 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariBAD: A Very Good Method for Bayes-Adaptive Deep RL via Meta-Learning
Oct 18, 2019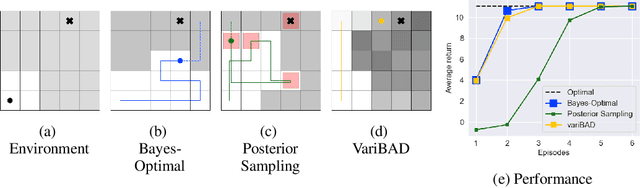
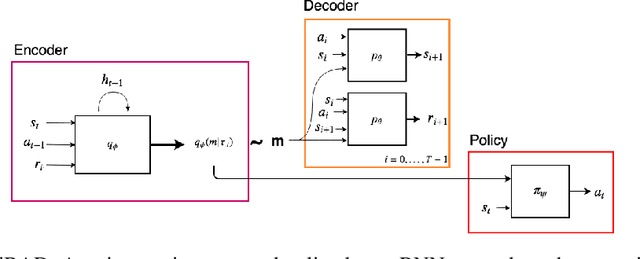
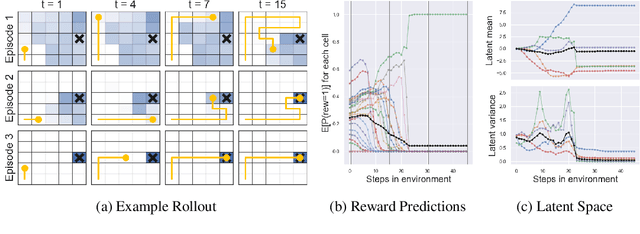
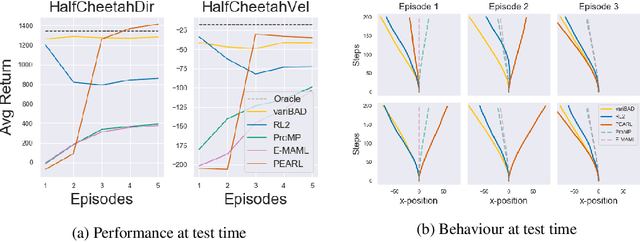
Trading off exploration and exploitation in an unknown environment is key to maximising expected return during learning. A Bayes-optimal policy, which does so optimally, conditions its actions not only on the environment state but on the agent's uncertainty about the environment. Computing a Bayes-optimal policy is however intractable for all but the smallest tasks. In this paper, we introduce variational Bayes-Adaptive Deep RL (variBAD), a way to meta-learn to perform approximate inference in an unknown environment, and incorporate task uncertainty directly during action selection. In a grid-world domain, we illustrate how variBAD performs structured online exploration as a function of task uncertainty. We also evaluate variBAD on MuJoCo domains widely used in meta-RL and show that it achieves higher return during training than existing methods.
Teacher algorithms for curriculum learning of Deep RL in continuously parameterized environments
Oct 16, 2019

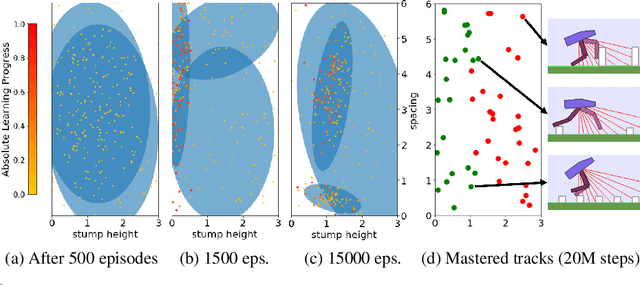
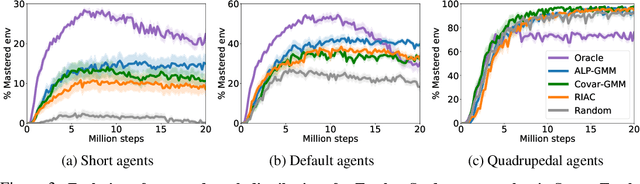
We consider the problem of how a teacher algorithm can enable an unknown Deep Reinforcement Learning (DRL) student to become good at a skill over a wide range of diverse environments. To do so, we study how a teacher algorithm can learn to generate a learning curriculum, whereby it sequentially samples parameters controlling a stochastic procedural generation of environments. Because it does not initially know the capacities of its student, a key challenge for the teacher is to discover which environments are easy, difficult or unlearnable, and in what order to propose them to maximize the efficiency of learning over the learnable ones. To achieve this, this problem is transformed into a surrogate continuous bandit problem where the teacher samples environments in order to maximize absolute learning progress of its student. We present a new algorithm modeling absolute learning progress with Gaussian mixture models (ALP-GMM). We also adapt existing algorithms and provide a complete study in the context of DRL. Using parameterized variants of the BipedalWalker environment, we study their efficiency to personalize a learning curriculum for different learners (embodiments), their robustness to the ratio of learnable/unlearnable environments, and their scalability to non-linear and high-dimensional parameter spaces. Videos and code are available at https://github.com/flowersteam/teachDeepRL.
Combining No-regret and Q-learning
Oct 07, 2019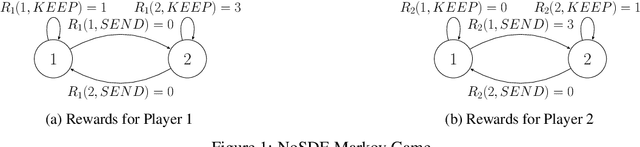
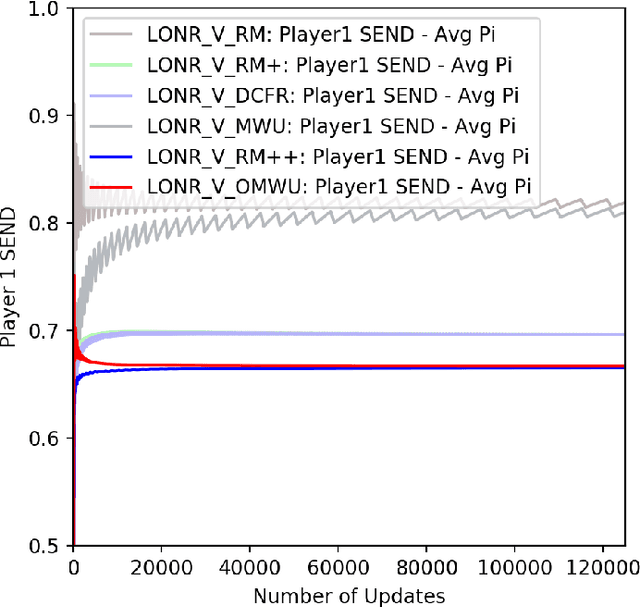
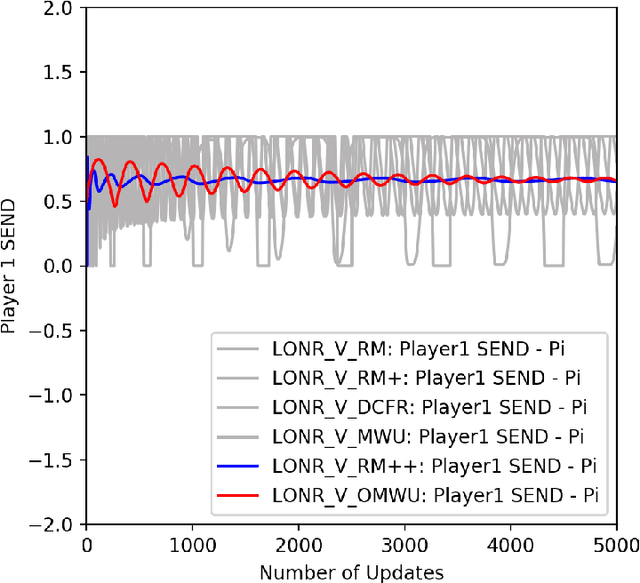
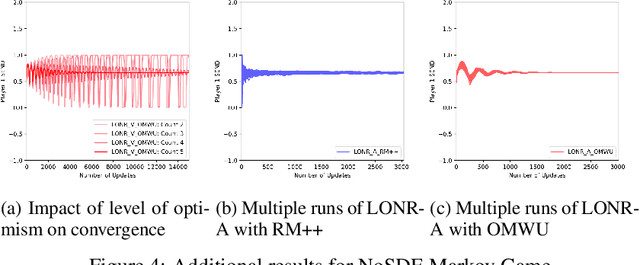
Counterfactual Regret Minimization (CFR) has found success in settings like poker which have both terminal states and perfect recall. We seek to understand how to relax these requirements. As a first step, we introduce a simple algorithm, local no-regret learning (LONR), which uses a Q-learning-like update rule to allow learning without terminal states or perfect recall. We prove its convergence for the basic case of MDPs (and limited extensions of them) and present empirical results showing that it achieves last iterate convergence in a number of settings, most notably NoSDE games, a class of Markov games specifically designed to be challenging to learn where no prior algorithm is known to achieve convergence to a stationary equilibrium even on average.
Near-Optimal Online Egalitarian learning in General Sum Repeated Matrix Games
Jun 04, 2019
We study two-player general sum repeated finite games where the rewards of each player are generated from an unknown distribution. Our aim is to find the egalitarian bargaining solution (EBS) for the repeated game, which can lead to much higher rewards than the maximin value of both players. Our most important contribution is the derivation of an algorithm that achieves simultaneously, for both players, a high-probability regret bound of order $\mathcal{O}(\sqrt[3]{\ln T}\cdot T^{2/3})$ after any $T$ rounds of play. We demonstrate that our upper bound is nearly optimal by proving a lower bound of $\Omega(T^{2/3})$ for any algorithm.
The MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors
Apr 22, 2019
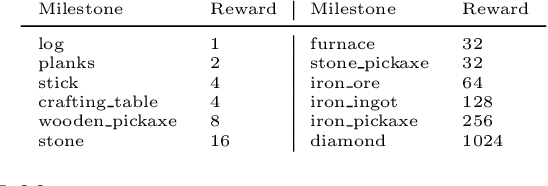
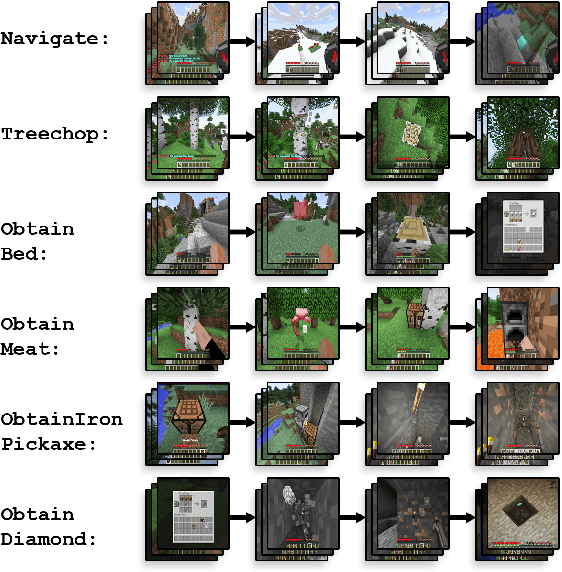
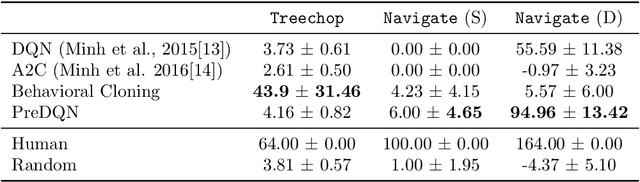
Though deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples. As state-of-the-art reinforcement learning (RL) systems require an exponentially increasing number of samples, their development is restricted to a continually shrinking segment of the AI community. Likewise, many of these systems cannot be applied to real-world problems, where environment samples are expensive. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we introduce the MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, we introduce: (1) the Minecraft ObtainDiamond task, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods; and (2) the MineRL-v0 dataset, a large-scale collection of over 60 million state-action pairs of human demonstrations that can be resimulated into embodied trajectories with arbitrary modifications to game state and visuals. Participants will compete to develop systems which solve the ObtainDiamond task with a limited number of samples from the environment simulator, Malmo. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures. At the end of each round, competitors will submit containerized versions of their learning algorithms and they will then be trained/evaluated from scratch on a hold-out dataset-environment pair for a total of 4-days on a prespecified hardware platform.
The Multi-Agent Reinforcement Learning in MalmÖ (MARLÖ) Competition
Jan 23, 2019Learning in multi-agent scenarios is a fruitful research direction, but current approaches still show scalability problems in multiple games with general reward settings and different opponent types. The Multi-Agent Reinforcement Learning in Malm\"O (MARL\"O) competition is a new challenge that proposes research in this domain using multiple 3D games. The goal of this contest is to foster research in general agents that can learn across different games and opponent types, proposing a challenge as a milestone in the direction of Artificial General Intelligence.
* 2 pages plus references
Successor Uncertainties: exploration and uncertainty in temporal difference learning
Oct 15, 2018
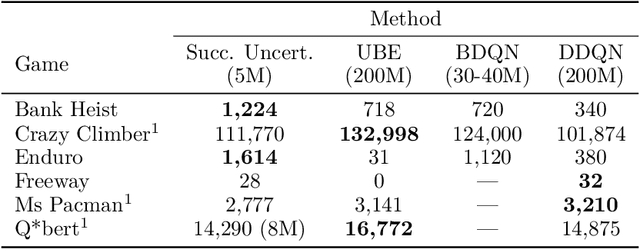
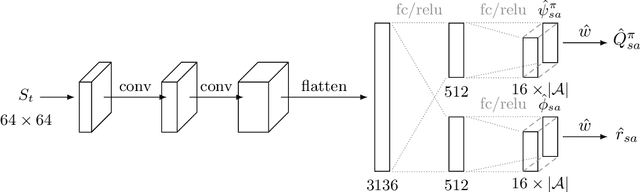
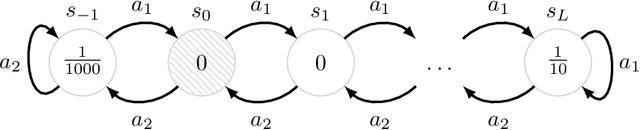
We consider the problem of balancing exploration and exploitation in sequential decision making problems. To explore efficiently, it is vital to consider the uncertainty over all consequences of a decision, and not just those that follow immediately; the uncertainties involved need to be propagated according to the dynamics of the problem. To this end, we develop Successor Uncertainties, a probabilistic model for the state-action value function of a Markov Decision Process that propagates uncertainties in a coherent and scalable way. We relate our approach to other classical and contemporary methods for exploration and present an empirical analysis.
CAML: Fast Context Adaptation via Meta-Learning
Oct 12, 2018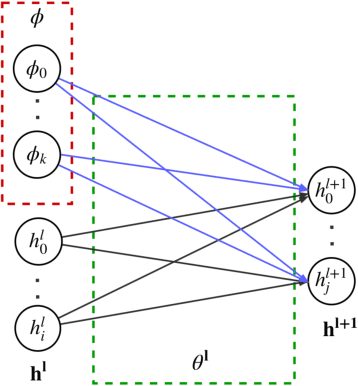

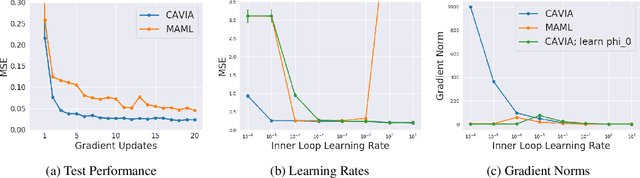
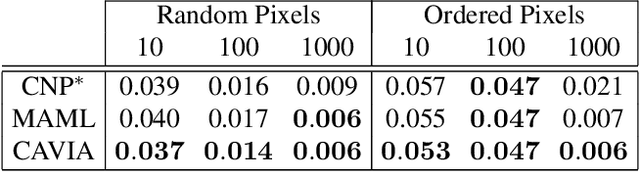
We propose CAML, a meta-learning method for fast adaptation that partitions the model parameters into two parts: context parameters that serve as additional input to the model and are adapted on individual tasks, and shared parameters that are meta-trained and shared across tasks. At test time, the context parameters are updated with one or several gradient steps on a task-specific loss that is backpropagated through the shared part of the network. Compared to approaches that adjust all parameters on a new task (e.g., MAML), our method can be scaled up to larger networks without overfitting on a single task, is easier to implement, and saves memory writes during training and network communication at test time for distributed machine learning systems. We show empirically that this approach outperforms MAML, is less sensitive to the task-specific learning rate, can capture meaningful task embeddings with the context parameters, and outperforms alternative partitionings of the parameter vectors.
Meta Reinforcement Learning with Latent Variable Gaussian Processes
Jul 07, 2018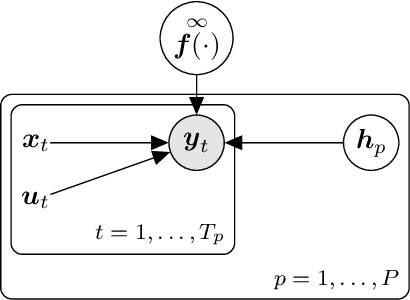
Learning from small data sets is critical in many practical applications where data collection is time consuming or expensive, e.g., robotics, animal experiments or drug design. Meta learning is one way to increase the data efficiency of learning algorithms by generalizing learned concepts from a set of training tasks to unseen, but related, tasks. Often, this relationship between tasks is hard coded or relies in some other way on human expertise. In this paper, we frame meta learning as a hierarchical latent variable model and infer the relationship between tasks automatically from data. We apply our framework in a model-based reinforcement learning setting and show that our meta-learning model effectively generalizes to novel tasks by identifying how new tasks relate to prior ones from minimal data. This results in up to a 60% reduction in the average interaction time needed to solve tasks compared to strong baselines.
Depth and nonlinearity induce implicit exploration for RL
May 29, 2018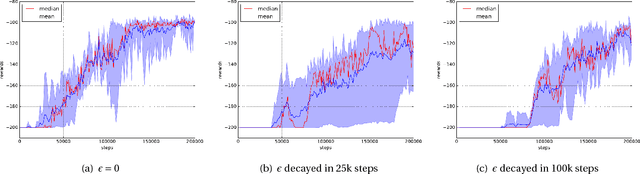
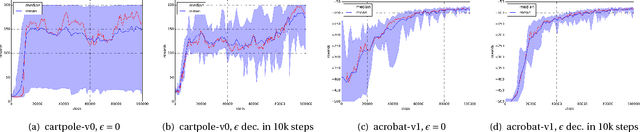
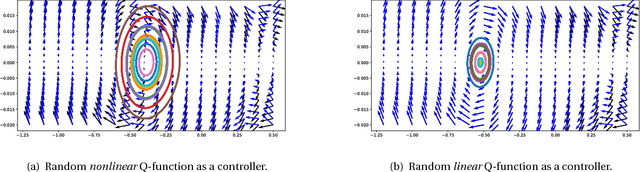
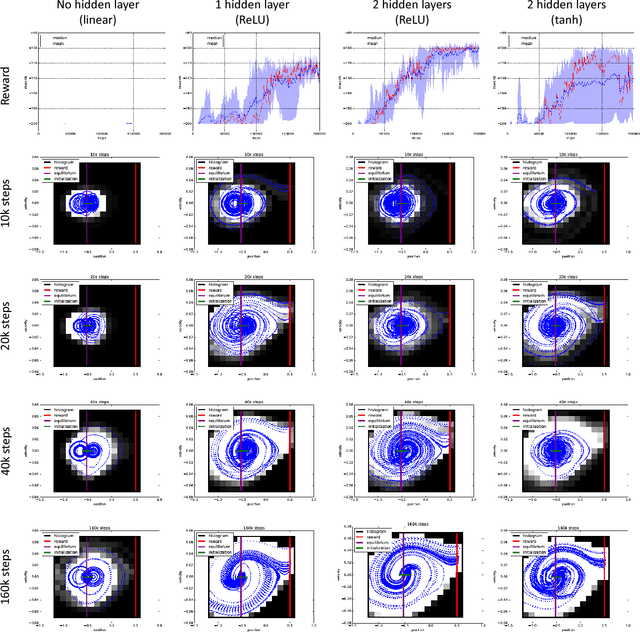
The question of how to explore, i.e., take actions with uncertain outcomes to learn about possible future rewards, is a key question in reinforcement learning (RL). Here, we show a surprising result: We show that Q-learning with nonlinear Q-function and no explicit exploration (i.e., a purely greedy policy) can learn several standard benchmark tasks, including mountain car, equally well as, or better than, the most commonly-used $\epsilon$-greedy exploration. We carefully examine this result and show that both the depth of the Q-network and the type of nonlinearity are important to induce such deterministic exploration.