 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Few-Shot Ensemble Learning with Focal Diversity-Based Pruning
Apr 05, 2024



This paper presents FusionShot, a focal diversity optimized few-shot ensemble learning approach for boosting the robustness and generalization performance of pre-trained few-shot models. The paper makes three original contributions. First, we explore the unique characteristics of few-shot learning to ensemble multiple few-shot (FS) models by creating three alternative fusion channels. Second, we introduce the concept of focal error diversity to learn the most efficient ensemble teaming strategy, rather than assuming that an ensemble of a larger number of base models will outperform those sub-ensembles of smaller size. We develop a focal-diversity ensemble pruning method to effectively prune out the candidate ensembles with low ensemble error diversity and recommend top-$K$ FS ensembles with the highest focal error diversity. Finally, we capture the complex non-linear patterns of ensemble few-shot predictions by designing the learn-to-combine algorithm, which can learn the diverse weight assignments for robust ensemble fusion over different member models. Extensive experiments on representative few-shot benchmarks show that the top-K ensembles recommended by FusionShot can outperform the representative SOTA few-shot models on novel tasks (different distributions and unknown at training), and can prevail over existing few-shot learners in both cross-domain settings and adversarial settings. For reproducibility purposes, FusionShot trained models, results, and code are made available at https://github.com/sftekin/fusionshot
A Survey of Privacy Threats and Defense in Vertical Federated Learning: From Model Life Cycle Perspective
Feb 06, 2024Vertical Federated Learning (VFL) is a federated learning paradigm where multiple participants, who share the same set of samples but hold different features, jointly train machine learning models. Although VFL enables collaborative machine learning without sharing raw data, it is still susceptible to various privacy threats. In this paper, we conduct the first comprehensive survey of the state-of-the-art in privacy attacks and defenses in VFL. We provide taxonomies for both attacks and defenses, based on their characterizations, and discuss open challenges and future research directions. Specifically, our discussion is structured around the model's life cycle, by delving into the privacy threats encountered during different stages of machine learning and their corresponding countermeasures. This survey not only serves as a resource for the research community but also offers clear guidance and actionable insights for practitioners to safeguard data privacy throughout the model's life cycle.
Imperio: Language-Guided Backdoor Attacks for Arbitrary Model Control
Jan 02, 2024Revolutionized by the transformer architecture, natural language processing (NLP) has received unprecedented attention. While advancements in NLP models have led to extensive research into their backdoor vulnerabilities, the potential for these advancements to introduce new backdoor threats remains unexplored. This paper proposes Imperio, which harnesses the language understanding capabilities of NLP models to enrich backdoor attacks. Imperio provides a new model control experience. It empowers the adversary to control the victim model with arbitrary output through language-guided instructions. This is achieved using a language model to fuel a conditional trigger generator, with optimizations designed to extend its language understanding capabilities to backdoor instruction interpretation and execution. Our experiments across three datasets, five attacks, and nine defenses confirm Imperio's effectiveness. It can produce contextually adaptive triggers from text descriptions and control the victim model with desired outputs, even in scenarios not encountered during training. The attack maintains a high success rate across complex datasets without compromising the accuracy of clean inputs and also exhibits resilience against representative defenses. The source code is available at \url{https://khchow.com/Imperio}.
Hierarchical Pruning of Deep Ensembles with Focal Diversity
Nov 17, 2023Deep neural network ensembles combine the wisdom of multiple deep neural networks to improve the generalizability and robustness over individual networks. It has gained increasing popularity to study deep ensemble techniques in the deep learning community. Some mission-critical applications utilize a large number of deep neural networks to form deep ensembles to achieve desired accuracy and resilience, which introduces high time and space costs for ensemble execution. However, it still remains a critical challenge whether a small subset of the entire deep ensemble can achieve the same or better generalizability and how to effectively identify these small deep ensembles for improving the space and time efficiency of ensemble execution. This paper presents a novel deep ensemble pruning approach, which can efficiently identify smaller deep ensembles and provide higher ensemble accuracy than the entire deep ensemble of a large number of member networks. Our hierarchical ensemble pruning approach (HQ) leverages three novel ensemble pruning techniques. First, we show that the focal diversity metrics can accurately capture the complementary capacity of the member networks of an ensemble, which can guide ensemble pruning. Second, we design a focal diversity based hierarchical pruning approach, which will iteratively find high quality deep ensembles with low cost and high accuracy. Third, we develop a focal diversity consensus method to integrate multiple focal diversity metrics to refine ensemble pruning results, where smaller deep ensembles can be effectively identified to offer high accuracy, high robustness and high efficiency. Evaluated using popular benchmark datasets, we demonstrate that the proposed hierarchical ensemble pruning approach can effectively identify high quality deep ensembles with better generalizability while being more time and space efficient in ensemble decision making.
Exploring Model Learning Heterogeneity for Boosting Ensemble Robustness
Oct 03, 2023



Deep neural network ensembles hold the potential of improving generalization performance for complex learning tasks. This paper presents formal analysis and empirical evaluation to show that heterogeneous deep ensembles with high ensemble diversity can effectively leverage model learning heterogeneity to boost ensemble robustness. We first show that heterogeneous DNN models trained for solving the same learning problem, e.g., object detection, can significantly strengthen the mean average precision (mAP) through our weighted bounding box ensemble consensus method. Second, we further compose ensembles of heterogeneous models for solving different learning problems, e.g., object detection and semantic segmentation, by introducing the connected component labeling (CCL) based alignment. We show that this two-tier heterogeneity driven ensemble construction method can compose an ensemble team that promotes high ensemble diversity and low negative correlation among member models of the ensemble, strengthening ensemble robustness against both negative examples and adversarial attacks. Third, we provide a formal analysis of the ensemble robustness in terms of negative correlation. Extensive experiments validate the enhanced robustness of heterogeneous ensembles in both benign and adversarial settings. The source codes are available on GitHub at https://github.com/git-disl/HeteRobust.
Securing Distributed SGD against Gradient Leakage Threats
May 10, 2023This paper presents a holistic approach to gradient leakage resilient distributed Stochastic Gradient Descent (SGD). First, we analyze two types of strategies for privacy-enhanced federated learning: (i) gradient pruning with random selection or low-rank filtering and (ii) gradient perturbation with additive random noise or differential privacy noise. We analyze the inherent limitations of these approaches and their underlying impact on privacy guarantee, model accuracy, and attack resilience. Next, we present a gradient leakage resilient approach to securing distributed SGD in federated learning, with differential privacy controlled noise as the tool. Unlike conventional methods with the per-client federated noise injection and fixed noise parameter strategy, our approach keeps track of the trend of per-example gradient updates. It makes adaptive noise injection closely aligned throughout the federated model training. Finally, we provide an empirical privacy analysis on the privacy guarantee, model utility, and attack resilience of the proposed approach. Extensive evaluation using five benchmark datasets demonstrates that our gradient leakage resilient approach can outperform the state-of-the-art methods with competitive accuracy performance, strong differential privacy guarantee, and high resilience against gradient leakage attacks. The code associated with this paper can be found: https://github.com/git-disl/Fed-alphaCDP.
STDLens: Model Hijacking-Resilient Federated Learning for Object Detection
Mar 25, 2023Federated Learning (FL) has been gaining popularity as a collaborative learning framework to train deep learning-based object detection models over a distributed population of clients. Despite its advantages, FL is vulnerable to model hijacking. The attacker can control how the object detection system should misbehave by implanting Trojaned gradients using only a small number of compromised clients in the collaborative learning process. This paper introduces STDLens, a principled approach to safeguarding FL against such attacks. We first investigate existing mitigation mechanisms and analyze their failures caused by the inherent errors in spatial clustering analysis on gradients. Based on the insights, we introduce a three-tier forensic framework to identify and expel Trojaned gradients and reclaim the performance over the course of FL. We consider three types of adaptive attacks and demonstrate the robustness of STDLens against advanced adversaries. Extensive experiments show that STDLens can protect FL against different model hijacking attacks and outperform existing methods in identifying and removing Trojaned gradients with significantly higher precision and much lower false-positive rates.
EENet: Learning to Early Exit for Adaptive Inference
Jan 15, 2023Budgeted adaptive inference with early exits is an emerging technique to improve the computational efficiency of deep neural networks (DNNs) for edge AI applications with limited resources at test time. This method leverages the fact that different test data samples may not require the same amount of computation for a correct prediction. By allowing early exiting from full layers of DNN inference for some test examples, we can reduce latency and improve throughput of edge inference while preserving performance. Although there have been numerous studies on designing specialized DNN architectures for training early-exit enabled DNN models, most of the existing work employ hand-tuned or manual rule-based early exit policies. In this study, we introduce a novel multi-exit DNN inference framework, coined as EENet, which leverages multi-objective learning to optimize the early exit policy for a trained multi-exit DNN under a given inference budget. This paper makes two novel contributions. First, we introduce the concept of early exit utility scores by combining diverse confidence measures with class-wise prediction scores to better estimate the correctness of test-time predictions at a given exit. Second, we train a lightweight, budget-driven, multi-objective neural network over validation predictions to learn the exit assignment scheduling for query examples at test time. The EENet early exit scheduler optimizes both the distribution of test samples to different exits and the selection of the exit utility thresholds such that the given inference budget is satisfied while the performance metric is maximized. Extensive experiments are conducted on five benchmarks, including three image datasets (CIFAR-10, CIFAR-100, ImageNet) and two NLP datasets (SST-2, AgNews). The results demonstrate the performance improvements of EENet compared to existing representative early exit techniques.
Promoting High Diversity Ensemble Learning with EnsembleBench
Oct 20, 2020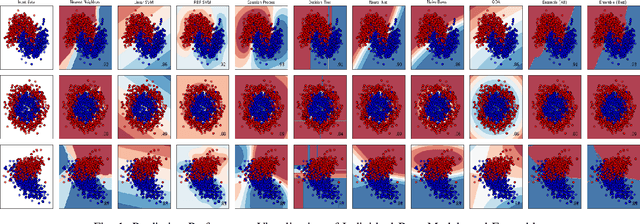



Ensemble learning is gaining renewed interests in recent years. This paper presents EnsembleBench, a holistic framework for evaluating and recommending high diversity and high accuracy ensembles. The design of EnsembleBench offers three novel features: (1) EnsembleBench introduces a set of quantitative metrics for assessing the quality of ensembles and for comparing alternative ensembles constructed for the same learning tasks. (2) EnsembleBench implements a suite of baseline diversity metrics and optimized diversity metrics for identifying and selecting ensembles with high diversity and high quality, making it an effective framework for benchmarking, evaluating and recommending high diversity model ensembles. (3) Four representative ensemble consensus methods are provided in the first release of EnsembleBench, enabling empirical study on the impact of consensus methods on ensemble accuracy. A comprehensive experimental evaluation on popular benchmark datasets demonstrates the utility and effectiveness of EnsembleBench for promoting high diversity ensembles and boosting the overall performance of selected ensembles.
Understanding Object Detection Through An Adversarial Lens
Jul 11, 2020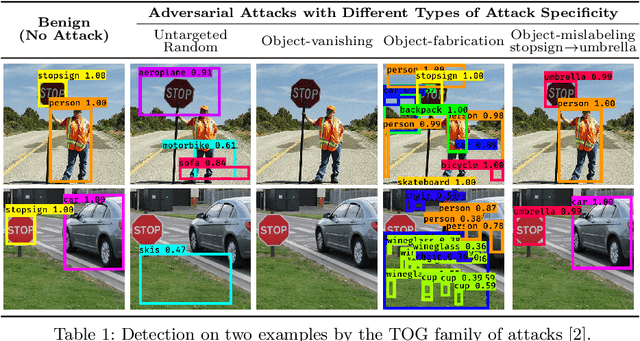
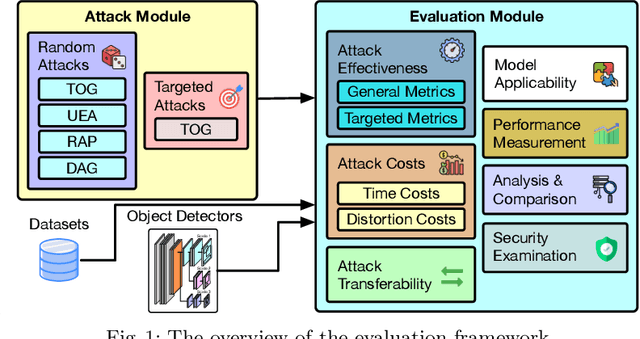

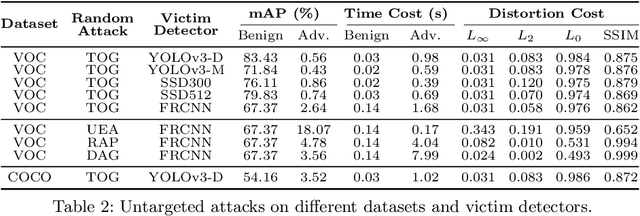
Deep neural networks based object detection models have revolutionized computer vision and fueled the development of a wide range of visual recognition applications. However, recent studies have revealed that deep object detectors can be compromised under adversarial attacks, causing a victim detector to detect no object, fake objects, or mislabeled objects. With object detection being used pervasively in many security-critical applications, such as autonomous vehicles and smart cities, we argue that a holistic approach for an in-depth understanding of adversarial attacks and vulnerabilities of deep object detection systems is of utmost importance for the research community to develop robust defense mechanisms. This paper presents a framework for analyzing and evaluating vulnerabilities of the state-of-the-art object detectors under an adversarial lens, aiming to analyze and demystify the attack strategies, adverse effects, and costs, as well as the cross-model and cross-resolution transferability of attacks. Using a set of quantitative metrics, extensive experiments are performed on six representative deep object detectors from three popular families (YOLOv3, SSD, and Faster R-CNN) with two benchmark datasets (PASCAL VOC and MS COCO). We demonstrate that the proposed framework can serve as a methodical benchmark for analyzing adversarial behaviors and risks in real-time object detection systems. We conjecture that this framework can also serve as a tool to assess the security risks and the adversarial robustness of deep object detectors to be deployed in real-world applications.