 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASVspoof 2021: Automatic Speaker Verification Spoofing and Countermeasures Challenge Evaluation Plan
Sep 01, 2021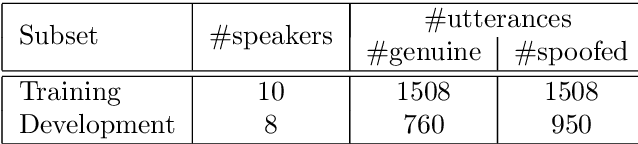
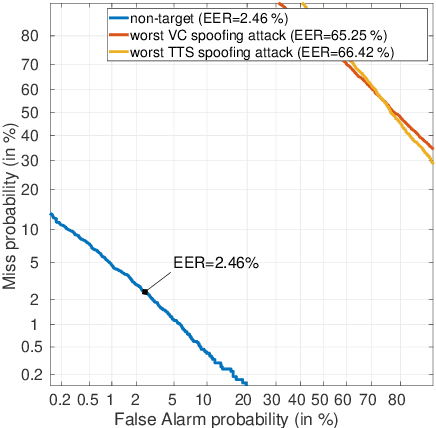
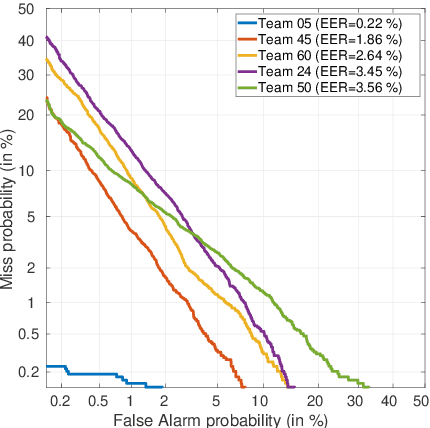
The automatic speaker verification spoofing and countermeasures (ASVspoof) challenge series is a community-led initiative which aims to promote the consideration of spoofing and the development of countermeasures. ASVspoof 2021 is the 4th in a series of bi-annual, competitive challenges where the goal is to develop countermeasures capable of discriminating between bona fide and spoofed or deepfake speech. This document provides a technical description of the ASVspoof 2021 challenge, including details of training, development and evaluation data, metrics, baselines, evaluation rules, submission procedures and the schedule.
Benchmarking and challenges in security and privacy for voice biometrics
Sep 01, 2021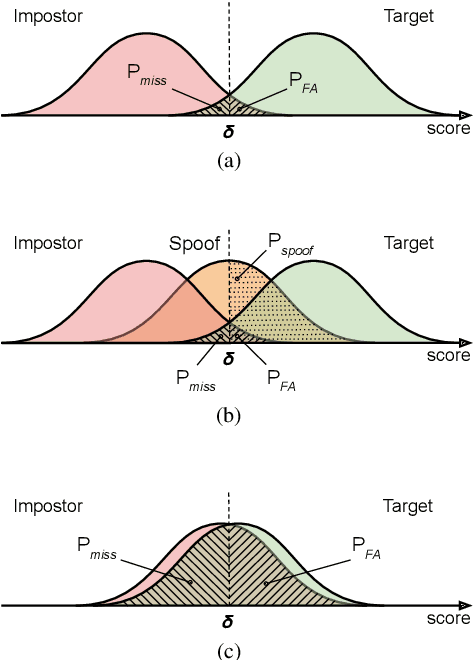
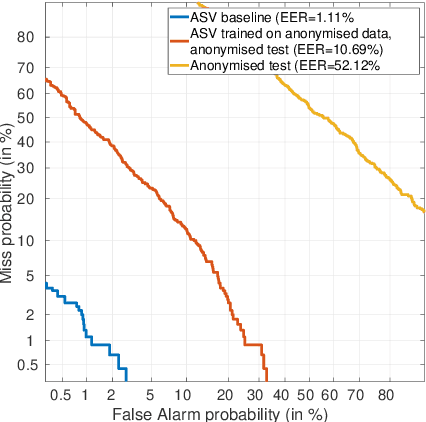
For many decades, research in speech technologies has focused upon improving reliability. With this now meeting user expectations for a range of diverse applications, speech technology is today omni-present. As result, a focus on security and privacy has now come to the fore. Here, the research effort is in its relative infancy and progress calls for greater, multidisciplinary collaboration with security, privacy, legal and ethical experts among others. Such collaboration is now underway. To help catalyse the efforts, this paper provides a high-level overview of some related research. It targets the non-speech audience and describes the benchmarking methodology that has spearheaded progress in traditional research and which now drives recent security and privacy initiatives related to voice biometrics. We describe: the ASVspoof challenge relating to the development of spoofing countermeasures; the VoicePrivacy initiative which promotes research in anonymisation for privacy preservation.
OpenForensics: Large-Scale Challenging Dataset For Multi-Face Forgery Detection And Segmentation In-The-Wild
Jul 30, 2021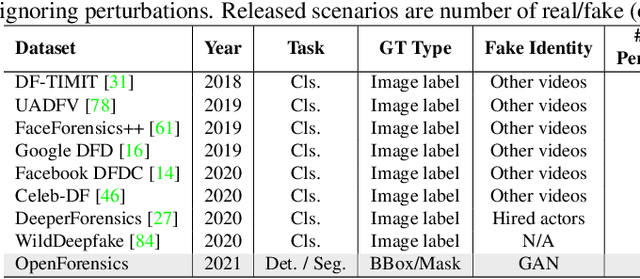

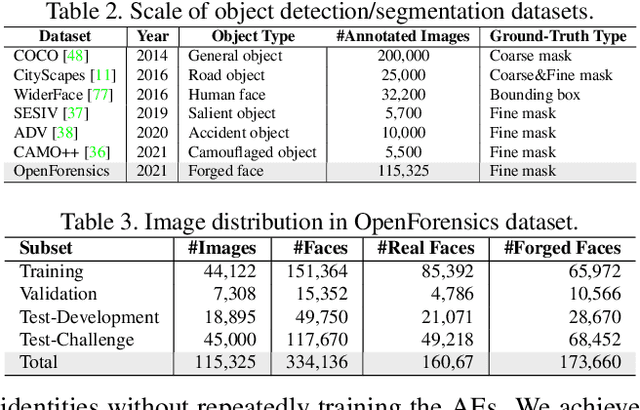

The proliferation of deepfake media is raising concerns among the public and relevant authorities. It has become essential to develop countermeasures against forged faces in social media. This paper presents a comprehensive study on two new countermeasure tasks: multi-face forgery detection and segmentation in-the-wild. Localizing forged faces among multiple human faces in unrestricted natural scenes is far more challenging than the traditional deepfake recognition task. To promote these new tasks, we have created the first large-scale dataset posing a high level of challenges that is designed with face-wise rich annotations explicitly for face forgery detection and segmentation, namely OpenForensics. With its rich annotations, our OpenForensics dataset has great potentials for research in both deepfake prevention and general human face detection. We have also developed a suite of benchmarks for these tasks by conducting an extensive evaluation of state-of-the-art instance detection and segmentation methods on our newly constructed dataset in various scenarios. The dataset, benchmark results, codes, and supplementary materials will be publicly available on our project page: https://sites.google.com/view/ltnghia/research/openforensics
Multi-Task Learning in Utterance-Level and Segmental-Level Spoof Detection
Jul 29, 2021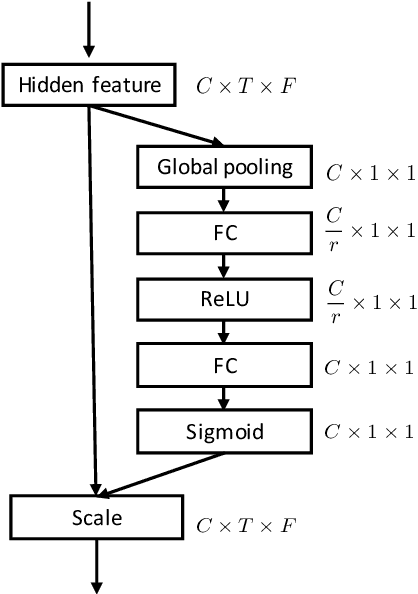
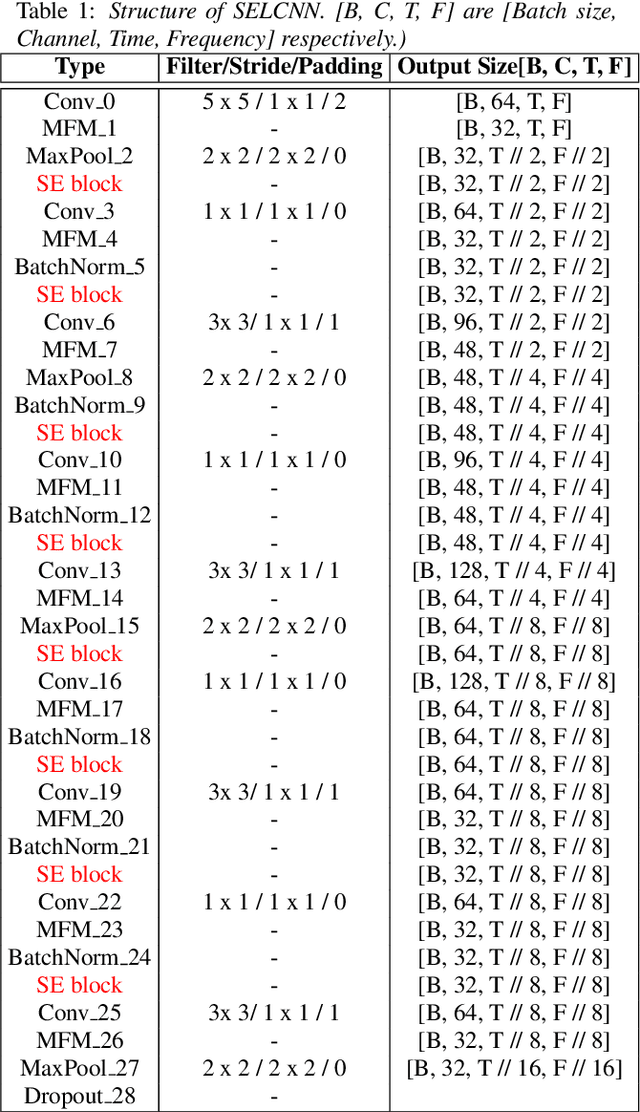

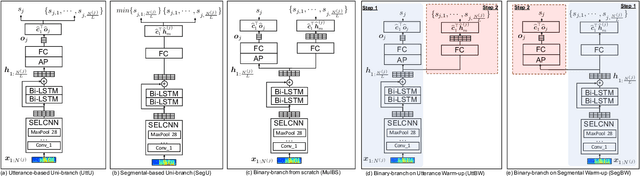
In this paper, we provide a series of multi-tasking benchmarks for simultaneously detecting spoofing at the segmental and utterance levels in the PartialSpoof database. First, we propose the SELCNN network, which inserts squeeze-and-excitation (SE) blocks into a light convolutional neural network (LCNN) to enhance the capacity of hidden feature selection. Then, we implement multi-task learning (MTL) frameworks with SELCNN followed by bidirectional long short-term memory (Bi-LSTM) as the basic model. We discuss MTL in PartialSpoof in terms of architecture (uni-branch/multi-branch) and training strategies (from-scratch/warm-up) step-by-step. Experiments show that the multi-task model performs better than single-task models. Also, in MTL, binary-branch architecture more adequately utilizes information from two levels than a uni-branch model. For the binary-branch architecture, fine-tuning a warm-up model works better than training from scratch. Models can handle both segment-level and utterance-level predictions simultaneously overall under binary-branch multi-task architecture. Furthermore, the multi-task model trained by fine-tuning a segmental warm-up model performs relatively better at both levels except on the evaluation set for segmental detection. Segmental detection should be explored further.
Use of speaker recognition approaches for learning timbre representations of musical instrument sounds from raw waveforms
Jul 24, 2021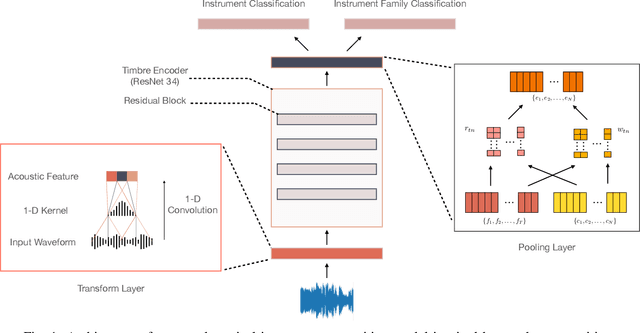
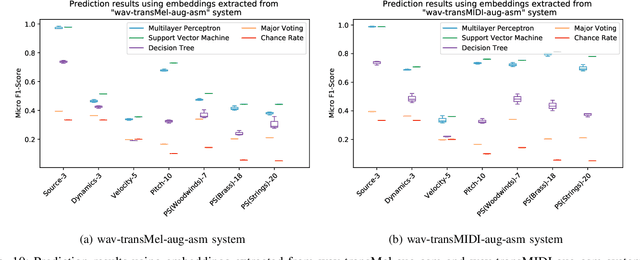
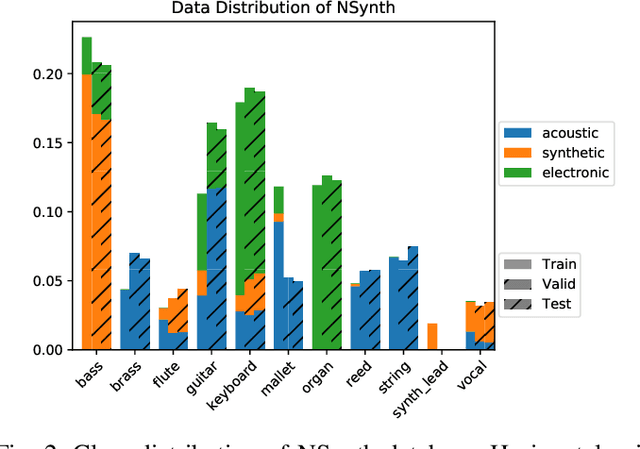
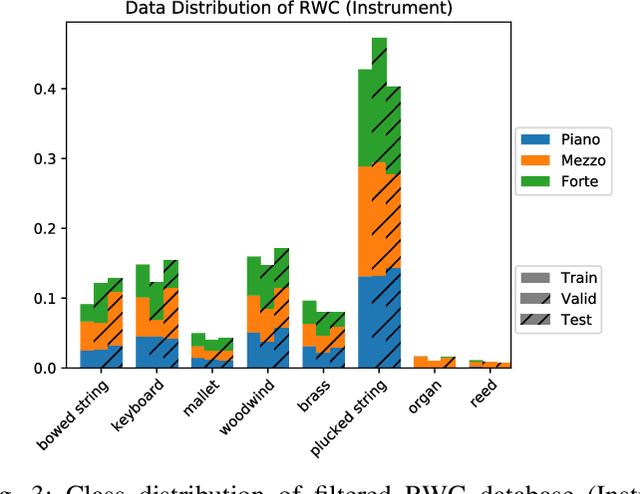
Timbre representations of musical instruments, essential for diverse applications such as musical audio synthesis and separation, might be learned as bottleneck features from an instrumental recognition model. Given the similarities between speaker recognition and musical instrument recognition, in this paper, we investigate how to adapt successful speaker recognition algorithms to musical instrument recognition to learn meaningful instrumental timbre representations. To address the mismatch between musical audio and models devised for speech, we introduce a group of trainable filters to generate proper acoustic features from input raw waveforms, making it easier for a model to be optimized in an input-agnostic and end-to-end manner. Through experiments on both the NSynth and RWC databases in both musical instrument closed-set identification and open-set verification scenarios, the modified speaker recognition model was capable of generating discriminative embeddings for instrument and instrument-family identities. We further conducted extensive experiments to characterize the encoded information in learned timbre embeddings.
SVSNet: An End-to-end Speaker Voice Similarity Assessment Model
Jul 20, 2021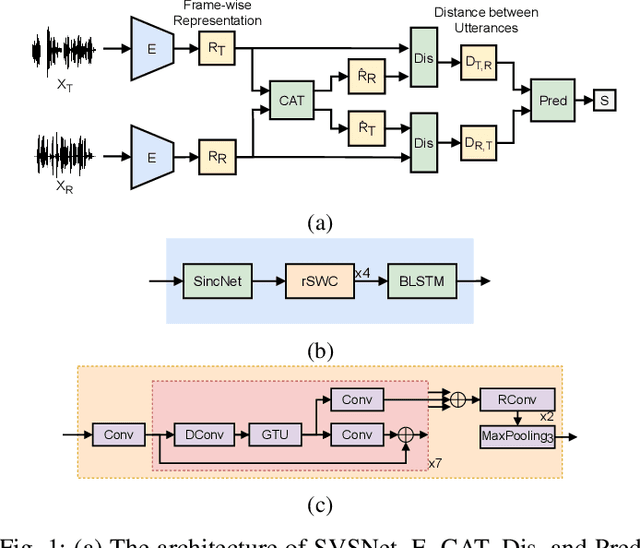
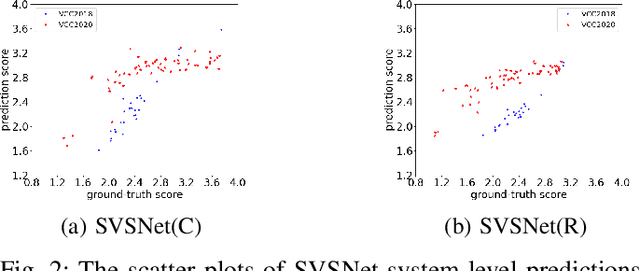
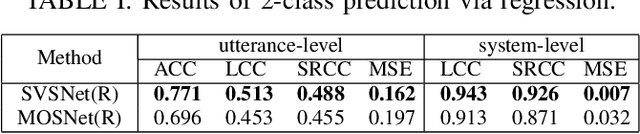
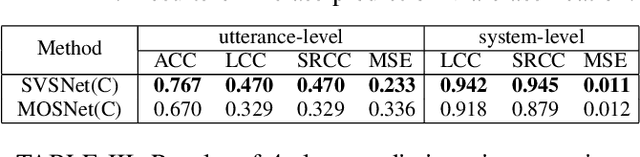
Neural evaluation metrics derived for numerous speech generation tasks have recently attracted great attention. In this paper, we propose SVSNet, the first end-to-end neural network model to assess the speaker voice similarity between natural speech and synthesized speech. Unlike most neural evaluation metrics that use hand-crafted features, SVSNet directly takes the raw waveform as input to more completely utilize speech information for prediction. SVSNet consists of encoder, co-attention, distance calculation, and prediction modules and is trained in an end-to-end manner. The experimental results on the Voice Conversion Challenge 2018 and 2020 (VCC2018 and VCC2020) datasets show that SVSNet notably outperforms well-known baseline systems in the assessment of speaker similarity at the utterance and system levels.
Preliminary study on using vector quantization latent spaces for TTS/VC systems with consistent performance
Jun 25, 2021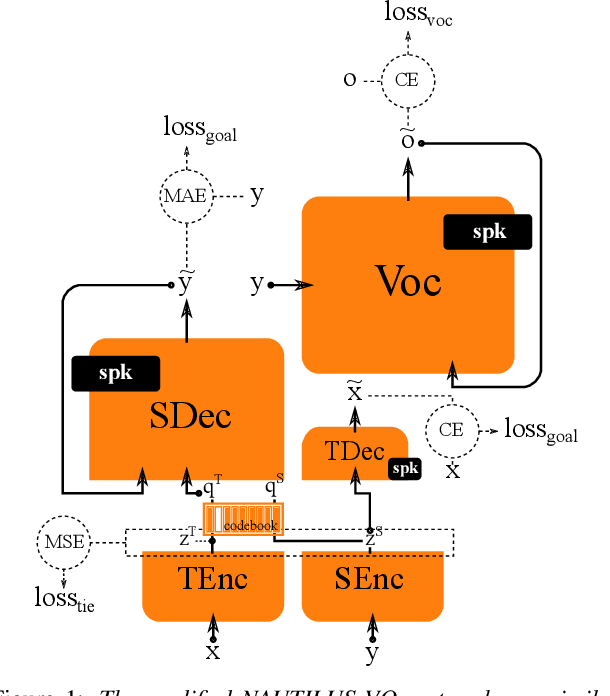
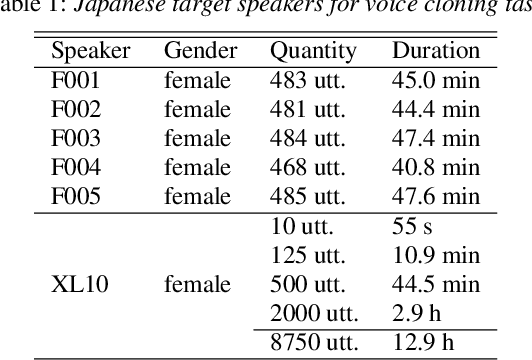
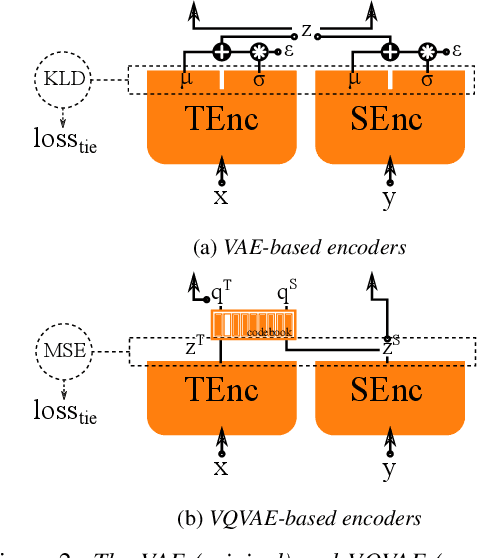
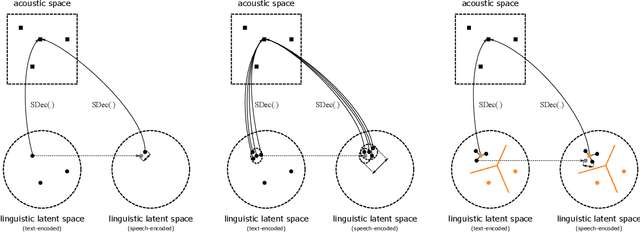
Generally speaking, the main objective when training a neural speech synthesis system is to synthesize natural and expressive speech from the output layer of the neural network without much attention given to the hidden layers. However, by learning useful latent representation, the system can be used for many more practical scenarios. In this paper, we investigate the use of quantized vectors to model the latent linguistic embedding and compare it with the continuous counterpart. By enforcing different policies over the latent spaces in the training, we are able to obtain a latent linguistic embedding that takes on different properties while having a similar performance in terms of quality and speaker similarity. Our experiments show that the voice cloning system built with vector quantization has only a small degradation in terms of perceptive evaluations, but has a discrete latent space that is useful for reducing the representation bit-rate, which is desirable for data transferring, or limiting the information leaking, which is important for speaker anonymization and other tasks of that nature.
Visualizing Classifier Adjacency Relations: A Case Study in Speaker Verification and Voice Anti-Spoofing
Jun 11, 2021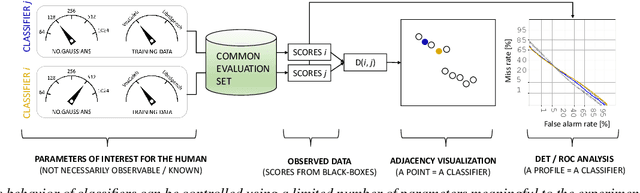
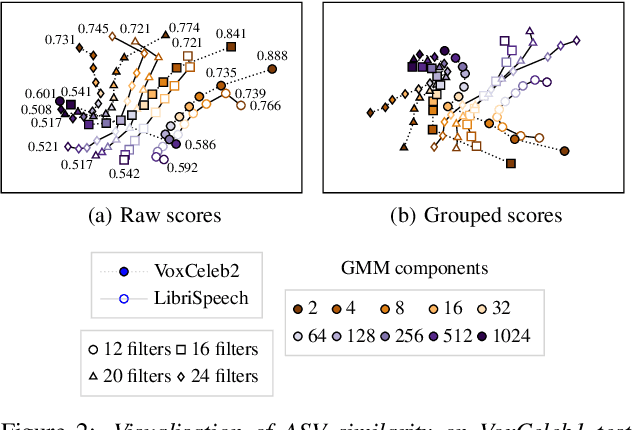
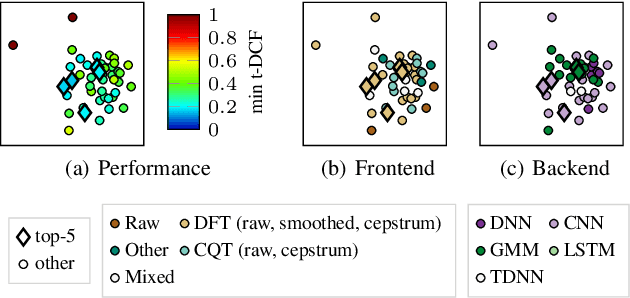
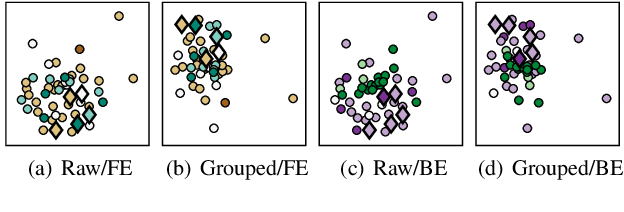
Whether it be for results summarization, or the analysis of classifier fusion, some means to compare different classifiers can often provide illuminating insight into their behaviour, (dis)similarity or complementarity. We propose a simple method to derive 2D representation from detection scores produced by an arbitrary set of binary classifiers in response to a common dataset. Based upon rank correlations, our method facilitates a visual comparison of classifiers with arbitrary scores and with close relation to receiver operating characteristic (ROC) and detection error trade-off (DET) analyses. While the approach is fully versatile and can be applied to any detection task, we demonstrate the method using scores produced by automatic speaker verification and voice anti-spoofing systems. The former are produced by a Gaussian mixture model system trained with VoxCeleb data whereas the latter stem from submissions to the ASVspoof 2019 challenge.
A Multi-Level Attention Model for Evidence-Based Fact Checking
Jun 02, 2021

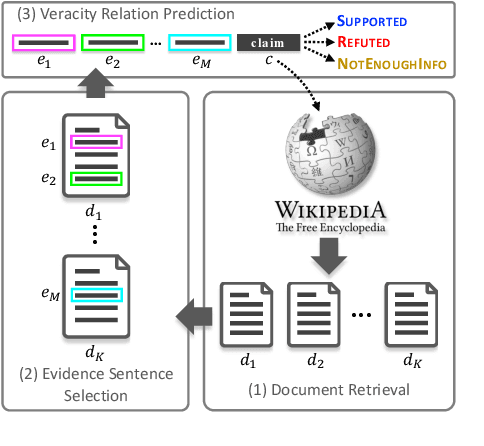
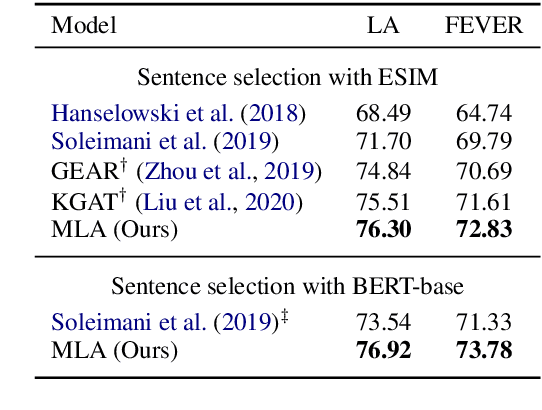
Evidence-based fact checking aims to verify the truthfulness of a claim against evidence extracted from textual sources. Learning a representation that effectively captures relations between a claim and evidence can be challenging. Recent state-of-the-art approaches have developed increasingly sophisticated models based on graph structures. We present a simple model that can be trained on sequence structures. Our model enables inter-sentence attentions at different levels and can benefit from joint training. Results on a large-scale dataset for Fact Extraction and VERification (FEVER) show that our model outperforms the graph-based approaches and yields 1.09% and 1.42% improvements in label accuracy and FEVER score, respectively, over the best published model.
Text-to-Speech Synthesis Techniques for MIDI-to-Audio Synthesis
May 17, 2021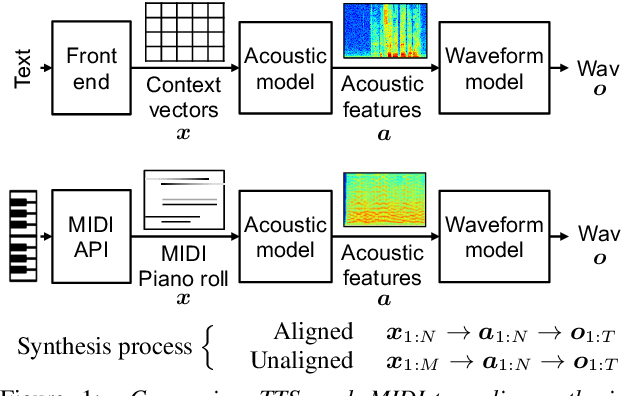
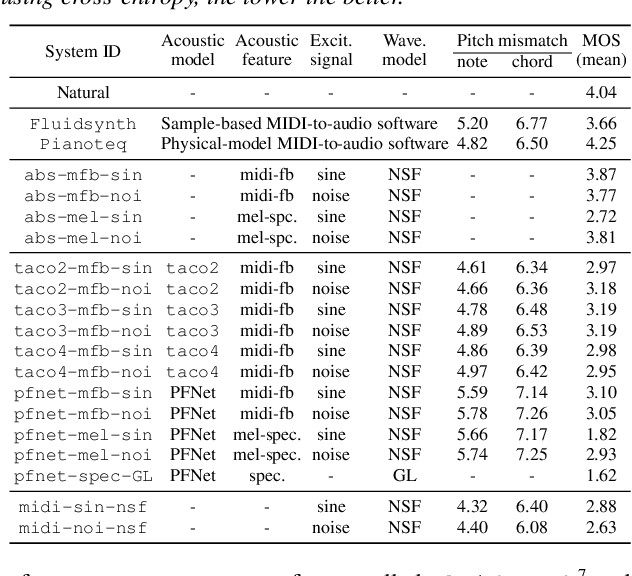
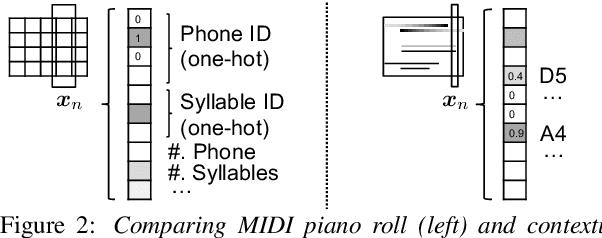
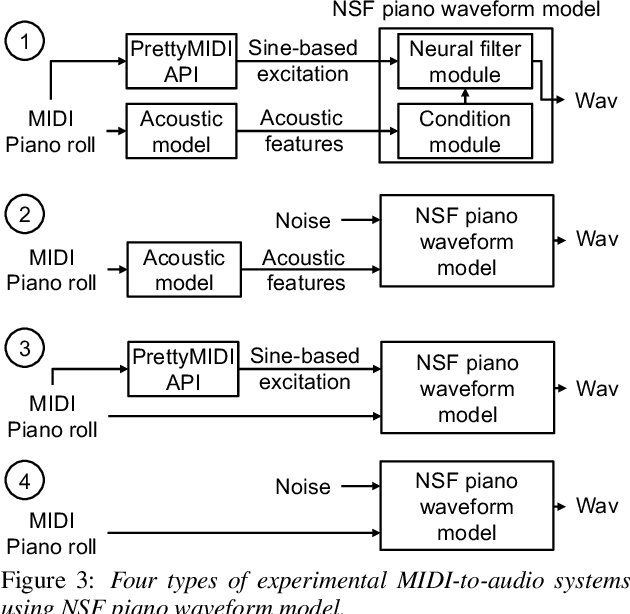
Speech synthesis and music audio generation from symbolic input differ in many aspects but share some similarities. In this study, we investigate how text-to-speech synthesis techniques can be used for piano MIDI-to-audio synthesis tasks. Our investigation includes Tacotron and neural source-filter waveform models as the basic components, with which we build MIDI-to-audio synthesis systems in similar ways to TTS frameworks. We also include reference systems using conventional sound modeling techniques such as sample-based and physical-modeling-based methods. The subjective experimental results demonstrate that the investigated TTS components can be applied to piano MIDI-to-audio synthesis with minor modifications. The results also reveal the performance bottleneck -- while the waveform model can synthesize high quality piano sound given natural acoustic features, the conversion from MIDI to acoustic features is challenging. The full MIDI-to-audio synthesis system is still inferior to the sample-based or physical-modeling-based approaches, but we encourage TTS researchers to test their TTS models for this new task and improve the performance.