 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLT-Net: Label Transfer by Learning Reversible Voxel-wise Correspondence for One-shot Medical Image Segmentation
Mar 20, 2020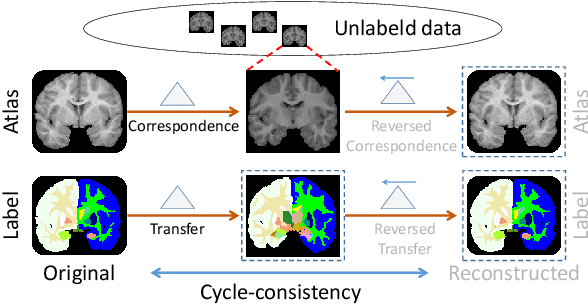
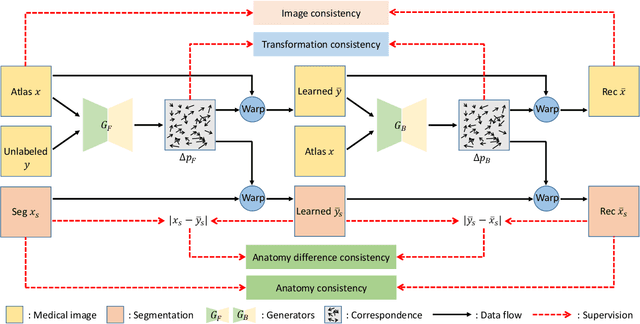
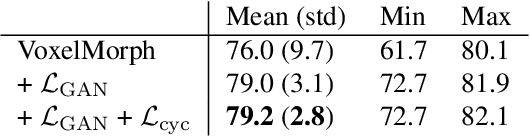
We introduce a one-shot segmentation method to alleviate the burden of manual annotation for medical images. The main idea is to treat one-shot segmentation as a classical atlas-based segmentation problem, where voxel-wise correspondence from the atlas to the unlabelled data is learned. Subsequently, segmentation label of the atlas can be transferred to the unlabelled data with the learned correspondence. However, since ground truth correspondence between images is usually unavailable, the learning system must be well-supervised to avoid mode collapse and convergence failure. To overcome this difficulty, we resort to the forward-backward consistency, which is widely used in correspondence problems, and additionally learn the backward correspondences from the warped atlases back to the original atlas. This cycle-correspondence learning design enables a variety of extra, cycle-consistency-based supervision signals to make the training process stable, while also boost the performance. We demonstrate the superiority of our method over both deep learning-based one-shot segmentation methods and a classical multi-atlas segmentation method via thorough experiments.
Quality Control of Neuron Reconstruction Based on Deep Learning
Mar 19, 2020
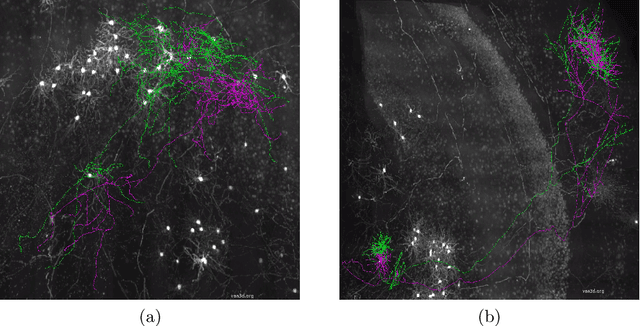
Neuron reconstruction is essential to generate exquisite neuron connectivity map for understanding brain function. Despite the significant amount of effect that has been made on automatic reconstruction methods, manual tracing by well-trained human annotators is still necessary. To ensure the quality of reconstructed neurons and provide guidance for annotators to improve their efficiency, we propose a deep learning based quality control method for neuron reconstruction in this paper. By formulating the quality control problem into a binary classification task regarding each single point, the proposed approach overcomes the technical difficulties resulting from the large image size and complex neuron morphology. Not only it provides the evaluation of reconstruction quality, but also can locate exactly where the wrong tracing begins. This work presents one of the first comprehensive studies for whole-brain scale quality control of neuron reconstructions. Experiments on five-fold cross validation with a large dataset demonstrate that the proposed approach can detect 74.7% errors with only 1.4% false alerts.
Identification of primary angle-closure on AS-OCT images with Convolutional Neural Networks
Oct 23, 2019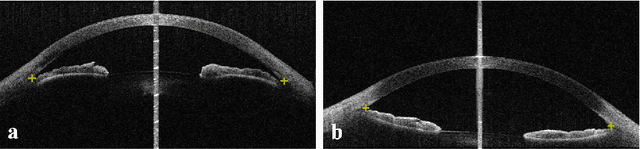
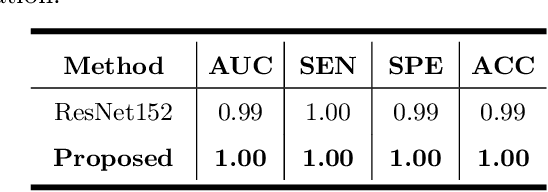
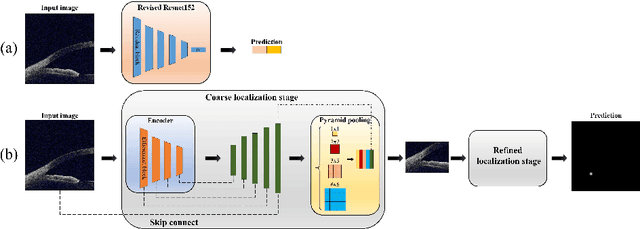
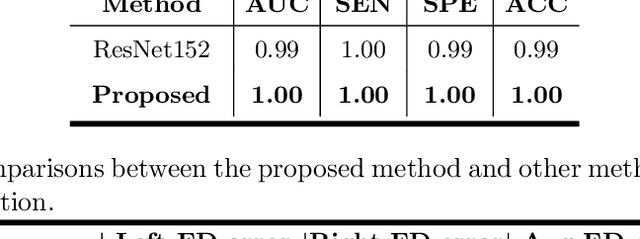
Primary angle-closure disease (PACD) is a severe retinal disease, which might cause irreversible vision loss. In clinic, accurate identification of angle-closure and localization of the scleral spur's position on anterior segment optical coherence tomography (AS-OCT) is essential for the diagnosis of PACD. However, manual delineation might confine in low accuracy and low efficiency. In this paper, we propose an efficient and accurate end-to-end architecture for angle-closure classification and scleral spur localization. Specifically, we utilize a revised ResNet152 as our backbone to improve the accuracy of the angle-closure identification. For scleral spur localization, we adopt EfficientNet as encoder because of its powerful feature extraction potential. By combining the skip-connect module and pyramid pooling module, the network is able to collect semantic cues in feature maps from multiple dimensions and scales. Afterward, we propose a novel keypoint registration loss to constrain the model's attention to the intensity and location of the scleral spur area. Several experiments are extensively conducted to evaluate our method on the angle-closure glaucoma evaluation (AGE) Challenge dataset. The results show that our proposed architecture ranks the first place of the classification task on the test dataset and achieves the average Euclidean distance error of 12.00 pixels in the scleral spur localization task.
Self-supervised Feature Learning for 3D Medical Images by Playing a Rubik's Cube
Oct 05, 2019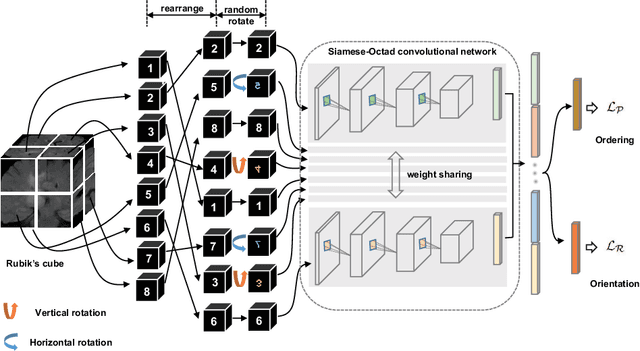
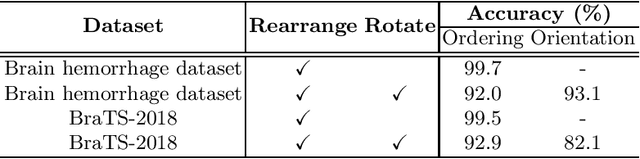
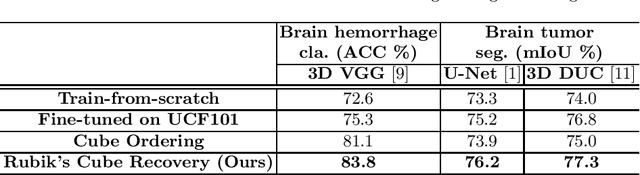
Witnessed the development of deep learning, increasing number of studies try to build computer aided diagnosis systems for 3D volumetric medical data. However, as the annotations of 3D medical data are difficult to acquire, the number of annotated 3D medical images is often not enough to well train the deep learning networks. The self-supervised learning deeply exploiting the information of raw data is one of the potential solutions to loose the requirement of training data. In this paper, we propose a self-supervised learning framework for the volumetric medical images. A novel proxy task, i.e., Rubik's cube recovery, is formulated to pre-train 3D neural networks. The proxy task involves two operations, i.e., cube rearrangement and cube rotation, which enforce networks to learn translational and rotational invariant features from raw 3D data. Compared to the train-from-scratch strategy, fine-tuning from the pre-trained network leads to a better accuracy on various tasks, e.g., brain hemorrhage classification and brain tumor segmentation. We show that our self-supervised learning approach can substantially boost the accuracies of 3D deep learning networks on the volumetric medical datasets without using extra data. To our best knowledge, this is the first work focusing on the self-supervised learning of 3D neural networks.
Uncertainty-Guided Domain Alignment for Layer Segmentation in OCT Images
Aug 30, 2019
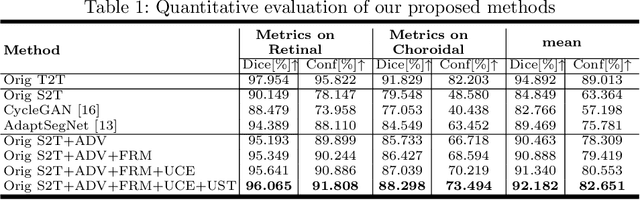
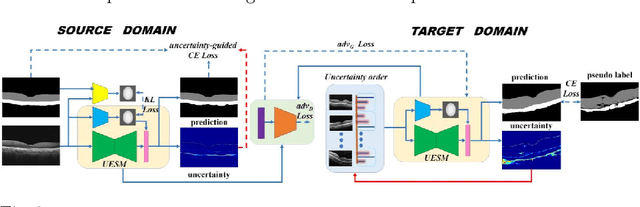
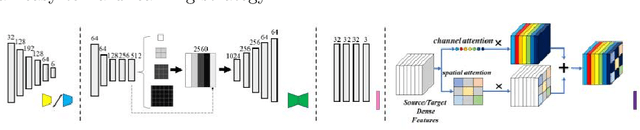
Automatic and accurate segmentation for retinal and choroidal layers of Optical Coherence Tomography (OCT) is crucial for detection of various ocular diseases. However, because of the variations in different equipments, OCT data obtained from different manufacturers might encounter appearance discrepancy, which could lead to performance fluctuation to a deep neural network. In this paper, we propose an uncertainty-guided domain alignment method to aim at alleviating this problem to transfer discriminative knowledge across distinct domains. We disign a novel uncertainty-guided cross-entropy loss for boosting the performance over areas with high uncertainty. An uncertainty-guided curriculum transfer strategy is developed for the self-training (ST), which regards uncertainty as efficient and effective guidance to optimize the learning process in target domain. Adversarial learning with feature recalibration module (FRM) is applied to transfer informative knowledge from the domain feature spaces adaptively. The experiments on two OCT datasets show that the proposed methods can obtain significant segmentation improvements compared with the baseline models.
Semi-supervised Breast Lesion Detection in Ultrasound Video Based on Temporal Coherence
Jul 16, 2019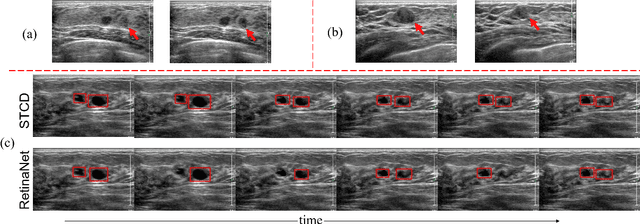

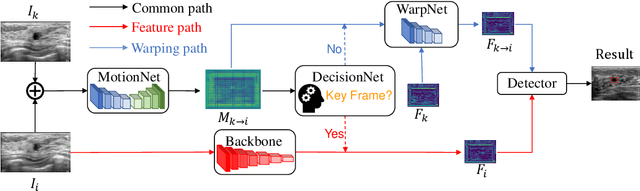
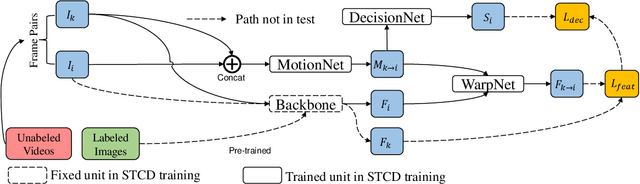
Breast lesion detection in ultrasound video is critical for computer-aided diagnosis. However, detecting lesion in video is quite challenging due to the blurred lesion boundary, high similarity to soft tissue and lack of video annotations. In this paper, we propose a semi-supervised breast lesion detection method based on temporal coherence which can detect the lesion more accurately. We aggregate features extracted from the historical key frames with adaptive key-frame scheduling strategy. Our proposed method accomplishes the unlabeled videos detection task by leveraging the supervision information from a different set of labeled images. In addition, a new WarpNet is designed to replace both the traditional spatial warping and feature aggregation operation, leading to a tremendous increase in speed. Experiments on 1,060 2D ultrasound sequences demonstrate that our proposed method achieves state-of-the-art video detection result as 91.3% in mean average precision and 19 ms per frame on GPU, compared to a RetinaNet based detection method in 86.6% and 32 ms.
Attentive CT Lesion Detection Using Deep Pyramid Inference with Multi-Scale Booster
Jul 09, 2019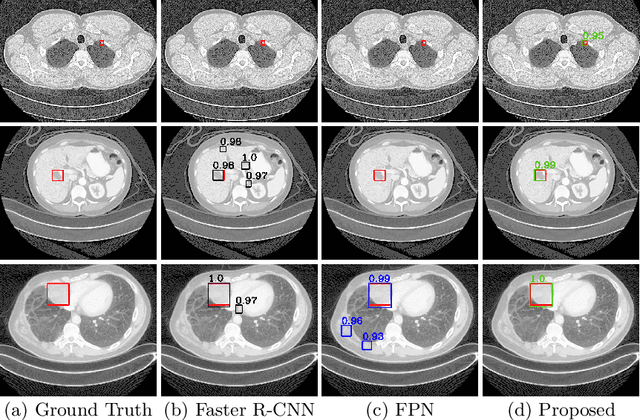
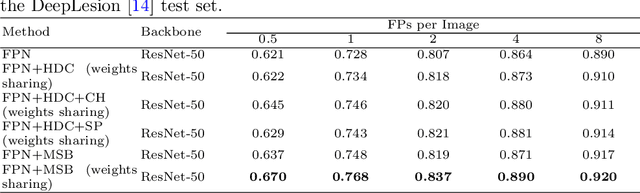
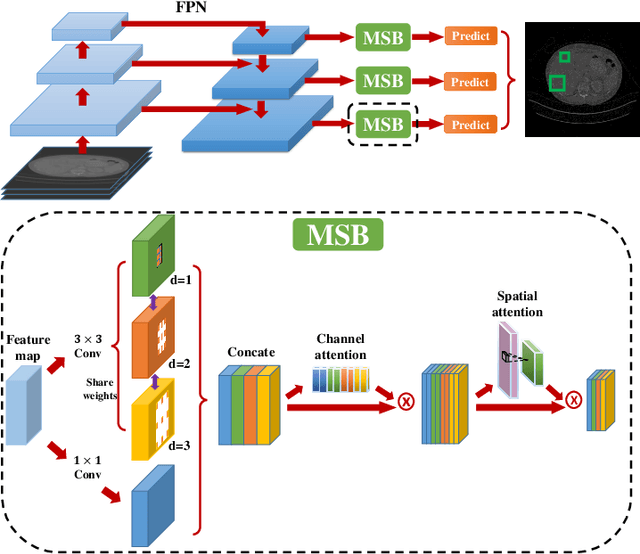
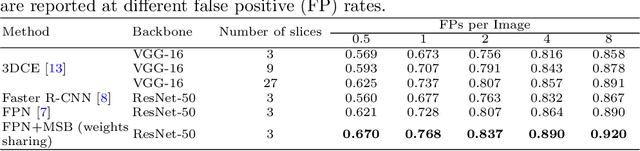
Accurate lesion detection in computer tomography (CT) slices benefits pathologic organ analysis in the medical diagnosis process. More recently, it has been tackled as an object detection problem using the Convolutional Neural Networks (CNNs). Despite the achievements from off-the-shelf CNN models, the current detection accuracy is limited by the inability of CNNs on lesions at vastly different scales. In this paper, we propose a Multi-Scale Booster (MSB) with channel and spatial attention integrated into the backbone Feature Pyramid Network (FPN). In each pyramid level, the proposed MSB captures fine-grained scale variations by using Hierarchically Dilated Convolutions (HDC). Meanwhile, the proposed channel and spatial attention modules increase the network's capability of selecting relevant features response for lesion detection. Extensive experiments on the DeepLesion benchmark dataset demonstrate that the proposed method performs superiorly against state-of-the-art approaches.
X2CT-GAN: Reconstructing CT from Biplanar X-Rays with Generative Adversarial Networks
May 16, 2019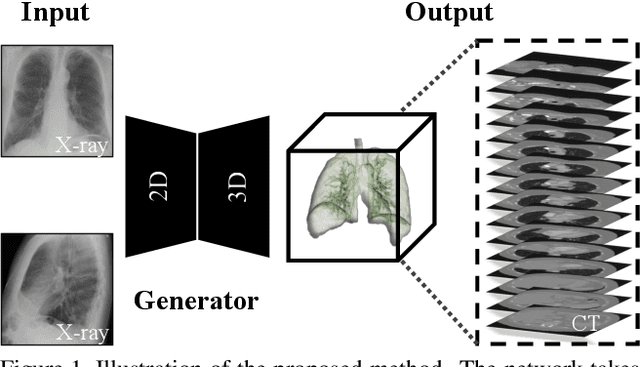
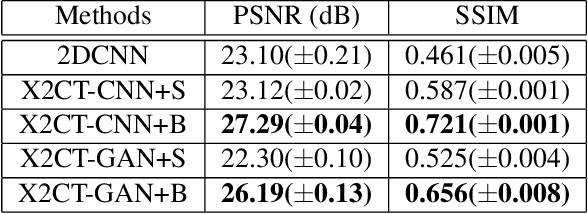
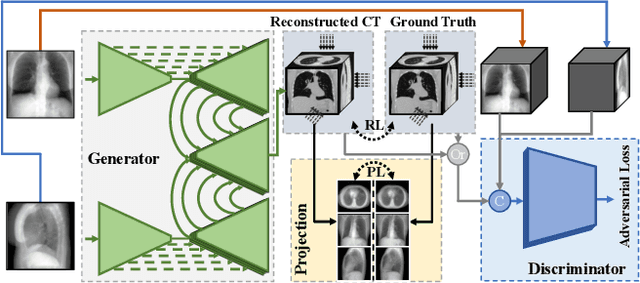
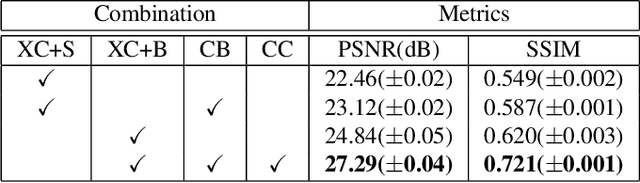
Computed tomography (CT) can provide a 3D view of the patient's internal organs, facilitating disease diagnosis, but it incurs more radiation dose to a patient and a CT scanner is much more cost prohibitive than an X-ray machine too. Traditional CT reconstruction methods require hundreds of X-ray projections through a full rotational scan of the body, which cannot be performed on a typical X-ray machine. In this work, we propose to reconstruct CT from two orthogonal X-rays using the generative adversarial network (GAN) framework. A specially designed generator network is exploited to increase data dimension from 2D (X-rays) to 3D (CT), which is not addressed in previous research of GAN. A novel feature fusion method is proposed to combine information from two X-rays.The mean squared error (MSE) loss and adversarial loss are combined to train the generator, resulting in a high-quality CT volume both visually and quantitatively. Extensive experiments on a publicly available chest CT dataset demonstrate the effectiveness of the proposed method. It could be a nice enhancement of a low-cost X-ray machine to provide physicians a CT-like 3D volume in several niche applications.
Med3D: Transfer Learning for 3D Medical Image Analysis
Apr 09, 2019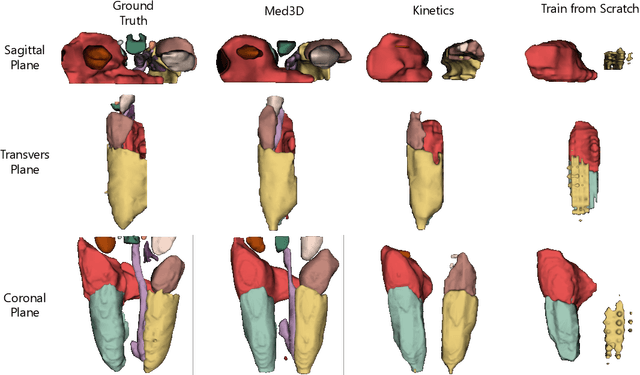
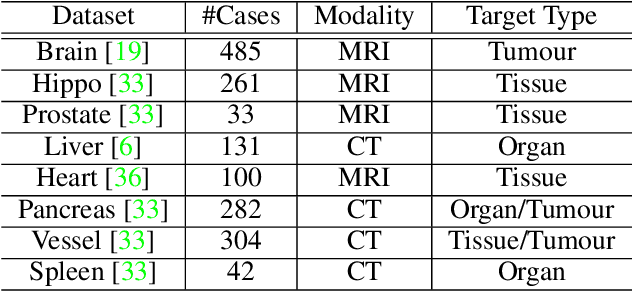
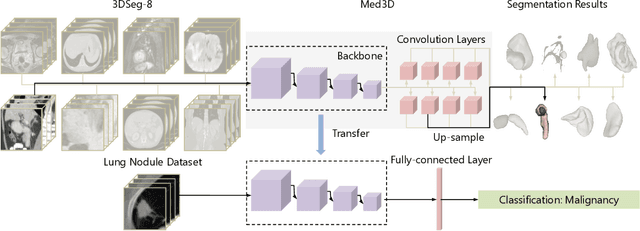
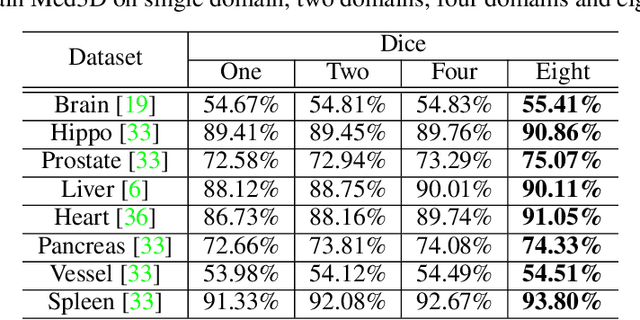
The performance on deep learning is significantly affected by volume of training data. Models pre-trained from massive dataset such as ImageNet become a powerful weapon for speeding up training convergence and improving accuracy. Similarly, models based on large dataset are important for the development of deep learning in 3D medical images. However, it is extremely challenging to build a sufficiently large dataset due to difficulty of data acquisition and annotation in 3D medical imaging. We aggregate the dataset from several medical challenges to build 3DSeg-8 dataset with diverse modalities, target organs, and pathologies. To extract general medical three-dimension (3D) features, we design a heterogeneous 3D network called Med3D to co-train multi-domain 3DSeg-8 so as to make a series of pre-trained models. We transfer Med3D pre-trained models to lung segmentation in LIDC dataset, pulmonary nodule classification in LIDC dataset and liver segmentation on LiTS challenge. Experiments show that the Med3D can accelerate the training convergence speed of target 3D medical tasks 2 times compared with model pre-trained on Kinetics dataset, and 10 times compared with training from scratch as well as improve accuracy ranging from 3% to 20%. Transferring our Med3D model on state-the-of-art DenseASPP segmentation network, in case of single model, we achieve 94.6\% Dice coefficient which approaches the result of top-ranged algorithms on the LiTS challenge.
TAN: Temporal Affine Network for Real-Time Left Ventricle Anatomical Structure Analysis Based on 2D Ultrasound Videos
Apr 01, 2019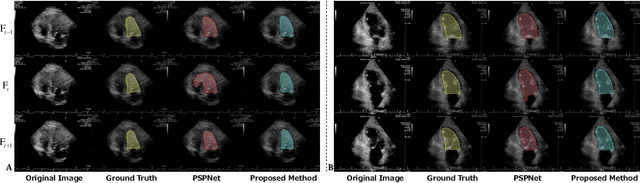
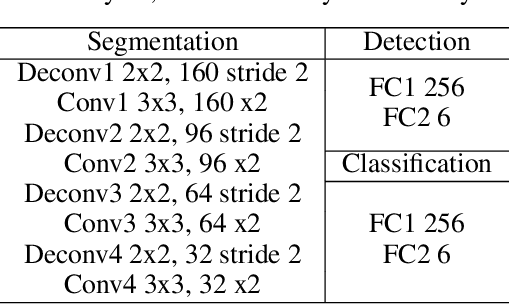
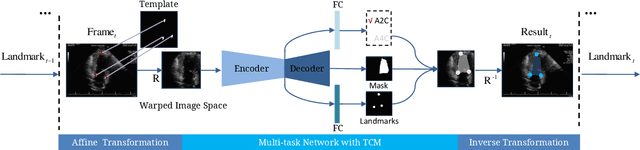
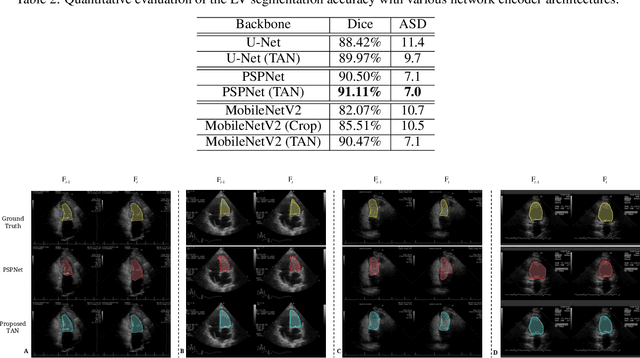
With superiorities on low cost, portability, and free of radiation, echocardiogram is a widely used imaging modality for left ventricle (LV) function quantification. However, automatic LV segmentation and motion tracking is still a challenging task. In addition to fuzzy border definition, low contrast, and abounding artifacts on typical ultrasound images, the shape and size of the LV change significantly in a cardiac cycle. In this work, we propose a temporal affine network (TAN) to perform image analysis in a warped image space, where the shape and size variations due to the cardiac motion as well as other artifacts are largely compensated. Furthermore, we perform three frequent echocardiogram interpretation tasks simultaneously: standard cardiac plane recognition, LV landmark detection, and LV segmentation. Instead of using three networks with one dedicating to each task, we use a multi-task network to perform three tasks simultaneously. Since three tasks share the same encoder, the compact network improves the segmentation accuracy with more supervision. The network is further finetuned with optical flow adjusted annotations to enhance motion coherence in the segmentation result. Experiments on 1,714 2D echocardiographic sequences demonstrate that the proposed method achieves state-of-the-art segmentation accuracy with real-time efficiency.