 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Sequence Modeling: Development and Applications in Asset Pricing
Aug 20, 2021We predict asset returns and measure risk premia using a prominent technique from artificial intelligence -- deep sequence modeling. Because asset returns often exhibit sequential dependence that may not be effectively captured by conventional time series models, sequence modeling offers a promising path with its data-driven approach and superior performance. In this paper, we first overview the development of deep sequence models, introduce their applications in asset pricing, and discuss their advantages and limitations. We then perform a comparative analysis of these methods using data on U.S. equities. We demonstrate how sequence modeling benefits investors in general through incorporating complex historical path dependence, and that Long- and Short-term Memory (LSTM) based models tend to have the best out-of-sample performance.
Active Reinforcement Learning over MDPs
Aug 17, 2021



The past decade has seen the rapid development of Reinforcement Learning, which acquires impressive performance with numerous training resources. However, one of the greatest challenges in RL is generalization efficiency (i.e., generalization performance in a unit time). This paper proposes a framework of Active Reinforcement Learning (ARL) over MDPs to improve generalization efficiency in a limited resource by instance selection. Given a number of instances, the algorithm chooses out valuable instances as training sets while training the policy, thereby costing fewer resources. Unlike existing approaches, we attempt to actively select and use training data rather than train on all the given data, thereby costing fewer resources. Furthermore, we introduce a general instance evaluation metrics and selection mechanism into the framework. Experiments results reveal that the proposed framework with Proximal Policy Optimization as policy optimizer can effectively improve generalization efficiency than unselect-ed and unbiased selected methods.
Multi-Domain Active Learning: A Comparative Study
Jun 25, 2021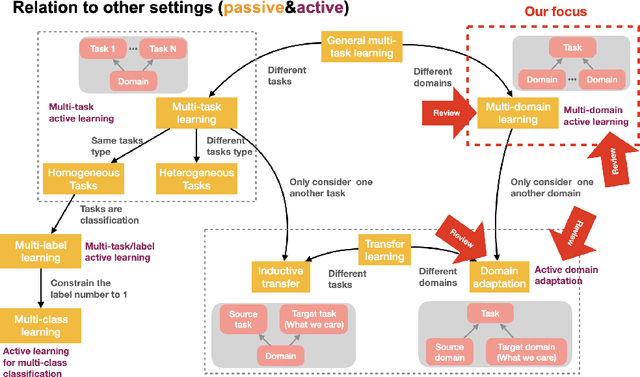
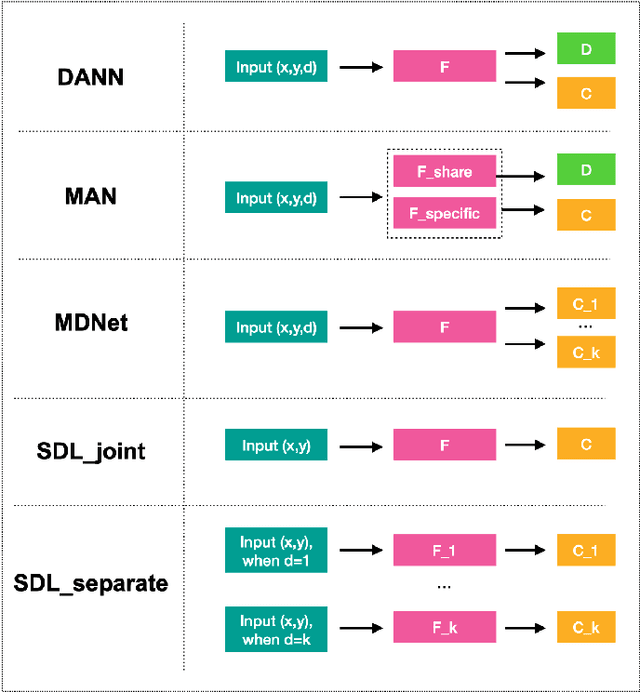
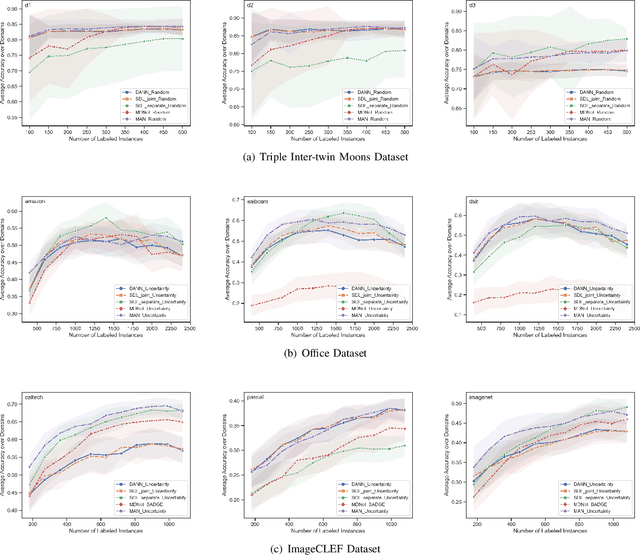
Building classifiers on multiple domains is a practical problem in the real life. Instead of building classifiers one by one, multi-domain learning (MDL) simultaneously builds classifiers on multiple domains. MDL utilizes the information shared among the domains to improve the performance. As a supervised learning problem, the labeling effort is still high in MDL problems. Usually, this high labeling cost issue could be relieved by using active learning. Thus, it is natural to utilize active learning to reduce the labeling effort in MDL, and we refer this setting as multi-domain active learning (MDAL). However, there are only few works which are built on this setting. And when the researches have to face this problem, there is no off-the-shelf solutions. Under this circumstance, combining the current multi-domain learning models and single-domain active learning strategies might be a preliminary solution for MDAL problem. To find out the potential of this preliminary solution, a comparative study over 5 models and 4 selection strategies is made in this paper. To the best of our knowledge, this is the first work provides the formal definition of MDAL. Besides, this is the first comparative work for MDAL problem. From the results, the Multinomial Adversarial Networks (MAN) model with a simple best vs second best (BvSB) uncertainty strategy shows its superiority in most cases. We take this combination as our off-the-shelf recommendation for the MDAL problem.
Robust Dynamic Network Embedding via Ensembles
May 30, 2021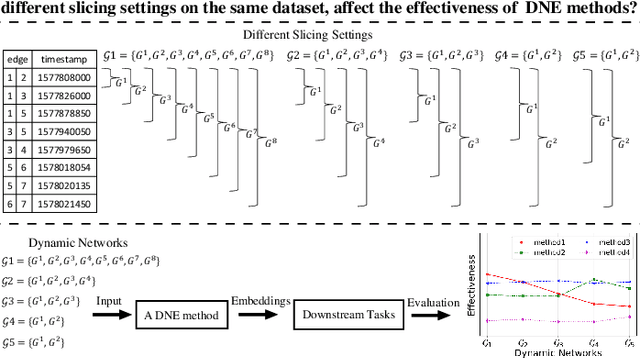
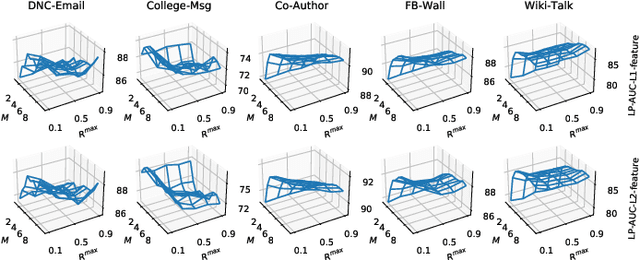
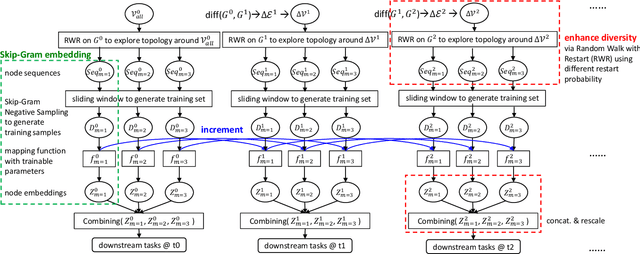
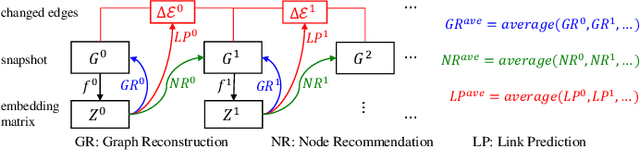
Dynamic Network Embedding (DNE) has recently attracted considerable attention due to the advantage of network embedding in various applications and the dynamic nature of many real-world networks. For dynamic networks, the degree of changes, i.e., defined as the averaged number of changed edges between consecutive snapshots spanning a dynamic network, could be very different in real-world scenarios. Although quite a few DNE methods have been proposed, it still remains unclear that whether and to what extent the existing DNE methods are robust to the degree of changes, which is however an important factor in both academic research and industrial applications. In this work, we investigate the robustness issue of DNE methods w.r.t. the degree of changes for the first time and accordingly, propose a robust DNE method. Specifically, the proposed method follows the notion of ensembles where the base learner adopts an incremental Skip-Gram neural embedding approach. To further boost the performance, a novel strategy is proposed to enhance the diversity among base learners at each timestep by capturing different levels of local-global topology. Extensive experiments demonstrate the benefits of special designs in the proposed method, and the superior performance of the proposed method compared to state-of-the-art methods. The comparative study also reveals the robustness issue of some DNE methods. The source code is available at https://github.com/houchengbin/SG-EDNE
Multi-objective Evolutionary Algorithms are Generally Good: Maximizing Monotone Submodular Functions over Sequences
Apr 20, 2021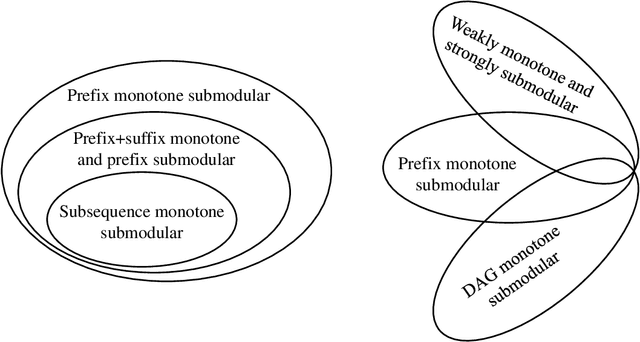

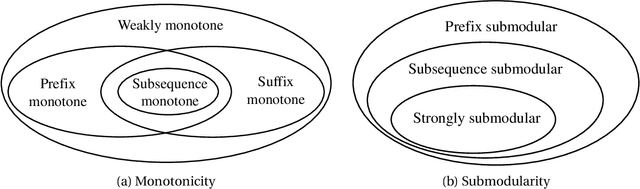

Evolutionary algorithms (EAs) are general-purpose optimization algorithms, inspired by natural evolution. Recent theoretical studies have shown that EAs can achieve good approximation guarantees for solving the problem classes of submodular optimization, which have a wide range of applications, such as maximum coverage, sparse regression, influence maximization, document summarization and sensor placement, just to name a few. Though they have provided some theoretical explanation for the general-purpose nature of EAs, the considered submodular objective functions are defined only over sets or multisets. To complement this line of research, this paper studies the problem class of maximizing monotone submodular functions over sequences, where the objective function depends on the order of items. We prove that for each kind of previously studied monotone submodular objective functions over sequences, i.e., prefix monotone submodular functions, weakly monotone and strongly submodular functions, and DAG monotone submodular functions, a simple multi-objective EA, i.e., GSEMO, can always reach or improve the best known approximation guarantee after running polynomial time in expectation. Note that these best-known approximation guarantees can be obtained only by different greedy-style algorithms before. Empirical studies on various applications, e.g., accomplishing tasks, maximizing information gain, search-and-tracking and recommender systems, show the excellent performance of the GSEMO.
A New Knowledge Gradient-based Method for Constrained Bayesian Optimization
Jan 20, 2021Black-box problems are common in real life like structural design, drug experiments, and machine learning. When optimizing black-box systems, decision-makers always consider multiple performances and give the final decision by comprehensive evaluations. Motivated by such practical needs, we focus on constrained black-box problems where the objective and constraints lack known special structure, and evaluations are expensive and even with noise. We develop a novel constrained Bayesian optimization approach based on the knowledge gradient method ($c-\rm{KG}$). A new acquisition function is proposed to determine the next batch of samples considering optimality and feasibility. An unbiased estimator of the gradient of the new acquisition function is derived to implement the $c-\rm{KG}$ approach.
A Survey on Neural Network Interpretability
Dec 28, 2020
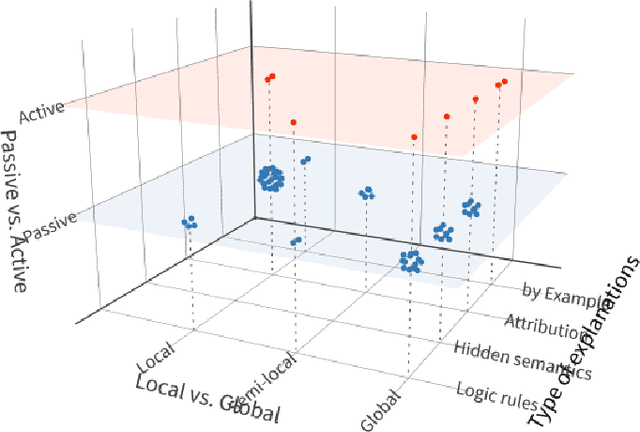
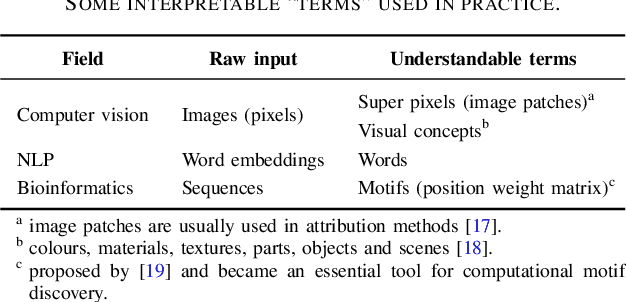
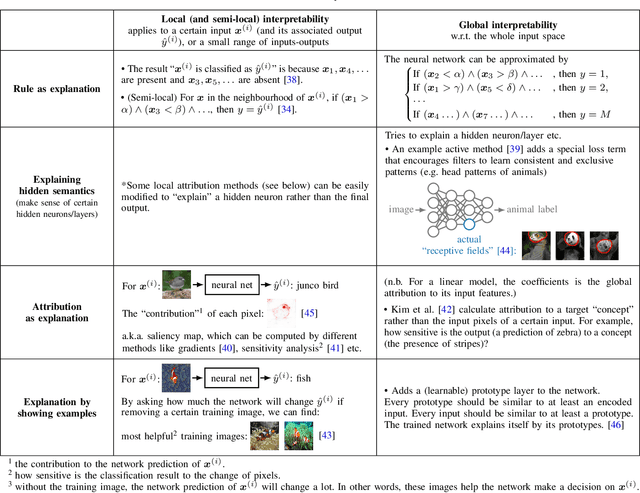
Along with the great success of deep neural networks, there is also growing concern about their black-box nature. The interpretability issue affects people's trust on deep learning systems. It is also related to many ethical problems, e.g., algorithmic discrimination. Moreover, interpretability is a desired property for deep networks to become powerful tools in other research fields, e.g., drug discovery and genomics. In this survey, we conduct a comprehensive review of the neural network interpretability research. We first clarify the definition of interpretability as it has been used in many different contexts. Then we elaborate on the importance of interpretability and propose a novel taxonomy organized along three dimensions: type of engagement (passive vs. active interpretation approaches), the type of explanation, and the focus (from local to global interpretability). This taxonomy provides a meaningful 3D view of distribution of papers from the relevant literature as two of the dimensions are not simply categorical but allow ordinal subcategories. Finally, we summarize the existing interpretability evaluation methods and suggest possible research directions inspired by our new taxonomy.
Memetic Search for Vehicle Routing with Simultaneous Pickup-Delivery and Time Windows
Nov 19, 2020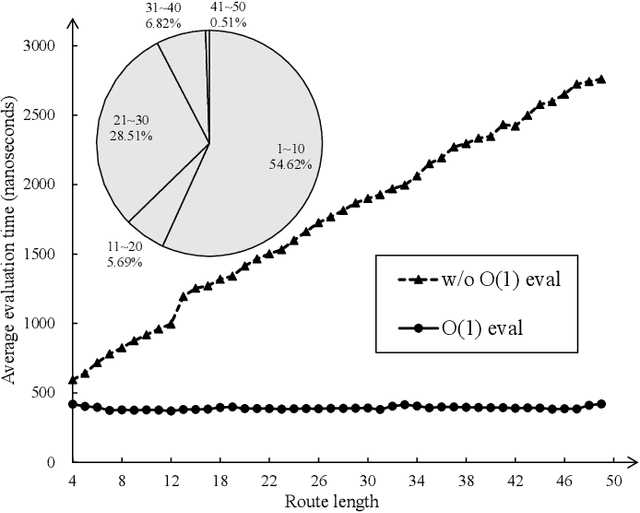
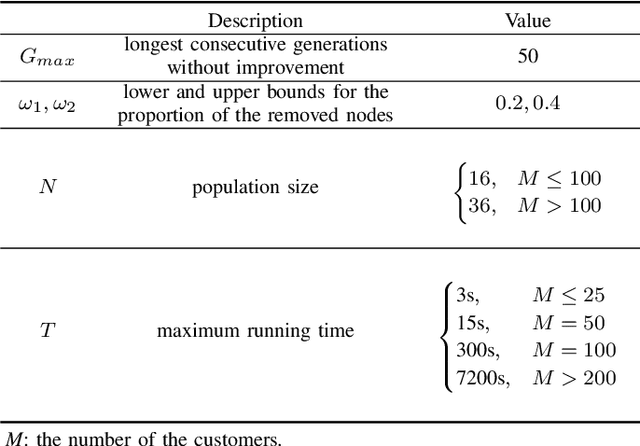
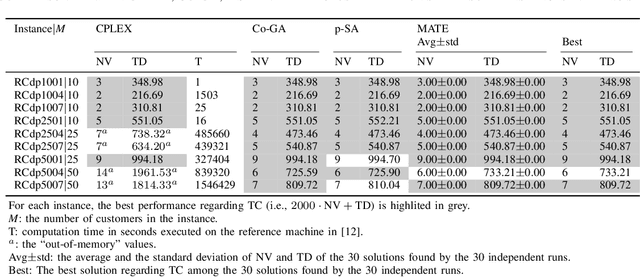
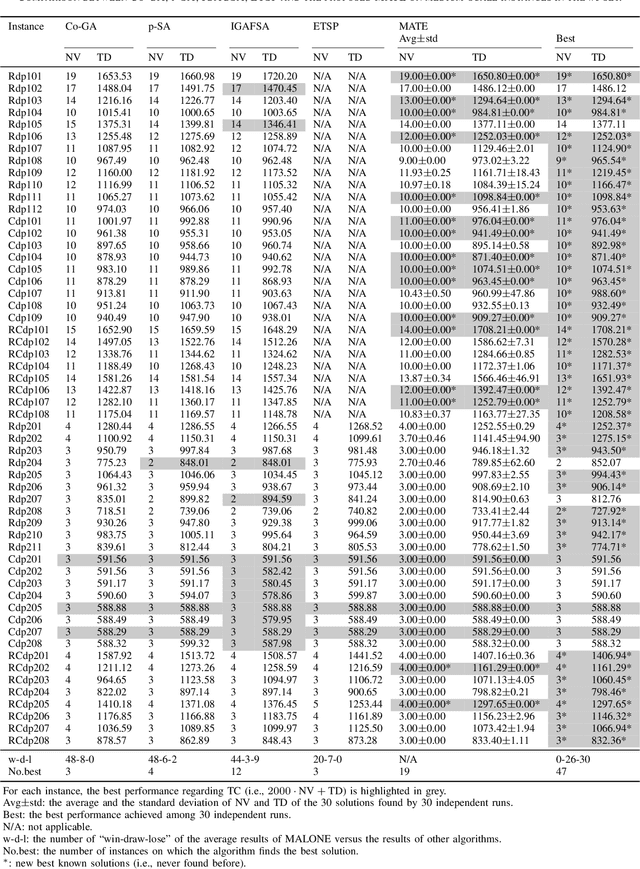
The vehicle routing problem with simultaneous pickup-delivery and time windows (VRPSPDTW) has attracted much attention in the last decade, due to its wide application in modern logistics involving bi-directional flow of goods. In this paper, we propose a memetic algorithm with efficient local search and extended neighborhood, dubbed MATE, for solving this problem. The novelty of MATE lies in three aspects: 1) an initialization procedure which integrates an existing heuristic into the population-based search framework, in an intelligent way; 2) a new crossover involving route inheritance and regret-based node reinsertion; 3) a highly-effective local search procedure which could flexibly search in a large neighborhood by switching between move operators with different step sizes, while keeping low computational complexity. Experimental results on public benchmark show that MATE consistently outperforms all the state-of-the-art algorithms, and notably, finds new best-known solutions on 44 instances (65 instances in total). A new benchmark of large-scale instances, derived from a real-world application of the JD logistics, is also introduced, which could serve as a new and more practical test set for future research.
Interpreting Deep Learning Model Using Rule-based Method
Oct 15, 2020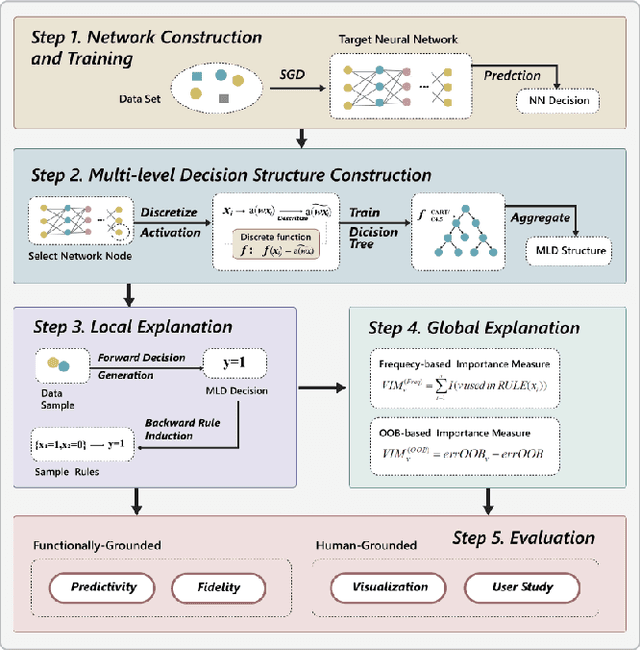
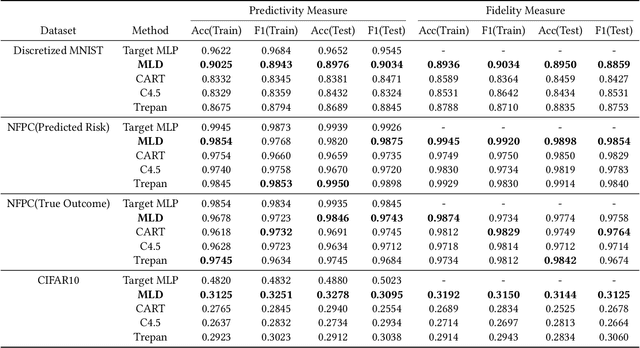
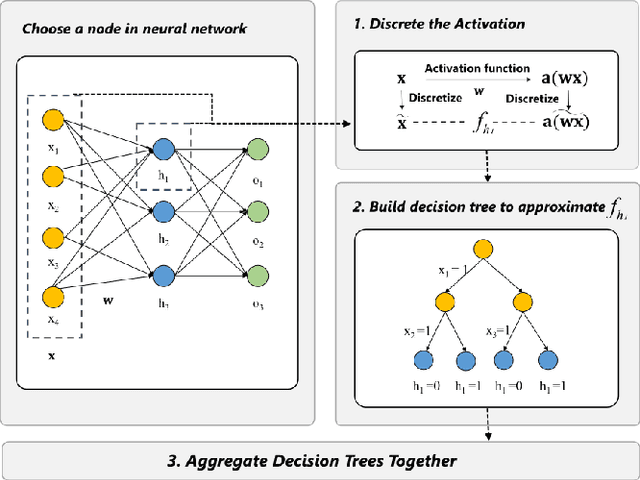
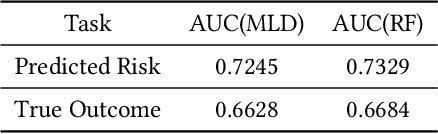
Deep learning models are favored in many research and industry areas and have reached the accuracy of approximating or even surpassing human level. However they've long been considered by researchers as black-box models for their complicated nonlinear property. In this paper, we propose a multi-level decision framework to provide comprehensive interpretation for the deep neural network model. In this multi-level decision framework, by fitting decision trees for each neuron and aggregate them together, a multi-level decision structure (MLD) is constructed at first, which can approximate the performance of the target neural network model with high efficiency and high fidelity. In terms of local explanation for sample, two algorithms are proposed based on MLD structure: forward decision generation algorithm for providing sample decisions, and backward rule induction algorithm for extracting sample rule-mapping recursively. For global explanation, frequency-based and out-of-bag based methods are proposed to extract important features in the neural network decision. Furthermore, experiments on the MNIST and National Free Pre-Pregnancy Check-up (NFPC) dataset are carried out to demonstrate the effectiveness and interpretability of MLD framework. In the evaluation process, both functionally-grounded and human-grounded methods are used to ensure credibility.
Evolutionary Reinforcement Learning via Cooperative Coevolutionary Negatively Correlated Search
Sep 08, 2020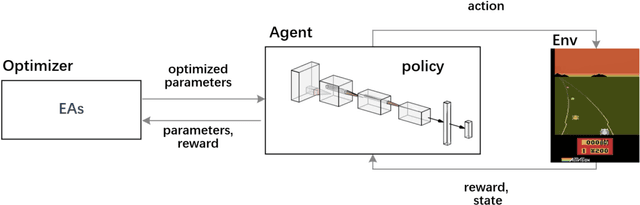
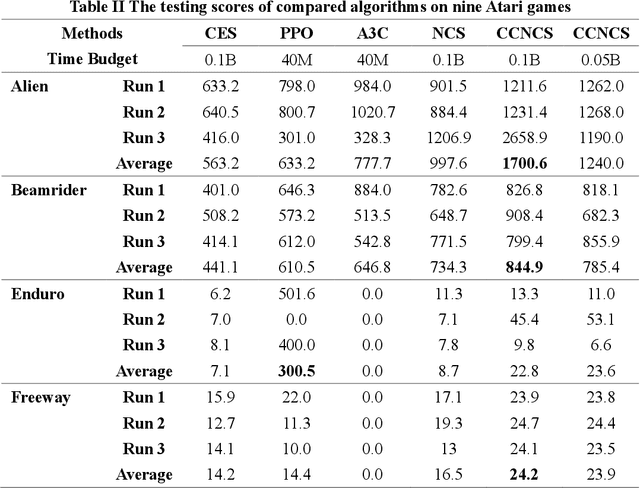
Evolutionary algorithms (EAs) have been successfully applied to optimize the policies for Reinforcement Learning (RL) tasks due to their exploration ability. The recently proposed Negatively Correlated Search (NCS) provides a distinct parallel exploration search behavior and is expected to facilitate RL more effectively. Considering that the commonly adopted neural policies usually involves millions of parameters to be optimized, the direct application of NCS to RL may face a great challenge of the large-scale search space. To address this issue, this paper presents an NCS-friendly Cooperative Coevolution (CC) framework to scale-up NCS while largely preserving its parallel exploration search behavior. The issue of traditional CC that can deteriorate NCS is also discussed. Empirical studies on 10 popular Atari games show that the proposed method can significantly outperform three state-of-the-art deep RL methods with 50% less computational time by effectively exploring a 1.7 million-dimensional search space.