 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Controller Networks for Real-Time Decision-Making in Embodied Learning
May 30, 2024Reinforcement learning is able to obtain generalized low-level robot policies on diverse robotics datasets in embodied learning scenarios, and Transformer has been widely used to model time-varying features. However, it still suffers from the issues of low data efficiency and high inference latency. In this paper, we propose to investigate the task from a new perspective of the frequency domain. We first observe that the energy density in the frequency domain of a robot's trajectory is mainly concentrated in the low-frequency part. Then, we present the Fourier Controller Network (FCNet), a new network that utilizes the Short-Time Fourier Transform (STFT) to extract and encode time-varying features through frequency domain interpolation. We further achieve parallel training and efficient recurrent inference by using FFT and Sliding DFT methods in the model architecture for real-time decision-making. Comprehensive analyses in both simulated (e.g., D4RL) and real-world environments (e.g., robot locomotion) demonstrate FCNet's substantial efficiency and effectiveness over existing methods such as Transformer, e.g., FCNet outperforms Transformer on multi-environmental robotics datasets of all types of sizes (from 1.9M to 120M). The project page and code can be found https://thkkk.github.io/fcnet.
StableDrag: Stable Dragging for Point-based Image Editing
Mar 07, 2024



Point-based image editing has attracted remarkable attention since the emergence of DragGAN. Recently, DragDiffusion further pushes forward the generative quality via adapting this dragging technique to diffusion models. Despite these great success, this dragging scheme exhibits two major drawbacks, namely inaccurate point tracking and incomplete motion supervision, which may result in unsatisfactory dragging outcomes. To tackle these issues, we build a stable and precise drag-based editing framework, coined as StableDrag, by designing a discirminative point tracking method and a confidence-based latent enhancement strategy for motion supervision. The former allows us to precisely locate the updated handle points, thereby boosting the stability of long-range manipulation, while the latter is responsible for guaranteeing the optimized latent as high-quality as possible across all the manipulation steps. Thanks to these unique designs, we instantiate two types of image editing models including StableDrag-GAN and StableDrag-Diff, which attains more stable dragging performance, through extensive qualitative experiments and quantitative assessment on DragBench.
Adversarial Medical Image with Hierarchical Feature Hiding
Dec 04, 2023Deep learning based methods for medical images can be easily compromised by adversarial examples (AEs), posing a great security flaw in clinical decision-making. It has been discovered that conventional adversarial attacks like PGD which optimize the classification logits, are easy to distinguish in the feature space, resulting in accurate reactive defenses. To better understand this phenomenon and reassess the reliability of the reactive defenses for medical AEs, we thoroughly investigate the characteristic of conventional medical AEs. Specifically, we first theoretically prove that conventional adversarial attacks change the outputs by continuously optimizing vulnerable features in a fixed direction, thereby leading to outlier representations in the feature space. Then, a stress test is conducted to reveal the vulnerability of medical images, by comparing with natural images. Interestingly, this vulnerability is a double-edged sword, which can be exploited to hide AEs. We then propose a simple-yet-effective hierarchical feature constraint (HFC), a novel add-on to conventional white-box attacks, which assists to hide the adversarial feature in the target feature distribution. The proposed method is evaluated on three medical datasets, both 2D and 3D, with different modalities. The experimental results demonstrate the superiority of HFC, \emph{i.e.,} it bypasses an array of state-of-the-art adversarial medical AE detectors more efficiently than competing adaptive attacks, which reveals the deficiencies of medical reactive defense and allows to develop more robust defenses in future.
A New Perspective to Boost Vision Transformer for Medical Image Classification
Jan 03, 2023Transformer has achieved impressive successes for various computer vision tasks. However, most of existing studies require to pretrain the Transformer backbone on a large-scale labeled dataset (e.g., ImageNet) for achieving satisfactory performance, which is usually unavailable for medical images. Additionally, due to the gap between medical and natural images, the improvement generated by the ImageNet pretrained weights significantly degrades while transferring the weights to medical image processing tasks. In this paper, we propose Bootstrap Own Latent of Transformer (BOLT), a self-supervised learning approach specifically for medical image classification with the Transformer backbone. Our BOLT consists of two networks, namely online and target branches, for self-supervised representation learning. Concretely, the online network is trained to predict the target network representation of the same patch embedding tokens with a different perturbation. To maximally excavate the impact of Transformer from limited medical data, we propose an auxiliary difficulty ranking task. The Transformer is enforced to identify which branch (i.e., online/target) is processing the more difficult perturbed tokens. Overall, the Transformer endeavours itself to distill the transformation-invariant features from the perturbed tokens to simultaneously achieve difficulty measurement and maintain the consistency of self-supervised representations. The proposed BOLT is evaluated on three medical image processing tasks, i.e., skin lesion classification, knee fatigue fracture grading and diabetic retinopathy grading. The experimental results validate the superiority of our BOLT for medical image classification, compared to ImageNet pretrained weights and state-of-the-art self-supervised learning approaches.
A Trustworthy Framework for Medical Image Analysis with Deep Learning
Dec 06, 2022Computer vision and machine learning are playing an increasingly important role in computer-assisted diagnosis; however, the application of deep learning to medical imaging has challenges in data availability and data imbalance, and it is especially important that models for medical imaging are built to be trustworthy. Therefore, we propose TRUDLMIA, a trustworthy deep learning framework for medical image analysis, which adopts a modular design, leverages self-supervised pre-training, and utilizes a novel surrogate loss function. Experimental evaluations indicate that models generated from the framework are both trustworthy and high-performing. It is anticipated that the framework will support researchers and clinicians in advancing the use of deep learning for dealing with public health crises including COVID-19.
Seg4Reg+: Consistency Learning between Spine Segmentation and Cobb Angle Regression
Aug 26, 2022Automated methods for Cobb angle estimation are of high demand for scoliosis assessment. Existing methods typically calculate the Cobb angle from landmark estimation, or simply combine the low-level task (e.g., landmark detection and spine segmentation) with the Cobb angle regression task, without fully exploring the benefits from each other. In this study, we propose a novel multi-task framework, named Seg4Reg+, which jointly optimizes the segmentation and regression networks. We thoroughly investigate both local and global consistency and knowledge transfer between each other. Specifically, we propose an attention regularization module leveraging class activation maps (CAMs) from image-segmentation pairs to discover additional supervision in the regression network, and the CAMs can serve as a region-of-interest enhancement gate to facilitate the segmentation task in turn. Meanwhile, we design a novel triangle consistency learning to train the two networks jointly for global optimization. The evaluations performed on the public AASCE Challenge dataset demonstrate the effectiveness of each module and superior performance of our model to the state-of-the-art methods.
Towards Trustworthy Healthcare AI: Attention-Based Feature Learning for COVID-19 Screening With Chest Radiography
Jul 19, 2022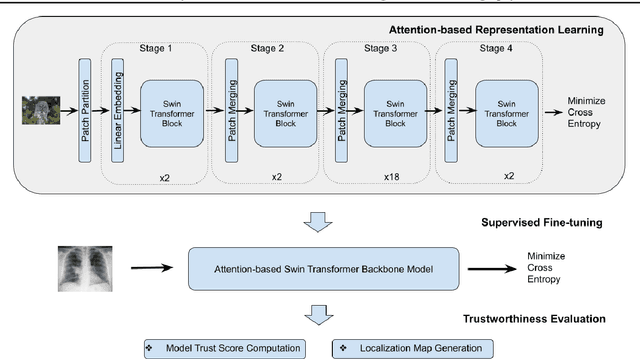
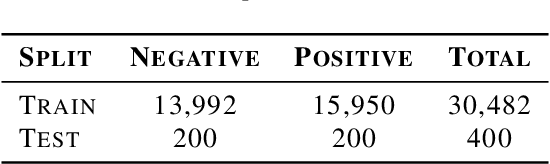

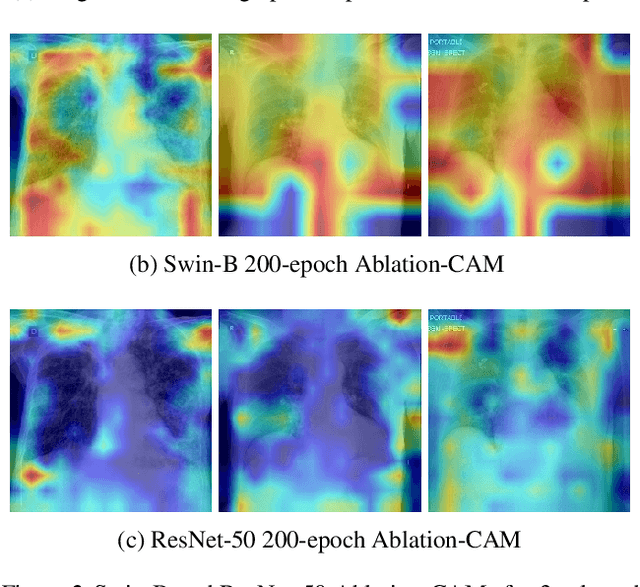
Building AI models with trustworthiness is important especially in regulated areas such as healthcare. In tackling COVID-19, previous work uses convolutional neural networks as the backbone architecture, which has shown to be prone to over-caution and overconfidence in making decisions, rendering them less trustworthy -- a crucial flaw in the context of medical imaging. In this study, we propose a feature learning approach using Vision Transformers, which use an attention-based mechanism, and examine the representation learning capability of Transformers as a new backbone architecture for medical imaging. Through the task of classifying COVID-19 chest radiographs, we investigate into whether generalization capabilities benefit solely from Vision Transformers' architectural advances. Quantitative and qualitative evaluations are conducted on the trustworthiness of the models, through the use of "trust score" computation and a visual explainability technique. We conclude that the attention-based feature learning approach is promising in building trustworthy deep learning models for healthcare.
Dense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation
Jul 18, 2022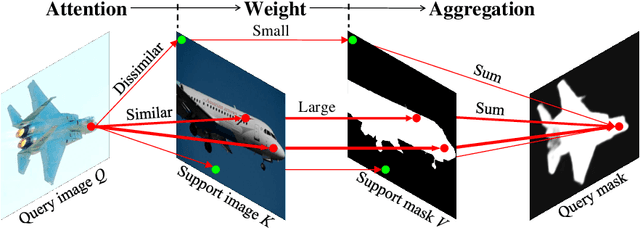
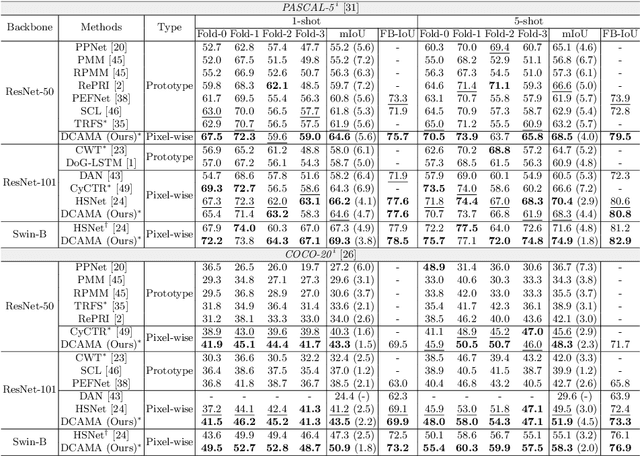
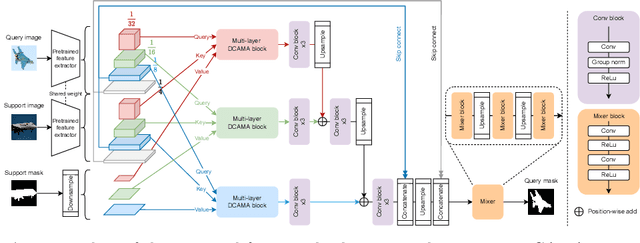
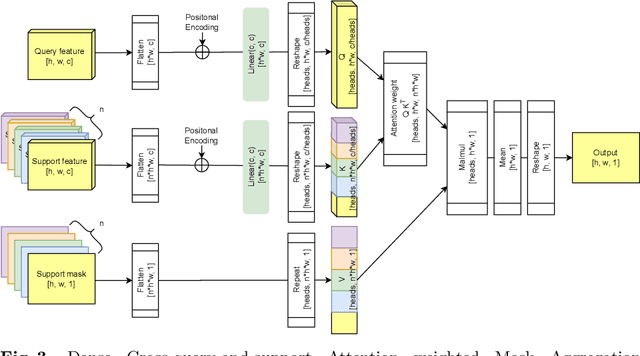
Research into Few-shot Semantic Segmentation (FSS) has attracted great attention, with the goal to segment target objects in a query image given only a few annotated support images of the target class. A key to this challenging task is to fully utilize the information in the support images by exploiting fine-grained correlations between the query and support images. However, most existing approaches either compressed the support information into a few class-wise prototypes, or used partial support information (e.g., only foreground) at the pixel level, causing non-negligible information loss. In this paper, we propose Dense pixel-wise Cross-query-and-support Attention weighted Mask Aggregation (DCAMA), where both foreground and background support information are fully exploited via multi-level pixel-wise correlations between paired query and support features. Implemented with the scaled dot-product attention in the Transformer architecture, DCAMA treats every query pixel as a token, computes its similarities with all support pixels, and predicts its segmentation label as an additive aggregation of all the support pixels' labels -- weighted by the similarities. Based on the unique formulation of DCAMA, we further propose efficient and effective one-pass inference for n-shot segmentation, where pixels of all support images are collected for the mask aggregation at once. Experiments show that our DCAMA significantly advances the state of the art on standard FSS benchmarks of PASCAL-5i, COCO-20i, and FSS-1000, e.g., with 3.1%, 9.7%, and 3.6% absolute improvements in 1-shot mIoU over previous best records. Ablative studies also verify the design DCAMA.
Learning Shape Priors by Pairwise Comparison for Robust Semantic Segmentation
Apr 23, 2022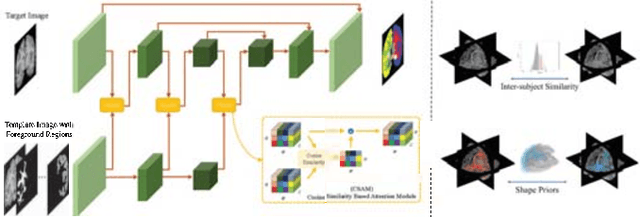
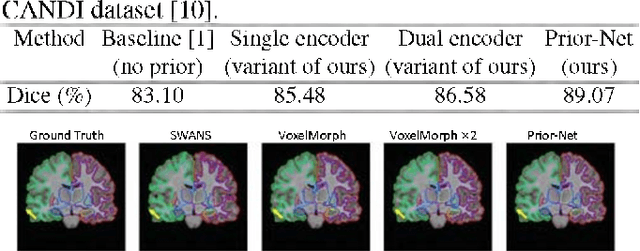
Semantic segmentation is important in medical image analysis. Inspired by the strong ability of traditional image analysis techniques in capturing shape priors and inter-subject similarity, many deep learning (DL) models have been recently proposed to exploit such prior information and achieved robust performance. However, these two types of important prior information are usually studied separately in existing models. In this paper, we propose a novel DL model to model both type of priors within a single framework. Specifically, we introduce an extra encoder into the classic encoder-decoder structure to form a Siamese structure for the encoders, where one of them takes a target image as input (the image-encoder), and the other concatenates a template image and its foreground regions as input (the template-encoder). The template-encoder encodes the shape priors and appearance characteristics of each foreground class in the template image. A cosine similarity based attention module is proposed to fuse the information from both encoders, to utilize both types of prior information encoded by the template-encoder and model the inter-subject similarity for each foreground class. Extensive experiments on two public datasets demonstrate that our proposed method can produce superior performance to competing methods.
DFTR: Depth-supervised Fusion Transformer for Salient Object Detection
Apr 11, 2022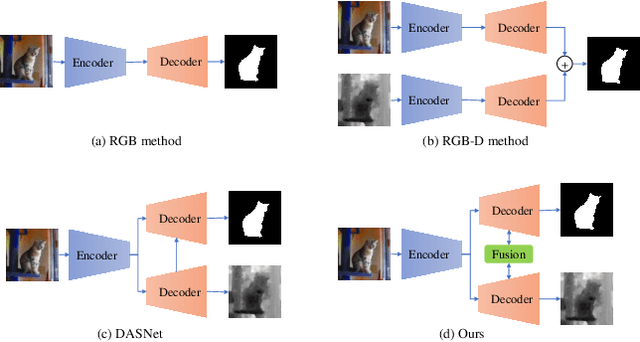
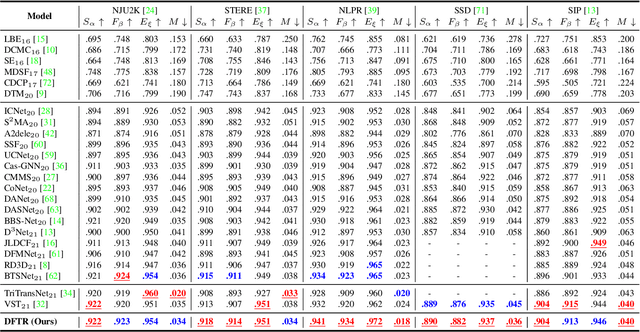
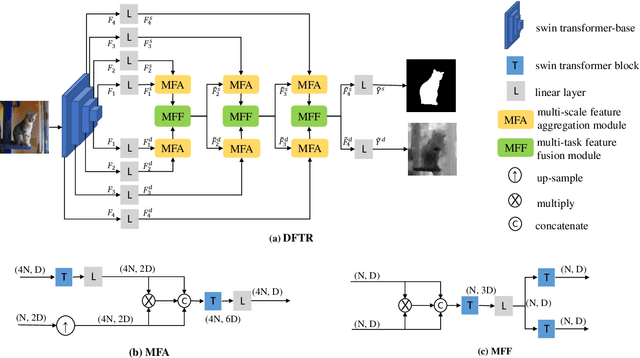
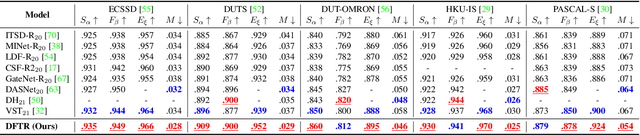
Automated salient object detection (SOD) plays an increasingly crucial role in many computer vision applications. By reformulating the depth information as supervision rather than as input, depth-supervised convolutional neural networks (CNN) have achieved promising results on both RGB and RGB-D SOD scenarios with the merits of no requirements for extra depth networks and depth inputs in the inference stage. This paper, for the first time, seeks to expand the applicability of depth supervision to the Transformer architecture. Specifically, we develop a Depth-supervised Fusion TRansformer (DFTR), to further improve the accuracy of both RGB and RGB-D SOD. The proposed DFTR involves three primary features: 1) DFTR, to the best of our knowledge, is the first pure Transformer-based model for depth-supervised SOD; 2) A multi-scale feature aggregation (MFA) module is proposed to fully exploit the multi-scale features encoded by the Swin Transformer in a coarse-to-fine manner; 3) To enable bidirectional information flow across different streams of features, a novel multi-stage feature fusion (MFF) module is further integrated into our DFTR with the emphasis on salient regions at different network learning stages. We extensively evaluate the proposed DFTR on ten benchmarking datasets. Experimental results show that our DFTR consistently outperforms the existing state-of-the-art methods for both RGB and RGB-D SOD tasks. The code and model will be made publicly available.