 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaFedFR: Federated Face Recognition with Adaptive Inter-Class Representation Learning
May 22, 2024



With the growing attention on data privacy and communication security in face recognition applications, federated learning has been introduced to learn a face recognition model with decentralized datasets in a privacy-preserving manner. However, existing works still face challenges such as unsatisfying performance and additional communication costs, limiting their applicability in real-world scenarios. In this paper, we propose a simple yet effective federated face recognition framework called AdaFedFR, by devising an adaptive inter-class representation learning algorithm to enhance the generalization of the generic face model and the efficiency of federated training under strict privacy-preservation. In particular, our work delicately utilizes feature representations of public identities as learnable negative knowledge to optimize the local objective within the feature space, which further encourages the local model to learn powerful representations and optimize personalized models for clients. Experimental results demonstrate that our method outperforms previous approaches on several prevalent face recognition benchmarks within less than 3 communication rounds, which shows communication-friendly and great efficiency.
LatentWarp: Consistent Diffusion Latents for Zero-Shot Video-to-Video Translation
Nov 01, 2023



Leveraging the generative ability of image diffusion models offers great potential for zero-shot video-to-video translation. The key lies in how to maintain temporal consistency across generated video frames by image diffusion models. Previous methods typically adopt cross-frame attention, \emph{i.e.,} sharing the \textit{key} and \textit{value} tokens across attentions of different frames, to encourage the temporal consistency. However, in those works, temporal inconsistency issue may not be thoroughly solved, rendering the fidelity of generated videos limited.%The current state of the art cross-frame attention method aims at maintaining fine-grained visual details across frames, but it is still challenged by the temporal coherence problem. In this paper, we find the bottleneck lies in the unconstrained query tokens and propose a new zero-shot video-to-video translation framework, named \textit{LatentWarp}. Our approach is simple: to constrain the query tokens to be temporally consistent, we further incorporate a warping operation in the latent space to constrain the query tokens. Specifically, based on the optical flow obtained from the original video, we warp the generated latent features of last frame to align with the current frame during the denoising process. As a result, the corresponding regions across the adjacent frames can share closely-related query tokens and attention outputs, which can further improve latent-level consistency to enhance visual temporal coherence of generated videos. Extensive experiment results demonstrate the superiority of \textit{LatentWarp} in achieving video-to-video translation with temporal coherence.
A Comprehensive Survey on Cross-modal Retrieval
Jul 21, 2016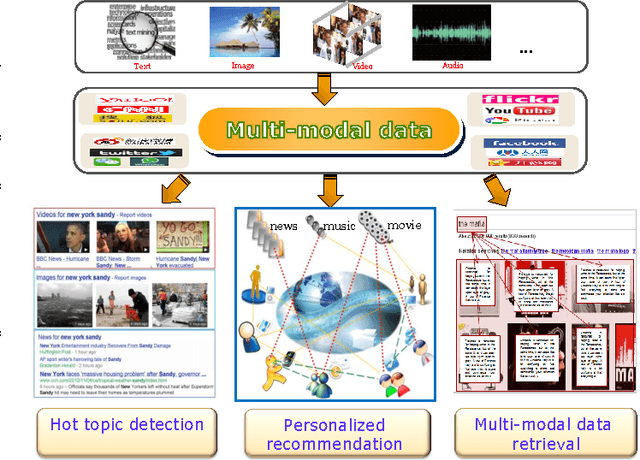
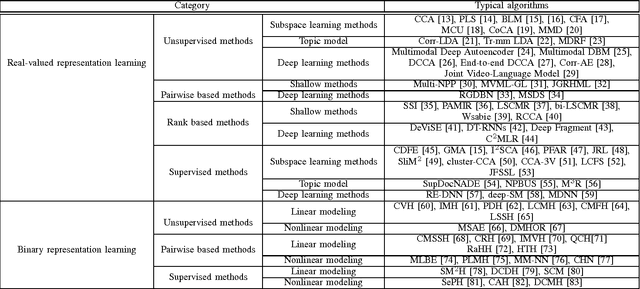


In recent years, cross-modal retrieval has drawn much attention due to the rapid growth of multimodal data. It takes one type of data as the query to retrieve relevant data of another type. For example, a user can use a text to retrieve relevant pictures or videos. Since the query and its retrieved results can be of different modalities, how to measure the content similarity between different modalities of data remains a challenge. Various methods have been proposed to deal with such a problem. In this paper, we first review a number of representative methods for cross-modal retrieval and classify them into two main groups: 1) real-valued representation learning, and 2) binary representation learning. Real-valued representation learning methods aim to learn real-valued common representations for different modalities of data. To speed up the cross-modal retrieval, a number of binary representation learning methods are proposed to map different modalities of data into a common Hamming space. Then, we introduce several multimodal datasets in the community, and show the experimental results on two commonly used multimodal datasets. The comparison reveals the characteristic of different kinds of cross-modal retrieval methods, which is expected to benefit both practical applications and future research. Finally, we discuss open problems and future research directions.