deep learning. A key component of these optimizers is the so-called preconditioning matrix, providing enhanced gradient information and regulating the step size of each gradient direction. In this paper, we propose a novel approach to designing the preconditioning matrix by utilizing the gradient difference between two successive steps as the diagonal elements. These diagonal elements are closely related to the Hessian and can be perceived as an approximation of the inner product between the Hessian row vectors and difference of the adjacent parameter vectors. Additionally, we introduce an auto-switching function that enables the preconditioning matrix to switch dynamically between Stochastic Gradient Descent (SGD) and the adaptive optimizer. Based on these two techniques, we develop a new optimizer named AGD that enhances the generalization performance. We evaluate AGD on public datasets of Natural Language Processing (NLP), Computer Vision (CV), and Recommendation Systems (RecSys). Our experimental results demonstrate that AGD outperforms the state-of-the-art (SOTA) optimizers, achieving highly competitive or significantly better predictive performance. Furthermore, we analyze how AGD is able to switch automatically between SGD and the adaptive optimizer and its actual effects on various scenarios. The code is available at https://github.com/intelligent-machine-learning/dlrover/tree/master/atorch/atorch/optimizers.
Developing a Novel Image Marker to Predict the Responses of Neoadjuvant Chemotherapy for Ovarian Cancer Patients
Sep 13, 2023Objective: Neoadjuvant chemotherapy (NACT) is one kind of treatment for advanced stage ovarian cancer patients. However, due to the nature of tumor heterogeneity, the patients' responses to NACT varies significantly among different subgroups. To address this clinical challenge, the purpose of this study is to develop a novel image marker to achieve high accuracy response prediction of the NACT at an early stage. Methods: For this purpose, we first computed a total of 1373 radiomics features to quantify the tumor characteristics, which can be grouped into three categories: geometric, intensity, and texture features. Second, all these features were optimized by principal component analysis algorithm to generate a compact and informative feature cluster. Using this cluster as the input, an SVM based classifier was developed and optimized to create a final marker, indicating the likelihood of the patient being responsive to the NACT treatment. To validate this scheme, a total of 42 ovarian cancer patients were retrospectively collected. A nested leave-one-out cross-validation was adopted for model performance assessment. Results: The results demonstrate that the new method yielded an AUC (area under the ROC [receiver characteristic operation] curve) of 0.745. Meanwhile, the model achieved overall accuracy of 76.2%, positive predictive value of 70%, and negative predictive value of 78.1%. Conclusion: This study provides meaningful information for the development of radiomics based image markers in NACT response prediction.
ImGeoNet: Image-induced Geometry-aware Voxel Representation for Multi-view 3D Object Detection
Aug 17, 2023



We propose ImGeoNet, a multi-view image-based 3D object detection framework that models a 3D space by an image-induced geometry-aware voxel representation. Unlike previous methods which aggregate 2D features into 3D voxels without considering geometry, ImGeoNet learns to induce geometry from multi-view images to alleviate the confusion arising from voxels of free space, and during the inference phase, only images from multiple views are required. Besides, a powerful pre-trained 2D feature extractor can be leveraged by our representation, leading to a more robust performance. To evaluate the effectiveness of ImGeoNet, we conduct quantitative and qualitative experiments on three indoor datasets, namely ARKitScenes, ScanNetV2, and ScanNet200. The results demonstrate that ImGeoNet outperforms the current state-of-the-art multi-view image-based method, ImVoxelNet, on all three datasets in terms of detection accuracy. In addition, ImGeoNet shows great data efficiency by achieving results comparable to ImVoxelNet with 100 views while utilizing only 40 views. Furthermore, our studies indicate that our proposed image-induced geometry-aware representation can enable image-based methods to attain superior detection accuracy than the seminal point cloud-based method, VoteNet, in two practical scenarios: (1) scenarios where point clouds are sparse and noisy, such as in ARKitScenes, and (2) scenarios involve diverse object classes, particularly classes of small objects, as in the case in ScanNet200.
ReCLIP: Refine Contrastive Language Image Pre-Training with Source Free Domain Adaptation
Aug 04, 2023



Large-scale Pre-Training Vision-Language Model such as CLIP has demonstrated outstanding performance in zero-shot classification, e.g. achieving 76.3% top-1 accuracy on ImageNet without seeing any example, which leads to potential benefits to many tasks that have no labeled data. However, while applying CLIP to a downstream target domain, the presence of visual and text domain gaps and cross-modality misalignment can greatly impact the model performance. To address such challenges, we propose ReCLIP, the first source-free domain adaptation method for vision-language models, which does not require any source data or target labeled data. ReCLIP first learns a projection space to mitigate the misaligned visual-text embeddings and learns pseudo labels, and then deploys cross-modality self-training with the pseudo labels, to update visual and text encoders, refine labels and reduce domain gaps and misalignments iteratively. With extensive experiments, we demonstrate ReCLIP reduces the average error rate of CLIP from 30.17% to 25.06% on 22 image classification benchmarks.
Spatio-Temporal Classification of Lung Ventilation Patterns using 3D EIT Images: A General Approach for Individualized Lung Function Evaluation
Jul 01, 2023The Pulmonary Function Test (PFT) is an widely utilized and rigorous classification test for lung function evaluation, serving as a comprehensive tool for lung diagnosis. Meanwhile, Electrical Impedance Tomography (EIT) is a rapidly advancing clinical technique that visualizes conductivity distribution induced by ventilation. EIT provides additional spatial and temporal information on lung ventilation beyond traditional PFT. However, relying solely on conventional isolated interpretations of PFT results and EIT images overlooks the continuous dynamic aspects of lung ventilation. This study aims to classify lung ventilation patterns by extracting spatial and temporal features from the 3D EIT image series. The study uses a Variational Autoencoder network with a MultiRes block to compress the spatial distribution in a 3D image into a one-dimensional vector. These vectors are then concatenated to create a feature map for the exhibition of temporal features. A simple convolutional neural network is used for classification. Data collected from 137 subjects were finally used for training. The model is validated by ten-fold and leave-one-out cross-validation first. The accuracy and sensitivity of normal ventilation mode are 0.95 and 1.00, and the f1-score is 0.94. Furthermore, we check the reliability and feasibility of the proposed pipeline by testing it on newly recruited nine subjects. Our results show that the pipeline correctly predicts the ventilation mode of 8 out of 9 subjects. The study demonstrates the potential of using image series for lung ventilation mode classification, providing a feasible method for patient prescreening and presenting an alternative form of PFT.
Sharpness-Aware Minimization Revisited: Weighted Sharpness as a Regularization Term
May 25, 2023



Deep Neural Networks (DNNs) generalization is known to be closely related to the flatness of minima, leading to the development of Sharpness-Aware Minimization (SAM) for seeking flatter minima and better generalization. In this paper, we revisit the loss of SAM and propose a more general method, called WSAM, by incorporating sharpness as a regularization term. We prove its generalization bound through the combination of PAC and Bayes-PAC techniques, and evaluate its performance on various public datasets. The results demonstrate that WSAM achieves improved generalization, or is at least highly competitive, compared to the vanilla optimizer, SAM and its variants. The code is available at https://github.com/intelligent-machine-learning/dlrover/tree/master/atorch/atorch/optimizers.
Multi-task Paired Masking with Alignment Modeling for Medical Vision-Language Pre-training
May 13, 2023



In recent years, the growing demand for medical imaging diagnosis has brought a significant burden to radiologists. The existing Med-VLP methods provide a solution for automated medical image analysis which learns universal representations from large-scale medical images and reports and benefits downstream tasks without requiring fine-grained annotations. However, the existing methods based on joint image-text reconstruction neglect the importance of cross-modal alignment in conjunction with joint reconstruction, resulting in inadequate cross-modal interaction. In this paper, we propose a unified Med-VLP framework based on Multi-task Paired Masking with Alignment (MPMA) to integrate the cross-modal alignment task into the joint image-text reconstruction framework to achieve more comprehensive cross-modal interaction, while a global and local alignment (GLA) module is designed to assist self-supervised paradigm in obtaining semantic representations with rich domain knowledge. To achieve more comprehensive cross-modal fusion, we also propose a Memory-Augmented Cross-Modal Fusion (MA-CMF) module to fully integrate visual features to assist in the process of report reconstruction. Experimental results show that our approach outperforms previous methods over all downstream tasks, including uni-modal, cross-modal and multi-modal tasks.
Predict NAS Multi-Task by Stacking Ensemble Models using GP-NAS
May 02, 2023Accurately predicting the performance of architecture with small sample training is an important but not easy task. How to analysis and train dataset to overcome overfitting is the core problem we should deal with. Meanwhile if there is the mult-task problem, we should also think about if we can take advantage of their correlation and estimate as fast as we can. In this track, Super Network builds a search space based on ViT-Base. The search space contain depth, num-heads, mpl-ratio and embed-dim. What we done firstly are pre-processing the data based on our understanding of this problem which can reduce complexity of problem and probability of over fitting. Then we tried different kind of models and different way to combine them. Finally we choose stacking ensemble models using GP-NAS with cross validation. Our stacking model ranked 1st in CVPR 2022 Track 2 Challenge.