 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Monocular Depth Estimation with an Edge Guided Network
Sep 29, 2022
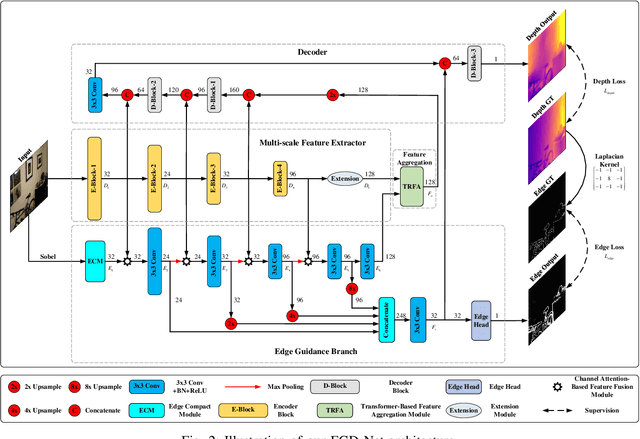
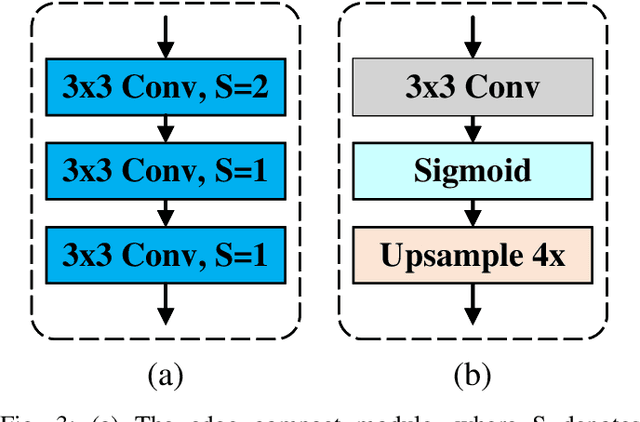
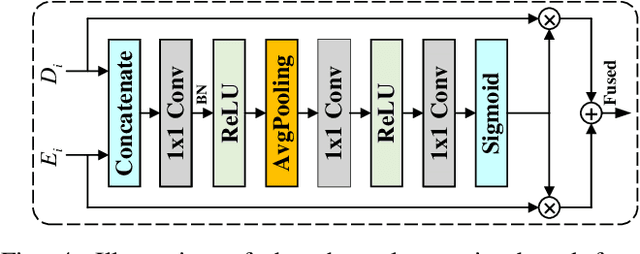
Monocular depth estimation is an important task that can be applied to many robotic applications. Existing methods focus on improving depth estimation accuracy via training increasingly deeper and wider networks, however these suffer from large computational complexity. Recent studies found that edge information are important cues for convolutional neural networks (CNNs) to estimate depth. Inspired by the above observations, we present a novel lightweight Edge Guided Depth Estimation Network (EGD-Net) in this study. In particular, we start out with a lightweight encoder-decoder architecture and embed an edge guidance branch which takes as input image gradients and multi-scale feature maps from the backbone to learn the edge attention features. In order to aggregate the context information and edge attention features, we design a transformer-based feature aggregation module (TRFA). TRFA captures the long-range dependencies between the context information and edge attention features through cross-attention mechanism. We perform extensive experiments on the NYU depth v2 dataset. Experimental results show that the proposed method runs about 96 fps on a Nvidia GTX 1080 GPU whilst achieving the state-of-the-art performance in terms of accuracy.
Multiplex Heterogeneous Graph Convolutional Network
Aug 12, 2022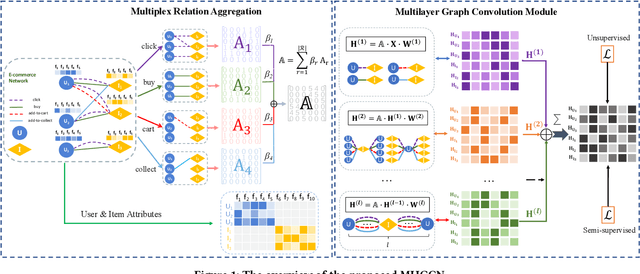
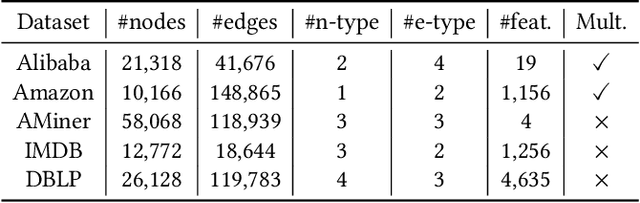
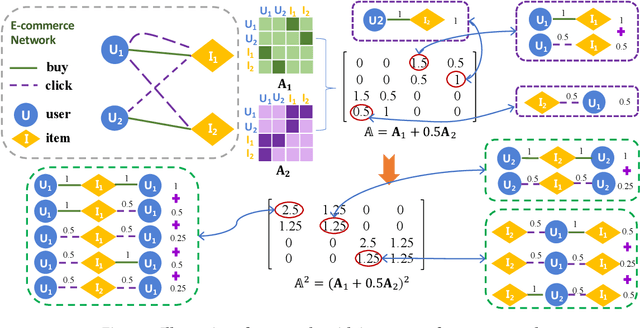
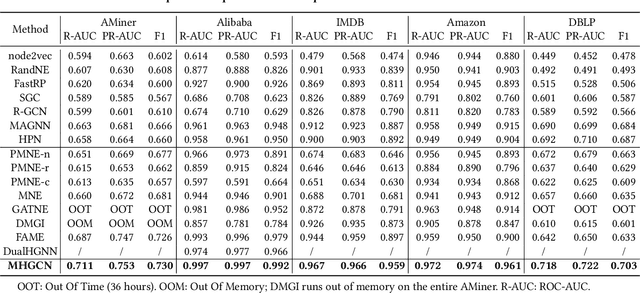
Heterogeneous graph convolutional networks have gained great popularity in tackling various network analytical tasks on heterogeneous network data, ranging from link prediction to node classification. However, most existing works ignore the relation heterogeneity with multiplex network between multi-typed nodes and different importance of relations in meta-paths for node embedding, which can hardly capture the heterogeneous structure signals across different relations. To tackle this challenge, this work proposes a Multiplex Heterogeneous Graph Convolutional Network (MHGCN) for heterogeneous network embedding. Our MHGCN can automatically learn the useful heterogeneous meta-path interactions of different lengths in multiplex heterogeneous networks through multi-layer convolution aggregation. Additionally, we effectively integrate both multi-relation structural signals and attribute semantics into the learned node embeddings with both unsupervised and semi-supervised learning paradigms. Extensive experiments on five real-world datasets with various network analytical tasks demonstrate the significant superiority of MHGCN against state-of-the-art embedding baselines in terms of all evaluation metrics.
Synthetic Aperture Radar Image Change Detection via Layer Attention-Based Noise-Tolerant Network
Aug 09, 2022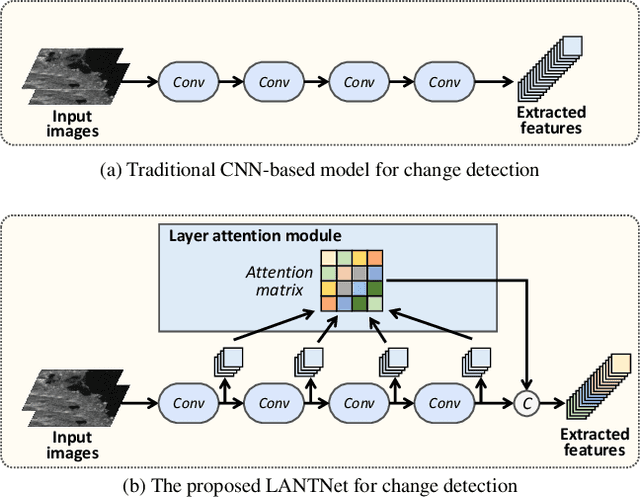
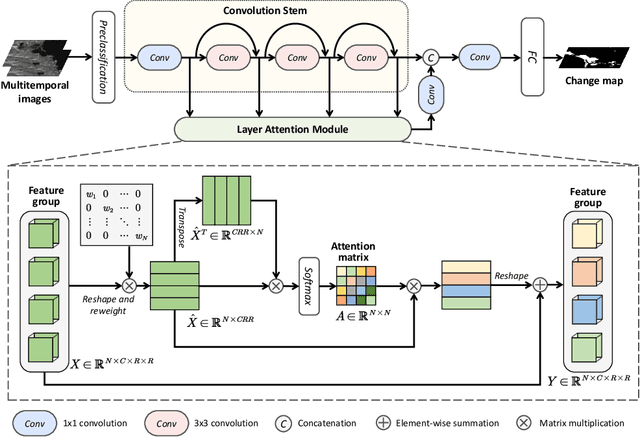

Recently, change detection methods for synthetic aperture radar (SAR) images based on convolutional neural networks (CNN) have gained increasing research attention. However, existing CNN-based methods neglect the interactions among multilayer convolutions, and errors involved in the preclassification restrict the network optimization. To this end, we proposed a layer attention-based noise-tolerant network, termed LANTNet. In particular, we design a layer attention module that adaptively weights the feature of different convolution layers. In addition, we design a noise-tolerant loss function that effectively suppresses the impact of noisy labels. Therefore, the model is insensitive to noisy labels in the preclassification results. The experimental results on three SAR datasets show that the proposed LANTNet performs better compared to several state-of-the-art methods. The source codes are available at https://github.com/summitgao/LANTNet
Editing Out-of-domain GAN Inversion via Differential Activations
Jul 17, 2022


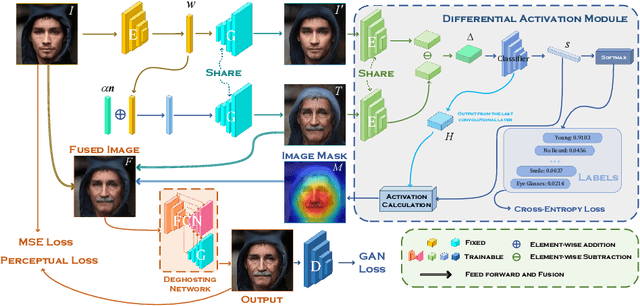
Despite the demonstrated editing capacity in the latent space of a pretrained GAN model, inverting real-world images is stuck in a dilemma that the reconstruction cannot be faithful to the original input. The main reason for this is that the distributions between training and real-world data are misaligned, and because of that, it is unstable of GAN inversion for real image editing. In this paper, we propose a novel GAN prior based editing framework to tackle the out-of-domain inversion problem with a composition-decomposition paradigm. In particular, during the phase of composition, we introduce a differential activation module for detecting semantic changes from a global perspective, \ie, the relative gap between the features of edited and unedited images. With the aid of the generated Diff-CAM mask, a coarse reconstruction can intuitively be composited by the paired original and edited images. In this way, the attribute-irrelevant regions can be survived in almost whole, while the quality of such an intermediate result is still limited by an unavoidable ghosting effect. Consequently, in the decomposition phase, we further present a GAN prior based deghosting network for separating the final fine edited image from the coarse reconstruction. Extensive experiments exhibit superiorities over the state-of-the-art methods, in terms of qualitative and quantitative evaluations. The robustness and flexibility of our method is also validated on both scenarios of single attribute and multi-attribute manipulations.
Mutual Distillation Learning Network for Trajectory-User Linking
May 08, 2022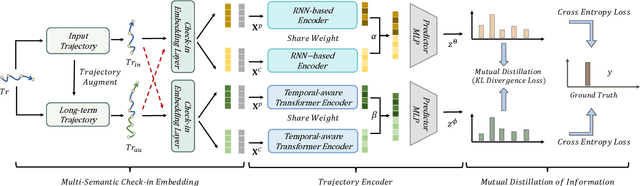
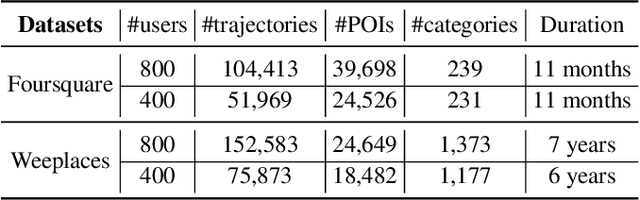
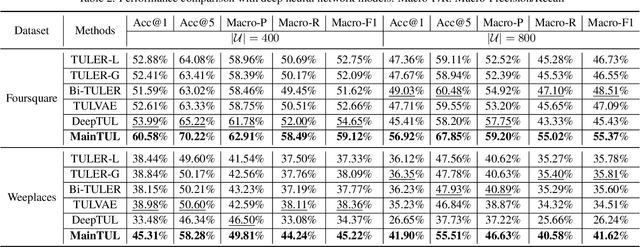
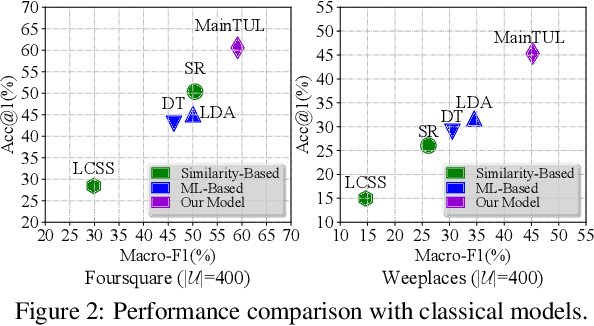
Trajectory-User Linking (TUL), which links trajectories to users who generate them, has been a challenging problem due to the sparsity in check-in mobility data. Existing methods ignore the utilization of historical data or rich contextual features in check-in data, resulting in poor performance for TUL task. In this paper, we propose a novel Mutual distillation learning network to solve the TUL problem for sparse check-in mobility data, named MainTUL. Specifically, MainTUL is composed of a Recurrent Neural Network (RNN) trajectory encoder that models sequential patterns of input trajectory and a temporal-aware Transformer trajectory encoder that captures long-term time dependencies for the corresponding augmented historical trajectories. Then, the knowledge learned on historical trajectories is transferred between the two trajectory encoders to guide the learning of both encoders to achieve mutual distillation of information. Experimental results on two real-world check-in mobility datasets demonstrate the superiority of MainTUL against state-of-the-art baselines. The source code of our model is available at https://github.com/Onedean/MainTUL.
Enhancing the Transferability via Feature-Momentum Adversarial Attack
Apr 22, 2022
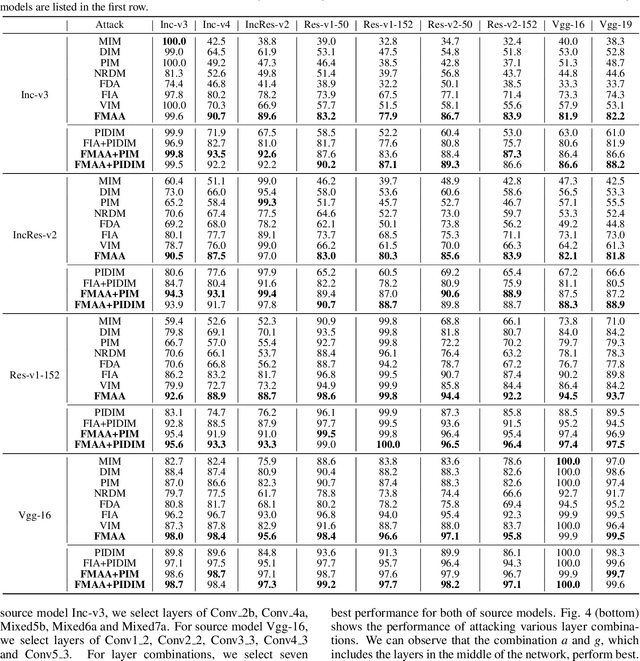
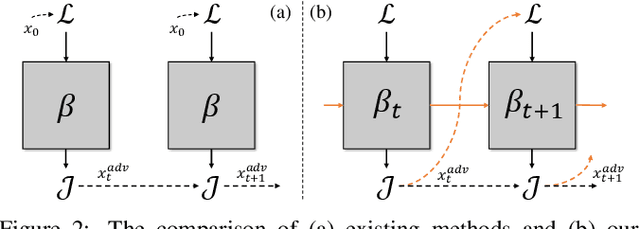
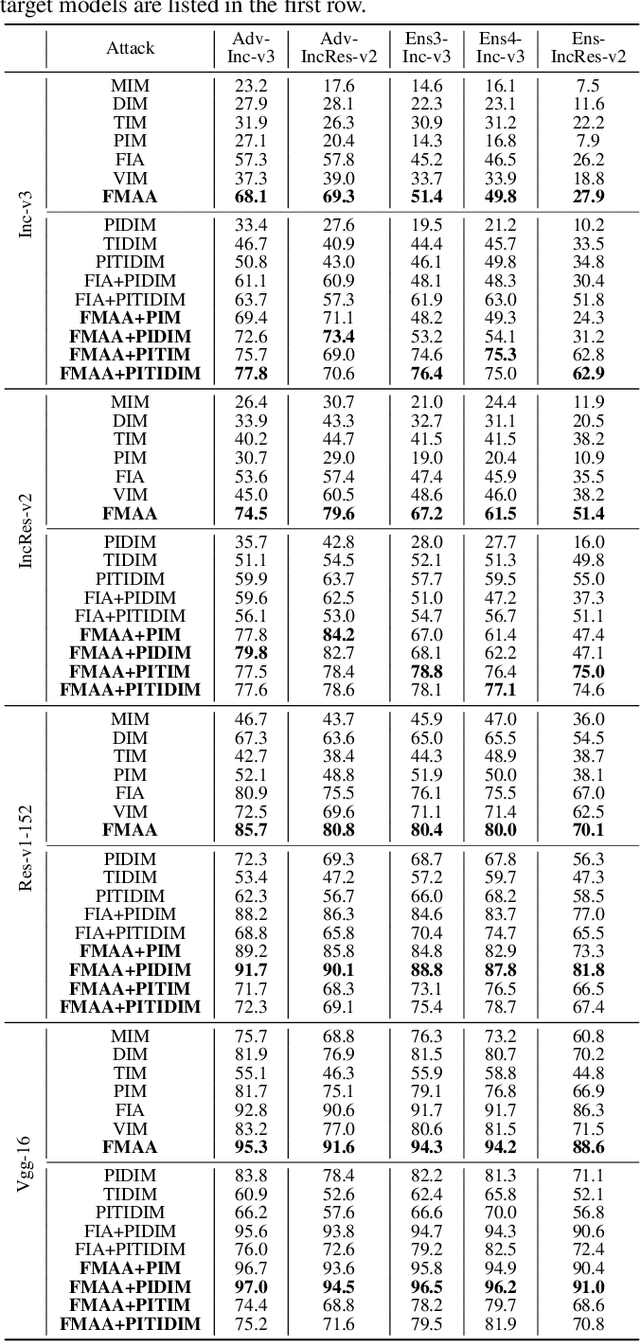
Transferable adversarial attack has drawn increasing attention due to their practical threaten to real-world applications. In particular, the feature-level adversarial attack is one recent branch that can enhance the transferability via disturbing the intermediate features. The existing methods usually create a guidance map for features, where the value indicates the importance of the corresponding feature element and then employs an iterative algorithm to disrupt the features accordingly. However, the guidance map is fixed in existing methods, which can not consistently reflect the behavior of networks as the image is changed during iteration. In this paper, we describe a new method called Feature-Momentum Adversarial Attack (FMAA) to further improve transferability. The key idea of our method is that we estimate a guidance map dynamically at each iteration using momentum to effectively disturb the category-relevant features. Extensive experiments demonstrate that our method significantly outperforms other state-of-the-art methods by a large margin on different target models.
Scalable Motif Counting for Large-scale Temporal Graphs
Apr 20, 2022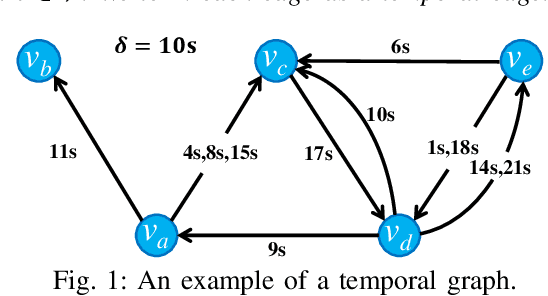
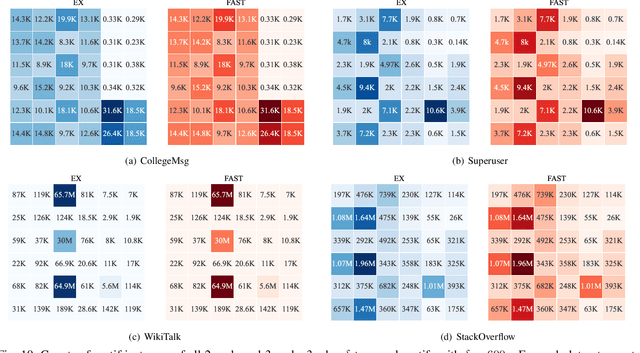
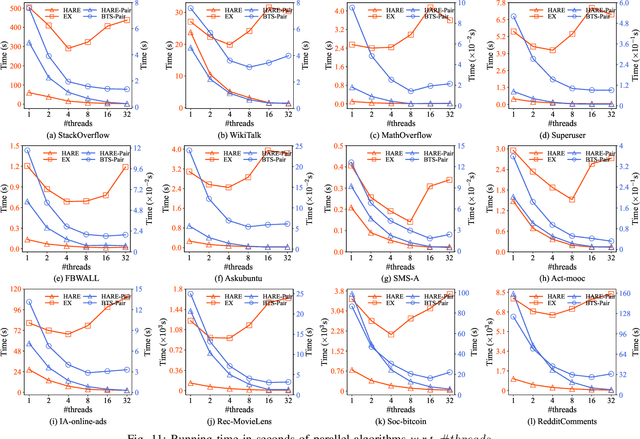
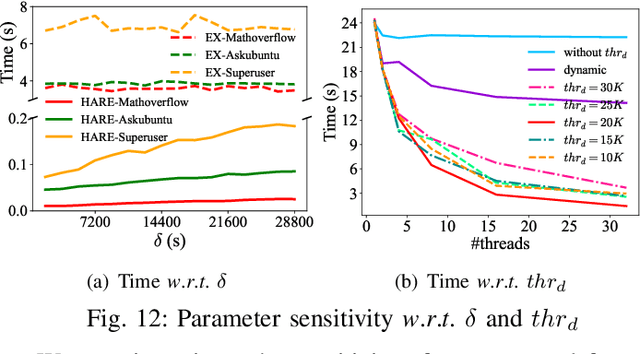
One fundamental problem in temporal graph analysis is to count the occurrences of small connected subgraph patterns (i.e., motifs), which benefits a broad range of real-world applications, such as anomaly detection, structure prediction, and network representation learning. However, existing works focused on exacting temporal motif are not scalable to large-scale temporal graph data, due to their heavy computational costs or inherent inadequacy of parallelism. In this work, we propose a scalable parallel framework for exactly counting temporal motifs in large-scale temporal graphs. We first categorize the temporal motifs based on their distinct properties, and then design customized algorithms that offer efficient strategies to exactly count the motif instances of each category. Moreover, our compact data structures, namely triple and quadruple counters, enable our algorithms to directly identify the temporal motif instances of each category, according to edge information and the relationship between edges, therefore significantly improving the counting efficiency. Based on the proposed counting algorithms, we design a hierarchical parallel framework that features both inter- and intra-node parallel strategies, and fully leverages the multi-threading capacity of modern CPU to concurrently count all temporal motifs. Extensive experiments on sixteen real-world temporal graph datasets demonstrate the superiority and capability of our proposed framework for temporal motif counting, achieving up to 538* speedup compared to the state-of-the-art methods. The source code of our method is available at: https://github.com/steven-ccq/FAST-temporal-motif.
Change Detection from Synthetic Aperture Radar Images via Dual Path Denoising Network
Mar 13, 2022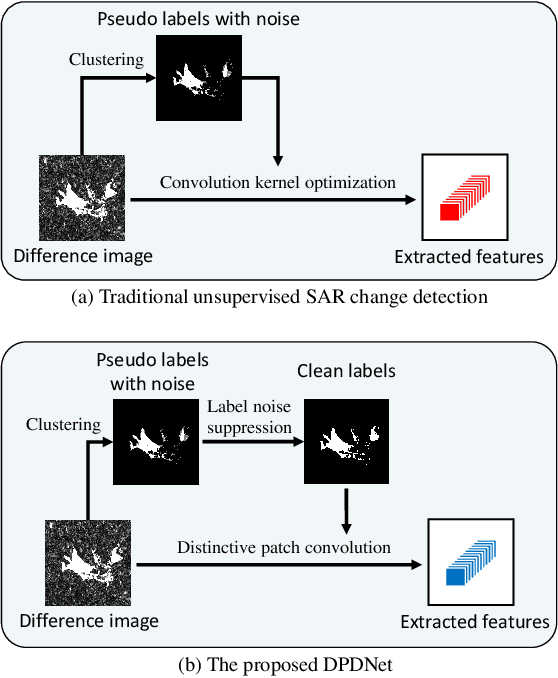

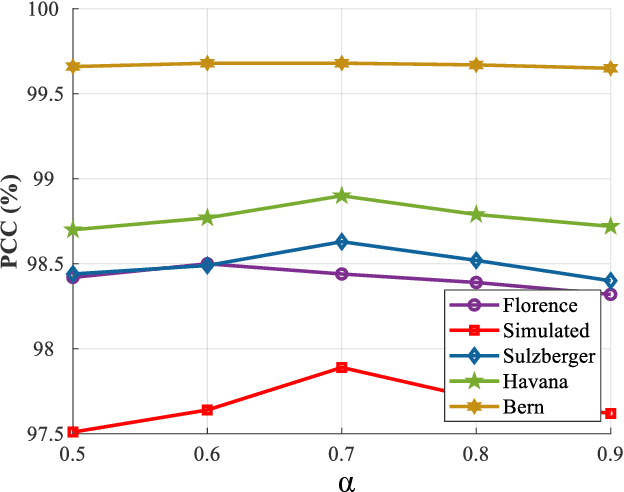
Benefited from the rapid and sustainable development of synthetic aperture radar (SAR) sensors, change detection from SAR images has received increasing attentions over the past few years. Existing unsupervised deep learning-based methods have made great efforts to exploit robust feature representations, but they consume much time to optimize parameters. Besides, these methods use clustering to obtain pseudo-labels for training, and the pseudo-labeled samples often involve errors, which can be considered as "label noise". To address these issues, we propose a Dual Path Denoising Network (DPDNet) for SAR image change detection. In particular, we introduce the random label propagation to clean the label noise involved in preclassification. We also propose the distinctive patch convolution for feature representation learning to reduce the time consumption. Specifically, the attention mechanism is used to select distinctive pixels in the feature maps, and patches around these pixels are selected as convolution kernels. Consequently, the DPDNet does not require a great number of training samples for parameter optimization, and its computational efficiency is greatly enhanced. Extensive experiments have been conducted on five SAR datasets to verify the proposed DPDNet. The experimental results demonstrate that our method outperforms several state-of-the-art methods in change detection results.
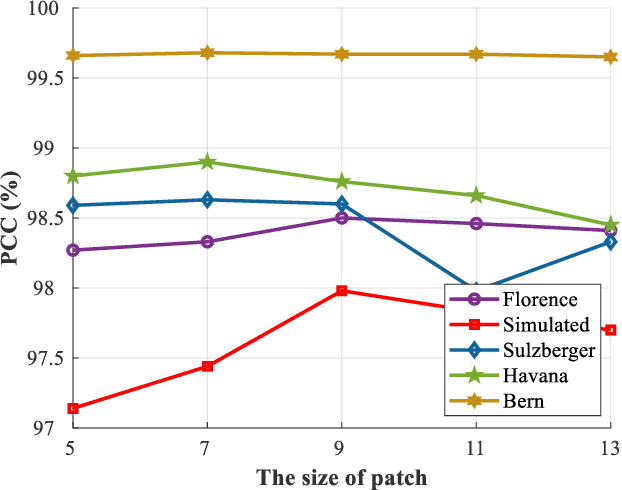
SSCU-Net: Spatial-Spectral Collaborative Unmixing Network for Hyperspectral Images
Mar 12, 2022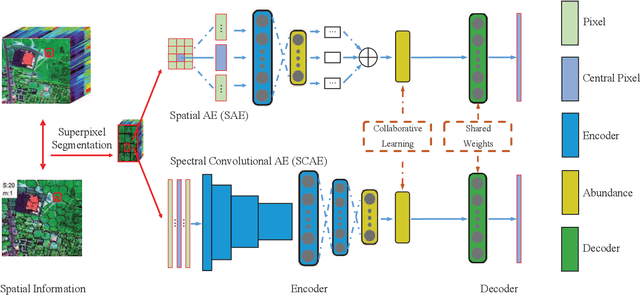
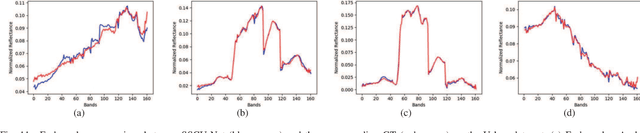
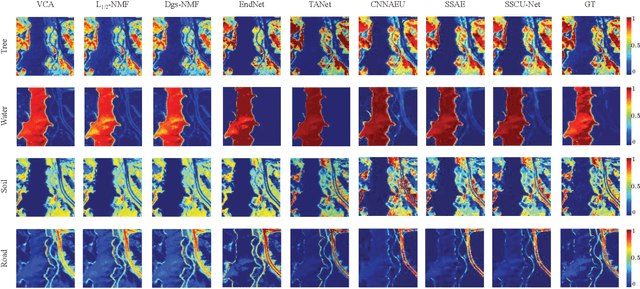
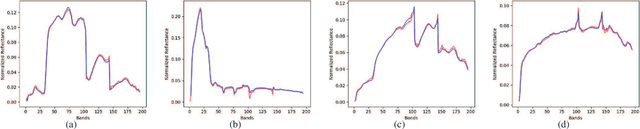
Linear spectral unmixing is an essential technique in hyperspectral image processing and interpretation. In recent years, deep learning-based approaches have shown great promise in hyperspectral unmixing, in particular, unsupervised unmixing methods based on autoencoder networks are a recent trend. The autoencoder model, which automatically learns low-dimensional representations (abundances) and reconstructs data with their corresponding bases (endmembers), has achieved superior performance in hyperspectral unmixing. In this article, we explore the effective utilization of spatial and spectral information in autoencoder-based unmixing networks. Important findings on the use of spatial and spectral information in the autoencoder framework are discussed. Inspired by these findings, we propose a spatial-spectral collaborative unmixing network, called SSCU-Net, which learns a spatial autoencoder network and a spectral autoencoder network in an end-to-end manner to more effectively improve the unmixing performance. SSCU-Net is a two-stream deep network and shares an alternating architecture, where the two autoencoder networks are efficiently trained in a collaborative way for estimation of endmembers and abundances. Meanwhile, we propose a new spatial autoencoder network by introducing a superpixel segmentation method based on abundance information, which greatly facilitates the employment of spatial information and improves the accuracy of unmixing network. Moreover, extensive ablation studies are carried out to investigate the performance gain of SSCU-Net. Experimental results on both synthetic and real hyperspectral data sets illustrate the effectiveness and competitiveness of the proposed SSCU-Net compared with several state-of-the-art hyperspectral unmixing methods.
Change Detection from Synthetic Aperture Radar Images via Graph-Based Knowledge Supplement Network
Feb 09, 2022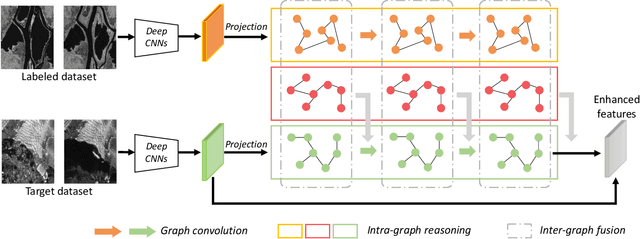
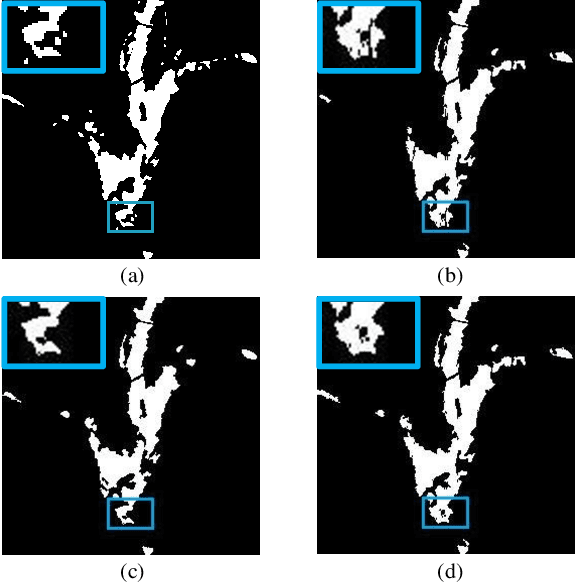
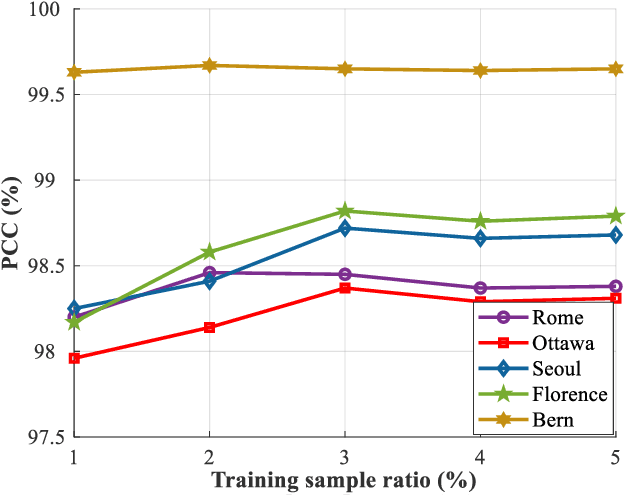
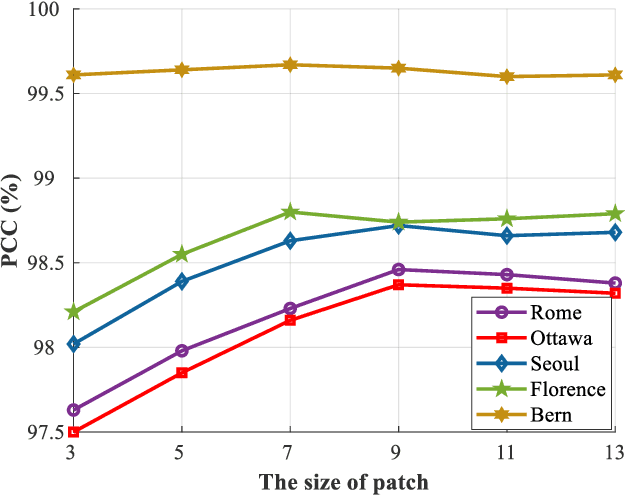
Synthetic aperture radar (SAR) image change detection is a vital yet challenging task in the field of remote sensing image analysis. Most previous works adopt a self-supervised method which uses pseudo-labeled samples to guide subsequent training and testing. However, deep networks commonly require many high-quality samples for parameter optimization. The noise in pseudo-labels inevitably affects the final change detection performance. To solve the problem, we propose a Graph-based Knowledge Supplement Network (GKSNet). To be more specific, we extract discriminative information from the existing labeled dataset as additional knowledge, to suppress the adverse effects of noisy samples to some extent. Afterwards, we design a graph transfer module to distill contextual information attentively from the labeled dataset to the target dataset, which bridges feature correlation between datasets. To validate the proposed method, we conducted extensive experiments on four SAR datasets, which demonstrated the superiority of the proposed GKSNet as compared to several state-of-the-art baselines. Our codes are available at https://github.com/summitgao/SAR_CD_GKSNet.