 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomic structure generation from reconstructing structural fingerprints
Jul 27, 2022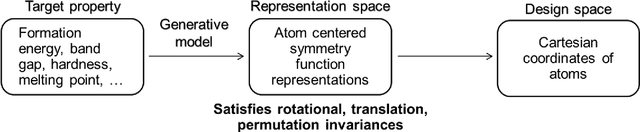
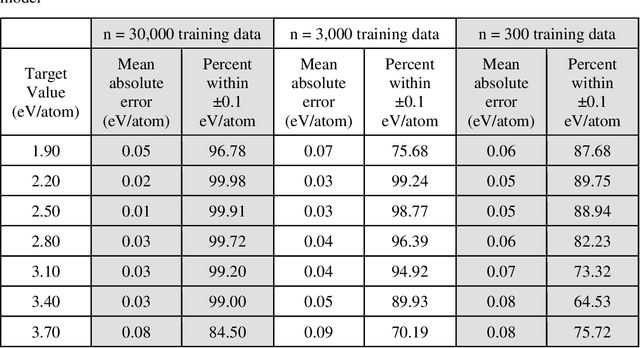
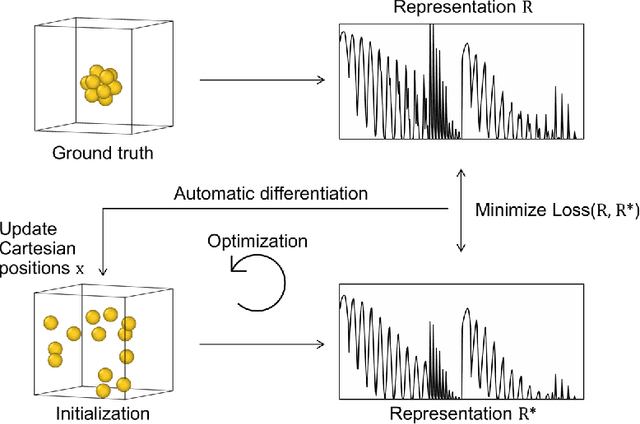
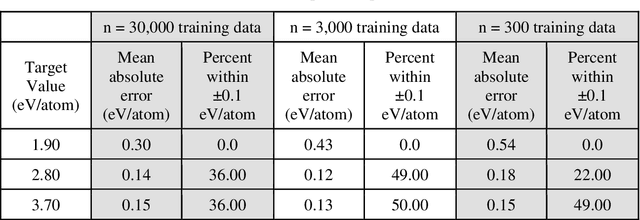
Data-driven machine learning methods have the potential to dramatically accelerate the rate of materials design over conventional human-guided approaches. These methods would help identify or, in the case of generative models, even create novel crystal structures of materials with a set of specified functional properties to then be synthesized or isolated in the laboratory. For crystal structure generation, a key bottleneck lies in developing suitable atomic structure fingerprints or representations for the machine learning model, analogous to the graph-based or SMILES representations used in molecular generation. However, finding data-efficient representations that are invariant to translations, rotations, and permutations, while remaining invertible to the Cartesian atomic coordinates remains an ongoing challenge. Here, we propose an alternative approach to this problem by taking existing non-invertible representations with the desired invariances and developing an algorithm to reconstruct the atomic coordinates through gradient-based optimization using automatic differentiation. This can then be coupled to a generative machine learning model which generates new materials within the representation space, rather than in the data-inefficient Cartesian space. In this work, we implement this end-to-end structure generation approach using atom-centered symmetry functions as the representation and conditional variational autoencoders as the generative model. We are able to successfully generate novel and valid atomic structures of sub-nanometer Pt nanoparticles as a proof of concept. Furthermore, this method can be readily extended to any suitable structural representation, thereby providing a powerful, generalizable framework towards structure-based generation.
Stable Parallel Training of Wasserstein Conditional Generative Adversarial Neural Networks
Jul 25, 2022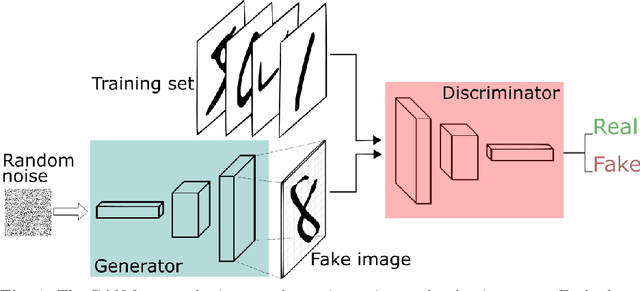
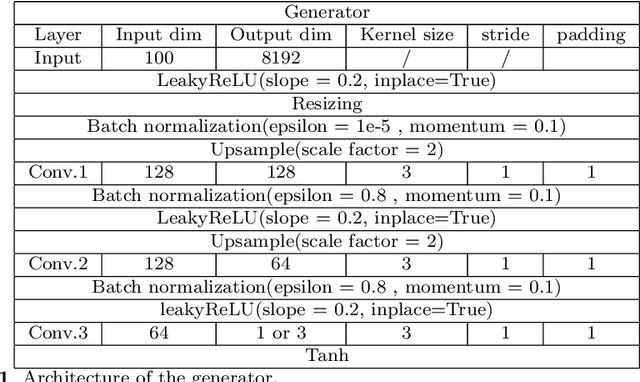
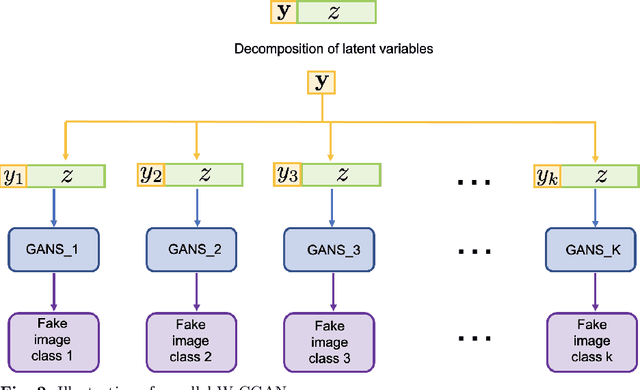
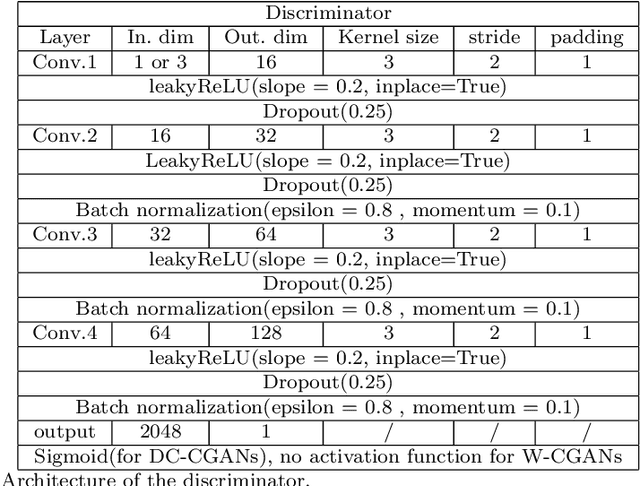
We propose a stable, parallel approach to train Wasserstein Conditional Generative Adversarial Neural Networks (W-CGANs) under the constraint of a fixed computational budget. Differently from previous distributed GANs training techniques, our approach avoids inter-process communications, reduces the risk of mode collapse and enhances scalability by using multiple generators, each one of them concurrently trained on a single data label. The use of the Wasserstein metric also reduces the risk of cycling by stabilizing the training of each generator. We illustrate the approach on the CIFAR10, CIFAR100, and ImageNet1k datasets, three standard benchmark image datasets, maintaining the original resolution of the images for each dataset. Performance is assessed in terms of scalability and final accuracy within a limited fixed computational time and computational resources. To measure accuracy, we use the inception score, the Frechet inception distance, and image quality. An improvement in inception score and Frechet inception distance is shown in comparison to previous results obtained by performing the parallel approach on deep convolutional conditional generative adversarial neural networks (DC-CGANs) as well as an improvement of image quality of the new images created by the GANs approach. Weak scaling is attained on both datasets using up to 2,000 NVIDIA V100 GPUs on the OLCF supercomputer Summit.
MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021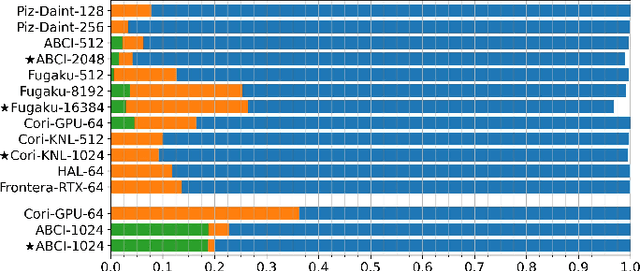
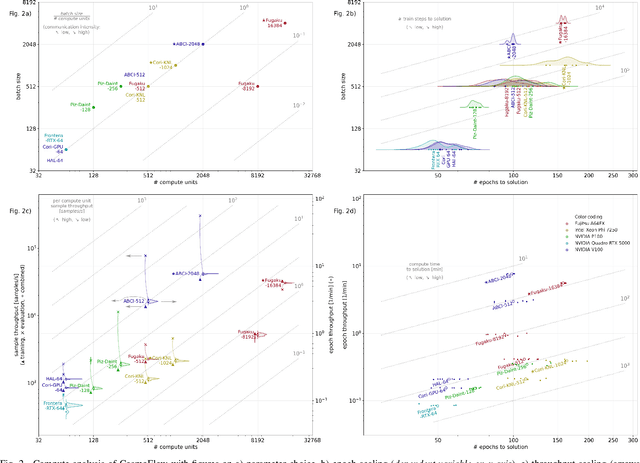
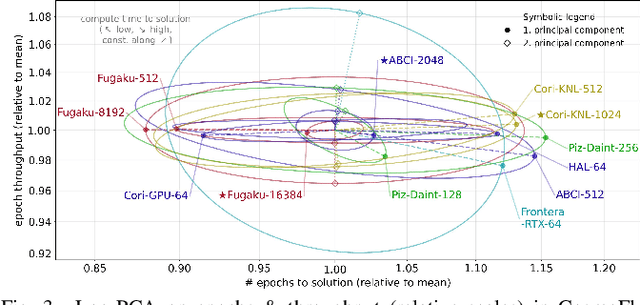
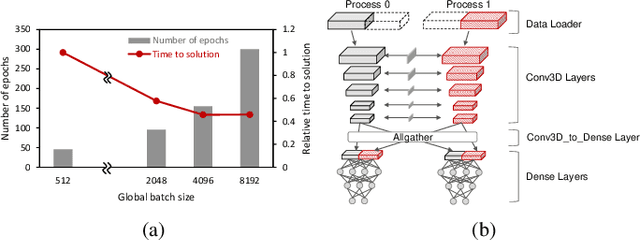
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
Stable Anderson Acceleration for Deep Learning
Oct 26, 2021
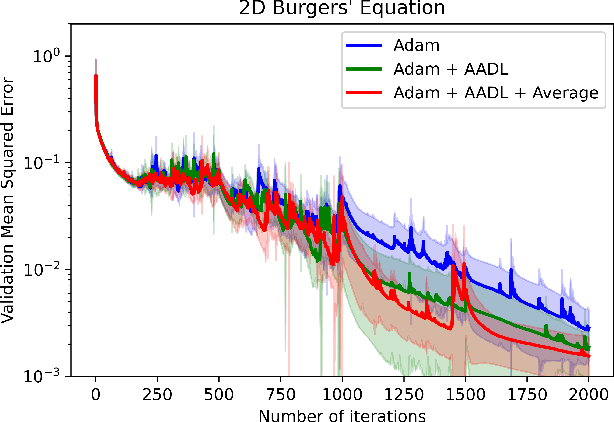
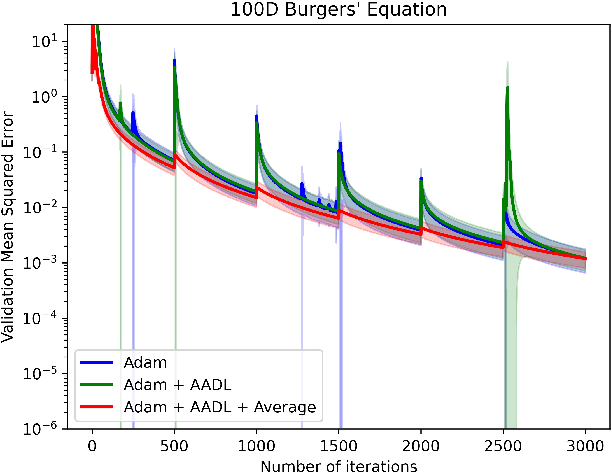
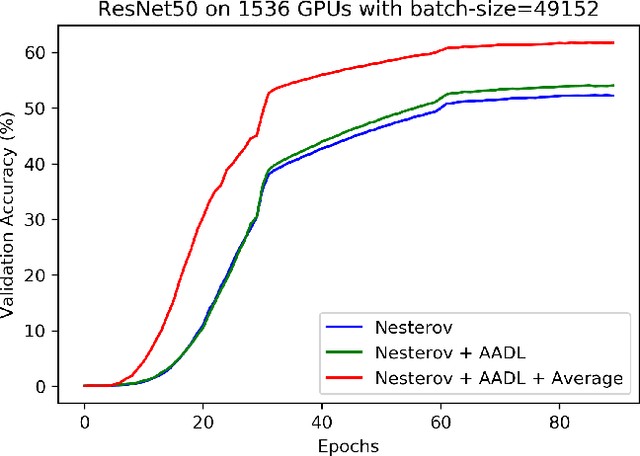
Anderson acceleration (AA) is an extrapolation technique designed to speed-up fixed-point iterations like those arising from the iterative training of DL models. Training DL models requires large datasets processed in randomly sampled batches that tend to introduce in the fixed-point iteration stochastic oscillations of amplitude roughly inversely proportional to the size of the batch. These oscillations reduce and occasionally eliminate the positive effect of AA. To restore AA's advantage, we combine it with an adaptive moving average procedure that smoothes the oscillations and results in a more regular sequence of gradient descent updates. By monitoring the relative standard deviation between consecutive iterations, we also introduce a criterion to automatically assess whether the moving average is needed. We applied the method to the following DL instantiations: (i) multi-layer perceptrons (MLPs) trained on the open-source graduate admissions dataset for regression, (ii) physics informed neural networks (PINNs) trained on source data to solve 2d and 100d Burgers' partial differential equations (PDEs), and (iii) ResNet50 trained on the open-source ImageNet1k dataset for image classification. Numerical results obtained using up to 1,536 NVIDIA V100 GPUs on the OLCF supercomputer Summit showed the stabilizing effect of the moving average on AA for all the problems above.
Neural network based order parameter for phase transitions and its applications in high-entropy alloys
Sep 12, 2021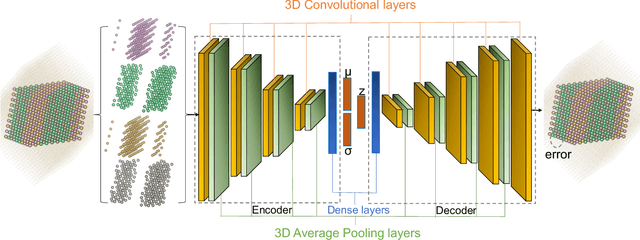
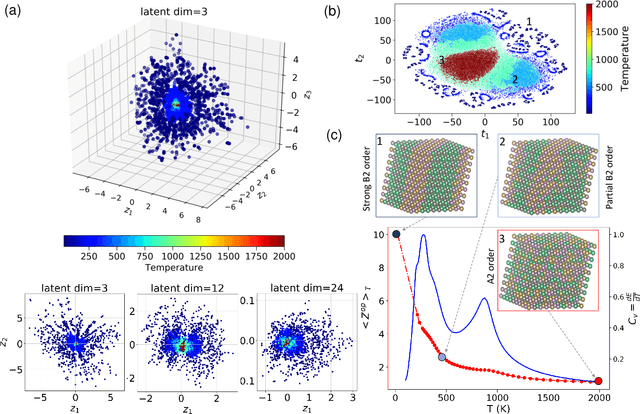
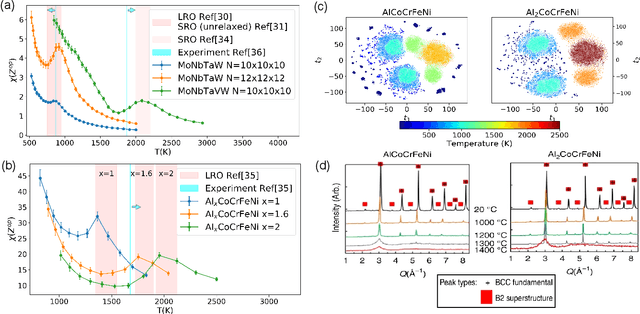
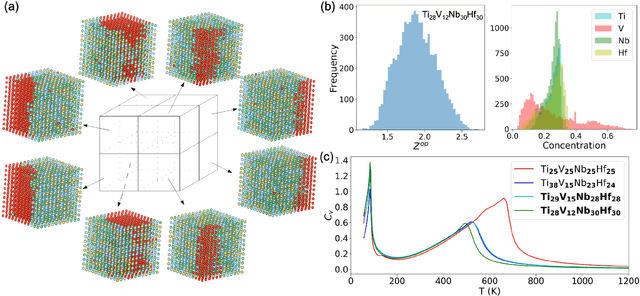
Phase transition is one of the most important phenomena in nature and plays a central role in materials design. All phase transitions are characterized by suitable order parameters, including the order-disorder phase transition. However, finding a representative order parameter for complex systems is nontrivial, such as for high-entropy alloys. Given variational autoencoder's (VAE) strength of reducing high dimensional data into few principal components, here we coin a new concept of "VAE order parameter". We propose that the Manhattan distance in the VAE latent space can serve as a generic order parameter for order-disorder phase transitions. The physical properties of the order parameter are quantitatively interpreted and demonstrated by multiple refractory high-entropy alloys. Assisted by it, a generally applicable alloy design concept is proposed by mimicking the nature mixing of elements. Our physically interpretable "VAE order parameter" lays the foundation for the understanding of and alloy design by chemical ordering.
Scalable Balanced Training of Conditional Generative Adversarial Neural Networks on Image Data
Feb 21, 2021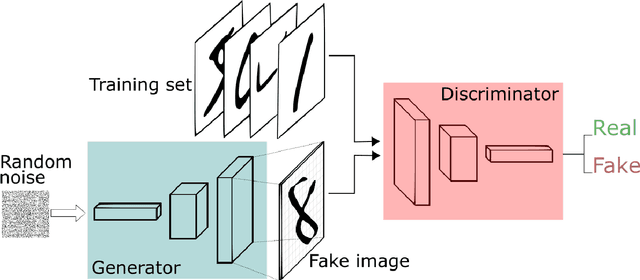
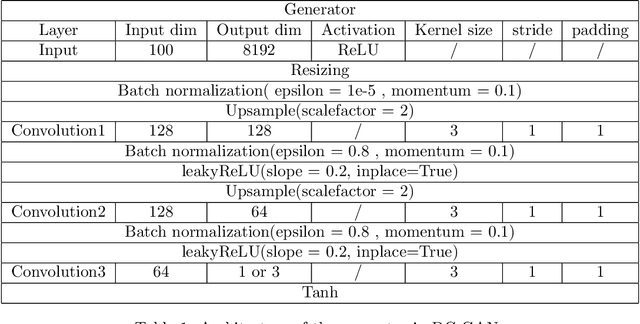

We propose a distributed approach to train deep convolutional generative adversarial neural network (DC-CGANs) models. Our method reduces the imbalance between generator and discriminator by partitioning the training data according to data labels, and enhances scalability by performing a parallel training where multiple generators are concurrently trained, each one of them focusing on a single data label. Performance is assessed in terms of inception score and image quality on MNIST, CIFAR10, CIFAR100, and ImageNet1k datasets, showing a significant improvement in comparison to state-of-the-art techniques to training DC-CGANs. Weak scaling is attained on all the four datasets using up to 1,000 processes and 2,000 NVIDIA V100 GPUs on the OLCF supercomputer Summit.
Data optimization for large batch distributed training of deep neural networks
Dec 18, 2020

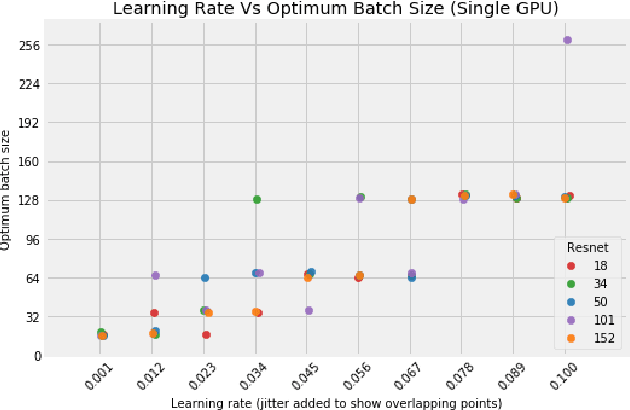
Distributed training in deep learning (DL) is common practice as data and models grow. The current practice for distributed training of deep neural networks faces the challenges of communication bottlenecks when operating at scale, and model accuracy deterioration with an increase in global batch size. Present solutions focus on improving message exchange efficiency as well as implementing techniques to tweak batch sizes and models in the training process. The loss of training accuracy typically happens because the loss function gets trapped in a local minima. We observe that the loss landscape minimization is shaped by both the model and training data and propose a data optimization approach that utilizes machine learning to implicitly smooth out the loss landscape resulting in fewer local minima. Our approach filters out data points which are less important to feature learning, enabling us to speed up the training of models on larger batch sizes to improved accuracy.
Distributed Training and Optimization Of Neural Networks
Dec 03, 2020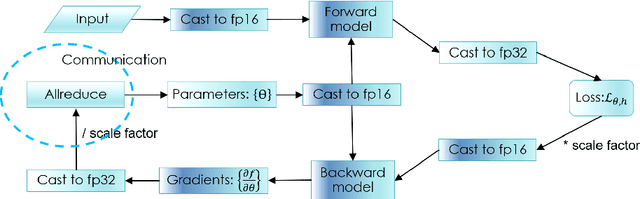
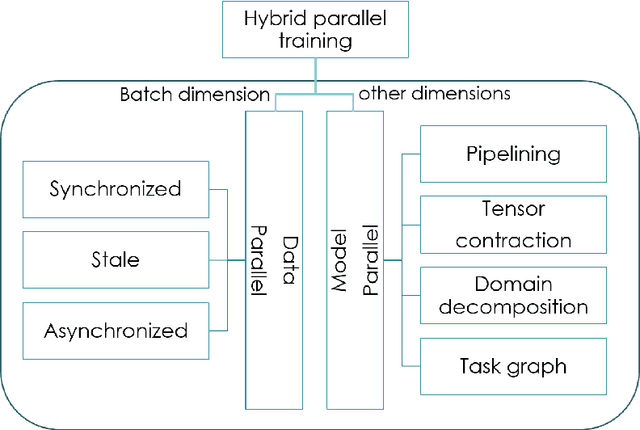
Deep learning models are yielding increasingly better performances thanks to multiple factors. To be successful, model may have large number of parameters or complex architectures and be trained on large dataset. This leads to large requirements on computing resource and turn around time, even more so when hyper-parameter optimization is done (e.g search over model architectures). While this is a challenge that goes beyond particle physics, we review the various ways to do the necessary computations in parallel, and put it in the context of high energy physics.
Integrating Deep Learning in Domain Sciences at Exascale
Nov 23, 2020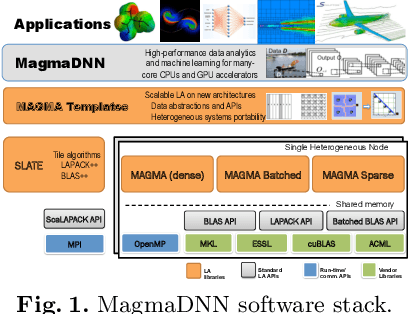
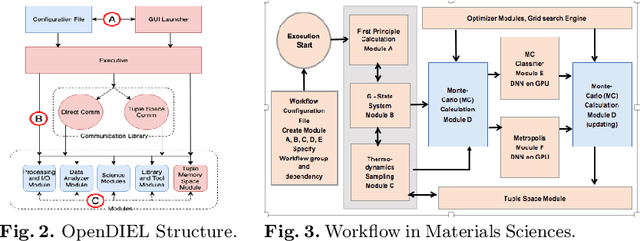
This paper presents some of the current challenges in designing deep learning artificial intelligence (AI) and integrating it with traditional high-performance computing (HPC) simulations. We evaluate existing packages for their ability to run deep learning models and applications on large-scale HPC systems efficiently, identify challenges, and propose new asynchronous parallelization and optimization techniques for current large-scale heterogeneous systems and upcoming exascale systems. These developments, along with existing HPC AI software capabilities, have been integrated into MagmaDNN, an open-source HPC deep learning framework. Many deep learning frameworks are targeted at data scientists and fall short in providing quality integration into existing HPC workflows. This paper discusses the necessities of an HPC deep learning framework and how those needs can be provided (e.g., as in MagmaDNN) through a deep integration with existing HPC libraries, such as MAGMA and its modular memory management, MPI, CuBLAS, CuDNN, MKL, and HIP. Advancements are also illustrated through the use of algorithmic enhancements in reduced- and mixed-precision, as well as asynchronous optimization methods. Finally, we present illustrations and potential solutions for enhancing traditional compute- and data-intensive applications at ORNL and UTK with AI. The approaches and future challenges are illustrated in materials science, imaging, and climate applications.
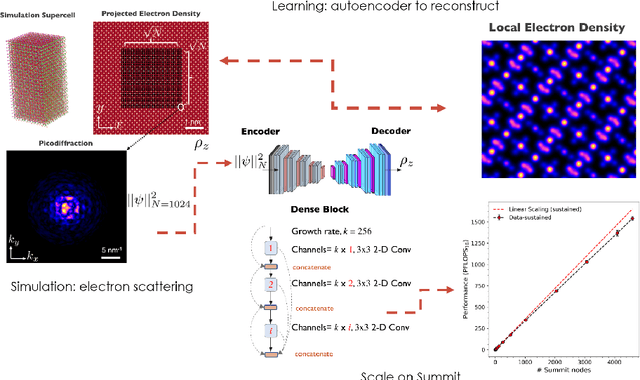
Exascale Deep Learning for Scientific Inverse Problems
Sep 24, 2019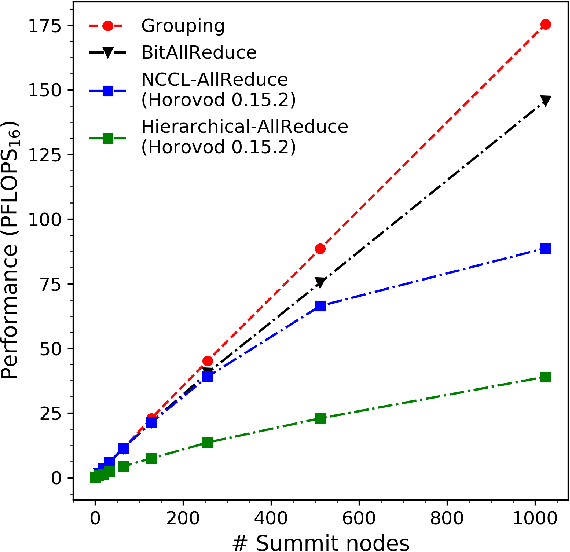

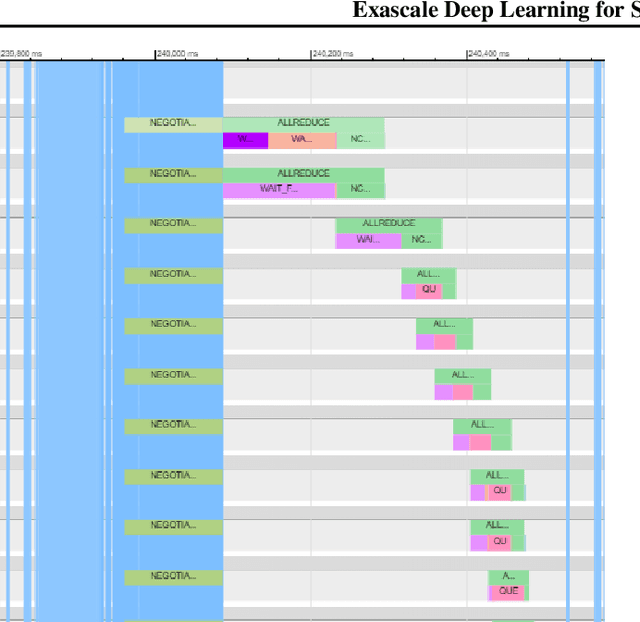

We introduce novel communication strategies in synchronous distributed Deep Learning consisting of decentralized gradient reduction orchestration and computational graph-aware grouping of gradient tensors. These new techniques produce an optimal overlap between computation and communication and result in near-linear scaling (0.93) of distributed training up to 27,600 NVIDIA V100 GPUs on the Summit Supercomputer. We demonstrate our gradient reduction techniques in the context of training a Fully Convolutional Neural Network to approximate the solution of a longstanding scientific inverse problem in materials imaging. The efficient distributed training on a dataset size of 0.5 PB, produces a model capable of an atomically-accurate reconstruction of materials, and in the process reaching a peak performance of 2.15(4) EFLOPS$_{16}$.