 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomizing a Large Language Model for VHDL Design of High-Performance Microprocessors
May 14, 2025The use of Large Language Models (LLMs) in hardware design has taken off in recent years, principally through its incorporation in tools that increase chip designer productivity. There has been considerable discussion about the use of LLMs in RTL specifications of chip designs, for which the two most popular languages are Verilog and VHDL. LLMs and their use in Verilog design has received significant attention due to the higher popularity of the language, but little attention so far has been given to VHDL despite its continued popularity in the industry. There has also been little discussion about the unique needs of organizations that engage in high-performance processor design, and techniques to deploy AI solutions in these settings. In this paper, we describe our journey in developing a Large Language Model (LLM) specifically for the purpose of explaining VHDL code, a task that has particular importance in an organization with decades of experience and assets in high-performance processor design. We show how we developed test sets specific to our needs and used them for evaluating models as we performed extended pretraining (EPT) of a base LLM. Expert evaluation of the code explanations produced by the EPT model increased to 69% compared to a base model rating of 43%. We further show how we developed an LLM-as-a-judge to gauge models similar to expert evaluators. This led us to deriving and evaluating a host of new models, including an instruction-tuned version of the EPT model with an expected expert evaluator rating of 71%. Our experiments also indicate that with the potential use of newer base models, this rating can be pushed to 85% and beyond. We conclude with a discussion on further improving the quality of hardware design LLMs using exciting new developments in the Generative AI world.
Tabular Transformers for Modeling Multivariate Time Series
Nov 03, 2020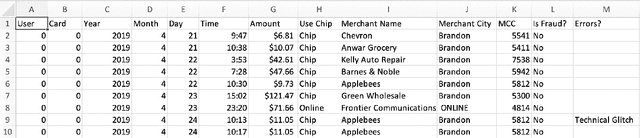

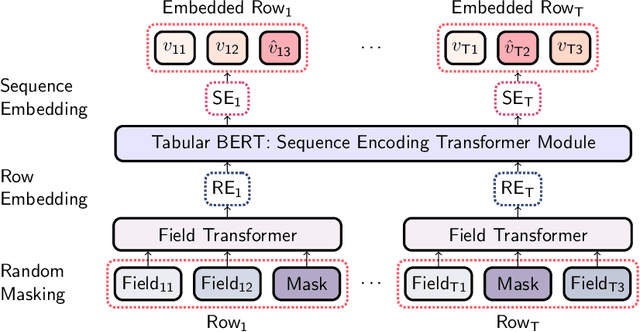
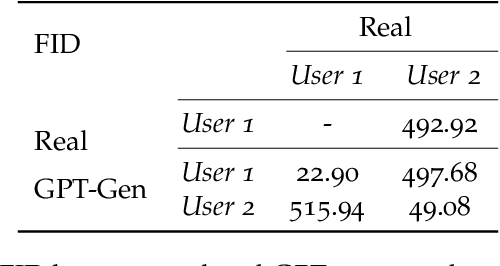
Tabular datasets are ubiquitous in data science applications. Given their importance, it seems natural to apply state-of-the-art deep learning algorithms in order to fully unlock their potential. Here we propose neural network models that represent tabular time series that can optionally leverage their hierarchical structure. This results in two architectures for tabular time series: one for learning representations that is analogous to BERT and can be pre-trained end-to-end and used in downstream tasks, and one that is akin to GPT and can be used for generation of realistic synthetic tabular sequences. We demonstrate our models on two datasets: a synthetic credit card transaction dataset, where the learned representations are used for fraud detection and synthetic data generation, and on a real pollution dataset, where the learned encodings are used to predict atmospheric pollutant concentrations. Code and data are available at https://github.com/IBM/TabFormer.
Increasing Trust in AI Services through Supplier's Declarations of Conformity
Aug 22, 2018The accuracy and reliability of machine learning algorithms are an important concern for suppliers of artificial intelligence (AI) services, but considerations beyond accuracy, such as safety, security, and provenance, are also critical elements to engender consumers' trust in a service. In this paper, we propose a supplier's declaration of conformity (SDoC) for AI services to help increase trust in AI services. An SDoC is a transparent, standardized, but often not legally required, document used in many industries and sectors to describe the lineage of a product along with the safety and performance testing it has undergone. We envision an SDoC for AI services to contain purpose, performance, safety, security, and provenance information to be completed and voluntarily released by AI service providers for examination by consumers. Importantly, it conveys product-level rather than component-level functional testing. We suggest a set of declaration items tailored to AI and provide examples for two fictitious AI services.