 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Active Learning Pipeline for Legal Text Classification
Nov 15, 2022



Active Learning (AL) is a powerful tool for learning with less labeled data, in particular, for specialized domains, like legal documents, where unlabeled data is abundant, but the annotation requires domain expertise and is thus expensive. Recent works have shown the effectiveness of AL strategies for pre-trained language models. However, most AL strategies require a set of labeled samples to start with, which is expensive to acquire. In addition, pre-trained language models have been shown unstable during fine-tuning with small datasets, and their embeddings are not semantically meaningful. In this work, we propose a pipeline for effectively using active learning with pre-trained language models in the legal domain. To this end, we leverage the available unlabeled data in three phases. First, we continue pre-training the model to adapt it to the downstream task. Second, we use knowledge distillation to guide the model's embeddings to a semantically meaningful space. Finally, we propose a simple, yet effective, strategy to find the initial set of labeled samples with fewer actions compared to existing methods. Our experiments on Contract-NLI, adapted to the classification task, and LEDGAR benchmarks show that our approach outperforms standard AL strategies, and is more efficient. Furthermore, our pipeline reaches comparable results to the fully-supervised approach with a small performance gap, and dramatically reduced annotation cost. Code and the adapted data will be made available.
Efficient Integration of Multi-Order Dynamics and Internal Dynamics in Stock Movement Prediction
Nov 11, 2022



Advances in deep neural network (DNN) architectures have enabled new prediction techniques for stock market data. Unlike other multivariate time-series data, stock markets show two unique characteristics: (i) \emph{multi-order dynamics}, as stock prices are affected by strong non-pairwise correlations (e.g., within the same industry); and (ii) \emph{internal dynamics}, as each individual stock shows some particular behaviour. Recent DNN-based methods capture multi-order dynamics using hypergraphs, but rely on the Fourier basis in the convolution, which is both inefficient and ineffective. In addition, they largely ignore internal dynamics by adopting the same model for each stock, which implies a severe information loss. In this paper, we propose a framework for stock movement prediction to overcome the above issues. Specifically, the framework includes temporal generative filters that implement a memory-based mechanism onto an LSTM network in an attempt to learn individual patterns per stock. Moreover, we employ hypergraph attentions to capture the non-pairwise correlations. Here, using the wavelet basis instead of the Fourier basis, enables us to simplify the message passing and focus on the localized convolution. Experiments with US market data over six years show that our framework outperforms state-of-the-art methods in terms of profit and stability. Our source code and data are available at \url{https://github.com/thanhtrunghuynh93/estimate}.
Discovering Language-neutral Sub-networks in Multilingual Language Models
May 25, 2022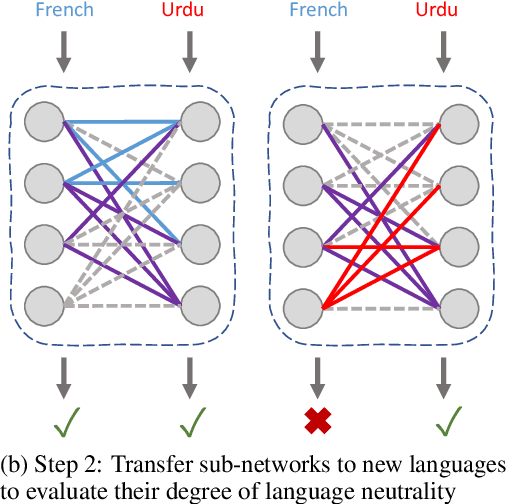
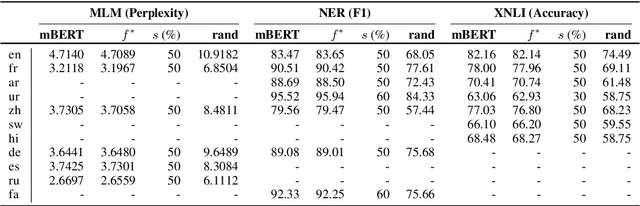
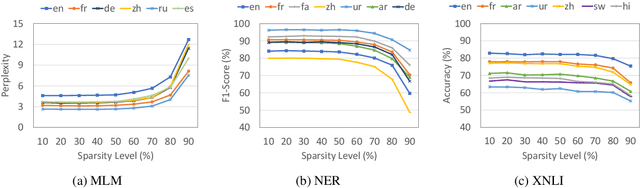
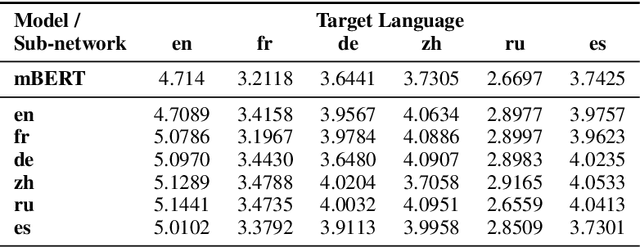
Multilingual pre-trained language models perform remarkably well on cross-lingual transfer for downstream tasks. Despite their impressive performance, our understanding of their language neutrality (i.e., the extent to which they use shared representations to encode similar phenomena across languages) and its role in achieving such performance remain open questions. In this work, we conceptualize language neutrality of multilingual models as a function of the overlap between language-encoding sub-networks of these models. Using mBERT as a foundation, we employ the lottery ticket hypothesis to discover sub-networks that are individually optimized for various languages and tasks. Using three distinct tasks and eleven typologically-diverse languages in our evaluation, we show that the sub-networks found for different languages are in fact quite similar, supporting the idea that mBERT jointly encodes multiple languages in shared parameters. We conclude that mBERT is comprised of a language-neutral sub-network shared among many languages, along with multiple ancillary language-specific sub-networks, with the former playing a more prominent role in mBERT's impressive cross-lingual performance.
From Scattered Sources to Comprehensive Technology Landscape: A Recommendation-based Retrieval Approach
Dec 09, 2021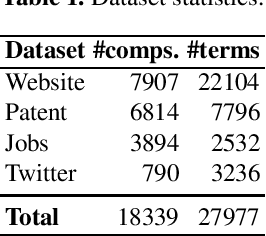
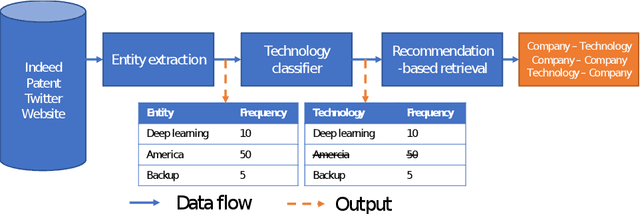
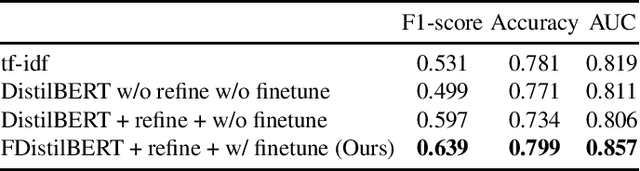
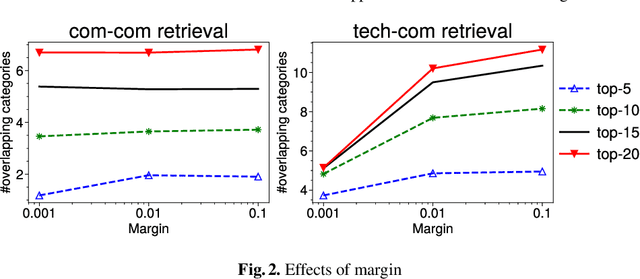
Mapping the technology landscape is crucial for market actors to take informed investment decisions. However, given the large amount of data on the Web and its subsequent information overload, manually retrieving information is a seemingly ineffective and incomplete approach. In this work, we propose an end-to-end recommendation based retrieval approach to support automatic retrieval of technologies and their associated companies from raw Web data. This is a two-task setup involving (i) technology classification of entities extracted from company corpus, and (ii) technology and company retrieval based on classified technologies. Our proposed framework approaches the first task by leveraging DistilBERT which is a state-of-the-art language model. For the retrieval task, we introduce a recommendation-based retrieval technique to simultaneously support retrieving related companies, technologies related to a specific company and companies relevant to a technology. To evaluate these tasks, we also construct a data set that includes company documents and entities extracted from these documents together with company categories and technology labels. Experiments show that our approach is able to return 4 times more relevant companies while outperforming traditional retrieval baseline in retrieving technologies.
SciClops: Detecting and Contextualizing Scientific Claims for Assisting Manual Fact-Checking
Oct 25, 2021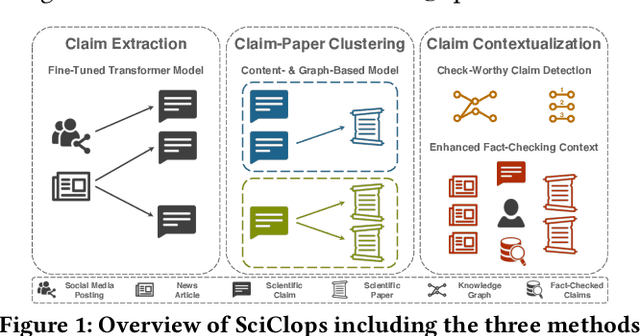

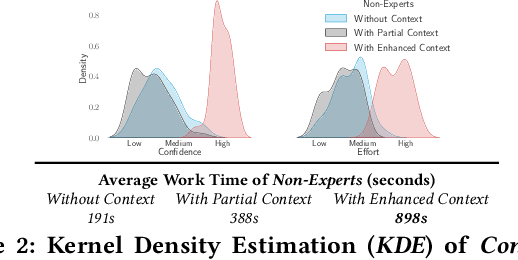
This paper describes SciClops, a method to help combat online scientific misinformation. Although automated fact-checking methods have gained significant attention recently, they require pre-existing ground-truth evidence, which, in the scientific context, is sparse and scattered across a constantly-evolving scientific literature. Existing methods do not exploit this literature, which can effectively contextualize and combat science-related fallacies. Furthermore, these methods rarely require human intervention, which is essential for the convoluted and critical domain of scientific misinformation. SciClops involves three main steps to process scientific claims found in online news articles and social media postings: extraction, clustering, and contextualization. First, the extraction of scientific claims takes place using a domain-specific, fine-tuned transformer model. Second, similar claims extracted from heterogeneous sources are clustered together with related scientific literature using a method that exploits their content and the connections among them. Third, check-worthy claims, broadcasted by popular yet unreliable sources, are highlighted together with an enhanced fact-checking context that includes related verified claims, news articles, and scientific papers. Extensive experiments show that SciClops tackles sufficiently these three steps, and effectively assists non-expert fact-checkers in the verification of complex scientific claims, outperforming commercial fact-checking systems.
Legal Transformer Models May Not Always Help
Sep 15, 2021
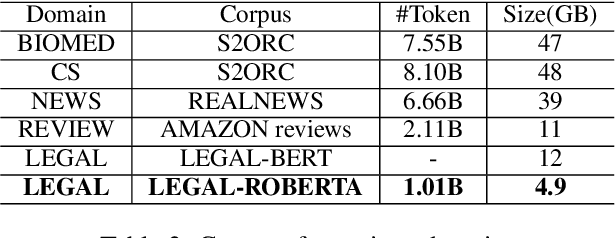

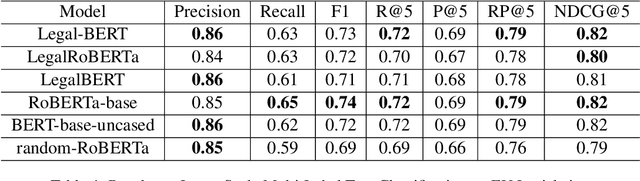
Deep learning-based Natural Language Processing methods, especially transformers, have achieved impressive performance in the last few years. Applying those state-of-the-art NLP methods to legal activities to automate or simplify some simple work is of great value. This work investigates the value of domain adaptive pre-training and language adapters in legal NLP tasks. By comparing the performance of language models with domain adaptive pre-training on different tasks and different dataset splits, we show that domain adaptive pre-training is only helpful with low-resource downstream tasks, thus far from being a panacea. We also benchmark the performance of adapters in a typical legal NLP task and show that they can yield similar performance to full model tuning with much smaller training costs. As an additional result, we release LegalRoBERTa, a RoBERTa model further pre-trained on legal corpora.
Direction is what you need: Improving Word Embedding Compression in Large Language Models
Jun 15, 2021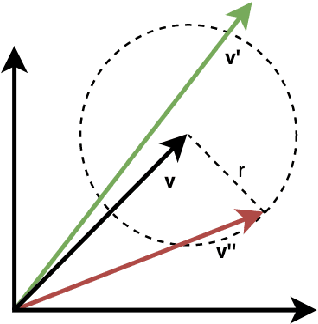

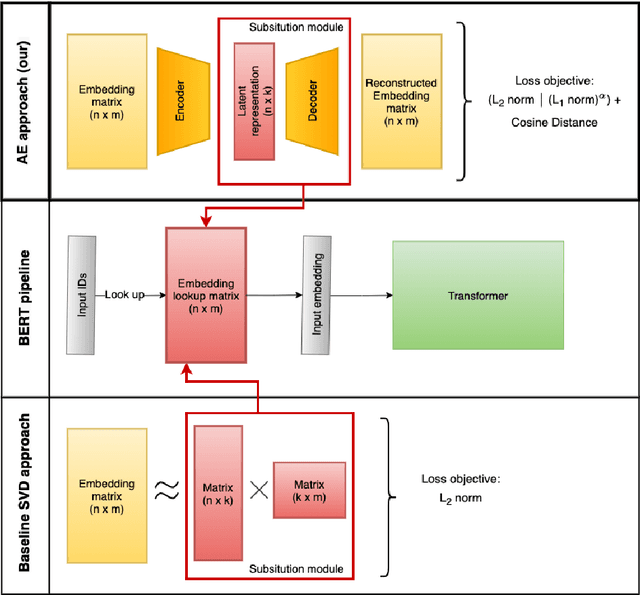
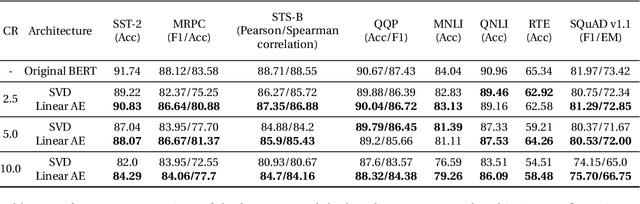
The adoption of Transformer-based models in natural language processing (NLP) has led to great success using a massive number of parameters. However, due to deployment constraints in edge devices, there has been a rising interest in the compression of these models to improve their inference time and memory footprint. This paper presents a novel loss objective to compress token embeddings in the Transformer-based models by leveraging an AutoEncoder architecture. More specifically, we emphasize the importance of the direction of compressed embeddings with respect to original uncompressed embeddings. The proposed method is task-agnostic and does not require further language modeling pre-training. Our method significantly outperforms the commonly used SVD-based matrix-factorization approach in terms of initial language model Perplexity. Moreover, we evaluate our proposed approach over SQuAD v1.1 dataset and several downstream tasks from the GLUE benchmark, where we also outperform the baseline in most scenarios. Our code is public.
On Representation Learning for Scientific News Articles Using Heterogeneous Knowledge Graphs
Apr 12, 2021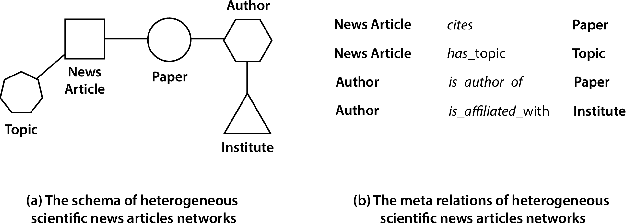
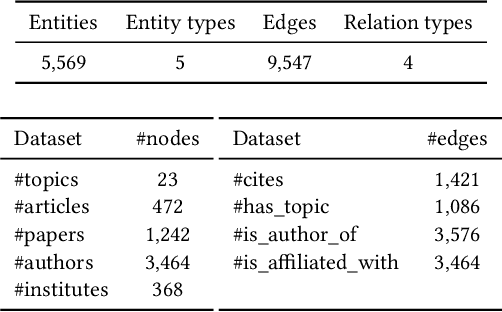
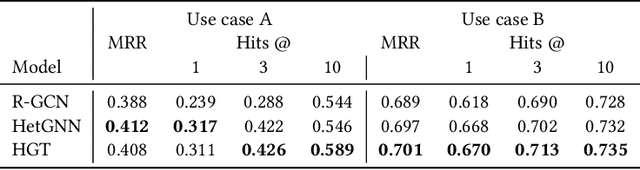
In the era of misinformation and information inflation, the credibility assessment of the produced news is of the essence. However, fact-checking can be challenging considering the limited references presented in the news. This challenge can be transcended by utilizing the knowledge graph that is related to the news articles. In this work, we present a methodology for creating scientific news article representations by modeling the directed graph between the scientific news articles and the cited scientific publications. The network used for the experiments is comprised of the scientific news articles, their topic, the cited research literature, and their corresponding authors. We implement and present three different approaches: 1) a baseline Relational Graph Convolutional Network (R-GCN), 2) a Heterogeneous Graph Neural Network (HetGNN) and 3) a Heterogeneous Graph Transformer (HGT). We test these models in the downstream task of link prediction on the: a) news article - paper links and b) news article - article topic links. The results show promising applications of graph neural network approaches in the domains of knowledge tracing and scientific news credibility assessment.
Spoken dialect identification in Twitter using a multi-filter architecture
Jun 05, 2020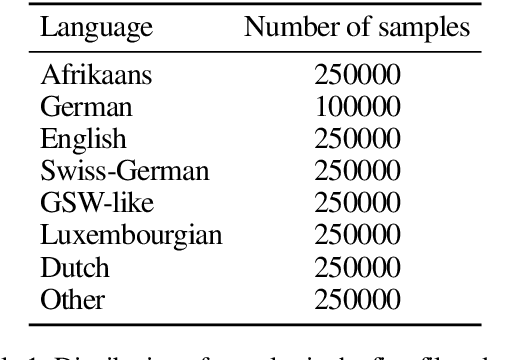
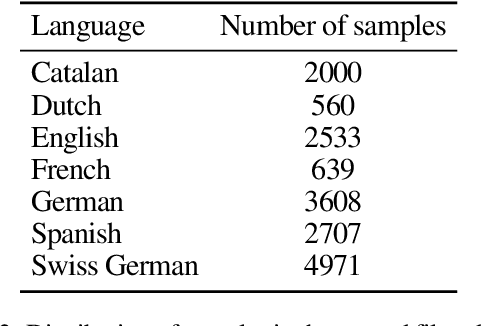
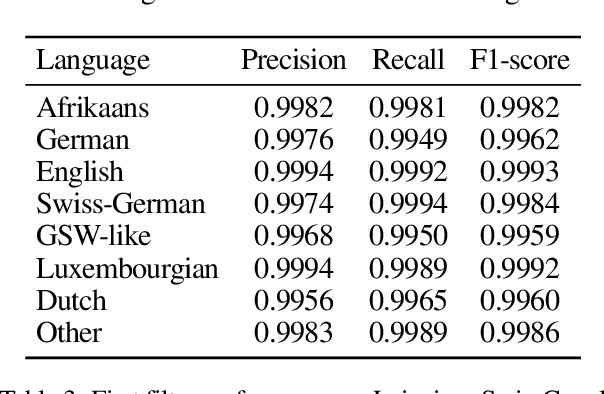
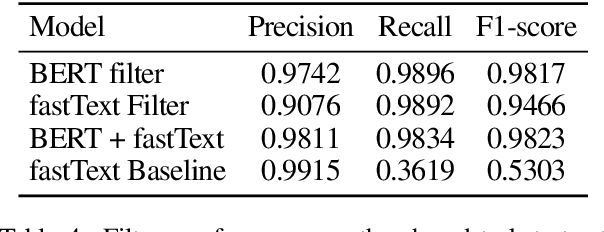
This paper presents our approach for SwissText & KONVENS 2020 shared task 2, which is a multi-stage neural model for Swiss German (GSW) identification on Twitter. Our model outputs either GSW or non-GSW and is not meant to be used as a generic language identifier. Our architecture consists of two independent filters where the first one favors recall, and the second one filter favors precision (both towards GSW). Moreover, we do not use binary models (GSW vs. not-GSW) in our filters but rather a multi-class classifier with GSW being one of the possible labels. Our model reaches F1-score of 0.982 on the test set of the shared task.
Upgrading the Newsroom: An Automated Image Selection System for News Articles
Apr 23, 2020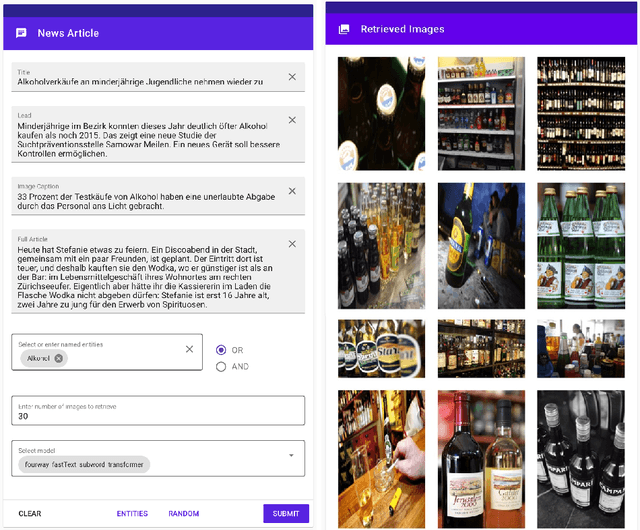
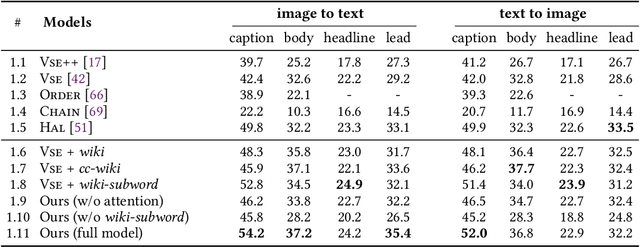
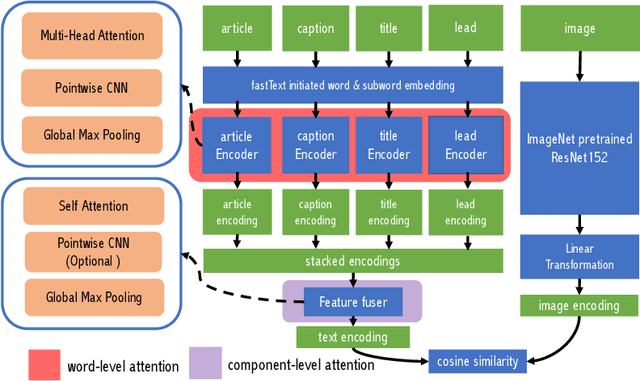
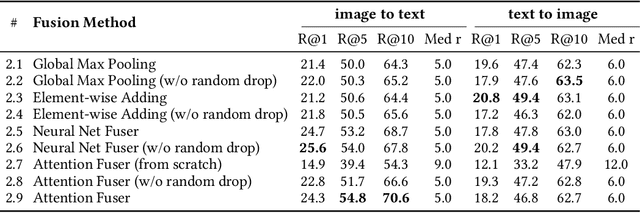
We propose an automated image selection system to assist photo editors in selecting suitable images for news articles. The system fuses multiple textual sources extracted from news articles and accepts multilingual inputs. It is equipped with char-level word embeddings to help both modeling morphologically rich languages, e.g. German, and transferring knowledge across nearby languages. The text encoder adopts a hierarchical self-attention mechanism to attend more to both keywords within a piece of text and informative components of a news article. We extensively experiment with our system on a large-scale text-image database containing multimodal multilingual news articles collected from Swiss local news media websites. The system is compared with multiple baselines with ablation studies and is shown to beat existing text-image retrieval methods in a weakly-supervised learning setting. Besides, we also offer insights on the advantage of using multiple textual sources and multilingual data.