 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM Agents for Earth Observation
Apr 16, 2025Earth Observation (EO) provides critical planetary data for environmental monitoring, disaster management, climate science, and other scientific domains. Here we ask: Are AI systems ready for reliable Earth Observation? We introduce \datasetnamenospace, a benchmark of 140 yes/no questions from NASA Earth Observatory articles across 13 topics and 17 satellite sensors. Using Google Earth Engine API as a tool, LLM agents can only achieve an accuracy of 33% because the code fails to run over 58% of the time. We improve the failure rate for open models by fine-tuning synthetic data, allowing much smaller models (Llama-3.1-8B) to achieve comparable accuracy to much larger ones (e.g., DeepSeek-R1). Taken together, our findings identify significant challenges to be solved before AI agents can automate earth observation, and suggest paths forward. The project page is available at https://iandrover.github.io/UnivEarth.
AllClear: A Comprehensive Dataset and Benchmark for Cloud Removal in Satellite Imagery
Oct 31, 2024



Clouds in satellite imagery pose a significant challenge for downstream applications. A major challenge in current cloud removal research is the absence of a comprehensive benchmark and a sufficiently large and diverse training dataset. To address this problem, we introduce the largest public dataset -- $\textit{AllClear}$ for cloud removal, featuring 23,742 globally distributed regions of interest (ROIs) with diverse land-use patterns, comprising 4 million images in total. Each ROI includes complete temporal captures from the year 2022, with (1) multi-spectral optical imagery from Sentinel-2 and Landsat 8/9, (2) synthetic aperture radar (SAR) imagery from Sentinel-1, and (3) auxiliary remote sensing products such as cloud masks and land cover maps. We validate the effectiveness of our dataset by benchmarking performance, demonstrating the scaling law -- the PSNR rises from $28.47$ to $33.87$ with $30\times$ more data, and conducting ablation studies on the temporal length and the importance of individual modalities. This dataset aims to provide comprehensive coverage of the Earth's surface and promote better cloud removal results.
Scale-Aware Recognition in Satellite Images under Resource Constraint
Oct 31, 2024



Recognition of features in satellite imagery (forests, swimming pools, etc.) depends strongly on the spatial scale of the concept and therefore the resolution of the images. This poses two challenges: Which resolution is best suited for recognizing a given concept, and where and when should the costlier higher-resolution (HR) imagery be acquired? We present a novel scheme to address these challenges by introducing three components: (1) A technique to distill knowledge from models trained on HR imagery to recognition models that operate on imagery of lower resolution (LR), (2) a sampling strategy for HR imagery based on model disagreement, and (3) an LLM-based approach for inferring concept "scale". With these components we present a system to efficiently perform scale-aware recognition in satellite imagery, improving accuracy over single-scale inference while following budget constraints. Our novel approach offers up to a 26.3% improvement over entirely HR baselines, using 76.3% fewer HR images.
Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment
Dec 12, 2023We introduce a method to train vision-language models for remote-sensing images without using any textual annotations. Our key insight is to use co-located internet imagery taken on the ground as an intermediary for connecting remote-sensing images and language. Specifically, we train an image encoder for remote sensing images to align with the image encoder of CLIP using a large amount of paired internet and satellite images. Our unsupervised approach enables the training of a first-of-its-kind large-scale vision language model (VLM) for remote sensing images at two different resolutions. We show that these VLMs enable zero-shot, open-vocabulary image classification, retrieval, segmentation and visual question answering for satellite images. On each of these tasks, our VLM trained without textual annotations outperforms existing VLMs trained with supervision, with gains of up to 20% for classification and 80% for segmentation.
Activation Regression for Continuous Domain Generalization with Applications to Crop Classification
Apr 14, 2022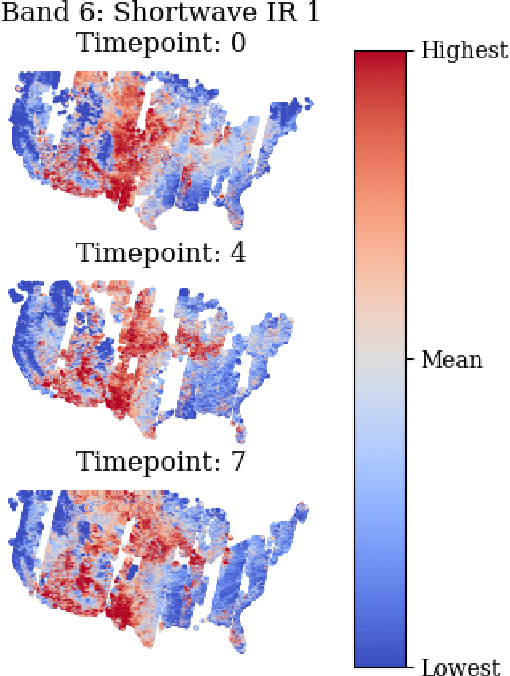
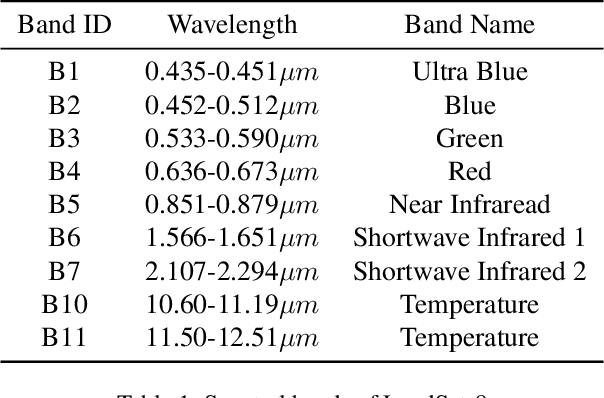
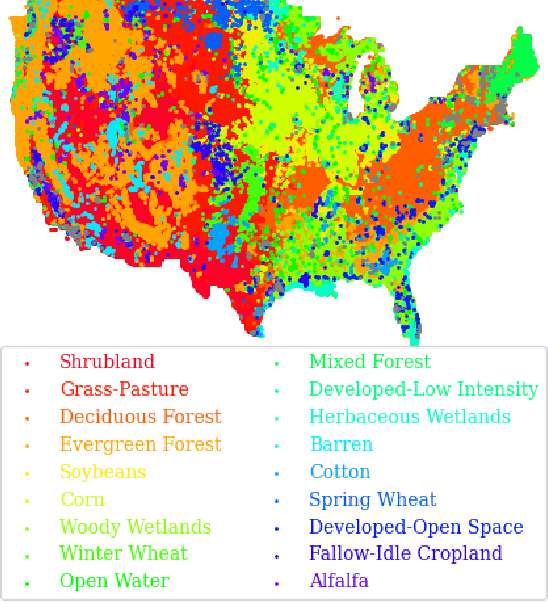
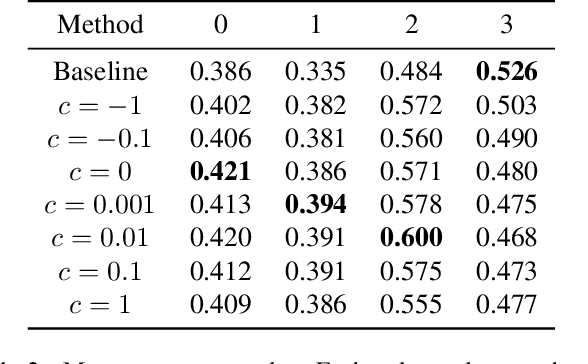
Geographic variance in satellite imagery impacts the ability of machine learning models to generalise to new regions. In this paper, we model geographic generalisation in medium resolution Landsat-8 satellite imagery as a continuous domain adaptation problem, demonstrating how models generalise better with appropriate domain knowledge. We develop a dataset spatially distributed across the entire continental United States, providing macroscopic insight into the effects of geography on crop classification in multi-spectral and temporally distributed satellite imagery. Our method demonstrates improved generalisability from 1) passing geographically correlated climate variables along with the satellite data to a Transformer model and 2) regressing on the model features to reconstruct these domain variables. Combined, we provide a novel perspective on geographic generalisation in satellite imagery and a simple-yet-effective approach to leverage domain knowledge. Code is available at: \url{https://github.com/samar-khanna/cropmap}
AutoPhoto: Aesthetic Photo Capture using Reinforcement Learning
Sep 21, 2021
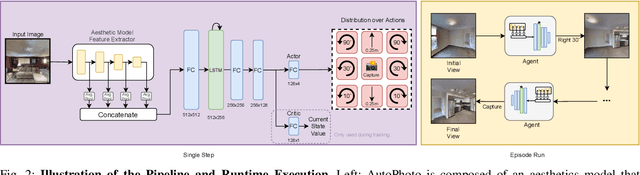


The process of capturing a well-composed photo is difficult and it takes years of experience to master. We propose a novel pipeline for an autonomous agent to automatically capture an aesthetic photograph by navigating within a local region in a scene. Instead of classical optimization over heuristics such as the rule-of-thirds, we adopt a data-driven aesthetics estimator to assess photo quality. A reinforcement learning framework is used to optimize the model with respect to the learned aesthetics metric. We train our model in simulation with indoor scenes, and we demonstrate that our system can capture aesthetic photos in both simulation and real world environments on a ground robot. To our knowledge, this is the first system that can automatically explore an environment to capture an aesthetic photo with respect to a learned aesthetic estimator.
Field-Guide-Inspired Zero-Shot Learning
Aug 24, 2021
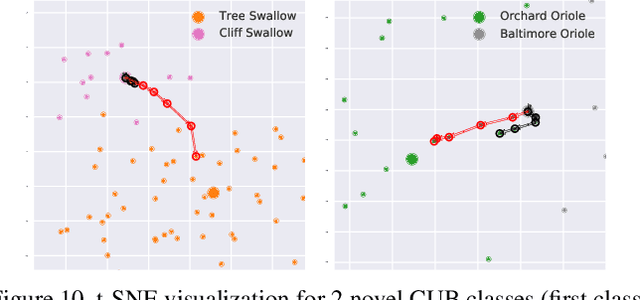
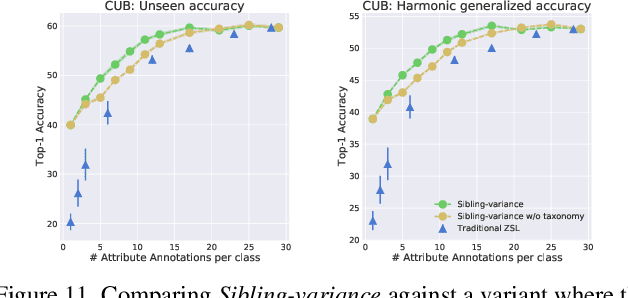
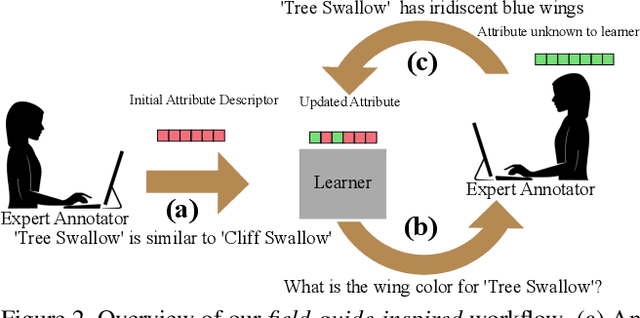
Modern recognition systems require large amounts of supervision to achieve accuracy. Adapting to new domains requires significant data from experts, which is onerous and can become too expensive. Zero-shot learning requires an annotated set of attributes for a novel category. Annotating the full set of attributes for a novel category proves to be a tedious and expensive task in deployment. This is especially the case when the recognition domain is an expert domain. We introduce a new field-guide-inspired approach to zero-shot annotation where the learner model interactively asks for the most useful attributes that define a class. We evaluate our method on classification benchmarks with attribute annotations like CUB, SUN, and AWA2 and show that our model achieves the performance of a model with full annotations at the cost of a significantly fewer number of annotations. Since the time of experts is precious, decreasing annotation cost can be very valuable for real-world deployment.
PhySG: Inverse Rendering with Spherical Gaussians for Physics-based Material Editing and Relighting
Apr 01, 2021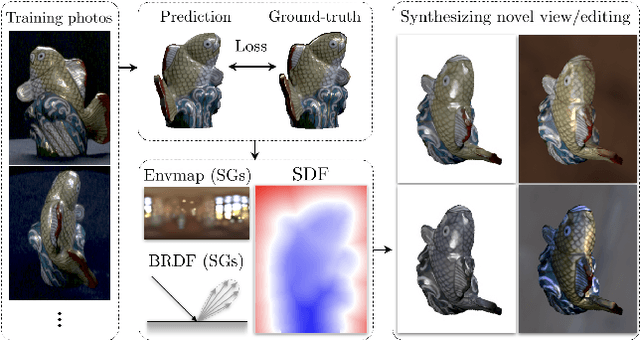

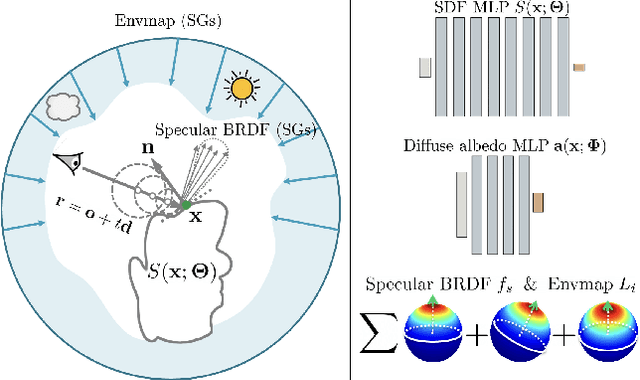

We present PhySG, an end-to-end inverse rendering pipeline that includes a fully differentiable renderer and can reconstruct geometry, materials, and illumination from scratch from a set of RGB input images. Our framework represents specular BRDFs and environmental illumination using mixtures of spherical Gaussians, and represents geometry as a signed distance function parameterized as a Multi-Layer Perceptron. The use of spherical Gaussians allows us to efficiently solve for approximate light transport, and our method works on scenes with challenging non-Lambertian reflectance captured under natural, static illumination. We demonstrate, with both synthetic and real data, that our reconstructions not only enable rendering of novel viewpoints, but also physics-based appearance editing of materials and illumination.
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering
Mar 30, 2021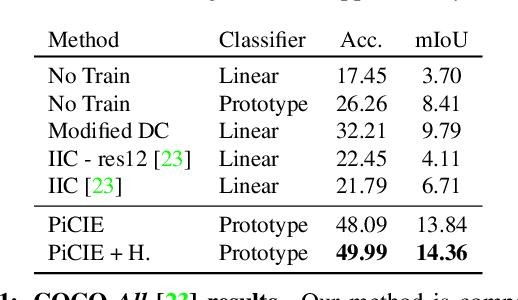
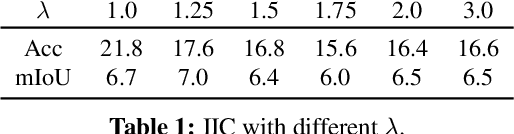
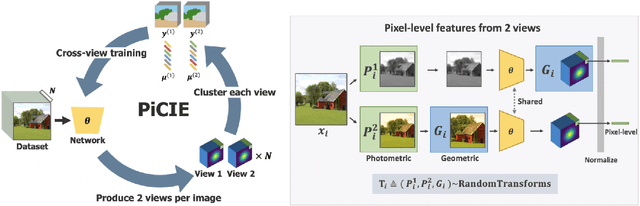
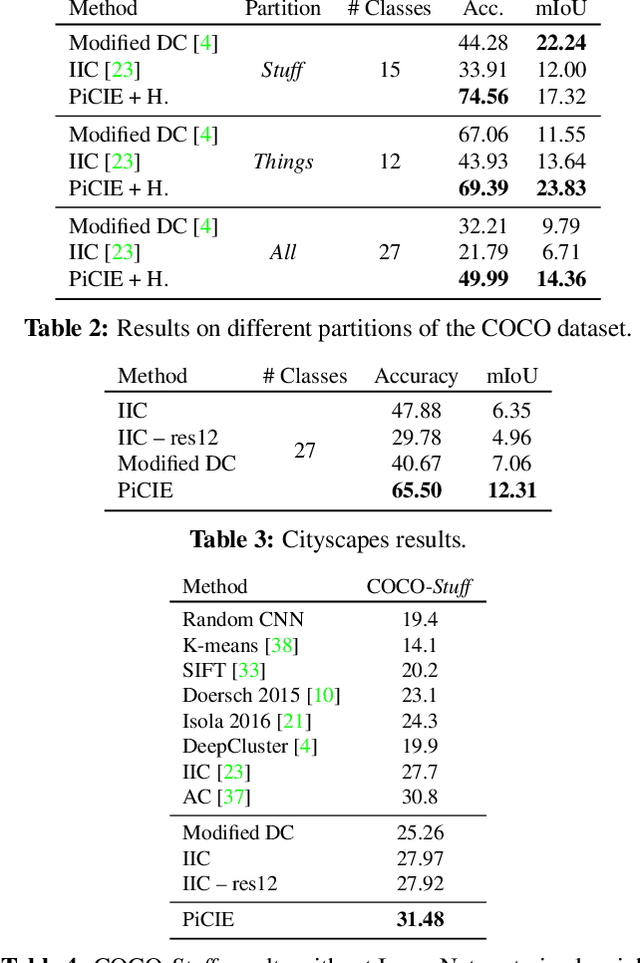
We present a new framework for semantic segmentation without annotations via clustering. Off-the-shelf clustering methods are limited to curated, single-label, and object-centric images yet real-world data are dominantly uncurated, multi-label, and scene-centric. We extend clustering from images to pixels and assign separate cluster membership to different instances within each image. However, solely relying on pixel-wise feature similarity fails to learn high-level semantic concepts and overfits to low-level visual cues. We propose a method to incorporate geometric consistency as an inductive bias to learn invariance and equivariance for photometric and geometric variations. With our novel learning objective, our framework can learn high-level semantic concepts. Our method, PiCIE (Pixel-level feature Clustering using Invariance and Equivariance), is the first method capable of segmenting both things and stuff categories without any hyperparameter tuning or task-specific pre-processing. Our method largely outperforms existing baselines on COCO and Cityscapes with +17.5 Acc. and +4.5 mIoU. We show that PiCIE gives a better initialization for standard supervised training. The code is available at https://github.com/janghyuncho/PiCIE.
Unified Shape and SVBRDF Recovery using Differentiable Monte Carlo Rendering
Mar 28, 2021
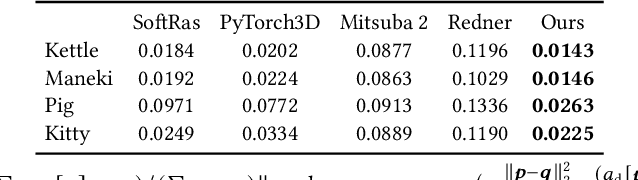
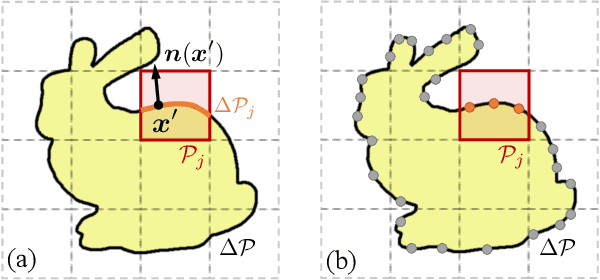

Reconstructing the shape and appearance of real-world objects using measured 2D images has been a long-standing problem in computer vision. In this paper, we introduce a new analysis-by-synthesis technique capable of producing high-quality reconstructions through robust coarse-to-fine optimization and physics-based differentiable rendering. Unlike most previous methods that handle geometry and reflectance largely separately, our method unifies the optimization of both by leveraging image gradients with respect to both object reflectance and geometry. To obtain physically accurate gradient estimates, we develop a new GPU-based Monte Carlo differentiable renderer leveraging recent advances in differentiable rendering theory to offer unbiased gradients while enjoying better performance than existing tools like PyTorch3D and redner. To further improve robustness, we utilize several shape and material priors as well as a coarse-to-fine optimization strategy to reconstruct geometry. We demonstrate that our technique can produce reconstructions with higher quality than previous methods such as COLMAP and Kinect Fusion.