 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTraj: Pre-Training on Heterogeneous Data for Adaptive and Zero-Shot Human Trajectory Prediction
Jul 31, 2025



While large-scale pre-training has advanced human trajectory prediction, a critical challenge remains: zero-shot transfer to unseen dataset with varying temporal dynamics. State-of-the-art pre-trained models often require fine-tuning to adapt to new datasets with different frame rates or observation horizons, limiting their scalability and practical utility. In this work, we systematically investigate this limitation and propose a robust solution. We first demonstrate that existing data-aware discrete models struggle when transferred to new scenarios with shifted temporal setups. We then isolate the temporal generalization from dataset shift, revealing that a simple, explicit conditioning mechanism for temporal metadata is a highly effective solution. Based on this insight, we present OmniTraj, a Transformer-based model pre-trained on a large-scale, heterogeneous dataset. Our experiments show that explicitly conditioning on the frame rate enables OmniTraj to achieve state-of-the-art zero-shot transfer performance, reducing prediction error by over 70\% in challenging cross-setup scenarios. After fine-tuning, OmniTraj achieves state-of-the-art results on four datasets, including NBA, JTA, WorldPose, and ETH-UCY. The code is publicly available: https://github.com/vita-epfl/omnitraj
Towards Generalizable Trajectory Prediction Using Dual-Level Representation Learning And Adaptive Prompting
Jan 08, 2025



Existing vehicle trajectory prediction models struggle with generalizability, prediction uncertainties, and handling complex interactions. It is often due to limitations like complex architectures customized for a specific dataset and inefficient multimodal handling. We propose Perceiver with Register queries (PerReg+), a novel trajectory prediction framework that introduces: (1) Dual-Level Representation Learning via Self-Distillation (SD) and Masked Reconstruction (MR), capturing global context and fine-grained details. Additionally, our approach of reconstructing segmentlevel trajectories and lane segments from masked inputs with query drop, enables effective use of contextual information and improves generalization; (2) Enhanced Multimodality using register-based queries and pretraining, eliminating the need for clustering and suppression; and (3) Adaptive Prompt Tuning during fine-tuning, freezing the main architecture and optimizing a small number of prompts for efficient adaptation. PerReg+ sets a new state-of-the-art performance on nuScenes [1], Argoverse 2 [2], and Waymo Open Motion Dataset (WOMD) [3]. Remarkable, our pretrained model reduces the error by 6.8% on smaller datasets, and multi-dataset training enhances generalization. In cross-domain tests, PerReg+ reduces B-FDE by 11.8% compared to its non-pretrained variant.
Forecast-PEFT: Parameter-Efficient Fine-Tuning for Pre-trained Motion Forecasting Models
Jul 28, 2024



Recent progress in motion forecasting has been substantially driven by self-supervised pre-training. However, adapting pre-trained models for specific downstream tasks, especially motion prediction, through extensive fine-tuning is often inefficient. This inefficiency arises because motion prediction closely aligns with the masked pre-training tasks, and traditional full fine-tuning methods fail to fully leverage this alignment. To address this, we introduce Forecast-PEFT, a fine-tuning strategy that freezes the majority of the model's parameters, focusing adjustments on newly introduced prompts and adapters. This approach not only preserves the pre-learned representations but also significantly reduces the number of parameters that need retraining, thereby enhancing efficiency. This tailored strategy, supplemented by our method's capability to efficiently adapt to different datasets, enhances model efficiency and ensures robust performance across datasets without the need for extensive retraining. Our experiments show that Forecast-PEFT outperforms traditional full fine-tuning methods in motion prediction tasks, achieving higher accuracy with only 17% of the trainable parameters typically required. Moreover, our comprehensive adaptation, Forecast-FT, further improves prediction performance, evidencing up to a 9.6% enhancement over conventional baseline methods. Code will be available at https://github.com/csjfwang/Forecast-PEFT.
Manipulating Trajectory Prediction with Backdoors
Jan 03, 2024



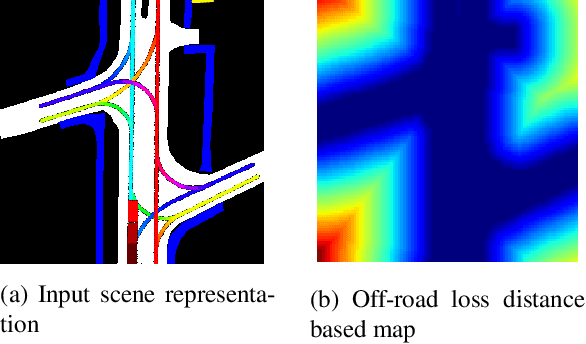
Autonomous vehicles ought to predict the surrounding agents' trajectories to allow safe maneuvers in uncertain and complex traffic situations. As companies increasingly apply trajectory prediction in the real world, security becomes a relevant concern. In this paper, we focus on backdoors - a security threat acknowledged in other fields but so far overlooked for trajectory prediction. To this end, we describe and investigate four triggers that could affect trajectory prediction. We then show that these triggers (for example, a braking vehicle), when correlated with a desired output (for example, a curve) during training, cause the desired output of a state-of-the-art trajectory prediction model. In other words, the model has good benign performance but is vulnerable to backdoors. This is the case even if the trigger maneuver is performed by a non-casual agent behind the target vehicle. As a side-effect, our analysis reveals interesting limitations within trajectory prediction models. Finally, we evaluate a range of defenses against backdoors. While some, like simple offroad checks, do not enable detection for all triggers, clustering is a promising candidate to support manual inspection to find backdoors.
Social-Transmotion: Promptable Human Trajectory Prediction
Dec 26, 2023



Accurate human trajectory prediction is crucial for applications such as autonomous vehicles, robotics, and surveillance systems. Yet, existing models often fail to fully leverage the non-verbal social cues human subconsciously communicate when navigating the space. To address this, we introduce Social-Transmotion, a generic model that exploits the power of transformers to handle diverse and numerous visual cues, capturing the multi-modal nature of human behavior. We translate the idea of a prompt from Natural Language Processing (NLP) to the task of human trajectory prediction, where a prompt can be a sequence of x-y coordinates on the ground, bounding boxes or body poses. This, in turn, augments trajectory data, leading to enhanced human trajectory prediction. Our model exhibits flexibility and adaptability by capturing spatiotemporal interactions between pedestrians based on the available visual cues, whether they are poses, bounding boxes, or a combination thereof. By the masking technique, we ensure our model's effectiveness even when certain visual cues are unavailable, although performance is further boosted with the presence of comprehensive visual data. We delve into the merits of using 2d versus 3d poses, and a limited set of poses. Additionally, we investigate the spatial and temporal attention map to identify which keypoints and frames of poses are vital for optimizing human trajectory prediction. Our approach is validated on multiple datasets, including JTA, JRDB, Pedestrians and Cyclists in Road Traffic, and ETH-UCY. The code is publicly available: https://github.com/vita-epfl/social-transmotion
Trajectory Prediction for Autonomous Driving based on Multi-Head Attention with Joint Agent-Map Representation
Jun 04, 2020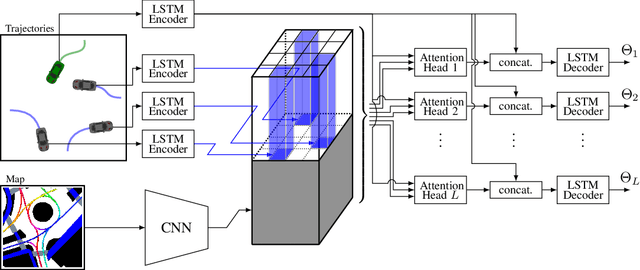

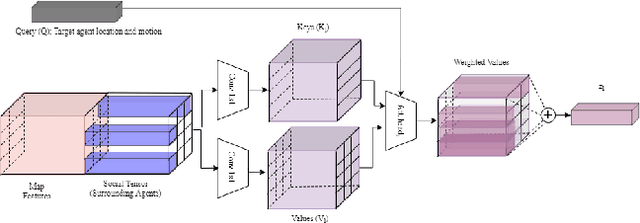
Predicting the trajectories of surrounding agents is an essential ability for robots navigating complex real-world environments. Autonomous vehicles (AV) in particular, can generate safe and efficient path plans by predicting the motion of surrounding road users. Future trajectories of agents can be inferred using two tightly linked cues: the locations and past motion of agents, and the static scene structure. The configuration of the agents may uncover which part of the scene is more relevant, while the scene structure can determine the relative influence of agents on each other's motion. To better model the interdependence of the two cues, we propose a multi-head attention-based model that uses a joint representation of the static scene and agent configuration for generating both keys and values for the attention heads. Moreover, to address the multimodality of future agent motion, we propose to use each attention head to generate a distinct future trajectory of the agent. Our model achieves state of the art results on the publicly available nuScenes dataset and generates diverse future trajectories compliant with scene structure and agent configuration. Additionally, the visualization of attention maps adds a layer of interpretability to the trajectories predicted by the model.