 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABot-OCR Technical Report
May 27, 2026We introduce ABot-OCR, an end-to-end vision-language model that transcribes a page image directly into clean Markdown in a single forward pass. By doing so, our approach completely eliminates the need for brittle modular orchestration. To maximize parsing fidelity, we develop a dedicated data engine to provide large-scale, structurally consistent supervision. Furthermore, we propose Decoupled Heterogeneous Document Optimization, a structure-constrained reinforcement learning method that sharpens textual accuracy and strictly enforces markup well-formedness beyond supervised fine-tuning alone. Extensive evaluations demonstrate the superior performance of our framework. On the OmniDocBench v1.5 and v1.6 benchmarks, ABot-OCR achieves state-of-the-art scores of 92.81 and 93.30 among all end-to-end systems, substantially narrowing the performance gap relative to strong pipeline baselines. Finally, comprehensive multilingual text recognition across ten diverse languages further confirms the robust generalizability of ABot-OCR.
POINav: Benchmarking and Enhancing Final-Meters Arrival in Real-World Vision-Language Navigation
May 27, 2026Real-world navigation is fundamentally driven by Points of Interest (POIs), yet reaching a precise POI remains a critical "final-meters" challenge. Existing Vision-Language Navigation (VLN) benchmarks of POI-goal navigation often suffer from coarse granularity or significant sim-to-real gaps due to generated scene. To bridge this gap, we present POINav-Bench, the first benchmark designed for closed-loop evaluation of real-world POI-goal navigation. It comprises 11 commercial areas reconstructed from real-world captures using 3D Gaussian Splatting (3DGS), covering 126,398 $m^{2}$ in total and spanning 163 distinct POIs. With traversability-aware annotations and reference trajectories, POINav-Bench enables high-fidelity evaluation of navigation agents in realistic, POI-rich real-world environments. Building on this, we propose the POINav Brain-Action Framework where a Brain module performs POI-grounded reasoning to guide an Action module in predicting continuous waypoints for real-world execution. We further curate the POINav-Dataset, containing 70K real-world signage-entrance pairs. Experiments show that our framework provides a viable path toward refining real-world POI-goal navigation.
Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019
Jan 11, 2022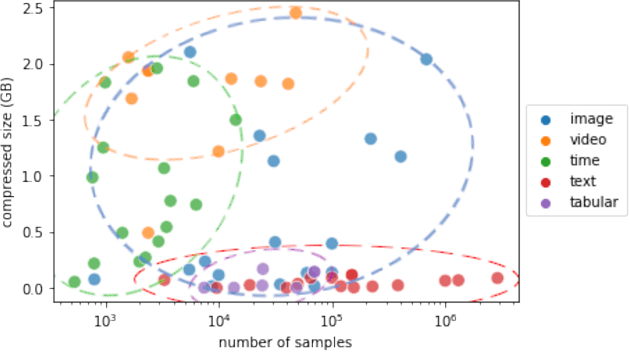
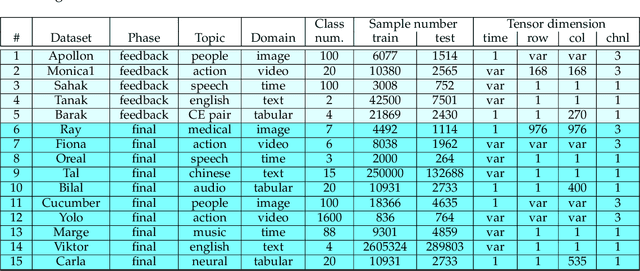
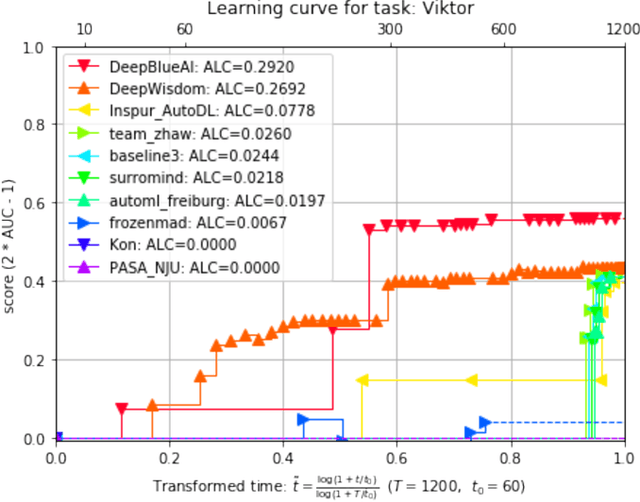
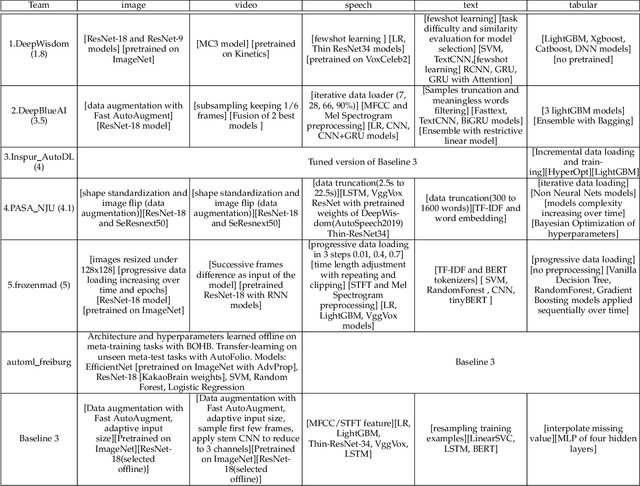
This paper reports the results and post-challenge analyses of ChaLearn's AutoDL challenge series, which helped sorting out a profusion of AutoML solutions for Deep Learning (DL) that had been introduced in a variety of settings, but lacked fair comparisons. All input data modalities (time series, images, videos, text, tabular) were formatted as tensors and all tasks were multi-label classification problems. Code submissions were executed on hidden tasks, with limited time and computational resources, pushing solutions that get results quickly. In this setting, DL methods dominated, though popular Neural Architecture Search (NAS) was impractical. Solutions relied on fine-tuned pre-trained networks, with architectures matching data modality. Post-challenge tests did not reveal improvements beyond the imposed time limit. While no component is particularly original or novel, a high level modular organization emerged featuring a "meta-learner", "data ingestor", "model selector", "model/learner", and "evaluator". This modularity enabled ablation studies, which revealed the importance of (off-platform) meta-learning, ensembling, and efficient data management. Experiments on heterogeneous module combinations further confirm the (local) optimality of the winning solutions. Our challenge legacy includes an ever-lasting benchmark (http://autodl.chalearn.org), the open-sourced code of the winners, and a free "AutoDL self-service".
* The first three authors contributed equally; This is only a draft version