 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025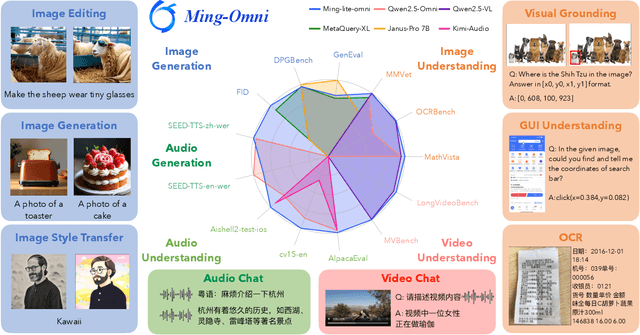
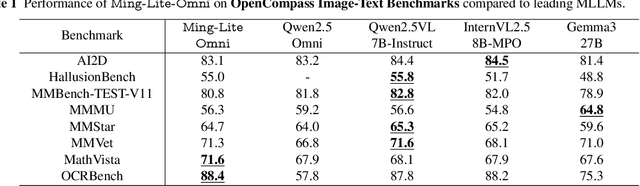
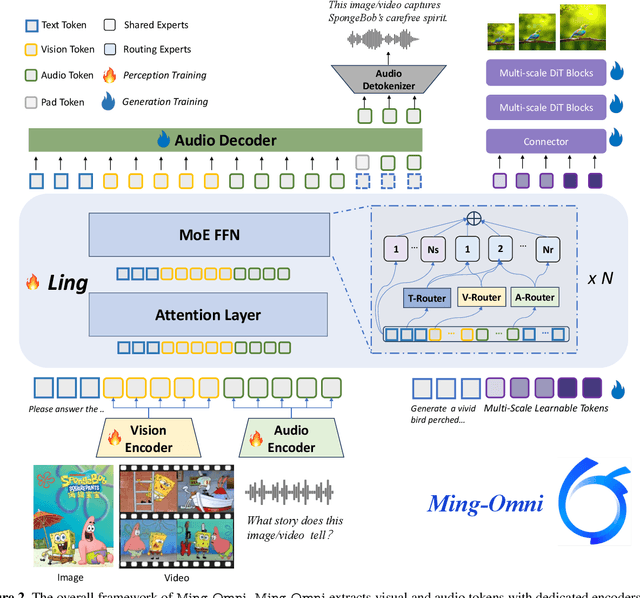
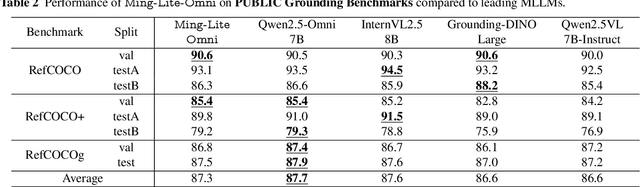
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Improving Cross-lingual Speech Synthesis with Triplet Training Scheme
Feb 22, 2022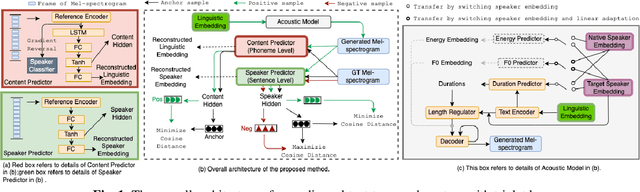
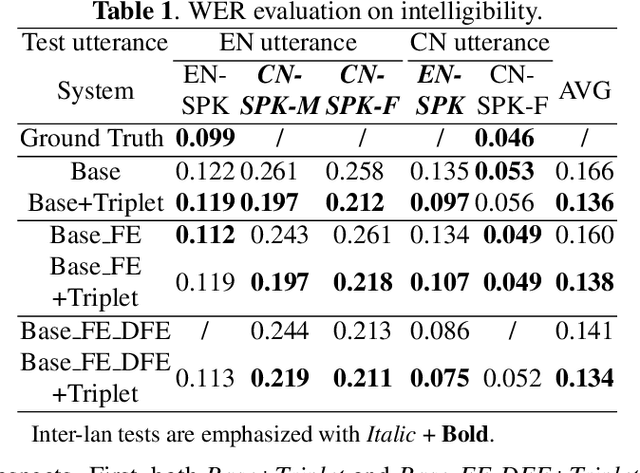
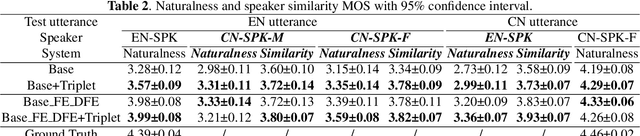
Recent advances in cross-lingual text-to-speech (TTS) made it possible to synthesize speech in a language foreign to a monolingual speaker. However, there is still a large gap between the pronunciation of generated cross-lingual speech and that of native speakers in terms of naturalness and intelligibility. In this paper, a triplet training scheme is proposed to enhance the cross-lingual pronunciation by allowing previously unseen content and speaker combinations to be seen during training. Proposed method introduces an extra fine-tune stage with triplet loss during training, which efficiently draws the pronunciation of the synthesized foreign speech closer to those from the native anchor speaker, while preserving the non-native speaker's timbre. Experiments are conducted based on a state-of-the-art baseline cross-lingual TTS system and its enhanced variants. All the objective and subjective evaluations show the proposed method brings significant improvement in both intelligibility and naturalness of the synthesized cross-lingual speech.