 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePI-Net: A Deep Learning Approach to Extract Topological Persistence Images
Jun 05, 2019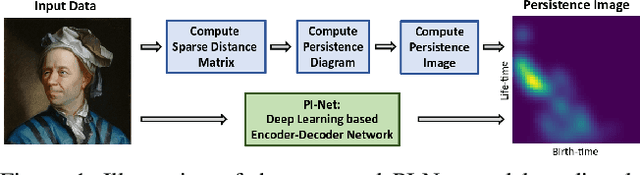
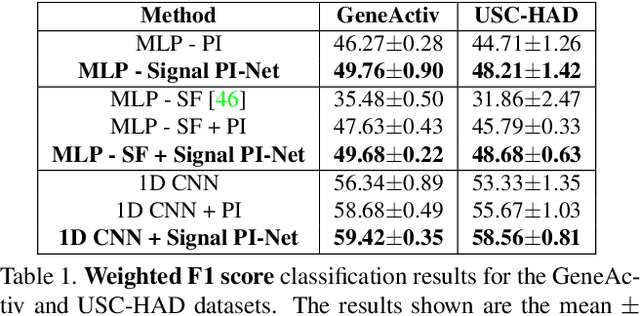
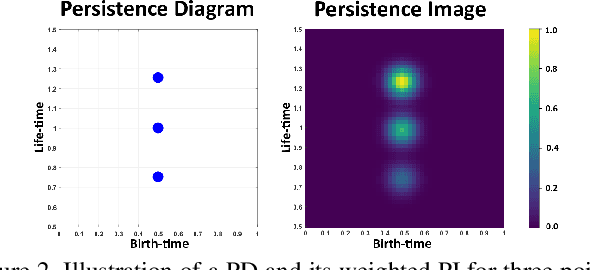

Topological features such as persistence diagrams and their functional approximations like persistence images (PIs) have been showing substantial promise for machine learning and computer vision applications. Key bottlenecks to their large scale adoption are computational expenditure and difficulty in incorporating them in a differentiable architecture. We take an important step in this paper to mitigate these bottlenecks by proposing a novel one-step approach to generate PIs directly from the input data. We propose a simple convolutional neural network architecture called PI-Net that allows us to learn mappings between the input data and PIs. We design two separate architectures, one designed to take in multi-variate time series signals as input and another that accepts multi-channel images as input. We call these networks Signal PI-Net and Image PI-Net respectively. To the best of our knowledge, we are the first to propose the use of deep learning for computing topological features directly from data. We explore the use of the proposed method on two applications: human activity recognition using accelerometer sensor data and image classification. We demonstrate the ease of fusing PIs in supervised deep learning architectures and speed up of several orders of magnitude for extracting PIs from data. Our code is available at https://github.com/anirudhsom/PI-Net.
Optimized Score Transformation for Fair Classification
May 31, 2019
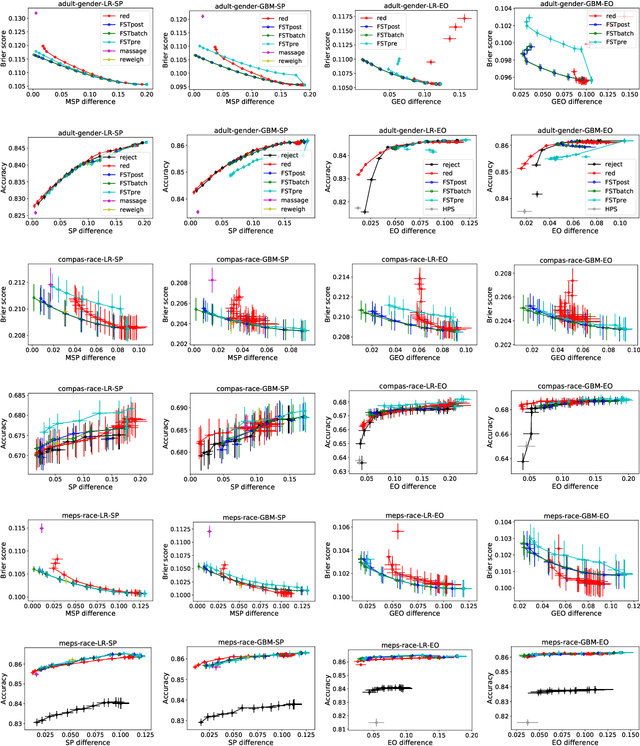
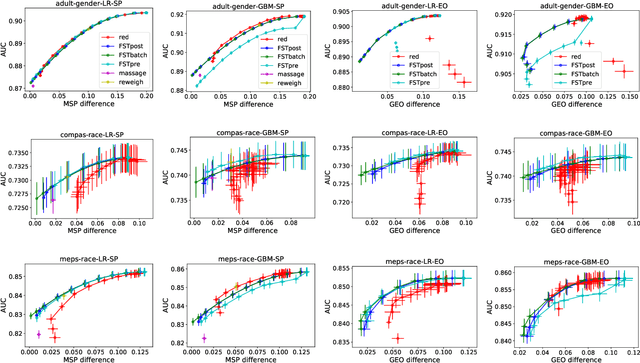
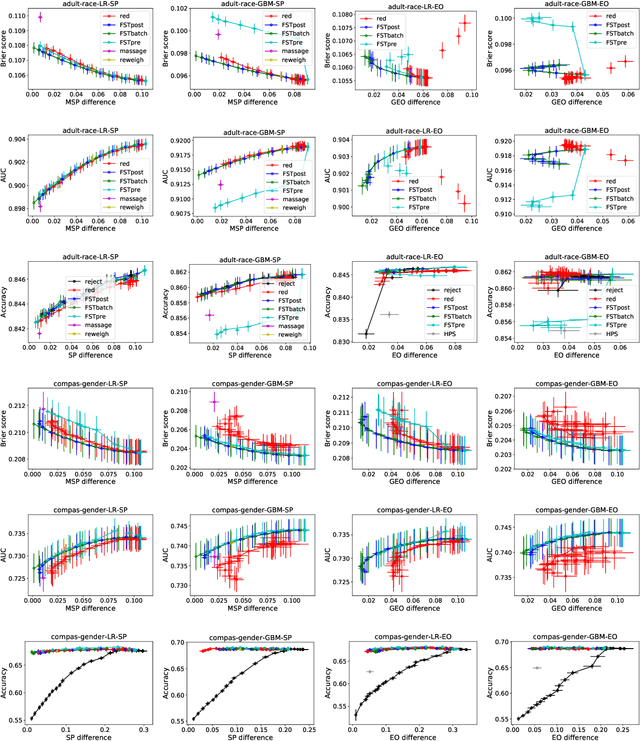
This paper considers fair probabilistic classification where the outputs of primary interest are predicted probabilities, commonly referred to as scores. We formulate the problem of transforming scores to satisfy fairness constraints that are linear in conditional means of scores while minimizing the loss in utility. The same formulation can be applied both to post-process classifier outputs as well as to pre-process training data. We derive a closed-form expression for the optimal transformed scores and a convex optimization problem for the transformation parameters. In the population limit, the transformed score function is the fairness-constrained minimizer of cross-entropy with respect to the optimal unconstrained scores. In the finite sample setting, we propose to approach this solution using a combination of standard probabilistic classifiers and ADMM. Comprehensive experiments show that the proposed \mname has advantages for score-based metrics such as Brier score and AUC while remaining competitive for binary label-based metrics such as accuracy.
Counting and Segmenting Sorghum Heads
May 30, 2019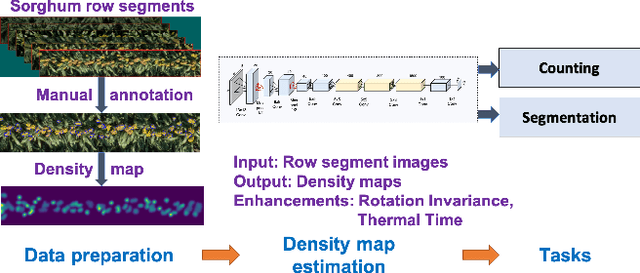
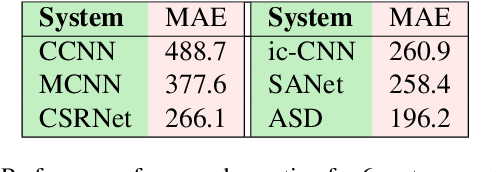

Phenotyping is the process of measuring an organism's observable traits. Manual phenotyping of crops is a labor-intensive, time-consuming, costly, and error prone process. Accurate, automated, high-throughput phenotyping can relieve a huge burden in the crop breeding pipeline. In this paper, we propose a scalable, high-throughput approach to automatically count and segment panicles (heads), a key phenotype, from aerial sorghum crop imagery. Our counting approach uses the image density map obtained from dot or region annotation as the target with a novel deep convolutional neural network architecture. We also propose a novel instance segmentation algorithm using the estimated density map, to identify the individual panicles in the presence of occlusion. With real Sorghum aerial images, we obtain a mean absolute error (MAE) of 1.06 for counting which is better than using well-known crowd counting approaches such as CCNN, MCNN and CSRNet models. The instance segmentation model also produces respectable results which will be ultimately useful in reducing the manual annotation workload for future data.
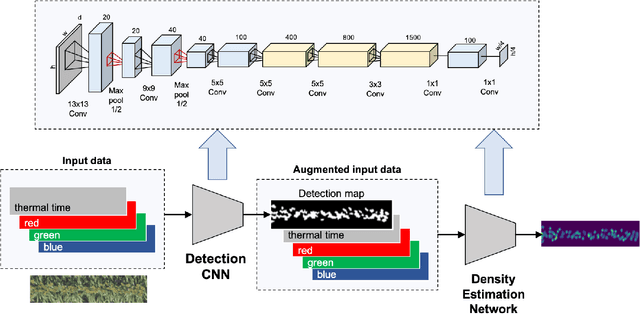
Crowd Counting with Decomposed Uncertainty
Mar 15, 2019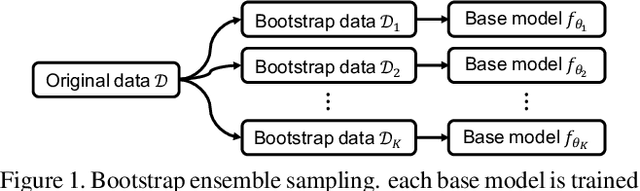
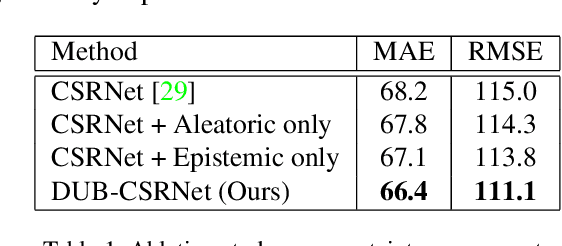
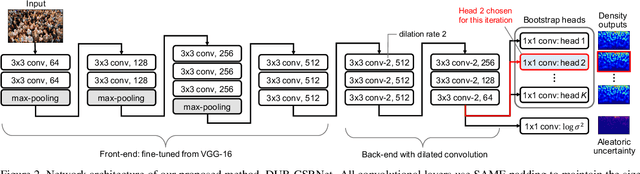
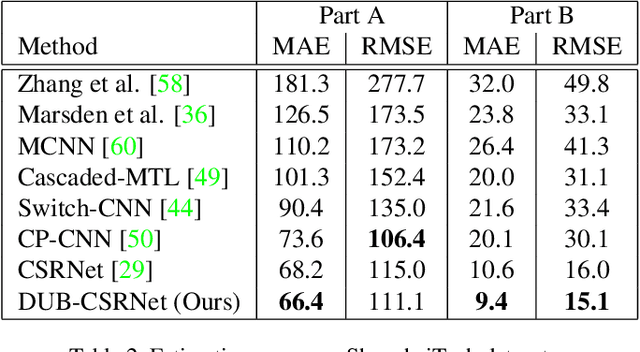
Research in neural networks in the field of computer vision has achieved remarkable accuracy for point estimation. However, the uncertainty in the estimation is rarely addressed. Uncertainty quantification accompanied by point estimation can lead to a more informed decision, and even improve the prediction quality. In this work, we focus on uncertainty estimation in the domain of crowd counting. We propose a scalable neural network framework with quantification of decomposed uncertainty using a bootstrap ensemble. We demonstrate that the proposed uncertainty quantification method provides additional insight to the crowd counting problem and is simple to implement. We also show that our proposed method outperforms the current state of the art method in many benchmark data sets. To the best of our knowledge, we have the best system for ShanghaiTech part A and B, UCF CC 50, UCSD, and UCF-QNRF datasets.
Bias Mitigation Post-processing for Individual and Group Fairness
Dec 14, 2018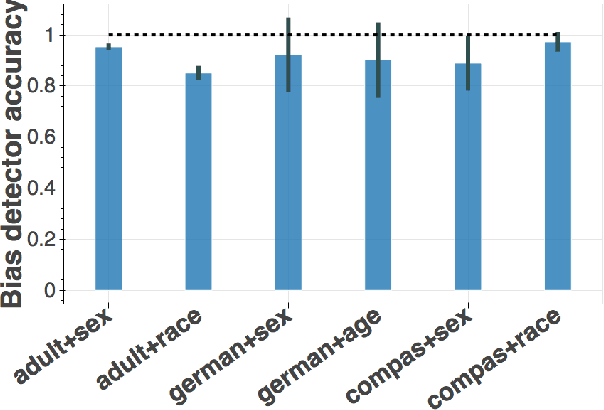
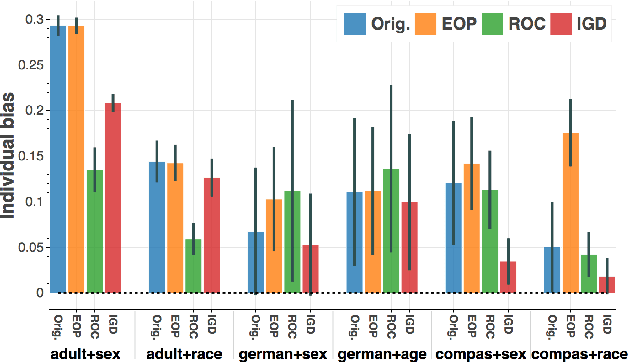
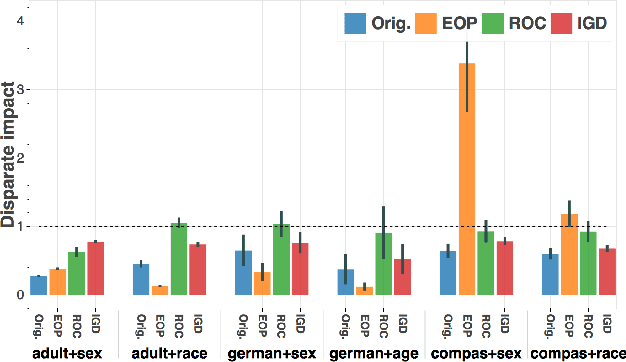
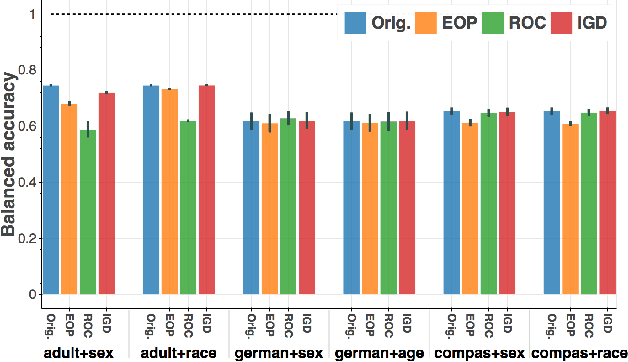
Whereas previous post-processing approaches for increasing the fairness of predictions of biased classifiers address only group fairness, we propose a method for increasing both individual and group fairness. Our novel framework includes an individual bias detector used to prioritize data samples in a bias mitigation algorithm aiming to improve the group fairness measure of disparate impact. We show superior performance to previous work in the combination of classification accuracy, individual fairness and group fairness on several real-world datasets in applications such as credit, employment, and criminal justice.
TED: Teaching AI to Explain its Decisions
Nov 12, 2018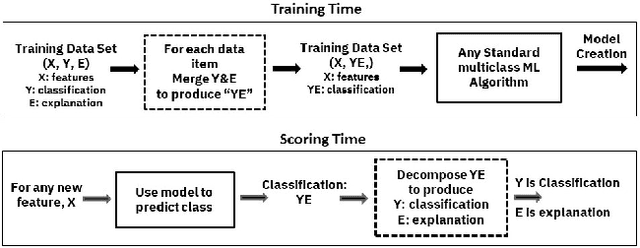
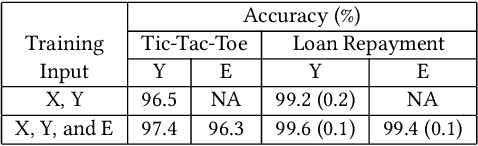

Artificial intelligence systems are being increasingly deployed due to their potential to increase the efficiency, scale, consistency, fairness, and accuracy of decisions. However, as many of these systems are opaque in their operation, there is a growing demand for such systems to provide explanations for their decisions. Conventional approaches to this problem attempt to expose or discover the inner workings of a machine learning model with the hope that the resulting explanations will be meaningful to the consumer. In contrast, this paper suggests a new approach to this problem. It introduces a simple, practical framework, called Teaching Explanations for Decisions (TED), that provides meaningful explanations that match the mental model of the consumer. We illustrate the generality and effectiveness of this approach with two different examples, resulting in highly accurate explanations with no loss of prediction accuracy for these two examples.
AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
Oct 03, 2018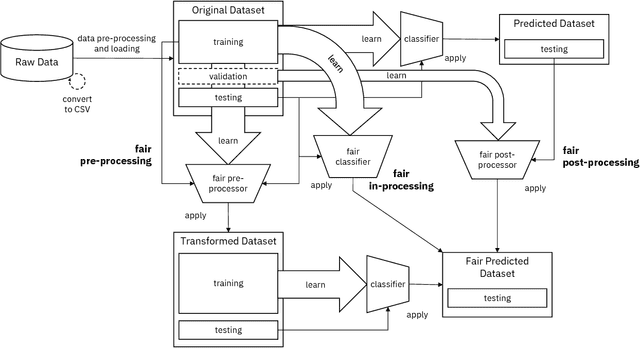
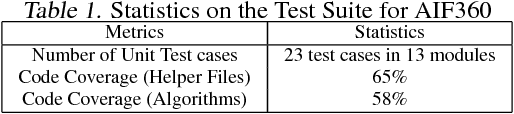
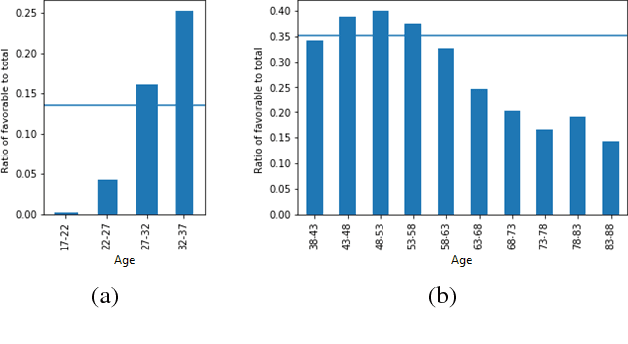
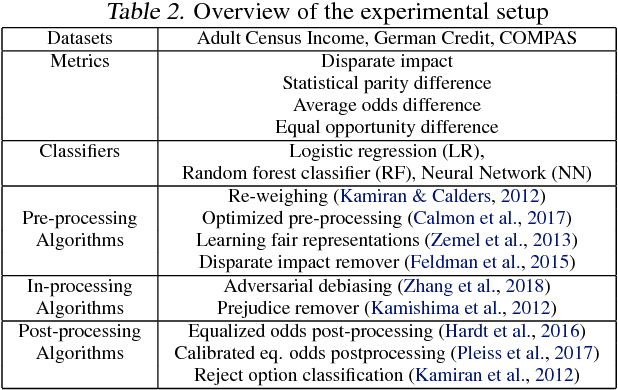
Fairness is an increasingly important concern as machine learning models are used to support decision making in high-stakes applications such as mortgage lending, hiring, and prison sentencing. This paper introduces a new open source Python toolkit for algorithmic fairness, AI Fairness 360 (AIF360), released under an Apache v2.0 license {https://github.com/ibm/aif360). The main objectives of this toolkit are to help facilitate the transition of fairness research algorithms to use in an industrial setting and to provide a common framework for fairness researchers to share and evaluate algorithms. The package includes a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to mitigate bias in datasets and models. It also includes an interactive Web experience (https://aif360.mybluemix.net) that provides a gentle introduction to the concepts and capabilities for line-of-business users, as well as extensive documentation, usage guidance, and industry-specific tutorials to enable data scientists and practitioners to incorporate the most appropriate tool for their problem into their work products. The architecture of the package has been engineered to conform to a standard paradigm used in data science, thereby further improving usability for practitioners. Such architectural design and abstractions enable researchers and developers to extend the toolkit with their new algorithms and improvements, and to use it for performance benchmarking. A built-in testing infrastructure maintains code quality.
Teaching Meaningful Explanations
Sep 11, 2018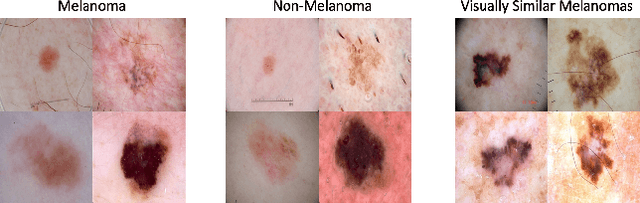
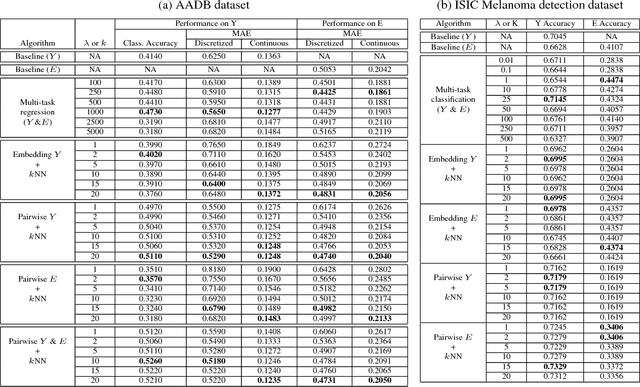
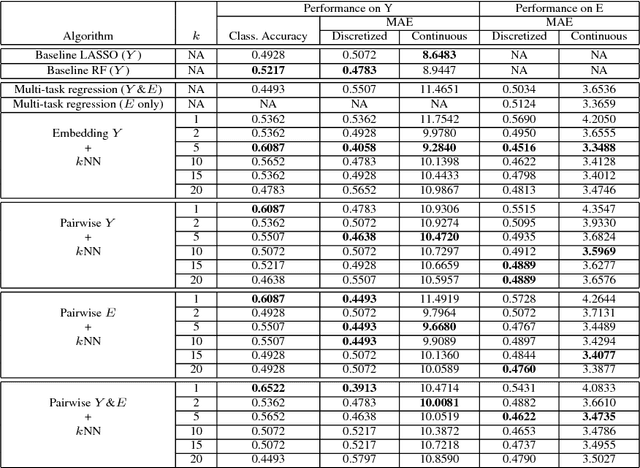
The adoption of machine learning in high-stakes applications such as healthcare and law has lagged in part because predictions are not accompanied by explanations comprehensible to the domain user, who often holds the ultimate responsibility for decisions and outcomes. In this paper, we propose an approach to generate such explanations in which training data is augmented to include, in addition to features and labels, explanations elicited from domain users. A joint model is then learned to produce both labels and explanations from the input features. This simple idea ensures that explanations are tailored to the complexity expectations and domain knowledge of the consumer. Evaluation spans multiple modeling techniques on a game dataset, a (visual) aesthetics dataset, a chemical odor dataset and a Melanoma dataset showing that our approach is generalizable across domains and algorithms. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, also improve modeling accuracy.
Increasing Trust in AI Services through Supplier's Declarations of Conformity
Aug 22, 2018The accuracy and reliability of machine learning algorithms are an important concern for suppliers of artificial intelligence (AI) services, but considerations beyond accuracy, such as safety, security, and provenance, are also critical elements to engender consumers' trust in a service. In this paper, we propose a supplier's declaration of conformity (SDoC) for AI services to help increase trust in AI services. An SDoC is a transparent, standardized, but often not legally required, document used in many industries and sectors to describe the lineage of a product along with the safety and performance testing it has undergone. We envision an SDoC for AI services to contain purpose, performance, safety, security, and provenance information to be completed and voluntarily released by AI service providers for examination by consumers. Importantly, it conveys product-level rather than component-level functional testing. We suggest a set of declaration items tailored to AI and provide examples for two fictitious AI services.
Perturbation Robust Representations of Topological Persistence Diagrams
Jul 26, 2018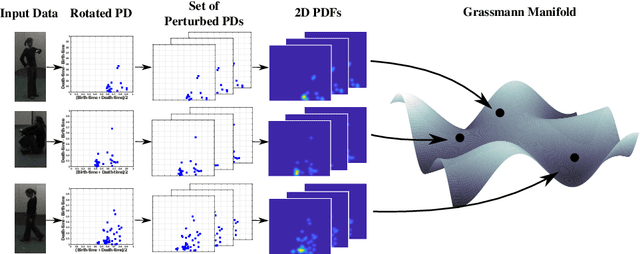

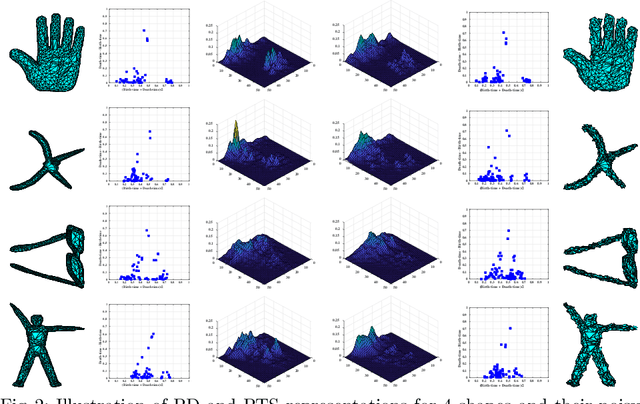

Topological methods for data analysis present opportunities for enforcing certain invariances of broad interest in computer vision, including view-point in activity analysis, articulation in shape analysis, and measurement invariance in non-linear dynamical modeling. The increasing success of these methods is attributed to the complementary information that topology provides, as well as availability of tools for computing topological summaries such as persistence diagrams. However, persistence diagrams are multi-sets of points and hence it is not straightforward to fuse them with features used for contemporary machine learning tools like deep-nets. In this paper we present theoretically well-grounded approaches to develop novel perturbation robust topological representations, with the long-term view of making them amenable to fusion with contemporary learning architectures. We term the proposed representation as Perturbed Topological Signatures, which live on a Grassmann manifold and hence can be efficiently used in machine learning pipelines. We explore the use of the proposed descriptor on three applications: 3D shape analysis, view-invariant activity analysis, and non-linear dynamical modeling. We show favorable results in both high-level recognition performance and time-complexity when compared to other baseline methods.