 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINER-SQL: Boosting Small Language Models for Text-to-SQL
May 05, 2026Large language models have driven major advances in Text-to-SQL generation. However, they suffer from high computational cost, long latency, and data privacy concerns, which make them impractical for many real-world applications. A natural alternative is to use small language models (SLMs), which enable efficient and private on-premise deployment. Yet, SLMs often struggle with weak reasoning and poor instruction following. Conventional reinforcement learning methods based on sparse binary rewards (0/1) provide little learning signal when the generated SQLs are incorrect, leading to unstable or collapsed training. To overcome these issues, we propose FINER-SQL, a scalable and reusable reinforcement learning framework that enhances SLMs through fine-grained execution feedback. Built on group relative policy optimization, FINER-SQL replaces sparse supervision with dense and interpretable rewards that offer continuous feedback even for incorrect SQLs. It introduces two key reward functions: a memory reward, which aligns reasoning with verified traces for semantic stability, and an atomic reward, which measures operation-level overlap to grant partial credit for structurally correct but incomplete SQLs. This approach transforms discrete correctness into continuous learning, enabling stable, critic-free optimization. Experiments on the BIRD and Spider benchmarks show that FINER-SQL achieves up to 67.73\% and 85\% execution accuracy with a 3B model -- matching much larger LLMs while reducing inference latency to 5.57~s/sample. These results highlight a cost-efficient and privacy-preserving path toward high-performance Text-to-SQL generation. Our code is available at https://github.com/thanhdath/finer-sql.
VLegal-Bench: Cognitively Grounded Benchmark for Vietnamese Legal Reasoning of Large Language Models
Dec 24, 2025The rapid advancement of large language models (LLMs) has enabled new possibilities for applying artificial intelligence within the legal domain. Nonetheless, the complexity, hierarchical organization, and frequent revisions of Vietnamese legislation pose considerable challenges for evaluating how well these models interpret and utilize legal knowledge. To address this gap, the Vietnamese Legal Benchmark (VLegal-Bench) is introduced, the first comprehensive benchmark designed to systematically assess LLMs on Vietnamese legal tasks. Informed by Bloom's cognitive taxonomy, VLegal-Bench encompasses multiple levels of legal understanding through tasks designed to reflect practical usage scenarios. The benchmark comprises 10,450 samples generated through a rigorous annotation pipeline, where legal experts label and cross-validate each instance using our annotation system to ensure every sample is grounded in authoritative legal documents and mirrors real-world legal assistant workflows, including general legal questions and answers, retrieval-augmented generation, multi-step reasoning, and scenario-based problem solving tailored to Vietnamese law. By providing a standardized, transparent, and cognitively informed evaluation framework, VLegal-Bench establishes a solid foundation for assessing LLM performance in Vietnamese legal contexts and supports the development of more reliable, interpretable, and ethically aligned AI-assisted legal systems. To facilitate access and reproducibility, we provide a public landing page for this benchmark at https://vilegalbench.cmcai.vn/.
A Multi-agent Text2SQL Framework using Small Language Models and Execution Feedback
Dec 21, 2025Text2SQL, the task of generating SQL queries from natural language text, is a critical challenge in data engineering. Recently, Large Language Models (LLMs) have demonstrated superior performance for this task due to their advanced comprehension and generation capabilities. However, privacy and cost considerations prevent companies from using Text2SQL solutions based on external LLMs offered as a service. Rather, small LLMs (SLMs) that are openly available and can hosted in-house are adopted. These SLMs, in turn, lack the generalization capabilities of larger LLMs, which impairs their effectiveness for complex tasks such as Text2SQL. To address these limitations, we propose MATS, a novel Text2SQL framework designed specifically for SLMs. MATS uses a multi-agent mechanism that assigns specialized roles to auxiliary agents, reducing individual workloads and fostering interaction. A training scheme based on reinforcement learning aligns these agents using feedback obtained during execution, thereby maintaining competitive performance despite a limited LLM size. Evaluation results using on benchmark datasets show that MATS, deployed on a single- GPU server, yields accuracy that are on-par with large-scale LLMs when using significantly fewer parameters. Our source code and data are available at https://github.com/thanhdath/mats-sql.
Scaling Text2SQL via LLM-efficient Schema Filtering with Functional Dependency Graph Rerankers
Dec 18, 2025Most modern Text2SQL systems prompt large language models (LLMs) with entire schemas -- mostly column information -- alongside the user's question. While effective on small databases, this approach fails on real-world schemas that exceed LLM context limits, even for commercial models. The recent Spider 2.0 benchmark exemplifies this with hundreds of tables and tens of thousands of columns, where existing systems often break. Current mitigations either rely on costly multi-step prompting pipelines or filter columns by ranking them against user's question independently, ignoring inter-column structure. To scale existing systems, we introduce \toolname, an open-source, LLM-efficient schema filtering framework that compacts Text2SQL prompts by (i) ranking columns with a query-aware LLM encoder enriched with values and metadata, (ii) reranking inter-connected columns via a lightweight graph transformer over functional dependencies, and (iii) selecting a connectivity-preserving sub-schema with a Steiner-tree heuristic. Experiments on real datasets show that \toolname achieves near-perfect recall and higher precision than CodeS, SchemaExP, Qwen rerankers, and embedding retrievers, while maintaining sub-second median latency and scaling to schemas with 23,000+ columns. Our source code is available at https://github.com/thanhdath/grast-sql.
On Node Features for Graph Neural Networks
Nov 20, 2019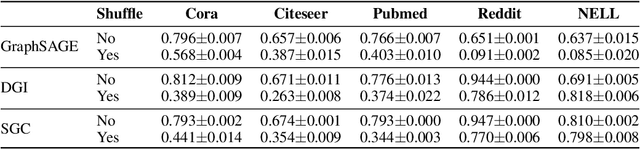
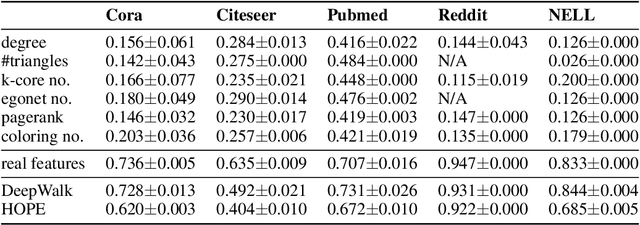
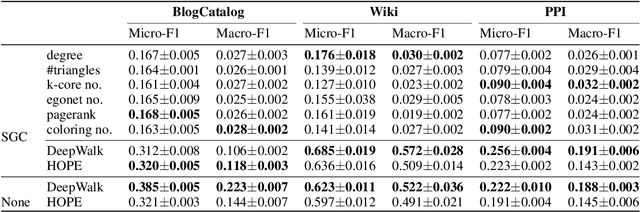
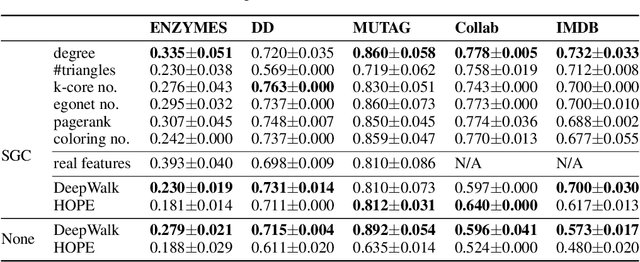
Graph neural network (GNN) is a deep model for graph representation learning. One advantage of graph neural network is its ability to incorporate node features into the learning process. However, this prevents graph neural network from being applied into featureless graphs. In this paper, we first analyze the effects of node features on the performance of graph neural network. We show that GNNs work well if there is a strong correlation between node features and node labels. Based on these results, we propose new feature initialization methods that allows to apply graph neural network to non-attributed graphs. Our experimental results show that the artificial features are highly competitive with real features.
Parallel Computation of Graph Embeddings
Sep 06, 2019
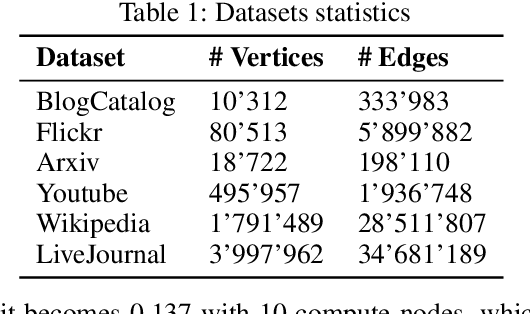
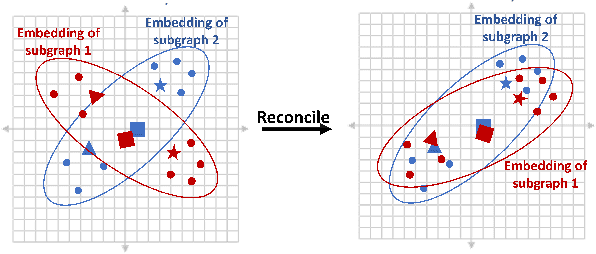
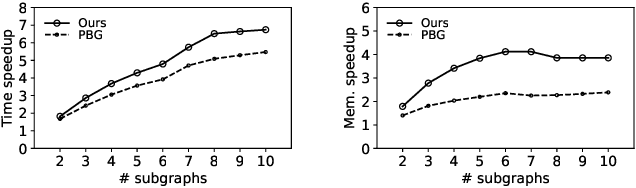
Graph embedding aims at learning a vector-based representation of vertices that incorporates the structure of the graph. This representation then enables inference of graph properties. Existing graph embedding techniques, however, do not scale well to large graphs. We therefore propose a framework for parallel computation of a graph embedding using a cluster of compute nodes with resource constraints. We show how to distribute any existing embedding technique by first splitting a graph for any given set of constrained compute nodes and then reconciling the embedding spaces derived for these subgraphs. We also propose a new way to evaluate the quality of graph embeddings that is independent of a specific inference task. Based thereon, we give a formal bound on the difference between the embeddings derived by centralised and parallel computation. Experimental results illustrate that our approach for parallel computation scales well, while largely maintaining the embedding quality.